数据中台与湖仓一体能碰出怎样的火花?网易数帆实时数据湖Arctic的新探索

数据从离线到实时是当前一个很大的趋势,但要建设实时数据、应用实时数据还面临两个难题。首先是实时和离线的技术栈不统一,导致系统和研发重复投入,在这之上的数据模型、代码也不能统一;其次是缺少数据治理,实时数据通常没有纳入数据中台管理,没有建模规范、数据质量差。针对这两个问题,网易数帆近日推出了实时数据湖引擎 Arctic。据介绍,Arctic 具备实时数据更新和导入的能力,能够无缝对接数据中台,将数据治理带入实时领域,同时支持批量查询和增量消费,可以做到流表和批表的一体。
这是作为网易公司基础软件团队的网易数帆首次对外发布在湖仓一体方向的进展,同时宣布的还有网易数帆有数实时数据中台战略。为了深入了解网易数帆在湖仓一体方向的探索和思考,以及实时数据湖引擎 Arctic 的设计思路和产品定位,InfoQ 采访了网易数帆平台开发专家马进,围绕以上问题逐一展开探讨。
湖仓一体(Lakehouse)最初指的是数据湖和数据仓库融合、兼具两者优点的新兴数据架构,但如今它已经不只是一个纯粹的技术概念,而是被赋予了更多与厂商产品层面相关的含义。在湖仓一体越来越火的同时,不同厂商也为它做出了各自的解读。在进一步探讨网易的湖仓一体实践之前,我们有必要先了解一下网易数帆是怎么理解“湖仓一体”的。
网易数帆团队开展湖仓一体工作主要源于现实应用场景中的一个痛点,即在大数据场景下的实时数据和离线数据的处理链路是割裂开的,而且实时数据和离线数据的存储也分别采用了两套不同的存储方案。一方面,重复建设和维护的成本比较大,另一方面,双方的研究成果也没有得到很好的复用。所以,团队一开始的目标其实是为了实现流批一体,也就是将实时数据和离线数据的处理和存储统一起来。
那为什么后面演变成湖仓一体呢?马进将流批一体划分为三个层次,分别是存储流批一体、开发流批一体和工具流批一体,并给出了这样一个等式:
“存储流批一体 = 湖仓一体 = 基于数据湖实现所有数仓功能”
离线数仓存储从本质上来讲,对应的就是数据湖技术,比如 Hadoop 生态的 Hive;相应的,实时数仓对应的就是传统数仓所具备的技术能力,像 Greenplum、Teradata、Oracle 这样的商用数据库,其实都具备流式更新和 ACID 的能力,可以完成一些实时报表的工作。网易数帆团队希望让基于数据湖概念的离线数仓技术具备实时计算的能力以及 ACID 的保障,也就是具备传统数仓的能力,因此,数据湖和传统数仓各项能力的结合,就是网易数帆团队要做的湖仓一体。基于这个目标,网易数帆打造了实时数据湖引擎 Arctic。

从实现路径来看,Arctic 的原始需求是基于数据湖解决“仓”的问题,团队对它的规划是先要具备“仓”的功能,“仓”的相关工作做好后,再去延展实现“湖”的功能。
除了湖仓一体,InfoQ 注意到,此前网易数帆还多次在公开场合提到另一个概念,即逻辑数据湖。网易数据科学中心总监、网易数帆有数产品总经理余利华曾在接受 InfoQ 采访时表示,逻辑数据湖是一种性价比更高的方式。这也给我们带来了一些疑惑:逻辑数据湖这个概念因什么而出现?它和湖仓一体、数据中台之间的关系要怎么理解?
马进表示,逻辑数据湖与湖仓一体是同一场景下的两个解决方案,本质上来说都是为中台服务的。逻辑数据湖是“物理分散、逻辑统一”,而湖仓一体是“物理统一”,二者是同一问题下的两个分支。
数据中台提供的是一套数据治理和数据研发的方法论,主要面向业务,其中的数据建模、数据研发包括数据运维,它们的治理体系是一套。但是从中台模块产品往下看,就会有不同方案的拆分。
其中,逻辑数据湖比较尊重业务以往的历史负担,比如之前用了 Greenplum、Oracle 这种数据仓库,希望数据中台能够直接基于这些数据仓库建设,不做数据迁移。从业务方来看,数据建模、数据开发与中台的治理体系是一套,但底层的数据存储可以不同。逻辑数据湖尝试用技术把一个个数据孤岛打通,比如对不同的数据仓库做联邦 Join,可以认为它是为了解决这种不统一的一个方案。“物理分散”,即底层的存储可以分开,但“逻辑统一”,上层的中台逻辑是统一的。
据了解,逻辑数据湖方案主要是为了满足网易数帆部分企业客户的需求,网易集团内部其实没有太多这样的负担,甚至可以说这种负担几乎没有,因为网易内部一开始就是基于 Hadoop 自建数据湖去实现的。但对很多企业客户来说,他们以前采购了不同的数据库,后来要构建自己的数据湖和数据中台体系,网易数帆就给他们提供了逻辑数据湖的方案,客户可以继续使用原有方案,同时网易数帆给他们提供一个整套的中台入口,统一管理不同的数据孤岛。这是逻辑数据湖主要适用的场景。
相比较之下,湖仓一体的解决方案更加彻底。对于没有历史负担的业务场景或企业客户,他们所有新建业务都可以基于湖仓一体的方案来建设。基于湖仓一体方案,底层存储在物理上就是统一的,都基于数据湖,上层也必然是统一的。
可以认为,这两个方案都是服务于整个中台,去构建一个统一的数据中台的治理逻辑。马进解释道,两种方案的收益不同,逻辑数据湖可以让用户快速上手,更好地覆盖企业的历史负担;而湖仓一体可以用更低的成本去解决业务上的痛点,如果把时间线拉长,未来当云计算更大范围普及之后,基于云端对象存储建设数据湖,跟使用传统商用数据库或商用数仓相比,节省的成本可能高达几十倍甚至几百倍。
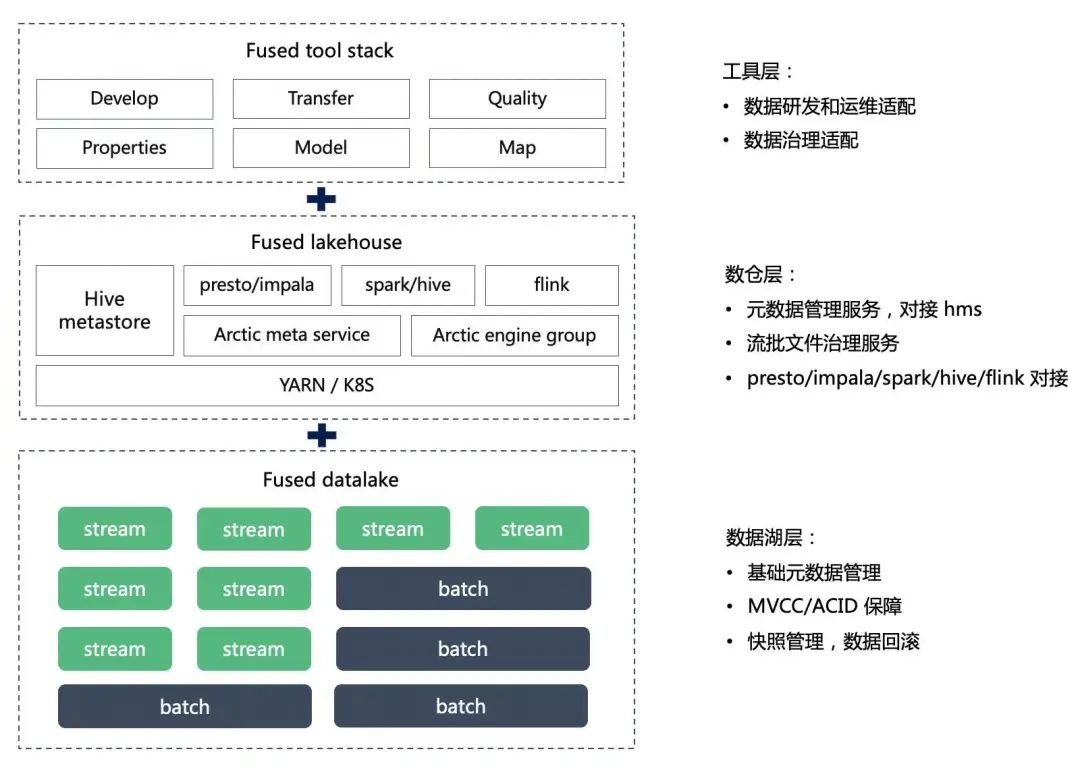
网易数帆建设湖仓一体的核心技术原理与 Hive 离线数仓方案最大的不同是对数据的管理粒度更加细化,Hive 的管理粒度在 Partition 级别,而网易数帆湖仓一体方案的管理粒度细化到文件。由于上层承接数据中台体系,湖仓一体需要为上层提供体系化的文件管理方案,涵盖文件治理和文件合并等功能,因此具备细粒度的文件管理能力是首要需求。
经过调研,团队最终选择使用 Apache Iceberg,主要考虑是因为 Iceberg 本身的元数据管理是面向文件的,有非常全的 manifest 机制,可以把表中的所有文件管理起来,Iceberg 作为底座提供了 ACID 的事务保证以及 MVCC 功能,可以保证数据的一致性,同时又具有可扩展性。
在 Iceberg 的基础上,团队又自研了实时摄取、文件索引、数据合并,以及一整套元数据管理服务。
据马进介绍,在最早做技术选型的时候,团队也调研过与 Iceberg 同类型的开源项目 Apache Hudi 和 Delta Lake,但最终都因为一些原因而放弃选用。在做调研时,Hudi 还是相对比较封闭的状态(它对自己的定位是 Spark 的一个 Lib,去年年底到今年才开始真正把支持 Flink 作为优先级比较高的工作),而网易数帆需要一个开放的解决方案来适配高度定制化需求。
除此之外,也有一些技术细节的考量。比如数据格式方面的问题,Hudi 的文件索引采用的是 Bloomfilter 以及 HBase 的机制,这两种机制都不是特别理想,HBase 需要引入第三方 KV 数据库,对商业输出不利,而 Bloomfilter 比较重,会让实时性大打折扣,因此都不太适合网易数帆的技术选型。网易数帆对 Arctic 核心功能的想法和设计,也跟 Hudi 有出入。
而没选 Delta Lake 则是因为它对实时性并不是看得很重,马进团队通过研究相关论文发现,Delta Lake 更多还是把 Spark 的生态作为第一优先级,这与团队做湖仓一体的目标还是有一些区别。
相比之下,Iceberg 相对更开放,对计算引擎的集成、对上层元数据的集成、对不同系统的集成都做得比较好,可以满足团队高度定制化的需求。因此团队最终选择了 Iceberg,能更好地落实自己的想法,并做出网易数帆独有的功能特色。
虽然 Arctic 以 Iceberg 为底座,但马进认为,从社区定位来看,Hudi 才是跟 Arctic 最像的。数据湖仓有一个非常重要的功能,即能够基于主键进行行级更新,Hudi 在功能上与 Arctic 比较匹配,只是在核心设计上二者存在分歧,在实时入湖这一方面 Hudi 也最具有代表性。所以 Arctic 在做性能对比测试的时候,也是拿 Hudi 来对比,而不是 Iceberg。
实际上,网易数帆团队在一开始做 Arctic 这个产品时,并不打算绑定任何一个开源的数据湖方案,包括 Iceberg。
最初团队更希望基于数据湖做一个流批一体的湖仓,通过制定一个管理 Base 数据(即存量数据)和 Change 数据(即增量数据或实时数据)的方案,做到对两种数据的解耦,不管底层使用什么数据湖技术,无论 Iceberg 还是 Delta Lake,对外暴露的都是同一套湖仓一体方案。这是 Arctic 最初的定位,即不跟任何一家数据湖基座做高度绑定,但要做到这一点需要极高的研发投入,很难一步到位。因此前期团队对于 Arctic 的定位首先是满足网易湖仓一体的业务目标,把上层实时入湖功能涉及的读合并、异步合并、元数据服务、小文件治理等等在一个数据湖基座上管理起来,有了数据湖的基座,就可以基于此再去做上层的服务,然后再考虑增加在不同数据湖上构建湖仓一体的能力。
这看起来似乎又在已经相当复杂的数据系统中增加了一个服务层,不过马进表示并非如此。首先做数据中台,本身就是在 Hive 之上加了一层;其次增加的这些功能实际上是引擎端的适配,会有一个单独的治理服务,而这个治理服务是偏中台的模块,可以认为是整套数据中台体系中的一部分。这个治理服务能够把湖仓的元数据管理起来,类似 Hive 中的 HMS,同时也可以做一些数据合并的规划,还能对接不同的计算引擎,比如 Presto、Impala、Spark SQL 以及 Flink。
据马进透露,团队预计会在明年 Q2 将 Arctic 开源出去。其实团队一直有在考虑如何将自研的东西贡献回开源社区。从去年开始,网易数帆团队就尝试跟一些头部互联网公司共建 Iceberg 社区,希望能引导社区往湖仓一体的方向去发展。但社区本身对发展方向有自己的规划,包括社区创始人前不久也已经从 Netflix 离职自己出来创业、围绕 Iceberg 成立了商业公司,想要推动社区往一定的方向走成本很高,进度也会比较慢。
因此网易数帆团队目前更希望先把所有的想法在 Arctic 上落实好,让整个湖仓一体方案运转起来,然后将做出来的成果开放出来,再进一步跟社区沟通,看哪些东西可以贡献回社区。马进认为,最重要的是希望 Arctic 至少能够在网易长期经营起来。
目前网易数帆已经有部分客户在使用 Arctic,集团内部也有不少业务接入了 Arctic。马进透露,根据前段时间中期汇报的统计数据,网易集团内部已经有大约 600TB 规模的数据在使用 Arctic,并且陆续有新的业务开始尝试。
按照数据来源,马进将 Arctic 的用户场景分为两大类,不同使用场景采用的数据架构不同,引入 Arctic 时使用的改造方案也有所不同。
第一类场景的数据主要来源于日志,比如网易云音乐、网易传媒,还有电商的部分数仓系统,他们的数据都以日志为主。对于日志数据,业务线在几年前已经构建了非常健全的 T+1 数据处理解决方案,现在他们希望将原有的 T+1 的离线业务改造成实时业务。但是改造成实时链路后,又担心数据的准确性,因为日志数据比较容易出现数据乱序和重复。针对这种日志型数据的场景,更多使用的是 Lambda 架构,Arctic 针对 Hive 提供了原地升级的方案,即将 Hive 的离线数仓表通过特定方式升级为 Arctic 表,升级后就可以通过实时计算引擎进行数据写入,而离线数仓还保持了批量写入的能力。Arctic 表会自动根据场景做实时和离线的切换来面对不同的业务场景。网易集团内部主推 Lambda 架构,因为集团内部日志型数据场景更多一些。
Kappa 架构则更多面向企业用户,像金融、制造业、物流等传统行业,他们的数据不管是实时数据还是全量数据,主要来源是数据库。数据库里存储的数据很少出现乱序重复的问题,相对比较准确,也有完整的机制保证数据一致性。这种情况通常不需要用离线链路来兜底,日常用一个实时链路就可以。但有时候也会出现数据库表变更的情况,比如增加一列或减少一列数据、数据表结构发生变化,或者一些数据出现了错误,需要大规模修正,这时就需要对原始数据进行批量计算回补,同时需要离线链路去发挥作用。
综上,网易集团内部主要进行 Lambda 架构的改造,而针对企业客户,主要的实践是 Kappa 架构。网易集团内部的互联网业务和传统企业客户的业务,数据处理的场景和方式不一样,不过两者没有绝对的界限,网易集团内部也有一些潜在的使用 Kappa 架构的场景,比如严选电商就有很多实时数据来自数据库的场景。
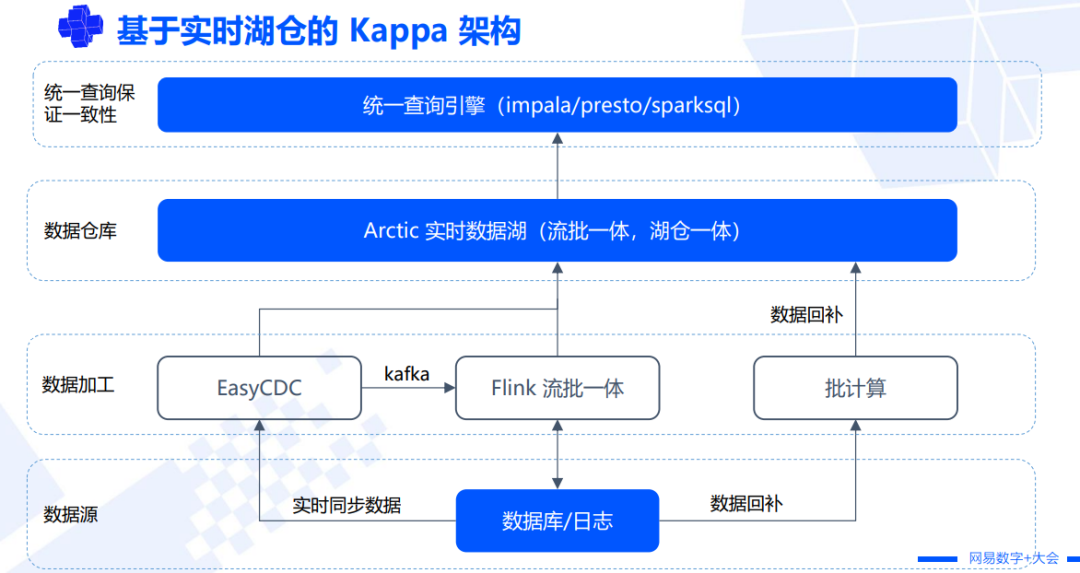
对于湖仓一体方案的实施和落地,Kappa 架构是最理想的方案,因为天然具备实时性,也没有历史负担,建设湖仓一体的成本低;而对于 Lambda 架构来说,就可能面临已有离线链路、但离线做的不够规范,本身就需要一定的改造,这种情况升级改造的成本会比较高,技术实现上也需要更多磨合。当前团队推动湖仓一体方案落地更多会选择一些基于 Kappa 架构的场景,Lambda 架构主要与集团内部大的业务共建,过程相对比较缓慢。
除了前面所说的历史负担问题,企业尝试采用湖仓一体技术还面临另一个挑战,就是组织上的问题。在马进看来,目前数据中台整个方案“离线”的基因很重,实时相对来说是一个比较独立的分支,而且实时计算不光用在大数据场景,在线场景也经常涉及。如果希望通过实时给整个数据中台赋能,就需要侵入到数据中台的架构体系里面去。这就涉及不同团队的磨合以及目标统一的问题,在推进上有一定的困难。这与前两年企业推行数据中台战略面临的挑战是类似的。
马进坦言,去年准备做湖仓一体的时候,就面临比较大的阻力,因为数据中台团队也有自己的规划,比如前面提到的逻辑数据湖,而湖仓一体是从另外一个角度去解决问题。这就需要公司的决策层在这件事情上有非常精准的判断并制定相应的战略目标。今年在网易数字 + 大会上正式宣布将实时数据中台作为战略来推进,是网易数帆在推进湖仓一体过程中有优势的一点。
对于网易数帆来说,湖仓一体(即存储的流批一体)是最终实现流批一体必经的一步,最终愿景是用一个逻辑一套代码去覆盖离线和实时两个场景。如果实时和离线是两套存储、用到两张表,就不可能用一套代码解决,因此要优先解决存储的流批一体,然后再基于此做开发的流批一体。把工具和团队统一之后,中台的模块如数据模型、数据资产、数据质量等等也都可以做流批一体了,从原先只有离线的功能,到具备实时功能,这被称为工具流批一体,更确切的说法是中台模块的流批一体,最终给前端业务呈现的就是实时数据中台。
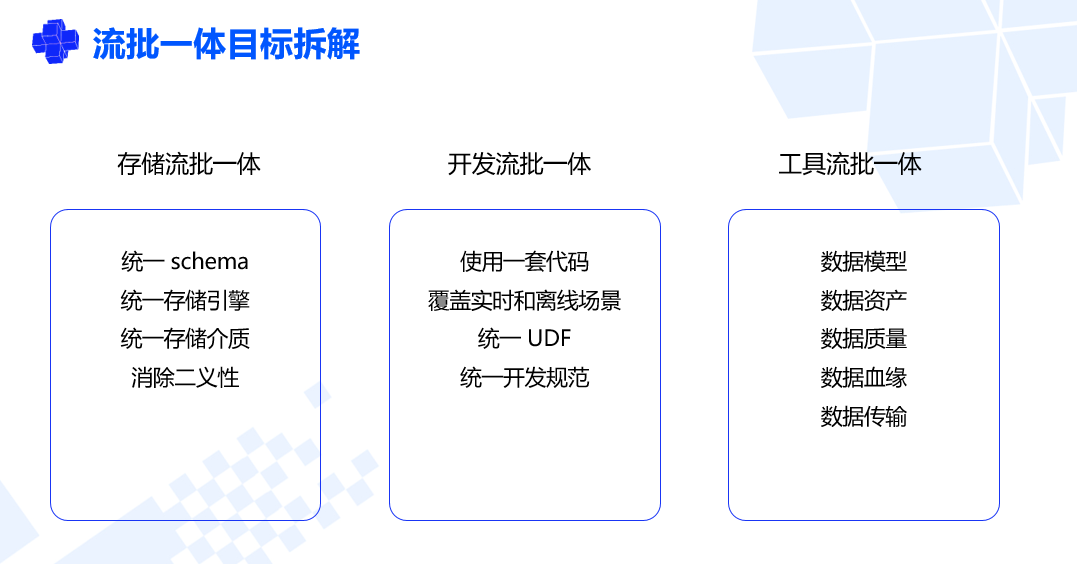
流批一体是网易数帆团队一直以来的战术方向,即做到大数据平台的实时化,而不是将实时计算独立出来做。前述流批一体的三个层次都是网易大数据平台未来的重点改进方向。
针对存储的流批一体,现在已经有实时数据湖引擎 Arctic,后续团队的工作重点主要包括性能优化和自研特色功能,比如实时数据摄取、数据合并、元数据管理服务等,整体有一个长期的研究规划。未来 Arctic 也将适配更多计算引擎,除了已经适配的 Flink、Spark,Impala 的适配工作也在进行中,明年 Arctic 开源的时候,也会做好 Presto 的适配。
同时,开发流批一体和工具流批一体方面的工作也在紧锣密鼓地展开。
开发的流批一体主要是负责 Flink 的小团队在跟进,目前主要在实践阶段。马进表示,计算流批一体的社区成熟度要比存储流批一体好很多,网易更多是在业务侧实践,争取明年可以推出开发流批一体的工具和平台。工具流批一体则是整个数据中台团队在推进,整体进度已经完成了 20%~30%,不过暂时还没有对外发布。
在马进看来,未来实时和离线技术必然会收敛到一起,从技术实现来看相对乐观,目前网易数帆也已经有相对应的解决方案,但大规模的业务落地需要更多时间。至少还需要两年时间,才会有更多业务把流批一体和湖仓一体作为一个比较标准的方案,过程的快慢与每个业务自身对存算分离的诉求的急迫程度有关。
客观来说,现阶段湖仓一体技术在开源技术里还不是很成熟。马进表示,企业需要对大方向保持关注,但到底要不要采用,还得看企业的发展情况。如果企业的自研能力相对缺乏,可以继续观望,等待更加成熟的解决方案出现。在他看来,现在的解决方案大多数都还处在体验尝鲜的阶段,远没有达到广泛应用的阶段。对于有一定技术实力的企业,可以先基于集团内部场景推广使用,这也是很多头部企业的做法,比如阿里、腾讯以及字节,网易也是先基于集团内部场景孵化一些解决方案。
不过网易数帆的工作重点是给企业做私有化解决方案,相比之下,阿里和腾讯的工作重点是公有云,更希望能将客户的解决方案垄断在自己的生态之中,而网易数帆则更倾向于背靠开源,然后强于开源,做技术的破壁者。
过去一年,围绕湖仓一体和流批一体话题,InfoQ 采访了数位大数据平台领域专家,虽然每家公司的解读和实现路径各有不同,但对于湖仓一体和流批一体未来长期的发展趋势基本能够达成一致。
从长远来看,不管是阿里云、腾讯云还是 Databricks,未来的湖仓一体发展趋势都是趋同的,即基于廉价的存储设施,把数仓的能力建设好,短期内可能由于公司发展战略及自身定位的差异,研究方向存在一定差异。
虽然如此,技术更迭的过程仍免不了曲折。对于很多企业来说,之前已经做了实时计算并构建出一套比较独立的架构,并没有很强的动力去做架构升级和更新。这有点类似于过去数据库领域常常提到的“自己革自己命”,数据中台也面临这样的困扰。但以发展的眼光来看,这样的突破非常有必要。如果进行了革命,最终实时和离线统一到一起,未来大数据平台会更加简单精练,工具的专业门槛会越来越高,但使用成本会越来越低,用户使用工具的投入走向收敛。
大数据平台以及数据业务全面的实时化,必然会对当前的生产关系以及组织架构带来一定的调整诉求。这是一个自我改革的驱动,需要企业有一定的魄力。
采访嘉宾介绍:
马进,网易数帆平台开发专家,网易数据科学中心在线数据和实时计算团队负责人,负责网易集团分布式数据库,数据传输平台,实时计算平台,实时数据湖等项目,长期从事中间件、大数据基础设施方面的研究和实践,目前带领团队聚焦在流批一体、湖仓一体的平台方案和技术演进上。
点击底部阅读原文访问 InfoQ 官网,获取更多湖仓一体精彩内容!
流行20年的架构设计原则SOLID可能已经不适合微服务了
软件工程师年满 40 岁,下一步怎么走?
曝腾讯天美员工税后收入250万,月均20万;传阿里CEO张勇要放权;“人人影视字幕组”侵权案宣判,被告人获刑三年半 | Q资讯
逃离被微软支配的恐惧,.NET开发者们Fork了一个开源分支
InfoQ 100 位优质创作者签约计划第二季火热进行中!欢迎各位同学踊跃报名~ 签约豪华大礼包、专属身份标志、百万流量扶持等好礼,等您来拿!
活动链接:http://gk.link/a/10KyO

点个在看少个 bug 👇