MySQL 深潜 - 一文详解 MySQL Data Dictionary

一 背景
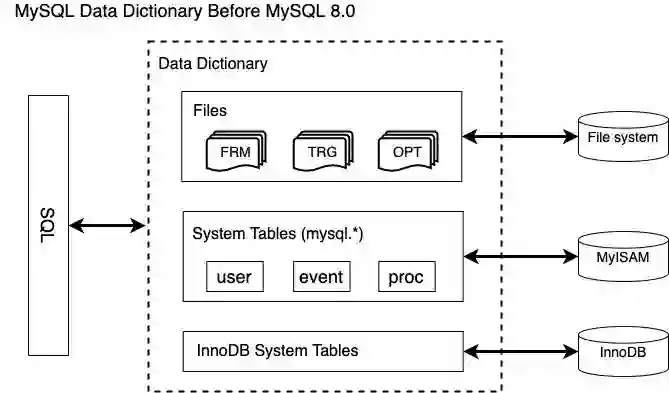
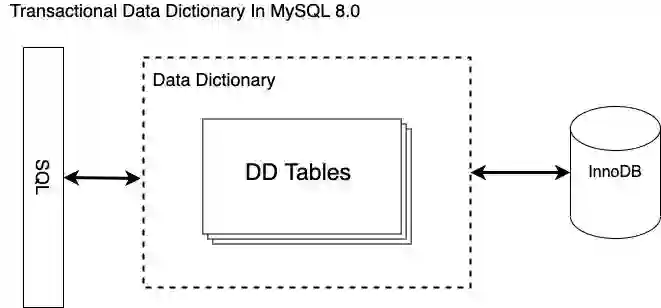
二 整体架构
三 metadata 在内存和引擎层面的表示
1 Table_impl
class Table_impl : public Abstract_table_impl, virtual public Table {// Fields.Object_id m_se_private_id;String_type m_engine;String_type m_comment;// - Partitioning related fields.enum_partition_type m_partition_type;String_type m_partition_expression;String_type m_partition_expression_utf8;enum_default_partitioning m_default_partitioning;// References to tightly-coupled objects.Index_collection m_indexes;Foreign_key_collection m_foreign_keys;Foreign_key_parent_collection m_foreign_key_parents;Partition_collection m_partitions;Partition_leaf_vector m_leaf_partitions;Trigger_collection m_triggers;Check_constraint_collection m_check_constraints;};
class Column_impl : public Entity_object_impl, public Column {// Fields.enum_column_types m_type;bool m_is_nullable;bool m_is_zerofill;bool m_is_unsigned;bool m_is_auto_increment;bool m_is_virtual;bool m_default_value_null;String_type m_default_value;// References to tightly-coupled objects.Abstract_table_impl *m_table;};
class Partition_impl : public Entity_object_impl, public Partition {// Fields.Object_id m_parent_partition_id;uint m_number;Object_id m_se_private_id;String_type m_description_utf8;String_type m_engine;String_type m_comment;Properties_impl m_options;Properties_impl m_se_private_data;// References to tightly-coupled objects.Table_impl *m_table;const Partition *m_parent;Partition_values m_values;Partition_indexes m_indexes;Table::Partition_collection m_sub_partitions;};
root@localhost:test 8.0.18-debug> SHOW CREATE TABLE mysql.tables\G*************************<strong> 1. row </strong>*************************Table: tablesCreate Table: CREATE TABLE `tables` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`schema_id` bigint(20) unsigned NOT NULL,`name` varchar(64) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,`type` enum('BASE TABLE','VIEW','SYSTEM VIEW') COLLATE utf8_bin NOT NULL,`engine` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`mysql_version_id` int(10) unsigned NOT NULL,`row_format` enum('Fixed','Dynamic','Compressed','Redundant','Compact','Paged') COLLATE utf8_bin DEFAULT NULL,`collation_id` bigint(20) unsigned DEFAULT NULL,`comment` varchar(2048) COLLATE utf8_bin NOT NULL,`hidden` enum('Visible','System','SE','DDL') COLLATE utf8_bin NOT NULL,`options` mediumtext COLLATE utf8_bin,`se_private_data` mediumtext COLLATE utf8_bin,`se_private_id` bigint(20) unsigned DEFAULT NULL,`tablespace_id` bigint(20) unsigned DEFAULT NULL,`partition_type` enum('HASH','KEY_51','KEY_55','LINEAR_HASH','LINEAR_KEY_51','LINEAR_KEY_55','RANGE','LIST','RANGE_COLUMNS','LIST_COLUMNS','AUTO','AUTO_LINEAR') COLLATE utf8_bin DEFAULT NULL,`partition_expression` varchar(2048) COLLATE utf8_bin DEFAULT NULL,`partition_expression_utf8` varchar(2048) COLLATE utf8_bin DEFAULT NULL,`default_partitioning` enum('NO','YES','NUMBER') COLLATE utf8_bin DEFAULT NULL,`subpartition_type` enum('HASH','KEY_51','KEY_55','LINEAR_HASH','LINEAR_KEY_51','LINEAR_KEY_55') COLLATE utf8_bin DEFAULT NULL,`subpartition_expression` varchar(2048) COLLATE utf8_bin DEFAULT NULL,`subpartition_expression_utf8` varchar(2048) COLLATE utf8_bin DEFAULT NULL,`default_subpartitioning` enum('NO','YES','NUMBER') COLLATE utf8_bin DEFAULT NULL,`created` timestamp NOT NULL,`last_altered` timestamp NOT NULL,`view_definition` longblob,`view_definition_utf8` longtext COLLATE utf8_bin,`view_check_option` enum('NONE','LOCAL','CASCADED') COLLATE utf8_bin DEFAULT NULL,`view_is_updatable` enum('NO','YES') COLLATE utf8_bin DEFAULT NULL,`view_algorithm` enum('UNDEFINED','TEMPTABLE','MERGE') COLLATE utf8_bin DEFAULT NULL,`view_security_type` enum('DEFAULT','INVOKER','DEFINER') COLLATE utf8_bin DEFAULT NULL,`view_definer` varchar(288) COLLATE utf8_bin DEFAULT NULL,`view_client_collation_id` bigint(20) unsigned DEFAULT NULL,`view_connection_collation_id` bigint(20) unsigned DEFAULT NULL,`view_column_names` longtext COLLATE utf8_bin,`last_checked_for_upgrade_version_id` int(10) unsigned NOT NULL,PRIMARY KEY (`id`),UNIQUE KEY `schema_id` (`schema_id`,`name`),UNIQUE KEY `engine` (`engine`,`se_private_id`),KEY `engine_2` (`engine`),KEY `collation_id` (`collation_id`),KEY `tablespace_id` (`tablespace_id`),KEY `type` (`type`),KEY `view_client_collation_id` (`view_client_collation_id`),KEY `view_connection_collation_id` (`view_connection_collation_id`),CONSTRAINT `tables_ibfk_1` FOREIGN KEY (`schema_id`) REFERENCES `schemata` (`id`),CONSTRAINT `tables_ibfk_2` FOREIGN KEY (`collation_id`) REFERENCES `collations` (`id`),CONSTRAINT `tables_ibfk_3` FOREIGN KEY (`tablespace_id`) REFERENCES `tablespaces` (`id`),CONSTRAINT `tables_ibfk_4` FOREIGN KEY (`view_client_collation_id`) REFERENCES `collations` (`id`),CONSTRAINT `tables_ibfk_5` FOREIGN KEY (`view_connection_collation_id`) REFERENCES `collations` (`id`)) /*!50100 TABLESPACE `mysql` */ ENGINE=InnoDB AUTO_INCREMENT=549 DEFAULT CHARSET=utf8 COLLATE=utf8_bin STATS_PERSISTENT=0 ROW_FORMAT=DYNAMIC1 row in set (0.00 sec)
通过以上 mysql.tables 的表定义可以获得存储引擎中实际存储的元信息字段。DD tables 包括 tables、schemata、columns、column_type_elements、indexes、index_column_usage、foreign_keys、foreign_key_column_usage、table_partitions、table_partition_values、index_partitions、triggers、check_constraints、view_table_usage、view_routine_usage 等。
Storage_adapter::get()// 根据访问对象类型,将依赖的 DD tables 加入到 open table list 中|--Open_dictionary_tables_ctx::register_tables<T>()|--Table_impl::register_tables()|--Open_dictionary_tables_ctx::open_tables() // 调用 Server 层接口打开所有表|--Raw_table::find_record() // 直接调用 handler 接口根据传入的 key(比如表名)查找记录|--handler::ha_index_read_idx_map() // index read// 从读取到的 record 中解析出对应属性,调用 field[field_no]->val_xx() 函数|--Table_impl::restore_attributes()// 通过调用 restore_children() 函数从与该对象关联的其他 DD 表中根据主外键读取完整的元数据定义|--Table_impl::restore_children()|--返回完整的 DD cache 对象
class Tables : public Entity_object_table_impl {enum enum_fields {FIELD_ID,FIELD_SCHEMA_ID,FIELD_NAME,FIELD_TYPE,FIELD_ENGINE,FIELD_MYSQL_VERSION_ID,FIELD_ROW_FORMAT,FIELD_COLLATION_ID,FIELD_COMMENT,FIELD_HIDDEN,FIELD_OPTIONS,FIELD_SE_PRIVATE_DATA,FIELD_SE_PRIVATE_ID,FIELD_TABLESPACE_ID,FIELD_PARTITION_TYPE,FIELD_PARTITION_EXPRESSION,FIELD_PARTITION_EXPRESSION_UTF8,FIELD_DEFAULT_PARTITIONING,FIELD_SUBPARTITION_TYPE,FIELD_SUBPARTITION_EXPRESSION,FIELD_SUBPARTITION_EXPRESSION_UTF8,FIELD_DEFAULT_SUBPARTITIONING,FIELD_CREATED,FIELD_LAST_ALTERED,FIELD_VIEW_DEFINITION,FIELD_VIEW_DEFINITION_UTF8,FIELD_VIEW_CHECK_OPTION,FIELD_VIEW_IS_UPDATABLE,FIELD_VIEW_ALGORITHM,FIELD_VIEW_SECURITY_TYPE,FIELD_VIEW_DEFINER,FIELD_VIEW_CLIENT_COLLATION_ID,FIELD_VIEW_CONNECTION_COLLATION_ID,FIELD_VIEW_COLUMN_NAMES,FIELD_LAST_CHECKED_FOR_UPGRADE_VERSION_ID,NUMBER_OF_FIELDS // Always keep this entry at the end of the enum};};
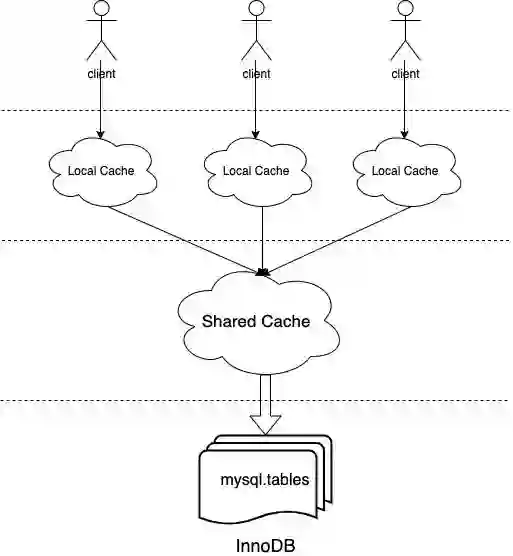
四 多级缓存
template <typename T>class Multi_map_base {private:Element_map<const T *, Cache_element<T>> m_rev_map; // Reverse element map.Element_map<typename T::Id_key, Cache_element<T>>m_id_map; // Id map instance.Element_map<typename T::Name_key, Cache_element<T>>m_name_map; // Name map instance.Element_map<typename T::Aux_key, Cache_element<T>>m_aux_map; // Aux map instance.};template <typename K, typename E>class Element_map {public:typedef std::map<K, E *, std::less<K>,Malloc_allocator<std::pair<const K, E *>>>Element_map_type; // Real map type.private:Element_map_type m_map; // The real map instance.std::set<K, std::less<K>,Malloc_allocator<K>>m_missed; // Cache misses being handled.};
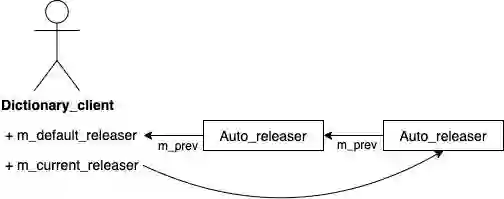
class Dictionary_client {Object_registry m_registry_committed; // Registry of committed objects.Object_registry m_registry_uncommitted; // Registry of uncommitted objects.Object_registry m_registry_dropped; // Registry of dropped objects.THD *m_thd; // Thread context, needed for cache misses.Auto_releaser m_default_releaser; // Default auto releaser.Auto_releaser *m_current_releaser; // Current auto releaser.};class Object_registry {std::unique_ptr<Local_multi_map<Abstract_table>> m_abstract_table_map;std::unique_ptr<Local_multi_map<Charset>> m_charset_map;std::unique_ptr<Local_multi_map<Collation>> m_collation_map;std::unique_ptr<Local_multi_map<Column_statistics>> m_column_statistics_map;std::unique_ptr<Local_multi_map<Event>> m_event_map;std::unique_ptr<Local_multi_map<Resource_group>> m_resource_group_map;std::unique_ptr<Local_multi_map<Routine>> m_routine_map;std::unique_ptr<Local_multi_map<Schema>> m_schema_map;std::unique_ptr<Local_multi_map<Spatial_reference_system>>m_spatial_reference_system_map;std::unique_ptr<Local_multi_map<Tablespace>> m_tablespace_map;};template <typename T>class Local_multi_map : public Multi_map_base<T> {};
class Shared_dictionary_cache {Shared_multi_map<Abstract_table> m_abstract_table_map;Shared_multi_map<Charset> m_charset_map;Shared_multi_map<Collation> m_collation_map;Shared_multi_map<Column_statistics> m_column_stat_map;Shared_multi_map<Event> m_event_map;Shared_multi_map<Resource_group> m_resource_group_map;Shared_multi_map<Routine> m_routine_map;Shared_multi_map<Schema> m_schema_map;Shared_multi_map<Spatial_reference_system> m_spatial_reference_system_map;Shared_multi_map<Tablespace> m_tablespace_map;};template <typename T>class Shared_multi_map : public Multi_map_base<T> {private:static const size_t initial_capacity = 256;mysql_mutex_t m_lock; // Single mutex to lock the map.mysql_cond_t m_miss_handled; // Broadcast a miss being handled.Free_list<Cache_element<T>> m_free_list; // Free list.std::vector<Cache_element<T> *>m_element_pool; // Pool of allocated elements.size_t m_capacity; // Total capacity, i.e., if the// number of elements exceeds this// limit, shrink the free list.}
// Get a dictionary object.template <typename K, typename T>bool Dictionary_client::acquire(const K &key, const T **object,bool *local_committed,bool *local_uncommitted) {// Lookup in registry of uncommitted objectsT *uncommitted_object = nullptr;bool dropped = false;acquire_uncommitted(key, &uncommitted_object, &dropped);...// Lookup in the registry of committed objects.Cache_element<T> *element = NULL;m_registry_committed.get(key, &element);...// Get the object from the shared cache.if (Shared_dictionary_cache::instance()->get(m_thd, key, &element)) {DBUG_ASSERT(m_thd->is_system_thread() || m_thd->killed ||m_thd->is_error());return true;}}
// Get a wrapper element from the map handling the given key type.template <typename T>template <typename K>bool Shared_multi_map<T>::get(const K &key, Cache_element<T> **element) {Autolocker lock(this);*element = use_if_present(key);if (*element) return false;// Is the element already missed?if (m_map<K>()->is_missed(key)) {while (m_map<K>()->is_missed(key))mysql_cond_wait(&m_miss_handled, &m_lock);*element = use_if_present(key);// Here, we return only if element is non-null. An absent element// does not mean that the object does not exist, it might have been// evicted after the thread handling the first cache miss added// it to the cache, before this waiting thread was alerted. Thus,// we need to handle this situation as a cache miss if the element// is absent.if (*element) return false;}// Mark the key as being missed.m_map<K>()->set_missed(key);return true;}
{if (thd->dd_client()->drop(table_def)) goto cleanup2;table_def = nullptr;DEBUG_SYNC_C("alter_table_after_dd_client_drop");// Reset check constraint's mode.reset_check_constraints_alter_mode(altered_table_def);if ((db_type->flags & HTON_SUPPORTS_ATOMIC_DDL)) {/*For engines supporting atomic DDL we have delayed storing newtable definition in the data-dictionary so far in order to avoidconflicts between old and new definitions on foreign key names.Since the old table definition is gone we can safely store newdefinition now.*/if (thd->dd_client()->store(altered_table_def)) goto cleanup2;}}.../*If the SE failed to commit the transaction, we must rollback themodified dictionary objects to make sure the DD cache, the DDtables and the state in the SE stay in sync.*/if (res)thd->dd_client()->rollback_modified_objects();elsethd->dd_client()->commit_modified_objects();
PolarDB 是阿里巴巴自主研发的云原生分布式关系型数据库,于2020年进入Gartner全球数据库Leader象限,并获得了2020年中国电子学会颁发的科技进步一等奖。PolarDB 基于云原生分布式数据库架构,提供大规模在线事务处理能力,兼具对复杂查询的并行处理能力,在云原生分布式数据库领域整体达到了国际领先水平,并且得到了广泛的市场认可。在阿里巴巴集团内部的最佳实践中,PolarDB还全面支撑了2020年天猫双十一,并刷新了数据库处理峰值记录,高达1.4亿TPS。欢迎有志之士加入我们,简历请投递到hope.lb@alibaba-inc.com,期待与您共同打造世界一流的下一代云原生分布式关系型数据库。
参考
低代码开发者征文召集令!参与低代码话题相关投稿,谈谈“你对低代码的理解”,“利用低代码工具真的实现降本增效吗”等话题。活动准备了Air Pods Pro,机械键盘,移动硬盘,阿里云定制书包等精美礼品等你来领!快来参与吧!
点击阅读原文即可参加活动~
登录查看更多
相关内容

专知会员服务
24+阅读 · 2022年3月24日




相关VIP内容
专知会员服务
24+阅读 · 2022年3月24日
相关资讯
相关论文