腾讯数据湖查询优化实践

分享嘉宾:陈梁 腾讯 高级工程师
编辑整理:Will(伟宜)
出品平台:DataFunTalk
导读:本次分享题目为数据湖技术Iceberg查询优化实践,主要包括以下几方面内容:
Iceberg简介
数据入湖
查询优化
后续规划
首先简单介绍一下iceberg。
1. Iceberg架构
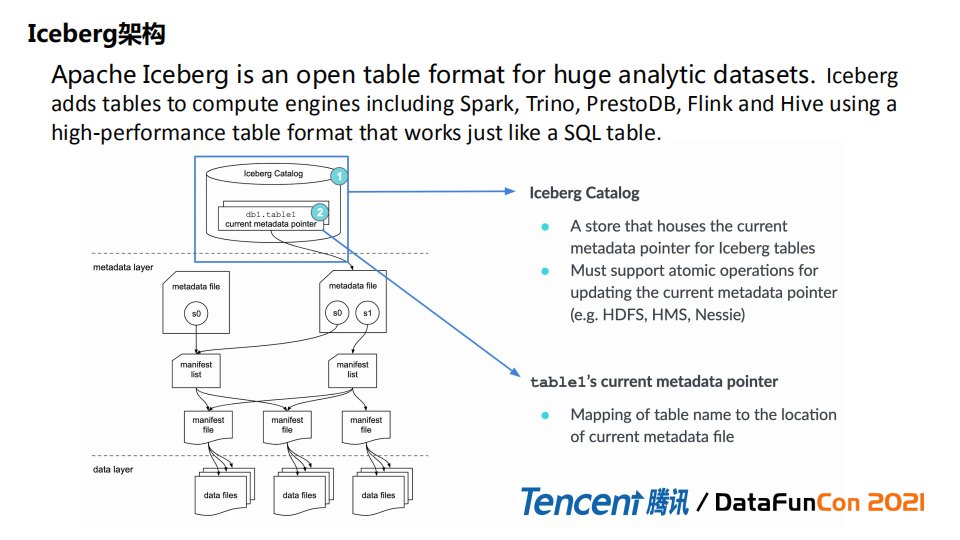
根据社区描述,Iceberg是一种具有高性能的表格式(数据组织格式),它可以适配Spark / Prest / Flink等引擎提供高性能的读写和元数据管理功能,在大数据领域,SQL化的操作方式带来了较高可靠性和简单性。
Iceberg是一个三层结构:
最底层是data层,是真实的数据,存储格式比较多的是Parquet和ORC。
Data层数据之上有Metadata元数据管理层。元数据决定如何加载数据、写入数据。所以说Metadata是iceberg的核心。
Metadata层又分成三块,最上层 metadata file 会记录表级别、快照级别信息,比如表的schema,分区;往下一层是manifest list,会将所有行为记录下来,比如insert或者其它操作;在manifest list之下会维护manifest files信息。manifest files 是data files最直接的映射关系,会记录文件级别的统计信息,包括索引信息,min/max值。
-
最上层是Catalog,通过它可以开始访问。
2. Iceberg查询
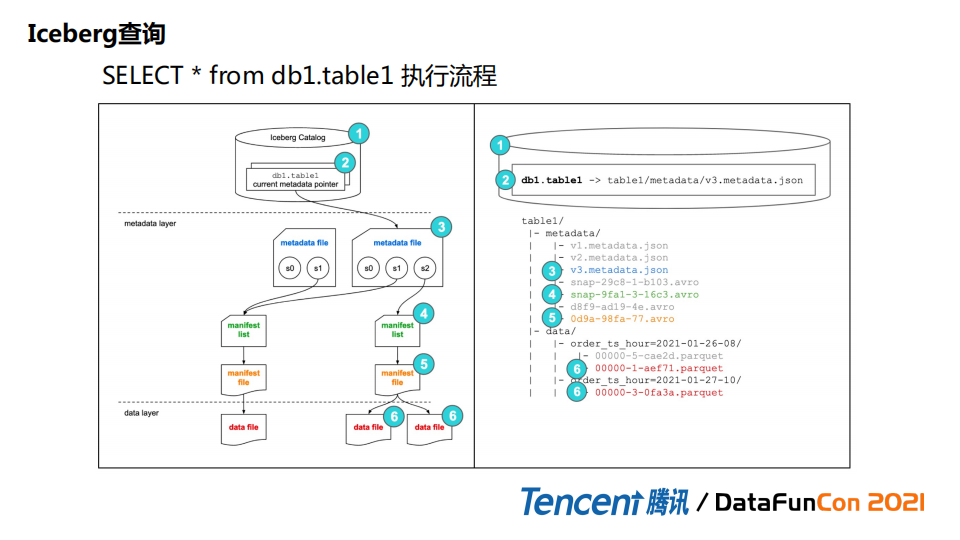
接下来看一下查询过程。例子是一个简单select SQL执行流程。如果存了一个hive catalog, 通过绑定方式会加载metadata json文件,这个文件由metastore管理,里面会记录当前信息比如current snapshot id。snapshot id会把它映射到 manifest list。根据manifest list里记录的关系,比如add或者删除的这类信息,来确定一些文件是否是需要的。然后再往下层去找manifest files 把文件级别信息找出来,包括统计信息。这个是全表查询。
3. Iceberg Hidden Partitioning
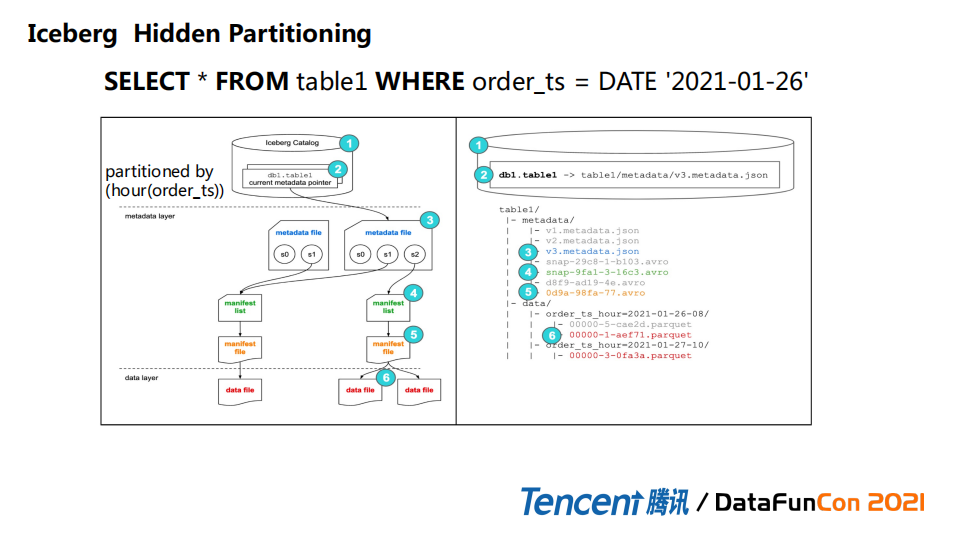
在传统的hive数仓结构中,查询某个表,如果指定的条件跨度比较大,可能需要全表扫描,随着分区数越来越多,hive metastore会有很大压力的。但是iceberg本身有自己高效的特性,比如支持分区隐藏来做表的查询。如果建表的时候认为分区数比较多,建表时创建一个隐藏分区出来,用户不需要做额外操作。Iceberg会把整个操作下推到隐藏分区级别做scan。
这里的例子创建的是hour(order_ts)级别分区,查询order_ts=DATE‘2021-01-26’时前边1到5 步是一样的,只是后面真正加载data files,会根据分区的条件找到真正的分区,把结果查询出来。有极大的data skipping 的效果。
4. Iceberg Time Travel
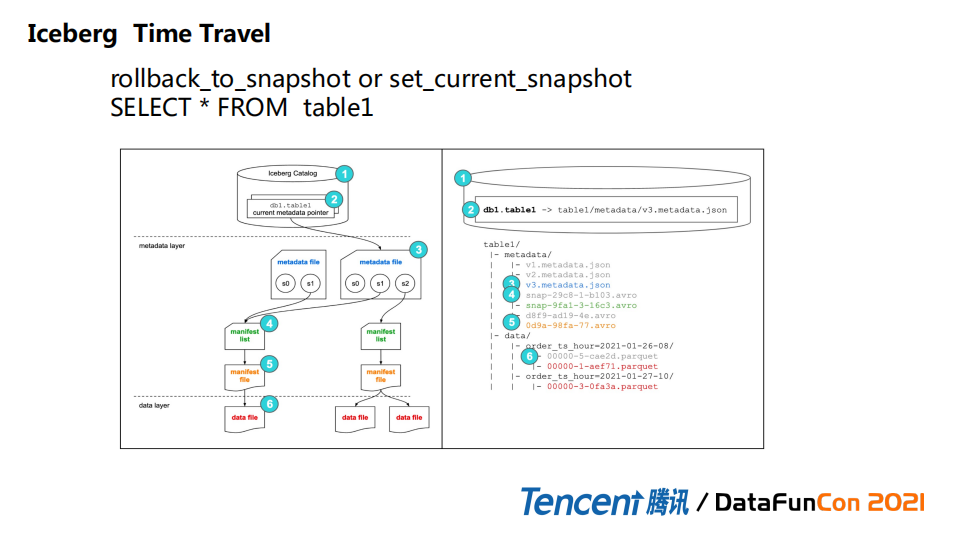
时间旅行是另外一个比较重要的特性。Iceberg架构决定所有历史信息都会被记录下来,所以我们可以通过API 或者SQL得到过去某个时间点的snapshot id,然后做历史时刻的查询。这里历史数据不仅仅包括数据本身信息,还包括历史的DDL,schema的变更信息都可以被保存下来,这也为上层服务定位问题提供便捷。
5. Iceberg Major Feature

Iceberg主要features总结如下:
① 基于快照的读写分离和回溯,通过snapshot id做前后隔离。
② 流批统一的写入和读取。
③ 表schema和分区演进,能够加速查询和data skipping,不必加载整个表。
④ 作为table format不绑定特定引擎,计算和存储完全隔离。
⑤ ACID语义,用户彼此之间读写没有影响,通过乐观锁commit之后对其他用户才是可见的。
1. 数据入湖的方式
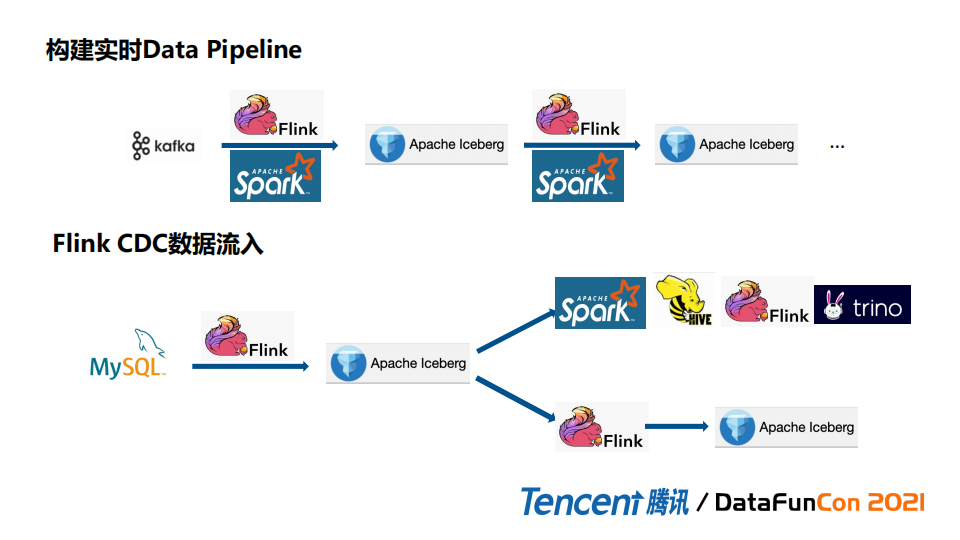
(1) 构建实时datapipeline
传统方式通过读kafka或者其它MQ数据,然后Flink或者Spark实时处理,再通过MQ给下游,然后Flink或者Spark再继续处理。这里可以通过Iceberg替换 MQ来做隔离,Iceberg通过snapshot隔离可以帮助实现增量的消费。Flink读取或者sink到Iceberg 都是非常方便的。
(2) 传统方式实现端到端的流式pipeline
一般是写hive表,是不能实现增量,分区比较多的情况下会通过分区实现增量,这个粒度比较大,分区比较的多的情况下对performance也有极大的影响。Iceberg可以解决整个问题。另外Flink支持CDC数据流入,结合Iceberg本身特性,Flink可以把mysql binlog日志同步到iceberg做离线和实时的数据分析。
(3) 近实时流批统一
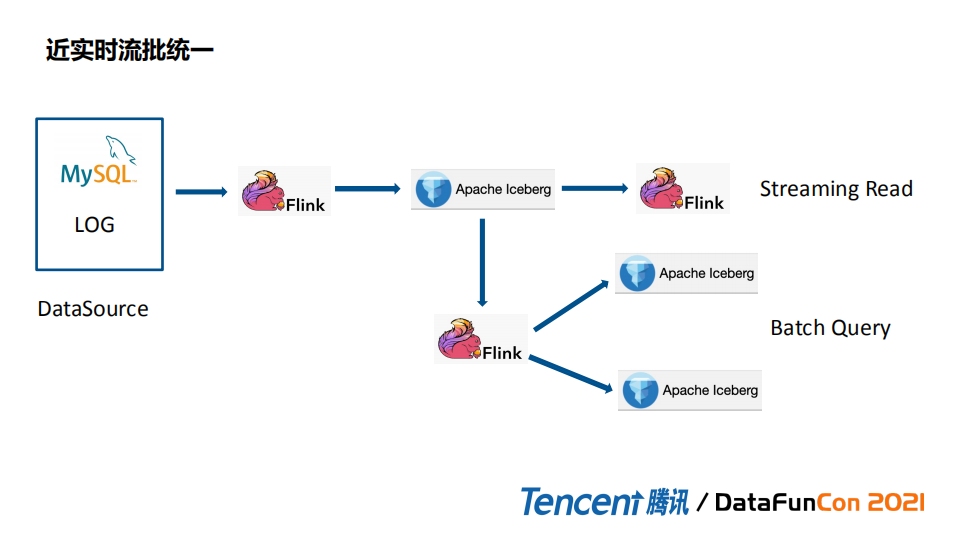
第三种方式是近实时流批统一。Data source 通过Flink同步到Iceberg,来做实时读取和batch query。如果是传统方案实现近实时流批统一需要中间层用Kafka存数据,这样kafka本身需要保证通路稳定性,但是消息队列稳定性不是很好实现。而且Kafka对历史数据,顺序记录都不是很完善。Iceberg本身可以做历史数据快照的保存,出现问题时我们随时可以随时回退到某个snapshot来继续消费、虽说会有轻微延迟,但会是接近实时的。另外Iceberg做了优化,比如下推,为下游消费提供加速效果。
2. DLA数据入湖
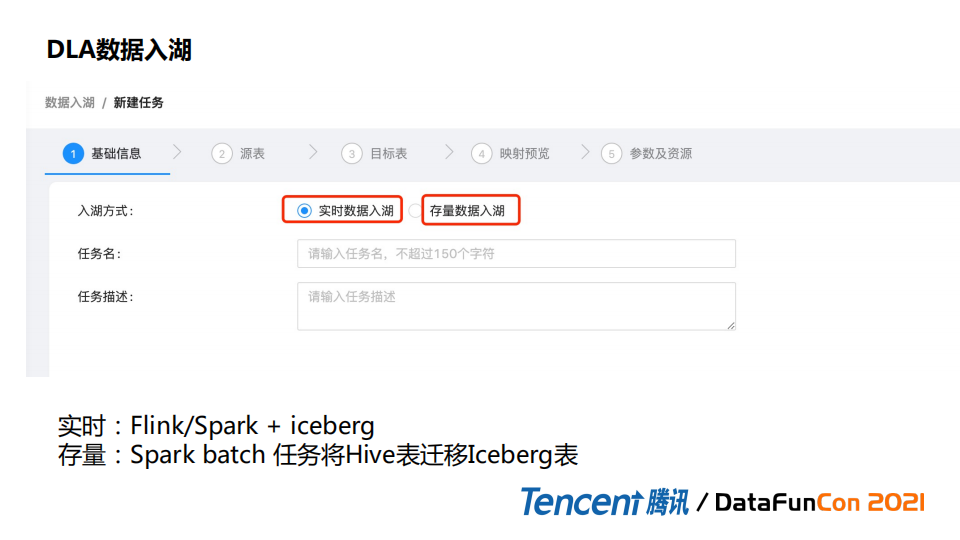
为了方便更多传统数仓(Hive)接入到数据湖和通过Iceberg表管理,我们提供了两种方式。
实时:Flink/Spark + Iceberg ,方便用户直接消费MQ数据。
存量:数据迁移,Spark batch任务将Hive表陆续迁移到Iceberg表。
前面介绍了Iceberg架构和数据入湖流程,接下来的主题是查询优化。
第一种场景,随着数据sink到Iceberg,数据逐步增长,会有问题,比如Flink分钟级别写入会导致小文件比较多,导致两个问。一个是导致namenode压力大。另外小文件比较多,同一个表文件随机分布在不同data node,scan时效率比较低。这样情况下需要对小文件进行优化。此外历史数据,比如job 失败会留下孤儿文件也需要清理。这是Flink sink会遇到的小文件问题。
第二种场景,数据量比较大但是数据没有按照一定规律分布,没有很好的data skipping效果,会导致加载数据量比较大和查询效率比较低。
1. 优化手段

基于上述问题,有两种解决方案。
第一种就是数据治理服务专门来处理小文件合并,快照清理,以及孤儿文件清理的动作。
第二点会有数据组织优化的改进,在默认Bin-Packing和Sort基础上扩展Z-ordering的实现,来做数据重分布。
2. 数据治理服务
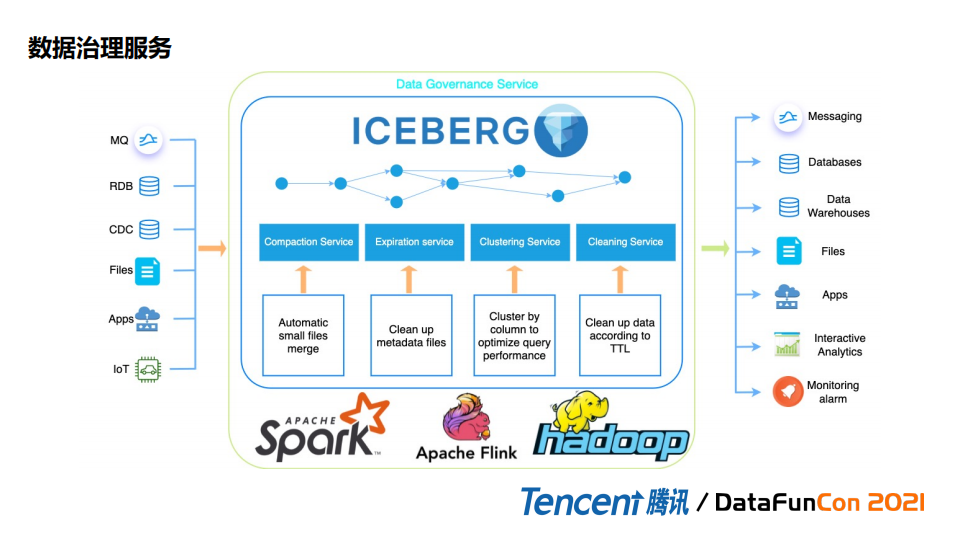
Flink支持运行时做合并,但是会影响Flink实时性,造成业务处理overhead, 所以我们把数据治理服务独立出来。数据治理服务主要分为四点:
Compaction Service:自动小文件合并;
Expiration Service:做metadatafiles和data files 的清理;
数据的Cluster Service :重新打散列组合,对多条件查询场景和按照需要skipping一部分数据时做一些适配;
Cleaning Service:类似可以清理的服务,相当于传统的Hive生命周期的管理。
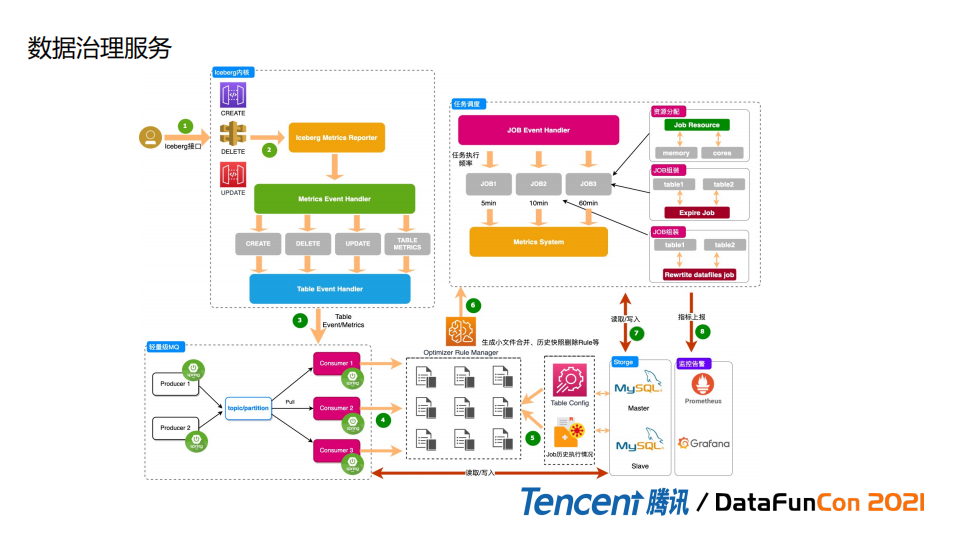
接下来我们看一下整体执行流程。
基于Iceberg接口统一,我们做了metrics 的适配,能够把Flink,Spark 做的一些操作比如DDL更新或者Insert 数据上报到MQ,之后通过读MQ数据来做一些分析,然后适配不同优化规则,通过规则去决定我们如何合并,如何删除等操作。
同时我们有任务调度服务来决定如何拼装job,例如有的table 比较小,可以把rewrite行为做一个合并,相当于做资源的优化。
3. 数据组织优化

数据组织优化主要是通过rewrite实现。
Bin-Packing: Iceberg默认小文件合并策略,按照固定大小做合并,适用场景就是小文件合并。因为是Robin策略会导致部分小文件不能及时合并,仍然有小文件问题。
Sort:支持按照固定列排序重写 适用场景:比较适合散列度较高的列进行排序,使得文件级别和Page级别的min-max范围更小,有助于高效的数据过滤,这种对于单个列的Data Skipping效果较好,可用于单条件查询。某个列散列度是比较高的,这时效果最显著。
Z-Ordering:是一种新的策略,在rewrite datafiles上扩展实现。利用Z-Order的空间曲线填充算法重写。适用场景:多个字段均能取得较好的Data Skipping效果,比较适合多条件查询。
4. Z-Ordering的介绍

这里的z-ordeing的介绍图片和介绍来自维基百科。有坐标轴,x轴和y轴,如果我们把x轴和y轴index转换为二进制,并且产生交错位后会形成一值,所有值首尾连接起来会形成一个线这个线就是z曲线,交错位的二进制的值也叫z-value。
其实发现这里边有很多小方格,可以发现某个点附近,具有公共前缀信息,结合z-ordering 曲线特征,我们可以对数据进行重组,在图片的例子中,重组之后放到四个文件中,再使用x,y字段查询,可以发现可以skip掉一半的文件。这就是z-ordering 的一个主要思想。
借助这个思想,可以把它复用到Iceberg中重写数据组织策略中。
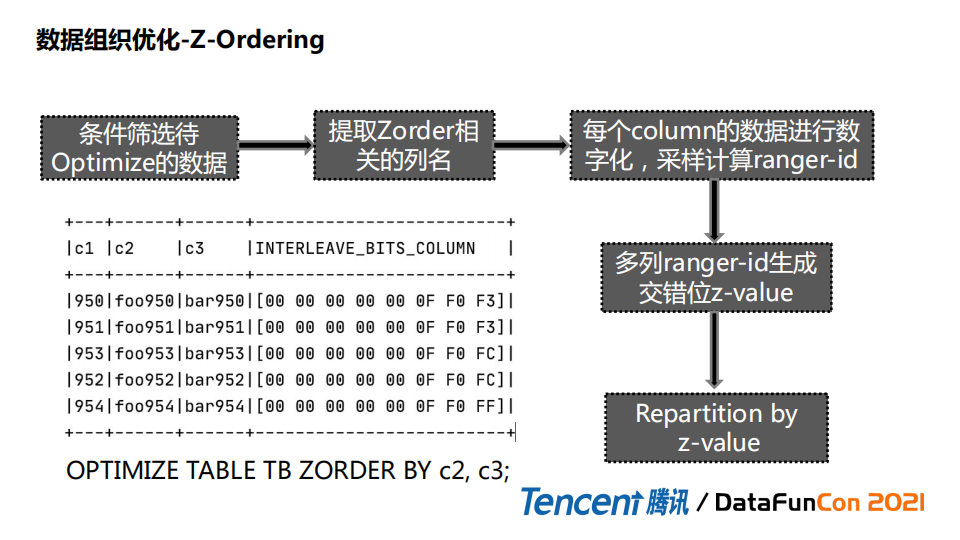
我们首先筛选出哪些数据需optimize,也就是需要z-ordering优化,第二步取出列名,第三步对列名进行数字化处理,这里通过采样方式把对应range分区id拿到,然后把对应range id生成信息产生交错位。把z-value(交错位) 提取出来,partition方式进行重写。

SQL Extension实现:为了方便用户接入使用,我们在Iceberg里Spark Extension模块了里做了sql的扩展实现。通过这种方式可以指定变量。也可以指定Options,来决定rewrite之后文件大小,以及其它Iceberg table的属性。
API的实现:这种方式也可以支持我们按照条件来做一个增量的optimize, 而且因为我们是直接复用rewrite的逻辑,所以也是支持V2 format。
接下来我们看一下效果,以SSB数据集测试。

首先将SSB数据集维度表和基表做一个join,然后充分打散,保证我们数据的随机性,方便我们测试。这里选取的数据不是特别大,规模数据是scale-100,60G数据,上万个文件。

对比三种场景:
第一种场景,10000文件查询数据时,扫描的数据量是比较大的,3.3G。
第二种场景,如果我们用bin-pack机制,也就是默认rewrite file策略,加载的数据量是3.2G,其实没有多少减少。
第三种场景,如果我们按照这三个字段进行z-order,我们可以按照加载的数据是有极大降低的。
下边是一个直观的图。
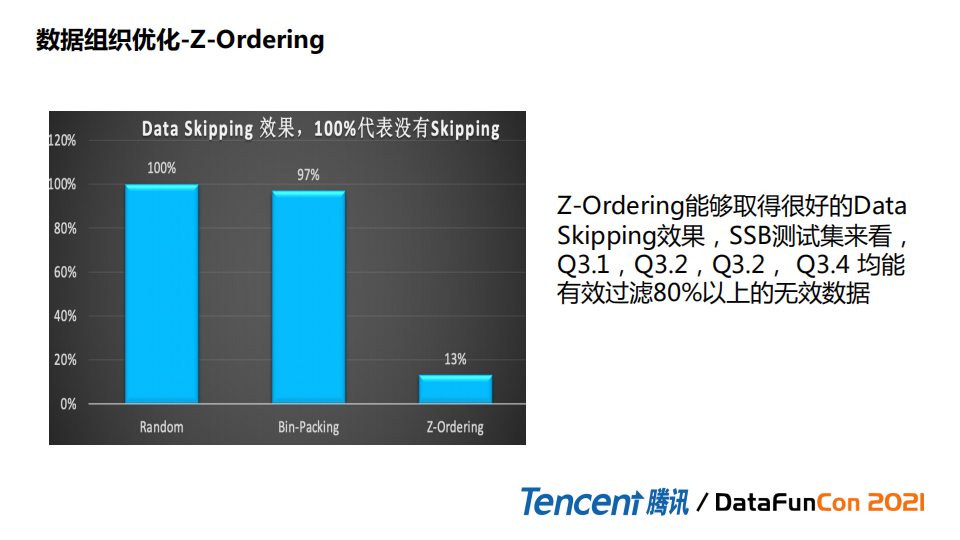
可以看到随机分布是没有data skipping效果,因为每个字段都是均匀分布在所有文件中。Bin-packing也是一样,因为它只是关注大小,不关注存储形式。如果是z-ordering能skip掉80%以上无效数据。

在内核层面:
第一点是做索引的支持,目前实现了parquet文件上的Bloom filter ,但是不够通用,我们正在做通用的Bloom filter。
第二点希望借助Alluxio做加速支持,在平台上做到对用户的透明。
第三点就是SQL Extension的持续增强。
第四点空间曲线的持续支持,z-ordering 也有些局限性,比如首尾跨度比较长,一些场景下不是很通用。
第五点完善read, write metrics采集,然后更好的根据不同场景做一个优化。
在平台层,做一些用户支持,包括:
部署在线查询平台,通过在线编码形式来查询数据。
优化文件合并规则,也在做持续改进和优化,并加入元数据管理。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“数据湖” 就可以获取《数据湖专知资料合集》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~