基于Iceberg的大规模数据分析优化加速实践

分享嘉宾:余根茂 腾讯 技术专家
编辑整理:李铭 多点dmall
出品平台:DataFunTalk
导读:随着企业数据量的不断增长,数据格式的不断增多,在保证数据查询准确性的条件下,数据分析人员对查询速度的要求变得越来越高。在探寻更快查询速度的过程中,Apache Iceberg提供了基于文件Metrics的DataSkipping技术,实现查询时快速筛选所需的数据文件。但是,我们在日常使用中发现,当查询条件中的筛选字段增多时,DataSkipping技术效率急剧下降,即最终需要扫描的数据文件大大增加,甚至需要全表扫描,此时DataSkipping带来的效率提升几乎可以忽略不计。为了能够使Apache IceBerg的DataSkipping技术能够发挥更好的效果,我们需要进行数据组织优化。接下来,我将和大家分享我们的思路、设计以及最终的效果。
今天的介绍会围绕下面五点展开:
查询分析的IO效率
数据组织优化设计
技术实现剖析
性能测评
未来规划
1. 一个查询例子
首先通过一个常见的查询案例,给大家介绍一下数据查询时Apache Iceberg为提高查询IO效率所提供的一些功能。
案例SQL:
SELECT count(*)FROM employeeWHERE first_name like ‘Tho%’AND last_name like‘Frank%’AND birthplace=‘newyork’;
以上的SQL是一个常见的查询语句,其中birthplace字段是分区字段。
这样的查询语句在Apache Iceberg中会经过以下的查询步骤:

分区裁剪:根据分区字段birthplace定位具体需要扫描的文件位置,过滤掉大量无效文件。
文件过滤:经过第一步筛选后,根据留下来的每一个数据文件上的first_name和last_name的min-max信息,以判断该数据文件是否存在目标结果数据。
Row Group过滤:根据parquet文件内部对数据的统计信息,可以快速过滤掉parquet文件块中不在查询范围内的Row Group。
就这样,经过三层IO的筛选过滤,最终只需要扫描很少的数据文件就可以完成此次的查询,提高总体查询效率。
以上便是Apache Iceberg提高总体查询效率的原因。但是,这里面有一些潜在的问题。
2. 潜在的问题
首先,min-max的出现需要基于数据经过排序的基础上,如果字段没有经过排序,那么分散在每一个数据文件中的字段是无序的,min-max其实也就失去了过滤的意义。
其次,一张表的查询往往涉及多个字段。如果多个字段进行排序,排序的效果会随着字段的增加而差强人意,前几列的效果可以保证,但是后序列的排序效果甚至可能出现乱序的情况。一旦乱序的情况产生,那么min-max的过滤效果失效,查询也将面临全表扫描,IO效率再次降低。
如下图中的第三列,如果查询会以此为筛选字段,那么将会扫描分区中所有的数据文件。
为了解决上述的问题,我们将解决方案关注在数据组织优化上。
1. 空间填充曲线(Space-filling curve)
我们先来了解一个数学上的概念:空间填充曲线。

我们不用太理解这个曲线数学上的意义,重点是它为我们解决问题带来的思路:降维。解决问题其实就是想要利用空间填充曲线,对多维数据(例如一张表中的多列)进行降维处理,以提升相关数据的聚集效果以及相应的数据min-max的使用效率。
2. 例子:地理位置编码
下面举一个空间填充曲线的使用案例,也就是地理位置编码(Geohash),也更方便理解我们将如何使用这个概念。
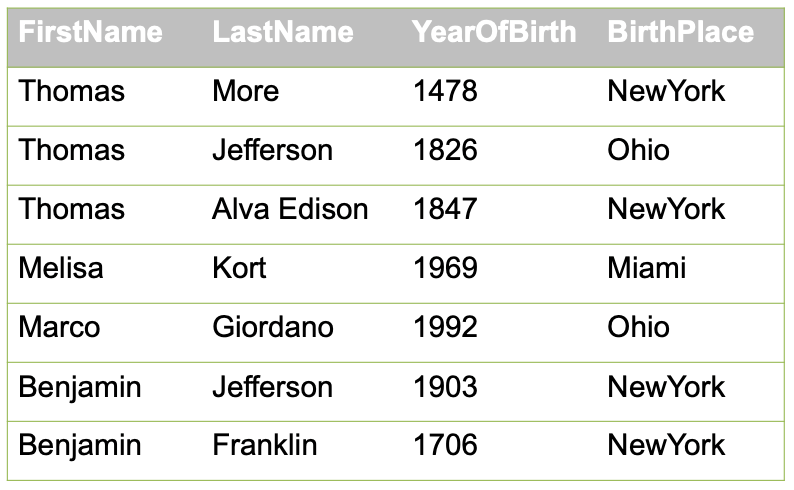
地理位置编码(Geohash)是一种分级的数据结构,把空间划分为网格。举个例子,我们要搜索区域为二维(x,y)的,其中x的范围是[2,3], y的范围是 [4,5],从图中也能看出它的总扫描范围是一个正方形的网格。
那怎么样用地理位置编码将其范围转化成一维(z)的呢?
首先取二维的上下界进行定位,即,刚刚x和y的范围按照上下界拆分,可以写为:
上界:x=3, y=5
下界:x=2, y=4
转化一维地址,根据Geohash的规则,将偶数位放经度,奇数位放在纬度,对上下界的值进行错位编码(即转换二进制),此时:
下界:100100
上界:100111
即转为了一维的搜索空间:[100100,100111],其中包含了4个值,分别为100100,100101,100110,100111,从上图可以看出,这四个值正好就是在二维的四方格中的四个值,降维后的含义是不变的。
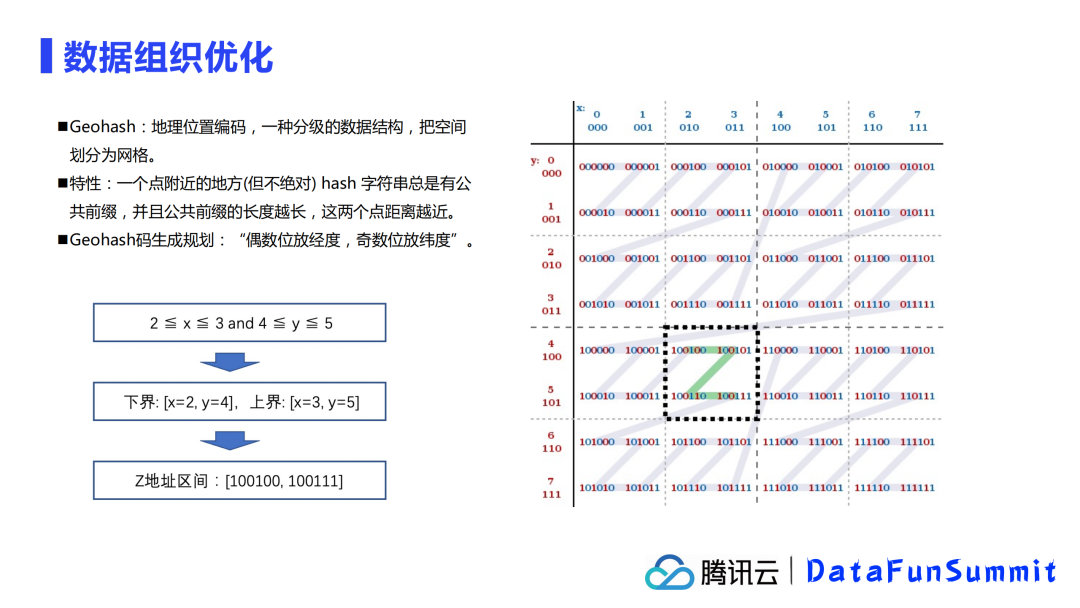
当然,降维不是这么简单的,很容易能找到反例:
如图所示,当范围在x为[1,3],y为[3,4]时,计算出的一维地址空间实际内容就远超过二维表现的空间,例如上图中红色部分,这种在降维后的范围中但不在降维前的范围中的这部分,一般称为fault数据。这样的fault数据会增加搜索的成本,降低搜索的效率,当然在后面我将给大家分享我们是如何在Apache Iceberg中避免这样fault数据出现的。
3. ZOrder算法的诞生及其意义
借鉴了上述的概念和思路,为了解决多列排序带来的查询效率的降低以及min-max的无效过滤问题,腾讯Iceberg实现了基于ZOrder算法的数据组织优化,并提供了原生的OPTIMIZE语法。
至于上述的fault数据问题,Apache Iceberg对文件中的数据提供了详细的统计信息,就例如我们一直提到的min-max,就能够在降维后对数据再次精准过滤,避免fault数据带来的危害。
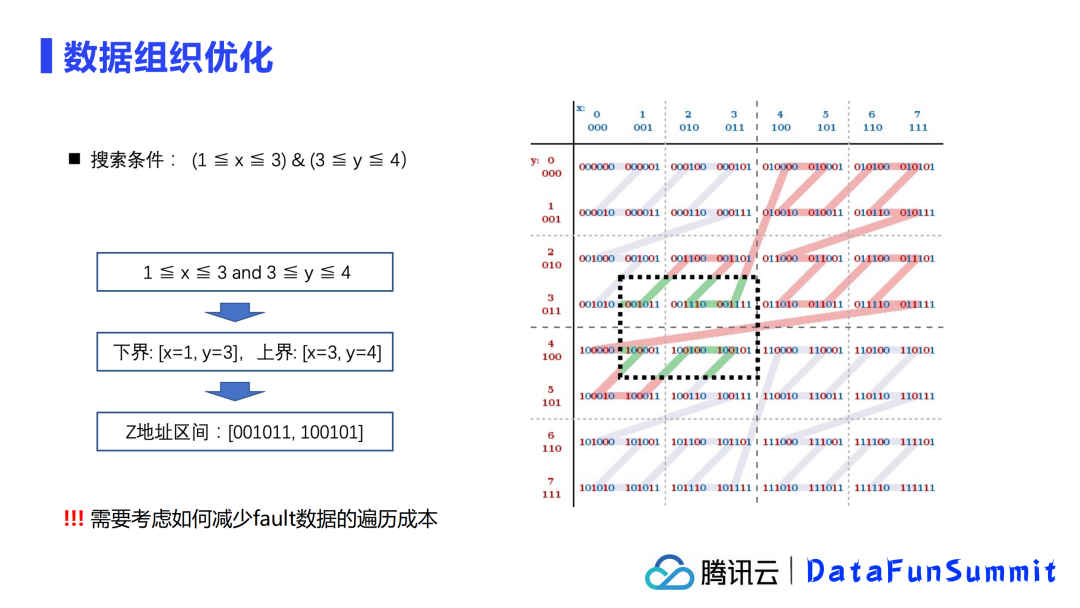
数据组织优化能带来什么?
如上图所示,绿色的点为我们此次查询的目标数据,红色的点为其他数据。从Snapshot N开始,如果我们不做组织优化,我们可以看到数据是分散在1000个文件中的,分布很均匀,导致查询的时候需要扫描大量文件。
在做OPTIMIZE优化后,例如Snapshot N+1,我们会将数据做聚合和重新排列,将数据整合成为4个文件,并且数据基本分布在少量几个文件中,这样的情况下扫描的文件就大大降低了。
而在后续,因为不断有数据写入,形成新的小文件,那继续使用增量的OPTIMIZE语法,可以不断对增量的小文件进行聚合整理,就如Snapshot N+2和Snapshot N+3。
这样会带来两个好处:
减少小文件,提升元数据质量和IO效率;
IO优化,提升查询效率。
接下来给大家介绍一下OPTIMIZE是如何实现组织优化的。
示例SQL语法:
OPTIMIZE TABLE employee ZORDER BY first_name, last_name1. 筛选候选文件
首先,使用OPTIMIZE时需要限定进行组织优化的是哪些文件。文件选择有两个筛选原则:
可以选择全表或者具体的分区文件夹进行组织优化;
支持多种策略,如上面描述的全量优化和增量优化。
2. 根据多维列值生成z地址
例如,某一行数据中,first_name是Thomas,last_name是More
初始数据:Thomas, More
数字化:68, 102
数字化的计算方式:对该列中的所有数据进行采样统计,而这个数据在采样区间中的位置的下标,即为数字化对应的值。
使用2字节bits表示:0000000001000100,00000000 01100110
现在分享的是2字节,实际实现时往往采用的是4字节或8字节进行处理。
交错位(转化一维):00000000 00000000 00110100 00110100
这个值就是z地址,也就是zOrderAddress。
3. 根据z地址进行Range重分区
4. 事务写回存储
通过Copy on Write的方式写回表中,生成新的快照文件。
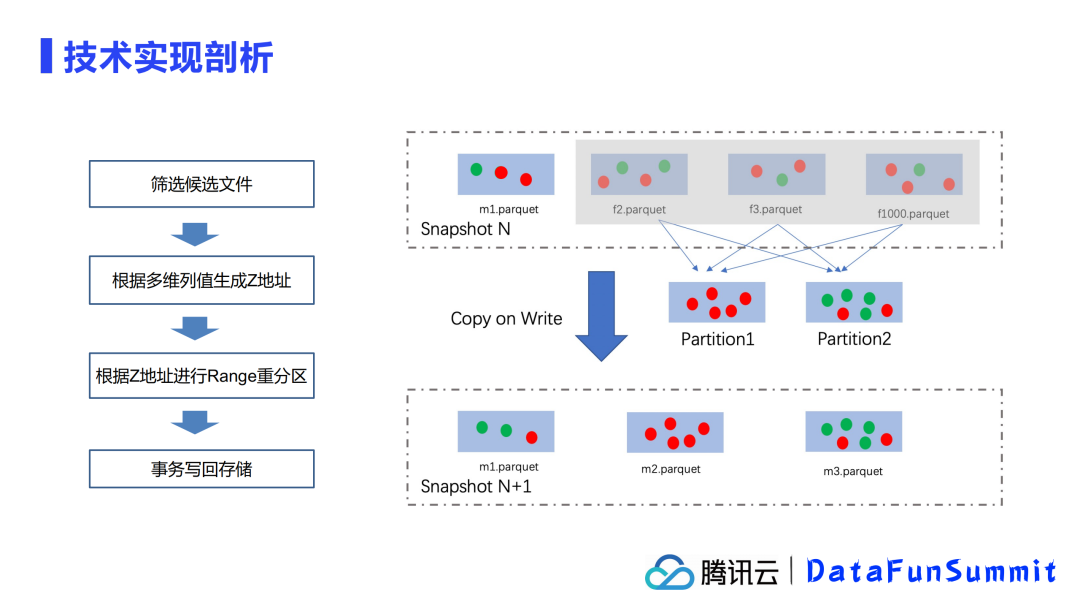
以上就是OPTIMIZE运行中的流程。
原生的语法支持:
OPTIMIZE table_identifier [ WHERE predictate ]ZORDER BY col_name1, col_name2
再次强调,where条件中仅支持分区列,用作分区组织优化的筛选。
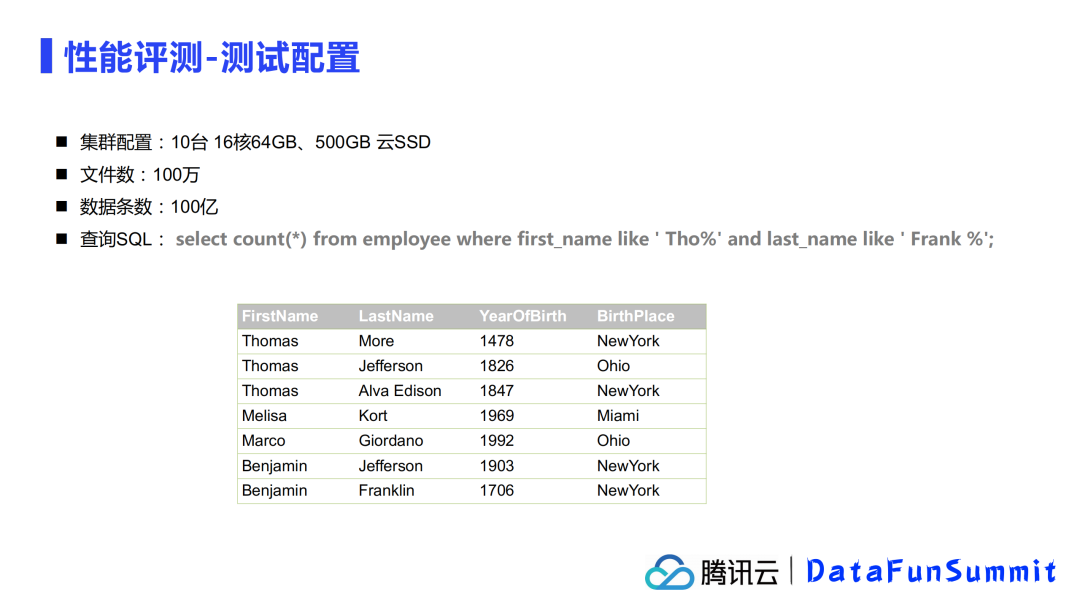
我们做了性能评测,测试了数据组织优化以后带来的查询性能的提升情况。主要分为以下两类测试:
关键参数测试
聚合列:很明显,不同的列做聚合效果不同
输出文件大小:配置写出文件的大小
CUBE大小:实际参与进行多维聚合的最小单元
SSB基准测试
关键参数测试测试配置:
1. 关键参数测试-聚合列
首先,我们固定了输出文件大小为1G,CUBE大小为150G,准备了两组不同数量的聚合列进行测试。
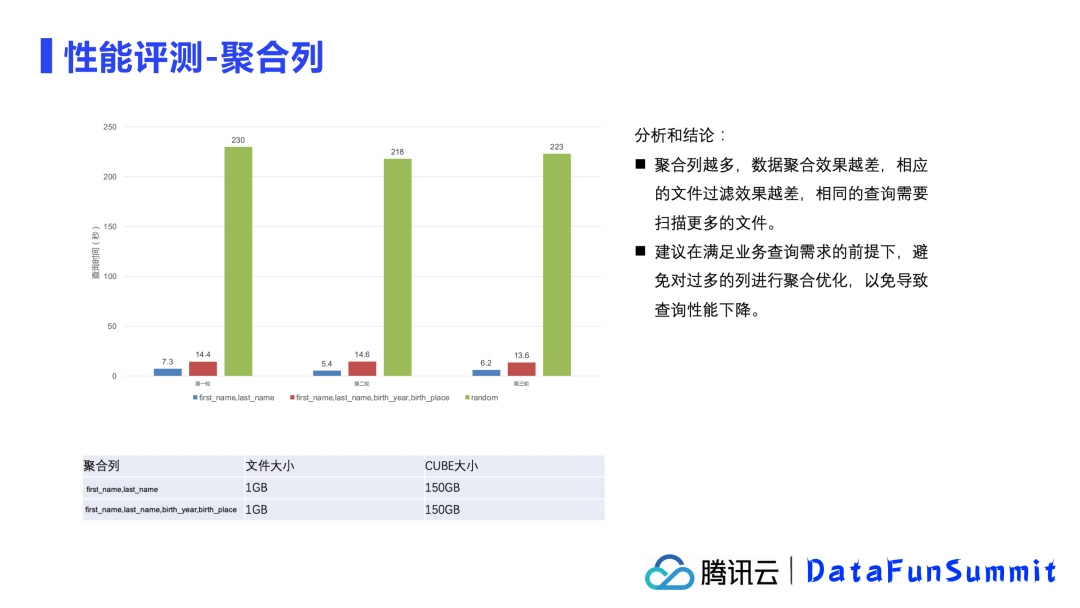
测试结果显示,聚合列越多,效果越差,相应的文件过滤效果越差,因为相同的查询需要扫描更多的文件,但是相比于组织优化前查询效率还是有显著提升的。
因此建议在满足业务需求的前提下,避免对过多的列进行聚合优化。
2. 关键参数测试-输出文件大小
接下来,我们限定了聚合列和CUBE大小,设置不同的输出文件大小来测试查询效率。
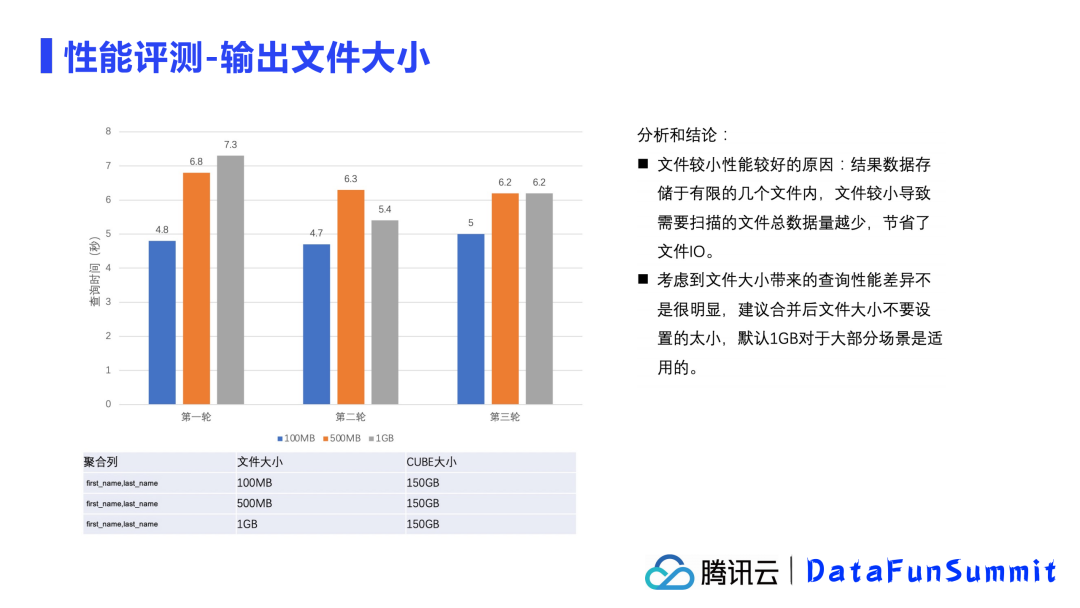
从结果上来看,文件输出大小对查询效率的影响并不大,因为数据较为集中,小文件的数据总量更少,节省了文件IO,所以查询效率要更好些。但是并不建议合并后的文件大小设计的太小,小文件数量的增加很容易出现文件扫描数量的增加,这个平衡不易把控,所以更建议默认1G的输出大小比较合适大部分场景。
3. 关键参数测试-CUBE大小
我们限定了聚合列和输出文件大小,设置不同的CUBE大小来测试查询效率。
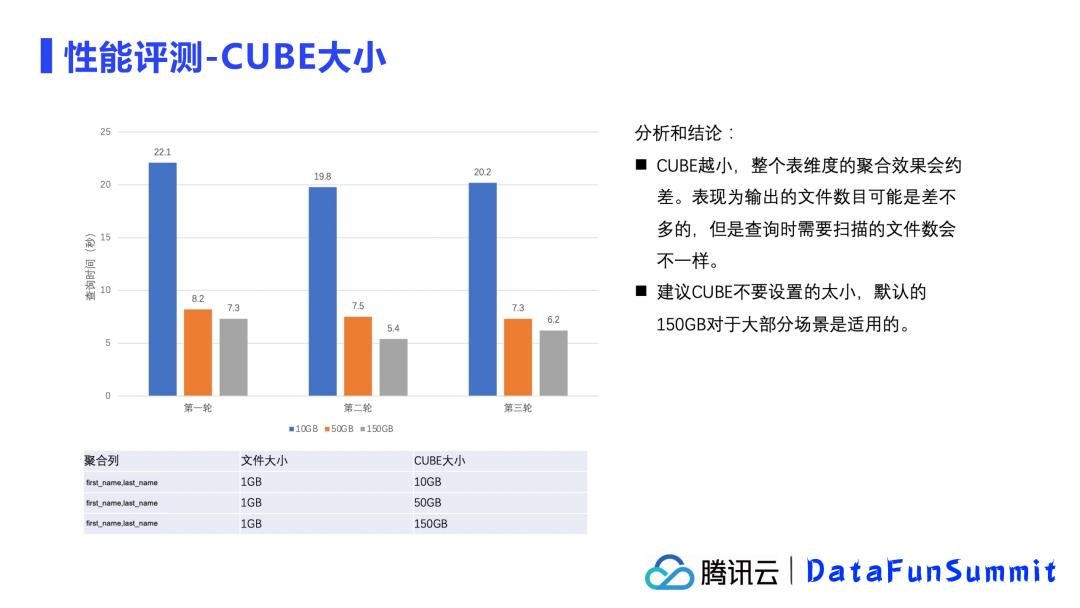
从测试结果来看,CUBE越小,性能越差。但CUBE设置的如果很大,反而容易在增量OPTIMIZE的时候,导致需要读取大量的数据来满足小部分数据增量的优化。所以建议还是使用默认配置,使用150G的CUBE较为均衡,对大部分场景是更为适用的。
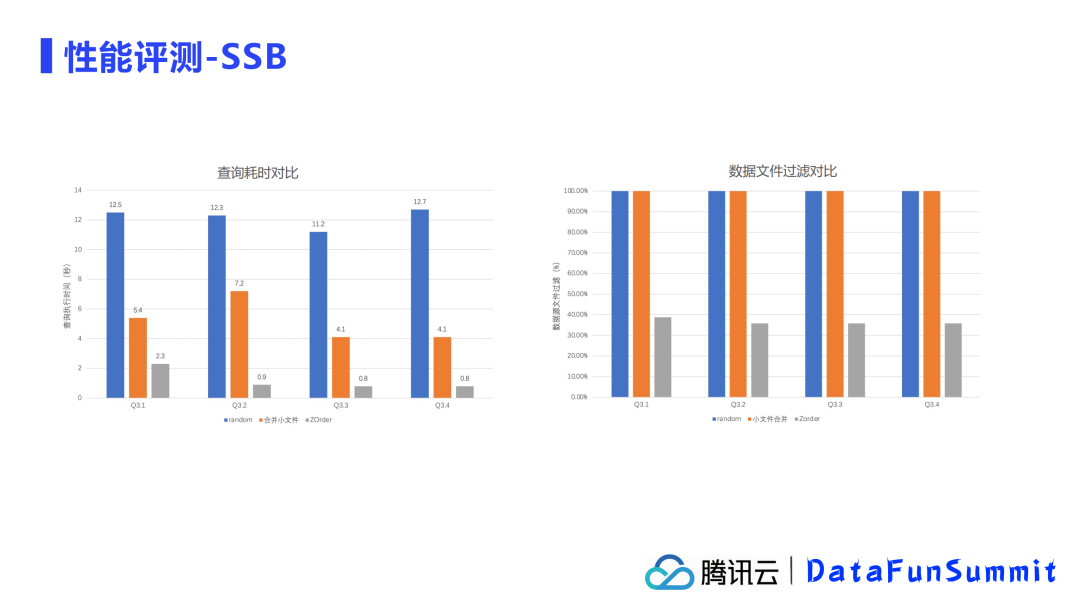
4. SSB基准测试
SSB测试是基于Kyligence官方提供的开源SSB(Star Schema Benchmark)压测工具,对其中的查询做了部分改造,主要选取使用Q3.1到Q3.4进行测试。

SSB测试的配置:

性能结果:
查询耗时方面:经过ZOrder排序后,查询耗时基本在1s以下,相比于不做任何优化的情况下,1w个小文件总查询耗时在12s以上,如果单纯只做小文件合并,查询耗时在4-7s之间,由此看到数据组织优化带来的效果是非常明显的。
数据文件过滤:不论是最初的状态还是合并小文件后,扫描的数据文件都是全表扫描,没有区别,但是ZOrder数据组织优化后,可以过滤掉大量的数据文件,进一步加速查询效率。
腾讯Iceberg的未来规划是:
提升数据持续接入的能力;
提升数据查询性能,包括存算分离的场景,索引支持等;
提升可运维性;
提升系统扩展,包括接入新的计算引擎,集成云上的catalog等。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“数据分析” 就可以获取《数据分析专知资料》专知下载链接







