深度学习在推荐系统上的应用

本文作者陈仲铭,知乎 ID:ZOMI,AI 研习社获其授权转载。
深度学习最近大红大紫,深度学习的爆发使得人工智能进一步发展,阿里、腾讯、百度先后建立了自己的AI Labs,就连传统的厂商OPPO、VIVO都在今年开始筹备建立自己的人工智能研究所。
确实深度学习很火,近期深度学习的战火烧到推荐系统,其强大的表征能力和低准入门槛,已经成为各大高校和中国人改网络发paper的红利时代。可是我还没能发上那么几篇,之前面试大厂的AI labs被总监虐,感觉工作之后被压榨太多,快干了。
推荐系统为什么引入深度学习?
为什么我们会想到使用深度学习去处理推荐系统里面的事情呢,推荐系统从基于内容的推荐,到协同过滤的推荐,协同过滤的推荐在整个推荐算法领域里独领风骚了多年,从基本的基于用户的协同过滤,基于item的协同过滤,到基于model的协同过滤等众多算法的延伸。或许深度学习在推荐系统里面没有像图像处理算法那样一枝独秀,但是深度学习对于推荐系统的帮助确实起到了,推波助澜的功效。下面我们可以来看一下推荐系统使用深度学习的原因。
能够直接从内容中提取特征,表征能力强
容易对噪声数据进行处理,抗噪能量强
可以使用RNN循环神经网络对动态或者序列数据进行建模
可以更加准确的学习user和item的特征
深度学习便于对负责数据进行统一处理
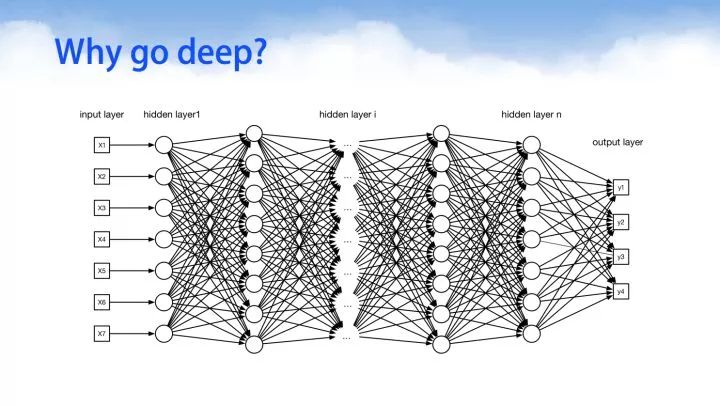
深度推荐系统
实际上深度学习在自然语言处理,图像处理,图像识别等领域迅猛发展的近4年来,深度学习在其他领域,例如强化学习,推荐系统也得到快速的发展。下面我们来看一下深度学习在推荐系统当中的一些应用,其主要分为5大类别,下面我们会重点介绍4个类别,分别是:
Learning item embeddings
Deep Collaborative filtering 深度协同过滤
Feature extraction directly from content 从内容中提取特征
Session-based recommendation with RNN 使用RNN从会话中推荐
hybird combination algorithm 混合基于深度学习的推荐系统

1. Learning item embeddings & 2VEC models
Embedding 其实就是从输入数据中学习到另外一组向量值的过程,通过另外一组向量去表达原来实际的向量。
在推荐系统里面我们经常会使用基于矩阵分解的协同过滤的方法,去得到Latent feature vector,也就是潜在特征向量。
这么一说可能会比较含糊,embedding到底对推荐系统来说有什么用,其实1)在更加高级的算法那中对item进行表征。2)能够用于item to item的推荐算法。
1.1 Embedding as MF
在推荐系统中我们现在常用的方法有矩阵分解 Matrix Factorization,MF。而矩阵分解实际上就是学习user & item的embedding向量。
学习相似特征
我们可以通过深度学习去矩阵分解算法中相类似的特征向量。其中包括items vector, user vector, 用户偏好向量。
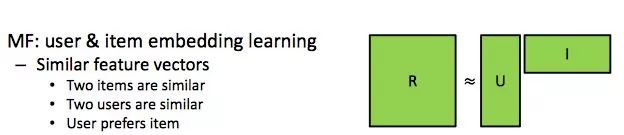
MF可以看做一个简单的神经网络
为什么这么说呢,其实我们可以这么来看,矩阵分解之于神经网络。输入是一个one-hot编码的用户id,对于数据的隐层权重向量来说是代表用户特征矩阵。对于隐层则可以是代表用户特征向量 user feature vector,对于隐层的输出权重向量来说代表item特征矩阵, Item feature maxtrix。最后该神经网络的输出则是用户对于该item的偏好。

1.2 Word2Vec
word2vec 对于做自然语言处理的人们来说,自然熟悉不过了。我觉得自己好多废话,word2vec顾名思义就是把单词编码成向量,例如单词 "拉稀" 编码成 [0.4442, 0.11345]。
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
Word2Vec模型中,主要有Skip-Gram和Continous Bag of Words (CBOW)两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
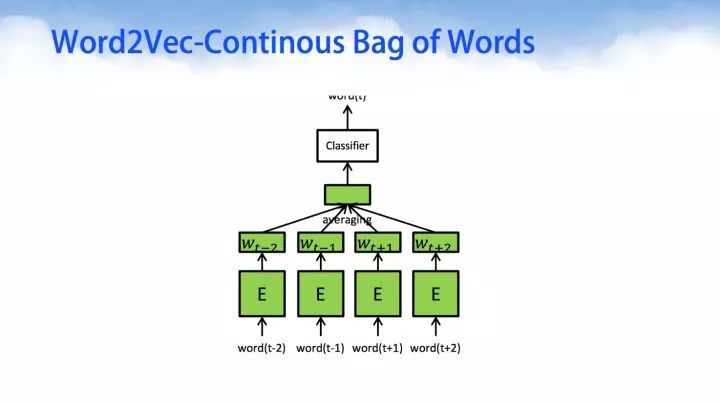
Word2Vec-Continous Bag of Words (CBOW)
Continous Bag of Words 连续词包的目标是使得给定上下文的目标词概率最大化。对于这样的深度学习模型来说,输入是经过one-hot编码的向量;经过神经网络的第一层E处,是对单词one-hot向量的embedding操作;对于中间隐层,是上下文的压缩编码特征;经过softmax转变后得到给定语料单词的最大似然估计。

上面就是word2vec的一个简单过程,经过上面过程我们可以对单词进行编码,然后对所有单词进行汇总求和分类,得到最后的语料向量。
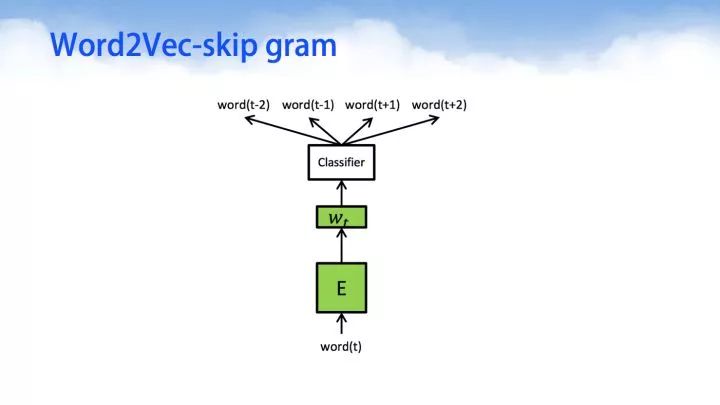
Word2Vec-skip gram
skip-gram与CBOW相比,只有细微的不同。skip-gram的输入是当前词的词向量,而输出是周围词的词向量。也就是说,通过当前词来预测周围的词。
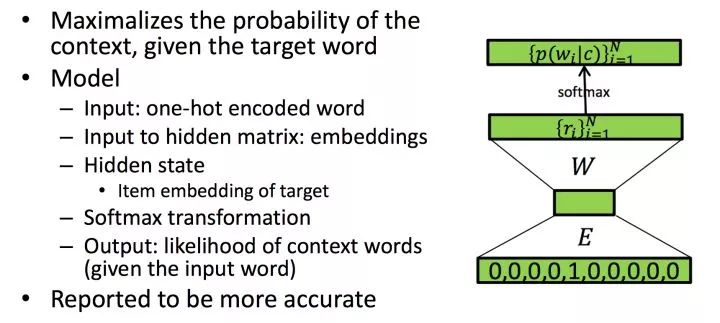
其中word2Vec部分与CBOW相同,但是根据论文和实践证明,skip-gram的方式得到的准确率会更高。表征能力也更强。
1.3 xxx2vec
当然,最常用的是上面2中,但是不乏近年来又衍生了更多的2vec变种,例如有的利用段落信息,有的利用整个文本的信息,有的则是在更高维度的item上进行2vec操作。下面我们一起来看看更多的衍生算法,至于说哪个算法哪个实现方式更好?笔者觉得应该尊重原数据,建立在理解业务的基础上进行操作,例如对于短视频的推荐与对于电影的推荐是不同,短视频有其特别的属性,例如搞笑、时间短、标题党等诸多属性需要去做去噪等工作。
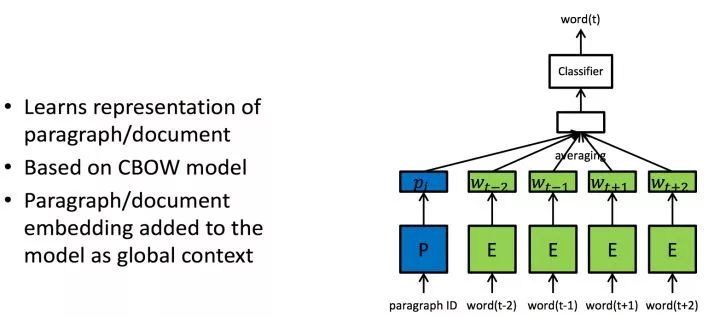
其中有Paragraph2vec基于CBOW,把段落的ID作为属性也纳入计算当中。
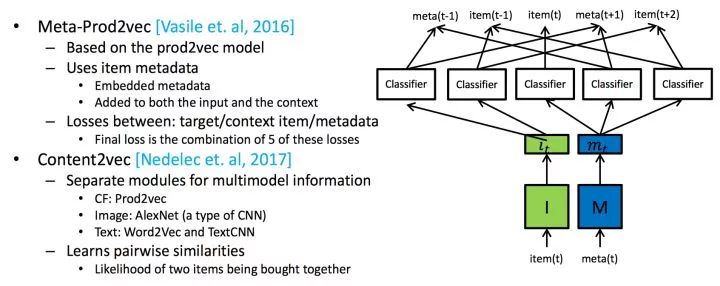
不过我们也可以像Content2Vec或者meta-prod2vec那样组合更多的特征进行处理,在这里以后再也不要说深度学习不需要特征工程时间了,深度学习的表征能力很好,但是工程师们仍然需要耗费大量的时间在选择特征这一件事情上,不懂特征工程的机器学习工程师不是好的机器学习工程师。
2.Deep Collaborative Filtering, DCL
深度协同过滤,一听名字就觉得逆天炸地。
2.1 Auto-encoders
Model-based方法的目的就是学习到User的隐向量矩阵U与Item的隐向量矩阵V。我们可以通过深度学习来学习这些抽象表示的隐向量。
Autoencoder(AE)是一个无监督学习模型,它利用反向传播算法,让模型的输出等于输入。Autoencoder利用AE来预测用户对物品missing的评分值,该模型的输入为评分矩阵R中的一行(User-based)或者一列(Item-based),其目标函数通过计算输入与输出的损失来优化模型,而R中missing的评分值通过模型的输出来预测,进而为用户做推荐。
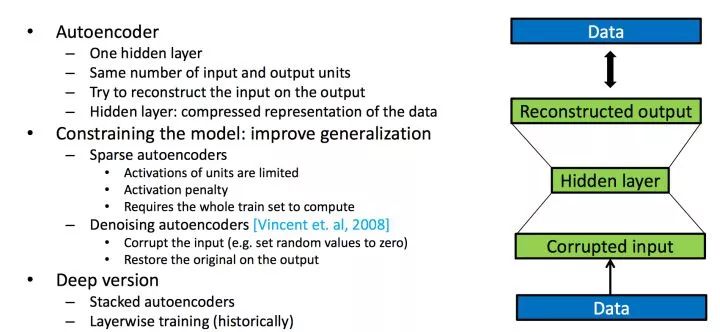
原论文的思路如下所示,对于autoencoders是一个自动编解码器,对于同源编解码器的训练学习过程中,我们的输入等于输出,中间编码向量作为特征向量。

该神经网络设计的编解码器一般只有3层,编码层(输入层),隐层,解码层(输出层)。
stacked denoising autoencoders
自从Autoencoders出现之后,确实是个好思想,但是后面我们迎来了DCL的黄金时代,确实DCL这篇文章首次提出让深度学习与协同过滤相结合,效果在开源数据集中取得了一点点上升,即使是一点点上升,但也是很重要的,因为把深度学习与协同过滤有机地集合了在一起。
Denoising Autoencoder(DAE)是在AE的基础之上,对输入的训练数据加入噪声。所以DAE必须学习去除这些噪声而获得真正的没有被噪声污染过的输入数据。因此,这就迫使编码器去学习输入数据的更加鲁棒的表达,通常DAE的泛化能力比一般的AE强。Stacked Denoising Autoencoder(SDAE)是一个多层的AE组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。

在SDAE的基础之上,又提出了Bayesian SDAE模型,并利用该模型来学习Item的隐向量,其输入为Item的Side information。该模型假设SDAE中的参数满足高斯分布,同时假设User的隐向量也满足高斯分布,进而利用概率矩阵分解来拟合原始评分矩阵。该模型通过最大后验估计(MAP)得到其要优化的目标函数,进而利用梯度下降学习模型参数,从而得到User与Item对应的隐向量矩阵。
Collaborative Recurrent Autoencoder
后来同一个作者又捣鼓出了CRAE.使用循环神经网络代替浅层的神经网络。看截图的风格,可以很清晰地看到肯定是出于同一个作者之手。

2.2 DeepCF
下面我们要介绍几个16-17年发表的DeepCF网络模型,虽然下面的网络模型不一定有用,但是其思想值得借鉴。
MV-DNN是基于多主题推荐,一个用户与多个主题内容进行建模组成一个深度神经网络。有n个用户则有n个神经网络,大量的神经网络进行组合成为一个庞大的DNN模型群。
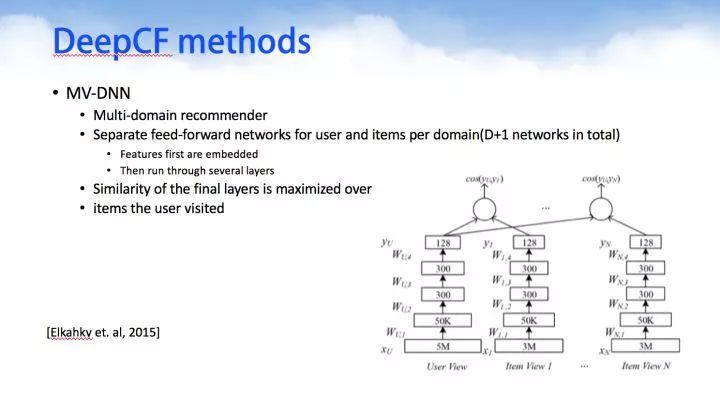
TDSSM与MV-DNN有点类似,用于对用户和item的短暂/临时数据进行一起建模。

Coevolving Features匹配上用户与item的瞬时信息,因为其相信随着用户在系统的浏览或者购买过程中,用户的选择偏好会不断改变,而所被选择的物品也会不断变化,这两者是一起发生变化的co-evolutionary。

Product Neural Network则是把产品的目录结构也纳入神经网络中进行计算,计算的同时考虑了产品目录结构属性。

2.3 google recommendations
下面两个是google近年来推出较为经典的使用深度学习做推荐算法的框架。其中Wide & Deep Learning网络模型由Wide Models和Deep Models组合而成,这里的特征组合方式非常巧妙。

YouTube Recommender,在今年的推荐系统顶级会议RecSys上,Google利用DNN来做YouTube的视频推荐。通过对用户观看的视频,搜索的关键字做embedding,然后在串联上用户的side information等信息,作为DNN的输入,利用一个多层的DNN学习出用户的隐向量,然后在其上面加上一层softmax学习出Item的隐向量,进而即可为用户做Top-N的推荐。
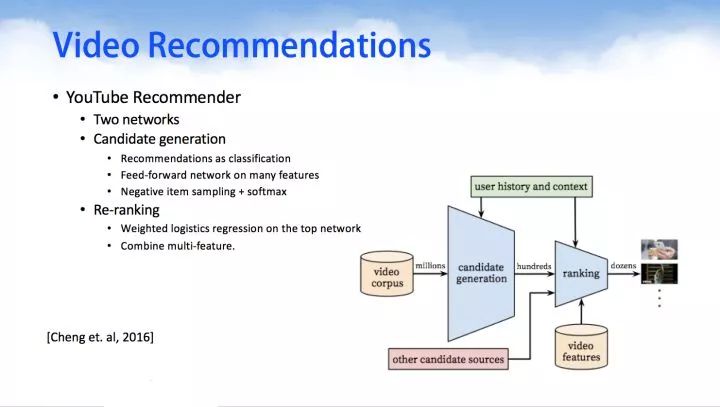
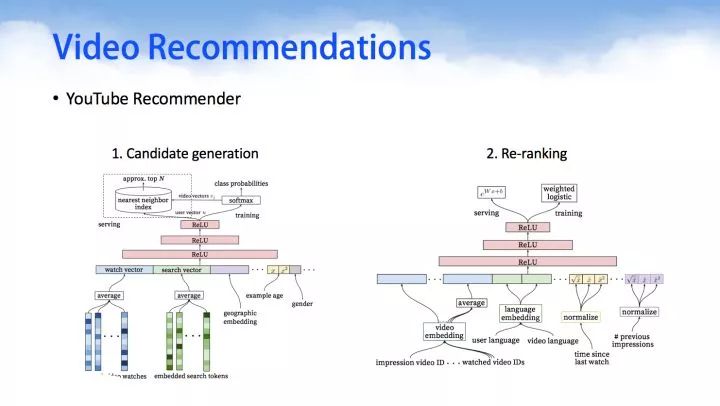
3.Content Features in recommenders
在基于内容/上下文特征的推荐中,我们的注意力对内容/上下文centent中,例如有图像、文本、语音,这些内容都可以通过深度学习建模,获得其高维特征或者分类属性,然后基于协同过滤算法CF和基于内容的过滤算法CBF的混合组合,进行推荐。

针对于图像识别一类任务,深度学习已经取得了举足的进展。深度神经挽留过模型设计一开始的时候模型权重越多模型越大,其精度越高,后来先后出现了GoogleNet、InceptionV1、INceptionV2、InceptionV3,resNet等著名的开源深度网络架构之后,在取得相同或者更高精度之下,其权重参数不断下降。值得注意的是,并不是意味着横坐标越往右,它的运算时间越大。在这里并没有对时间进行统计,而是对模型参数和网络的精度进行了纵横对比。其中有几个网络非常值得学习和经典的有:AlexNet、LeNet、GoogLeNet、VGG-16\VGG-19。
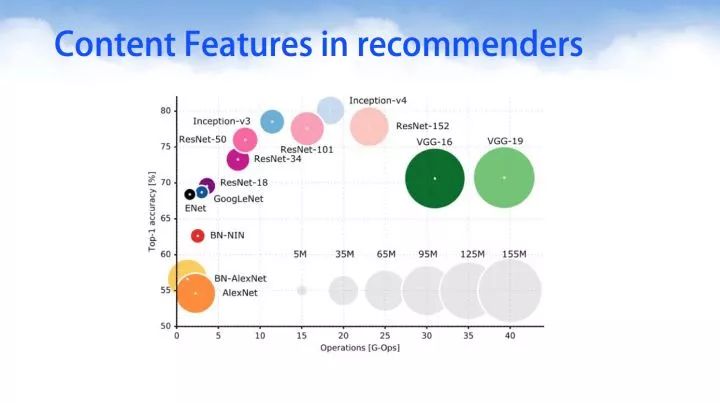
针对文本处理我们在此前已经介绍过一系列的Word2vec技术,而音频音乐方面的内容可以使用循环神经网络RNN进行序列数据建模。
4.Session-based neural recommendation

首先介绍下 session-based 的概念:session 是服务器端用来记录识别用户的一种机制。典型的场景比如购物车,服务端为特定的对象创建了特定的 Session,用于标识这个对象,并且跟踪用户的浏览点击行为。我们这里可以将其理解为具有时序关系的一些记录序列。
传统的两类推荐方法——基于内容的推荐算法和协同过滤推荐算法(model-based,memory-based)在刻画序列数据中存在缺陷:每个 item 相互独立,不能建模 session 中 item 的连续偏好信息。

在模型构建的时候,上图使用了GRU,但是我们可以有很多选择例如LSTM等,当然这些模型神经元的选择主要原因是为了防止梯度消散对长时间序列记忆力下降而出现的。
我们出现了基于时间序列数据建模的循环神经网络RNN,把用户的session信息看作是历史序列数据,用户的行为CTR作为循环神经网络RNN的预测输出。

5.总结
本文介绍了一些深度学习在推荐领域的应用,我们发现一些常见的深度模型(DNN, AE, CNN等)都可以应用于推荐系统中,但是针对不同领域的推荐,我们需要更多的高效的模型。随着深度学习技术的发展,我们相信深度学习将会成为推荐系统领域中一项非常重要的技术手段。

CCF ADL 系列又一诚意课程
两位全球计算机领域 Top 10 大神加盟
——韩家炜 & Philip S Yu
共 13 位专家,覆盖计算机学科研究热点
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
一文详解 AI 推荐系统三大算法
▼▼▼





