
注意力机制在推荐系统应用中的总结
作者 | 勿忘初心
链接 | https://zhuanlan.zhihu.com/p/151640509
编辑 | 机器学习与推荐算法
声明 | 未经原作者同意不得二次转载
摘要
1 引言
推荐系统是深度学习技术在商业社会的一项成功应用。通过从海量的数据中筛选出对用户最有价值的数据,提高整个商业流程的效率。大多数推荐模型都要涉及到对成段文本信息的处理,比如电商平台时用户的评论内容、新闻推荐中的新闻内容等。而注意力机制(attention)可以高效的提取文本中的重点,近几年在NLP领域任务中取得了令人侧目的效果,并涌现出了一大批利用attention提高推荐系统性能的研究工作。将attention运用在推荐系统,大多数是从文本数据的处理出发,利用attention提取文本中的重点进行下游任务,如阿里巴巴的DIN[1],少数是利用了attention能够自动的发现输入特征的重点的这一特性,来优化传统的推荐模型,典型的工作比如注意力分解机(AFM)[2]。
本文首先介绍了所需的背景知识,然后对近年来结合attention的推荐模型进行了综述。根据现有工作的启发,本文还提出了如何利用attention来优化微软新闻推荐模型DRN[3]。最后,我们对现有的工作进行了总结,并讨论了结合attention的推荐模型的可行的研究方向。
2 背景知识
2.1 Attention
处理长文本的时候,使用RNN模型容易遗失掉长程信息。因为RNN模型有一个从前到后或者从后到前的信息传播顺序,信息在传播过程中容易遗漏。而attention[4]可以通过提取文本中的重点,来克服这一问题。最简单的attention模型结构可以表示为图1所示,图中的Key, Query, Value在不同的情境下有不同的含义。
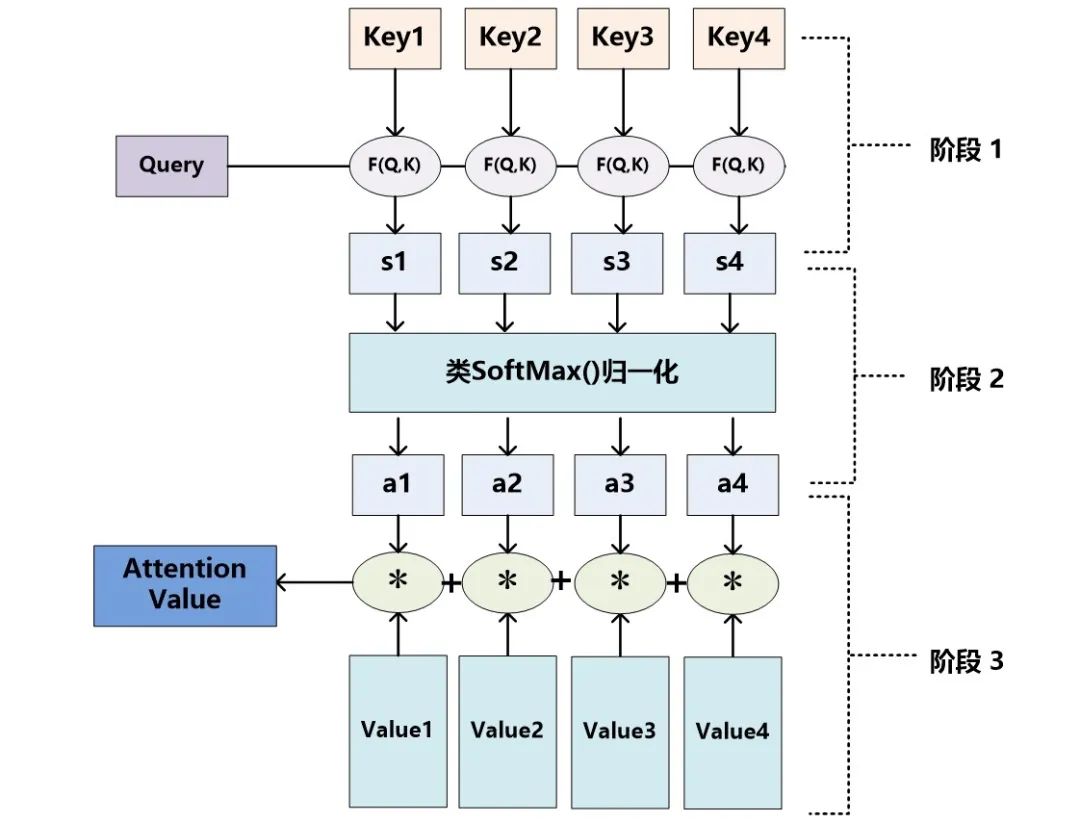
比如说给你一段只有四个字的用户的评论作为 Value , Query 是在评论中找到最能影响其他用户购买行为的部分,而 Key 和 Value 是一样的。具体以图一为例, 
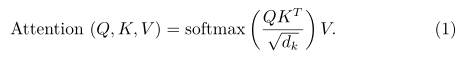
其中,除以 
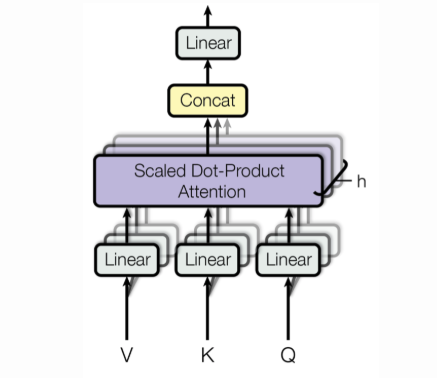
2.2 分解机
传统的线性回归模型,给定一个输入的特征向量 
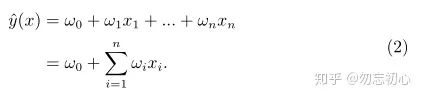
可以看到输入数据的每一位特征都是被分开考虑的,都有各自的参数。而现实中特征之间可能存在相关性,这种相关性也包含着一定的输入特征的信息,对这部分信息进行建模可以提升模型的表达能力。抱着这种想法,(2)式就可以修改为(3)式:
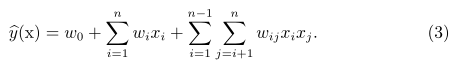
(3)式的问题在于时间复杂度太高,而且更糟糕的,如果我们的数据集是稀疏的,那么两个样本之间非常可能没有交互。比如 

而分解机的想法是,把
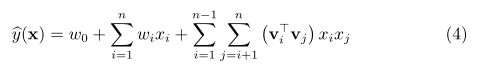
此时的 

其中每一个 



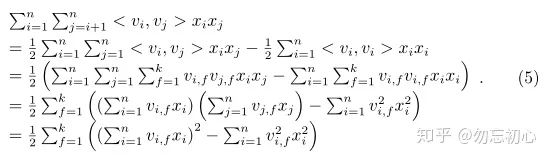
3 Attention在推荐系统中的应用
3.1 阿里深度兴趣网络
阿里巴巴的DIN[1]通过用户的行为序列来建模用户的兴趣表示。传统的办法通常是把用户的行为序列的每一项的embedding通过求和,求平均等方式转化为一个固定的embedding,我们记为emb2。但是这种办法非常粗糙,因为最终得到的emb2是一个固定维度的向量,将用户的历史行为中交互过的不同物品同等考虑,实际上用户对不同的物品的兴趣应该用不同的方式建模,因此emb2也就无法有效的表示用户兴趣的多样性。DIN通过对用户的历史行为序列进行注意力加权,来解决了这个问题。同时,DIN在实现中用到了诸多工程技巧,使得模型效果更进一步,这里我们主要讨论DIN建模用户兴趣表示的部分。
如图4所示,待推荐的物品 
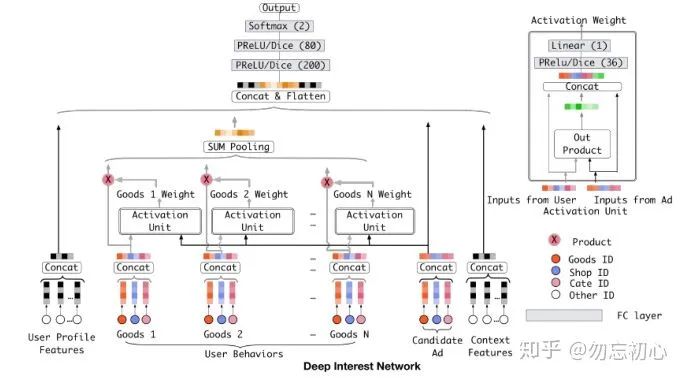
DIN模型的attention部分可以表示为(6)式:
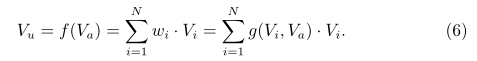
其中 




3.2 注意力分解机
利用分解机模型可以充分考虑用户与item之间的交互,来预测用户对item的兴趣。在前面已经介绍了分解机(FM)的原理:通过不同的特征向量之间各自做一次乘积操作来进行特征之间的交互。但是随着需要交互的特征数线性增加,或是考虑更高阶的三个特征同时交互的情况时,这种方法的效率就显的很低,不能够很好的推广到更高级的特征交叉的情况。因此人们提出了NFM[6],将(4)式中的最后一项用神经网络来代替。具体的,先将输入的特征向量输入embedding层,然后经过一个特征交叉池化层,最后再通过几层全连接神经网络来输出最终值。这里输入为 

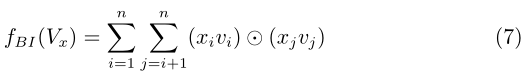
这里要介绍的AFM[7]可以看作是对NFM的扩展,我们可以使用AFM来构建优于原始FM与NFM的推荐系统,其模型示意图如图5所示:
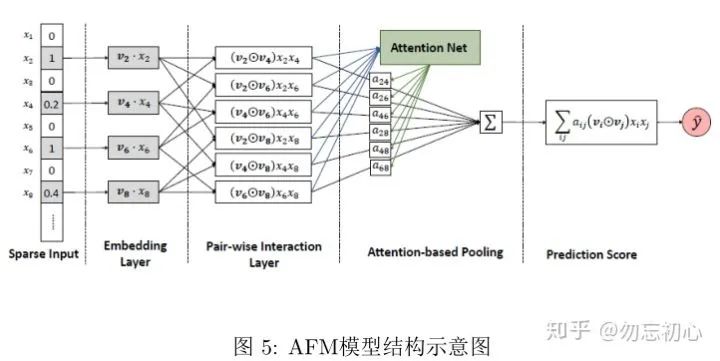
具体的,将特征交叉池化层和最终的输出层之间加入了attention操作。在特征交叉层也采用了元素积操作,求出交叉特征之后输入一层全连接网络进行激活,再将输出值进行SoftMax归一化操作,作为最终的注意力权重,将交叉特征进行注意力加权平均就得到了最终的输出结果(注意力分数)。其中注意力权重的计算可以表示为(8)式:
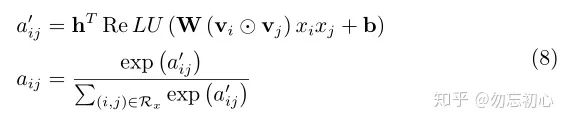
3.3 神经注意力评分回归
考虑评论信息可以构建更高效的推荐系统,NARRE[8]考虑的是不但要考虑评论信息,还要考虑评论信息的质量,也就是给每一个评论加上一个重要性权重,因此attention的思想很自然的就出现了。
NARRE的模型如图6所示,模型主要包含User Modeling部分、Item Modeling和输出部分。
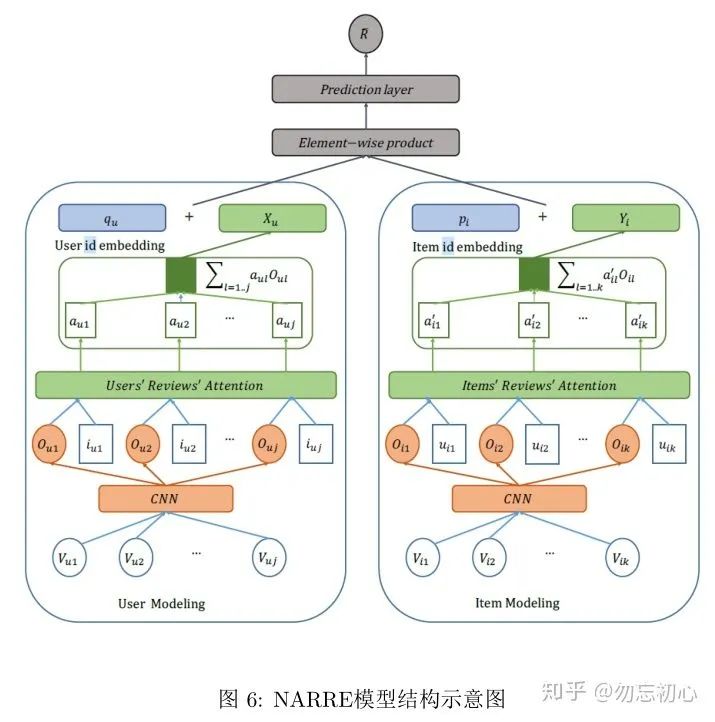
其中,User Modeling和Item Modeling分别处理user的评论与item收到的的评论。两个模型的结构相同,这里我们以Item Modeling为例来介绍。首先将item的评论转换为一个词向量矩阵 



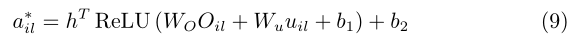
对 

最终输出一个注意力加权的评论特征,在经过一层不激活的全连接来得到输出。本模型最终的目的是给出用户u对
另外值得一提的是,本文发表于WWW 2018,在同年的WWW上又一篇论文与本文类似,主要不同在于评论的embedding部分采用了双向的GRU[9]。
3.4 多头协同注意力推荐网络
MPCN[10]的出发点也是希望对评论加上一个重要性权重,因此用到了attention的思想,但是在attention的权重计算方式上和[8][9]截然不同,是通过相似度矩阵来计算attention权重的。MPCN的模型结构如图7所示,核心即为两个相似度矩阵,以及review pointer模块。
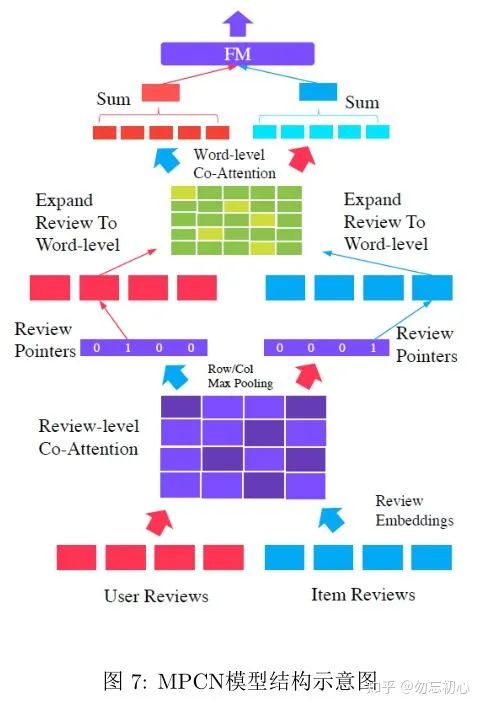
输入的是用户的评论列表与item的评论列表,具体如何embedding文中表述不清晰,上下文有冲突。这里我以下文的描述中推测出embedding是把每一个评论中的每一个单词映射为d维向量,然后每个评论的embedding就是对其中每个单词的embedding求和,最终输入的评论列表 
拿到embedding之后,先经过一个门控层来控制每一条评论对后续操作的影响程度,这一点在模型结构图中没有表现,具体的计算方式是:
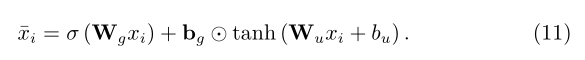
其中除 

下面计算 

其中 


如何从相似度矩阵中提取attention权重呢?常用的办法是对行或列进行求和,或者求平均,或者求最大值,因为这里我们得到attention权重之后还有review pointer模块,其目的是找到诸多评论中最有用的一条,因此我们这里对相似度矩阵在行列上求最大值,希望找到注意力权重最大的的评论,具体的计算方式如下式所示:
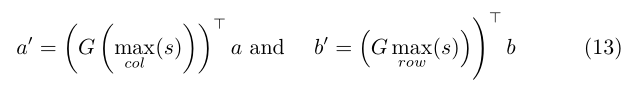
其中的 
到此,本文标题中的"Multi-Pointer Co-Attention Networks"也就不难实现了:我们只要让review pointer模块多输出几个评论就好了,而不是只输出一个。
对review-pointer提取出的用户与item评论求相似度矩阵,然后在行列进行平均池化求出注意力权重,拿这个权重对review-pointer模块的输入评论的embedding进行加权:
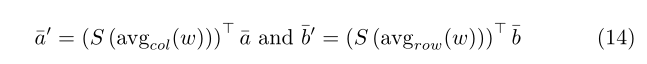
最后为了得到用户对item的评分,结果输出层采用了最原始的分解机,计算方式即为(4)式,输入值为注意力加权后的
4 讨论与总结
4.1 如何将attention机制用在微软的新闻推荐系统?
我们现在通过讨论“如何将attention机制用在微软的新闻推荐系统?”这一问题,来总结推荐系统中利用attention机制的方式。微软新闻推荐系统DRN[3]通过深度动作价值网络来预测用户对新闻的兴趣,网络模型如图8所示:
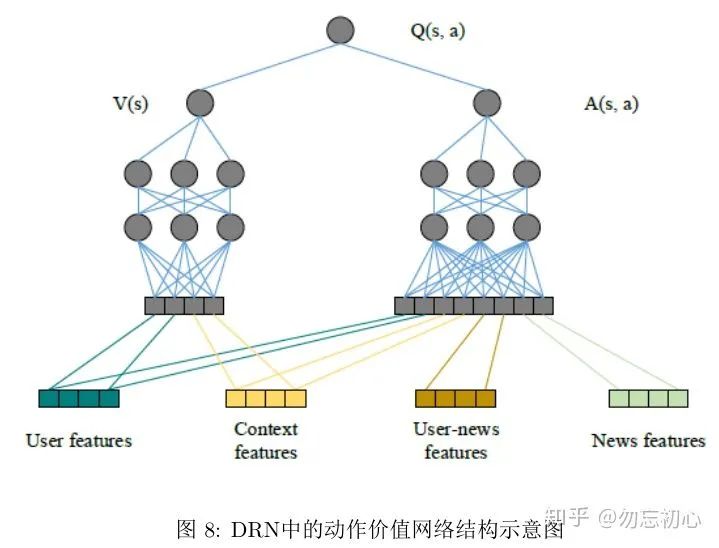
其中输入的四个特征都由代表某一类属性是否出现的one hot向量和代表点击次数和时间的向量组成,也就是说四个特征的表示都不是通过embedding得到的。网络中的 

如果考虑对新闻文本的利用,我们可以做用户特征与新闻word级别的embedding来求attention权重;或者像MPCN一样,求出一个用户与新闻的相似度矩阵,通过对矩阵进行行列操作,求出用户与新闻的对应attention权重。
4.2 未来研究方向展望
Attention用于推荐系统可以帮助模型更高效的利用信息,本文所讨论的方法都是从这个角度出发提出了新的模型。未来研究attention在推荐系统的应用,除了对现有方法的排列组合,还应多考虑如何将传统的方法进行“深度化”和“attention化”来提高其性能;以及更加高效的attention的形式,例如在对文本信息进行attention时,本文就展示了两种截然不同的形式,在什么情况下用哪一种形式更好,以及在特殊的推荐领域是否有针对问题的更加高效的利用attention的形式,都是一个值得研究的有趣的问题。
5 参考文献
Deep Interest Network for Click-Through Rate Prediction
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
DRN: A Deep Reinforcement Learning Framework for News Recommendation
Attention is All you Need
Factorization Machines
Neural Factorization Machines for Sparse Predictive Analytics
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
Neural Attentional Rating Regression with Review-level Explanations
Coevolutionary Recommendation Model: Mutual Learning
Multi-Pointer Co-Attention Networks for Recommendation
推荐阅读

登录查看更多
相关内容

Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
Arxiv
21+阅读 · 2019年2月4日


相关VIP内容
相关资讯
相关论文
Arxiv
21+阅读 · 2019年2月4日