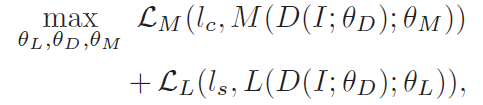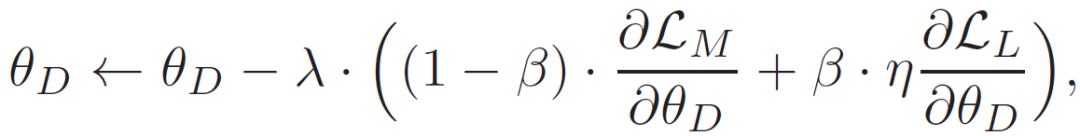本文依托于综述性文章,首先回顾了可解释性方法的主要分类以及可解释深度学习在医疗图像诊断领域中应用的主要方法。然后,结合三篇文章具体分析了可解释深度学习模型在医疗图像分析中的应用。
![]()
作为一种领先的人工智能方法,深度学习应用于各种医学诊断任务都是非常有效的,在某些方面甚至超过了人类专家。其中,一些计算机视觉方面的最新技术已经应用于医学成像任务中,如阿尔茨海默病的分类、肺癌检测、视网膜疾病检测等。但是,这些方法都没有在医学领域中得以广泛推广,除了计算成本高、训练样本数据缺乏等因素外,深度学习方法本身的黑盒特性是阻碍其应用的主要原因。
尽管深度学习方法有着比较完备的数学统计原理,但对于给定任务的知识表征学习尚缺乏明确解释。深度学习的黑盒特性以及检查黑盒模型行为工具的缺乏影响了其在众多领域中的应用,比如医学领域以及金融领域、自动驾驶领域等。在这些领域中,所使用模型的可解释性和可靠性是影响最终用户信任的关键因素。由于深度学习模型不可解释,研究人员无法将模型中的神经元权重直接理解 / 解释为知识。此外,一些文章的研究结果表明,无论是激活的幅度或选择性,还是对网络决策的影响,都不足以决定一个神经元对给定任务的重要性[2] ,即,现有的深度学习模型中的主要参数和结构都不能直接解释模型。因此,在医学、金融、自动驾驶等领域中深度学习方法尚未实现广泛的推广应用。
可解释性是指当人们在了解或解决一件事情的过程中,能够获得所需要的足够的可以理解的信息。深度学习方法的可解释性则是指能够理解深度学习模型内部机制以及能够理解深度学习模型的结果。关于 “可解释性” 英文有两个对应的单词,分别是 “Explainability” 和“Interpretability”。这两个单词在文献中经常是互换使用的。一般来说,“Interpretability”主要是指将一个抽象概念(如输出类别)映射到一个域示例(Domain Example),而 “Explainability” 则是指能够生成一组域特征(Domain Features),例如图像的像素,这些特征有助于模型的输出决策。本文聚焦的是医学影像学背景下深度学习模型的可解释性(Explainability)研究。
可解释性在医学领域中是非常重要的。一个医疗诊断系统必须是透明的(transparent)、可理解的(understandable)、可解释的(explainable),以获得医生、监管者和病人的信任。理想情况下,它应该能够向所有相关方解释做出某个决定的完整逻辑。公平、可信地使用人工智能,是在现实世界中部署人工智能方法或模型的关键因素。本文重点关注可解释深度学习方法在医疗图像诊断中的应用。由于医学图像自有的特点,构建用于医疗图像分析的可解释深度学习模型与其它领域中的应用是不同的。本文依托于综述性文章[1],首先回顾了可解释性方法的主要分类以及可解释深度学习在医疗图像诊断领域中应用的主要方法。然后,结合三篇文章具体分析了可解释深度学习模型在医疗图像分析中的应用。
一、可解释深度学习模型在医疗图像分析中的应用综述[1]
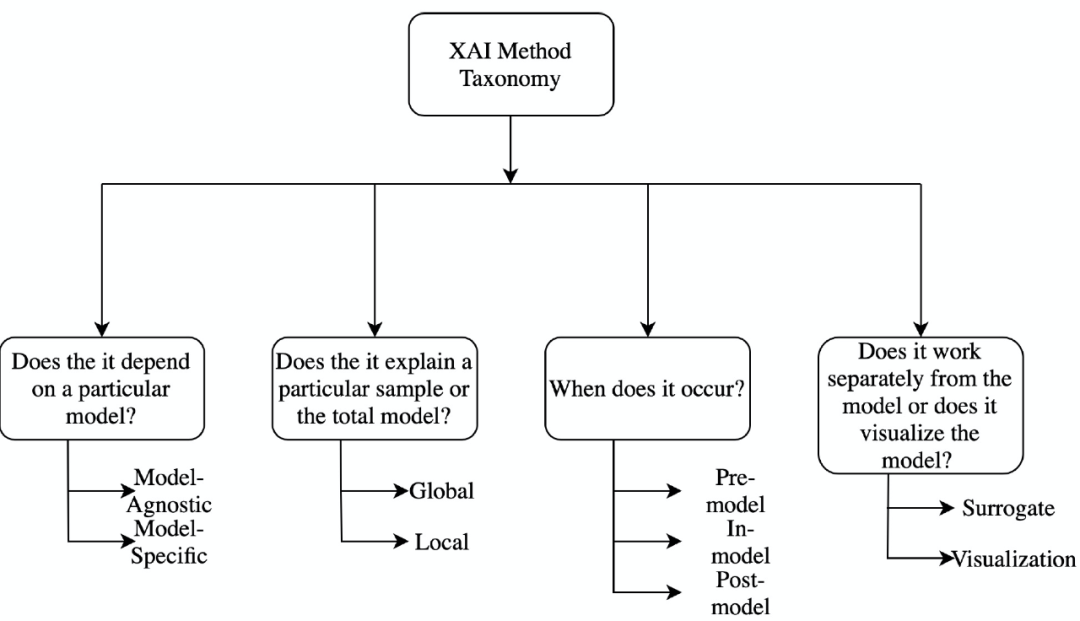
首先,我们来了解一下可解释性方法的分类。针对可解释性方法的分类问题研究人员提出了多种分类方式,但是这些方式都不是绝对的,即这些方法都是非排他性的,不同的分类方法之间存在重叠。图 1 给出可解释性分类方法的示例(可解释性人工智能工具(Explainable AI ,XAI)):
![]()
1.1.1 模型特定的方法 vs 模型无关方法(Model Specific vs Model Agnostic)
模型特定的方法基于单个模型的参数进行解释。例如,基于图神经网络的可解释方法(Graph neural network explainer,GNNExplainer)主要针对 GNN 的参数进行解释。模型无关方法并不局限于特定的模型体系结构。这些方法不能直接访问内部模型权重或结构参数,主要适用于事后分析。
1.1.2 全局方法 vs 局部方法(Global Methods vs Local Methods)
局部可解释性方法主要聚焦于模型的单个输出结果,一般通过设计能够解释特定预测或输出结果的原因的方法来实现。相反,全局方法通过利用关于模型、训练和相关数据的整体知识聚焦于模型本身,它试图从总体上解释模型的行为。特征重要性是全局方法的一个很好的例子,它试图找出在所有不同的特征中对模型性能有更好影响的特征。
1.1.3 模型前 vs 模型中 vs 模型后方法(Pre-model vs in-model vs post-model)
模型前方法是一类独立的、不依赖于任何深度学习模型结构的可解释性方法,主成分分析(PCA)、流形学习中的 t-SNE 都属于这一类方法。集成在深度学习模型本身中的可解释性方法称为模型中方法。模型后方法则是在建立深度学习模型之后实施的,这一类方法主要聚焦于找出模型在训练过程中究竟学到了什么。
1.1.4 替代方法 vs 可视化方法(Surrogate Methods vs Visualization Methods)
替代方法由不同的模型组成一个整体,用于分析其他黑盒模型。通过比较黑盒模型和替代模型来解释替代模型的决策,从而辅助理解黑盒模型。决策树(Decision tree)就是替代方法的一个例子。可视化方法并不是构建一个新的不同的模型,而是通过可视化的方法,例如激活图(Activation Maps),帮助解释模型的某些部分。
1.2 可解释深度学习模型在医疗图像分析中的应用分类
具体到医疗图像分析领域,引入可解释性方法的可解释深度学习模型主要有两类:属性方法(attribution based)和非属性方法(non-attribution based)
。两类方法的主要区别在于是否已经确定了输入特征对目标神经元的联系。属性方法的目标是直接确认输入特征对于深度学习网络中目标神经元的贡献程度。而非属性方法则是针对给定的专门问题开发并验证一种可解释性方法,例如生成专门的注意力、知识或解释性去辅助实现专门问题的可解释深度学习。
属性方法的目标是确定输入特征对目标神经元的贡献,通常将分类问题正确类别的输出神经元确定为目标神经元。所有输入特征的属性在输入样本形状中的排列形成热图(heatmaps),称为属性映射(Attribution Maps)。图 2 给出了不同图像的属性映射示例[3]。对目标神经元激活有积极贡献的特征用红色标记,而对激活有负面影响的特征则用蓝色标记。
![]()
图 2. 基于 Imagenet 图像的对 VGG-16 属性的研究示例[3]
扰动(Pertubation)是分析输入特征的改变对深度学习模型输出的影响的最简单方法,一般可以通过移除、屏蔽或修改某些输入特征、运行正向过程(输出计算)并测量与原始输出的差异来实现
。这一过程类似于在参数控制系统模型中进行的灵敏度分析。将对输出影响最大的输入特征确定为最重要的特征。对于图像数据来说,实现扰动的一种方法是用灰色斑块覆盖掉图像中的一部分进而将它们从系统视图中遮挡去除掉。以此来突出有效特征,从而提供正向和负向证据。另一种基于扰动的方法是 Shapley 值采样(Shapley Value sampling),它通过对每个输入特征进行多次采样来计算近似 Shapely 值,这也是联合博弈论中描述收益和损失在输入特征之间公平分配的一种常用方法。
基于反向传播的方法(Backpropagation based methods)是另外一种有效的属性方法
。基于反向传播的方法会通过一次前向和后向网络传播过程来计算所有输入特征的属性。一些方法会多次执行这些步骤,这种方法与输入特征的数量无关,并且计算速度比基于扰动的方法要慢得多。
由于具有良好的易用性,大多数研究可解释深度学习方法的医学影像学文献都使用的是属性方法。研究人员可以直接使用已有的属性模型训练得到一个合适的神经网络结构,这一过程不会增加计算复杂度。这使得人们可以直接使用预先得到的深度学习模型或具有定制体系结构的模型,以在给定任务上获得最佳性能。前者使这种实现过程更容易,并可以方便的引入诸如转移学习之类的技术,而后者可用于专门处理特定数据,并通过使用较少的参数避免过度拟合。引入属性方法可以有效展示出原有的深度学习模型是否能够学习相关有意义的特征,或者是否是通过学习伪特征来过度适应输入的。这使得研究人员可以调整模型结构和超参数,从而在测试数据上获得更好的结果,进而得到潜在的真实场景中的设置。
非属性方法是指针对给定的专门问题开发并验证一种可解释性方法,而不是像属性方法那样进行单独的分析。
非属性方法包括注意力图(Attention maps)、概念向量(Concept vectors)、相似图像(Similar image)、文本证明(text justification)、专家知识(expert knowledge)、内在解释性(Intrinsic explainability)等
。
注意力
是深度学习中一个非常有用的概念,是由人类对图像的不同部分或其它类型数据源的注意方式的不同所启发产生的。非属性方法中用到的注意力的主要是作为可解释的医学图像分析的深度学习工具。如文献 [4] 提出了一种新的
测试概念激活向量(Testing Concept Activation Vectors,TCAV)
方法,用人类可理解的概念向领域专家解释不同层次学习的特征。TCVA 把网络在概念空间中的方向导数作为显著图(Saliency Maps)。使用显著图来解释糖尿病性视网膜病变(diabetic retinopathy,DR)水平的预测,能够成功检测到视网膜中存在的微动脉瘤和动脉瘤。这就为医生提供了一个可解释的理由,即图像中是否存在给定的概念或物理结构。然而,许多医学中的临床概念(Clinical Concept),如结构纹理或组织形状等,并不能直接使用 TCAV 进行充分描述以证明其存在或不存在,此时就需要引入连续的测量指标进行辅助判断。
基于
专家知识
的非属性方法主要有两种:一是,使用不同的方法将模型特征与专家知识关联起来;二是,使用特定领域的知识来制定用于预测和解释的规则。基于
相似图像
的非属性方法为用户提供了类似标签的图像作为对给定测试图像进行预测的原因解释。
文本证明方法
使用一个给定推理后能够根据句子或短语来解释其决策的模型,该模型可以直接与专家和一般用户进行交流。例如,从分类器的视觉特征以及嵌入预测中获取输入的证明模型可以被用于生成乳腺肿块分类的诊断语句和可视化热图[5]。
内在解释性
是指模型具有根据人类可观察到的决策边界或特征来解释其决策的能力。一些相对简单的模型,如回归模型、决策树和支持向量机等,都是可以观察到决策边界的,因此是具备内在解释性的。最近的关于内在解释性的研究使用不同的方法使深度学习模型本质上可解释,例如混合使用机器学习分类器和在分割空间中的可视化特征等。
2.1、可视化卷积神经网络改善皮肤病变分类的决策支持[6]
![]()
本文提出了
一种属性方法用于实现可解释 CNN 在医疗图像诊断中的应用
。该方法训练得到了一个 CNN 用于在皮肤损伤数据库上进行二元分类,并通过可视化其特征图来检验 CNN 学习的特征。作者通过对不同特征图的可视化对比分析,确定输入特征对最终 CNN 目标神经元的贡献。
本文应用的 CNN 由 4 个卷积块组成,每个卷积块由 2 个卷积层组成,然后进行最大池化操作。卷积层的核大小为 3x3,分别有 8、16、32 和 64 个滤波器。接下来是 3 个全连接层,分别有 2056、1024 和 64 个隐藏单元。所有层都引入了校正的线性单位(ReLU)以满足非线性处理要求。
对于 CNN 的每个特征映射,通过将特征映射重新缩放到输入大小并将激活映射到透明绿色的部分(深绿色 = 更高激活度)创建了一个可视化效果。接下来,作者检查了所有的视觉效果,并将这些与皮肤科医生提供的典型特征对应起来。特别是 CNN(6,7)的最后两层卷积层,能够帮助深入了解哪些图像区域更能吸引 CNN 的注意力。作者使用公开的 ISIC 档案的数据(https://isic-archive.com/),组成一个包括 12838 张皮肤镜图像的训练库,分为两类(11910 个良性病变,928 个恶性病变)。在预处理步骤中,图像被缩小到 300x300 像素的分辨率,并将 RGB 值在标准化处理到 0 和 1 之间。通过选取 224x224 像素的随机裁剪来增强训练集中的图像,并通过旋转(角度在 0 和 2π之间均匀采样)、随机水平和 / 或垂直翻转、调整亮度(在 - 0.5 和 0.5 之间均匀采样的因子)、对比度(在 - 0.7 和 0.7 之间均匀采样的因子)、色调(在 - 0.02 和 0.02 之间均匀采样的因子)和饱和度(在 0.7 和 1.5 之间均匀采样的因子)进一步增强每个裁剪后的图像。作者使用 96 个小批量训练了 192 个 epoch 的网络,并用 Adam 算法更新了网络的参数,初始学习率为 10±4,一阶和二阶动量的指数衰减率分别为 0.9 和 0.999。
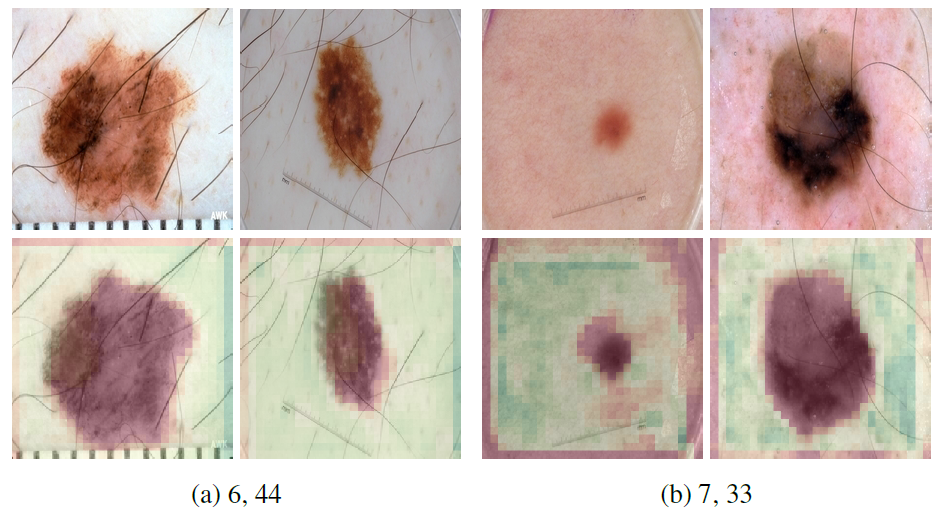
根据医生的诊断经验判断,边界不规则的皮肤病变边界可能表明存在恶性病变。图 1 所示的特征图在皮肤病变的边界上都有很高的激活率,但都处于边界的不同部位。第一张(a)检测的是病变的底部边界,而第二张(b)检测的是左侧边界。
![]()
图 1. 病变边界上具有高激活度的特征图。过滤器(a)在底部边界激活,而过滤器(b)在左侧边界激活
同样的推理也适用于病变内部的颜色。颜色均匀的病变通常是良性的,而严重的颜色不规则可能是恶性病变的征兆。图 2 所示的特征图在病变处有较暗的区域时具有较高的激活度,这意味着颜色不均匀。
![]()
图 2. 病灶内较暗区域高激活的特征图,表明病灶颜色不均匀
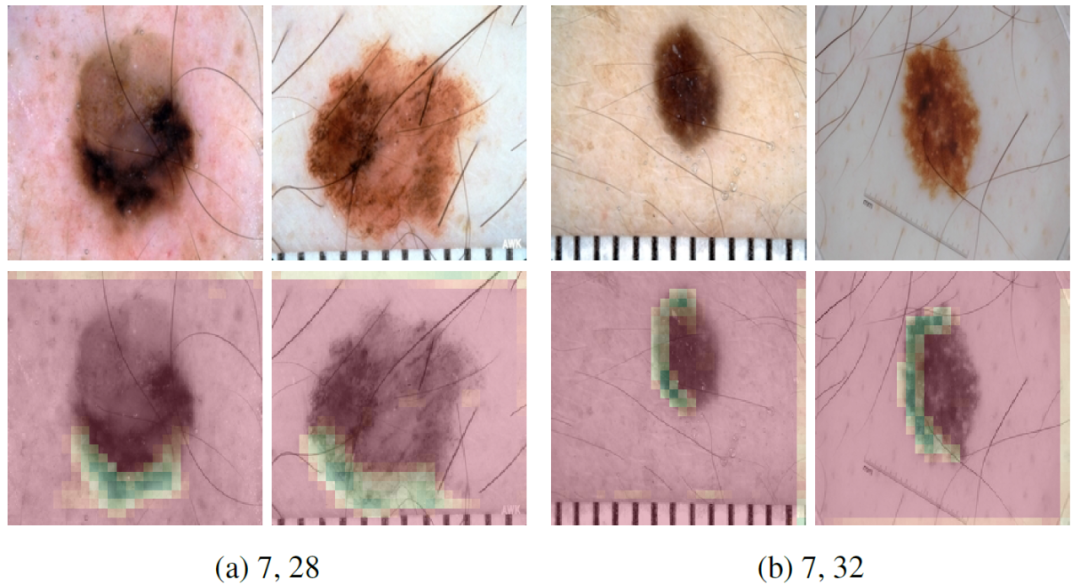
此外,医生一般认为皮肤颜色浅的人更容易晒伤,这会增加皮肤恶性病变的发生。因此,皮肤科医生在检查患者的皮损时会考虑到患者的皮肤类型。图 3 所示的特征图用于验证此特性。特征图(a)在白皙的皮肤中具有较高激活度,而特征图(b)在具有血管样结构的粉红色皮肤上具有高激活度。
![]()
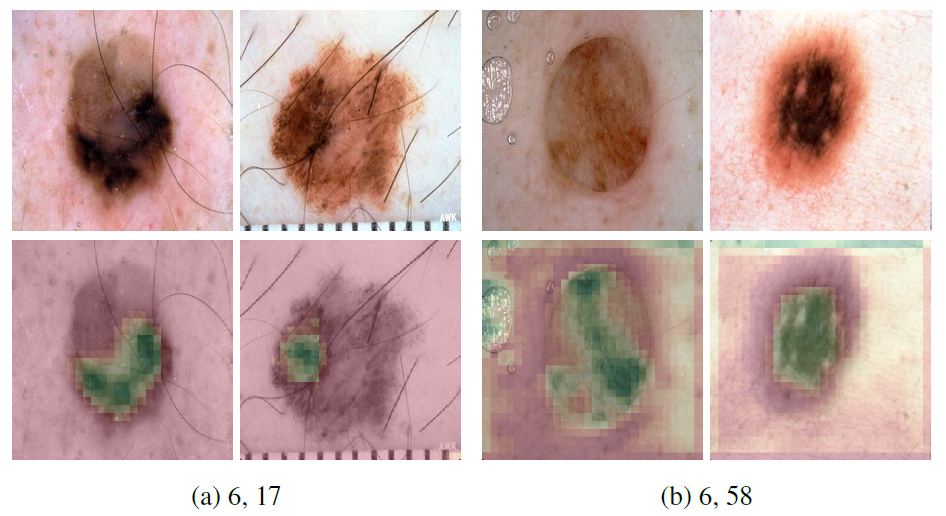
从皮肤科医生的角度考虑,头发对于最终的诊断没有影响。如图 4 所示,毛发状的结构区域具有较高激活度。
![]()
图 4. 特征图(7,8),在毛发状结构上具有高激活度
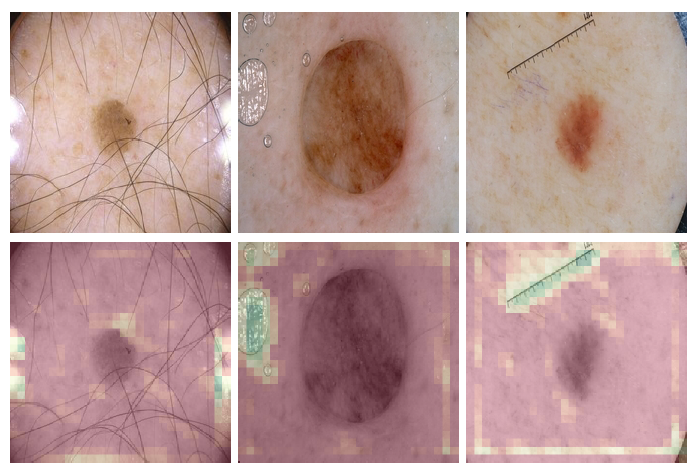
此外,作者还注意到一些特征映射对图像中的各种伪造影有很高的激活率。例如,如图 5 所示,一些特征图在镜面反射(specular reflections)、凝胶涂抹应用(gel application)或标尺(rulers)上具有高激活度。这突出了使用机器学习技术时的一些风险,即当这些伪造影在特定类的训练图像中显著存在时可能会对网络的输出产生潜在的偏差。
![]()
图 5. 各种图像伪造影的高激活特征图,从左到右,镜面反射、凝胶处理和标尺,这些伪造影可能会对 CNN 的输出造成偏差
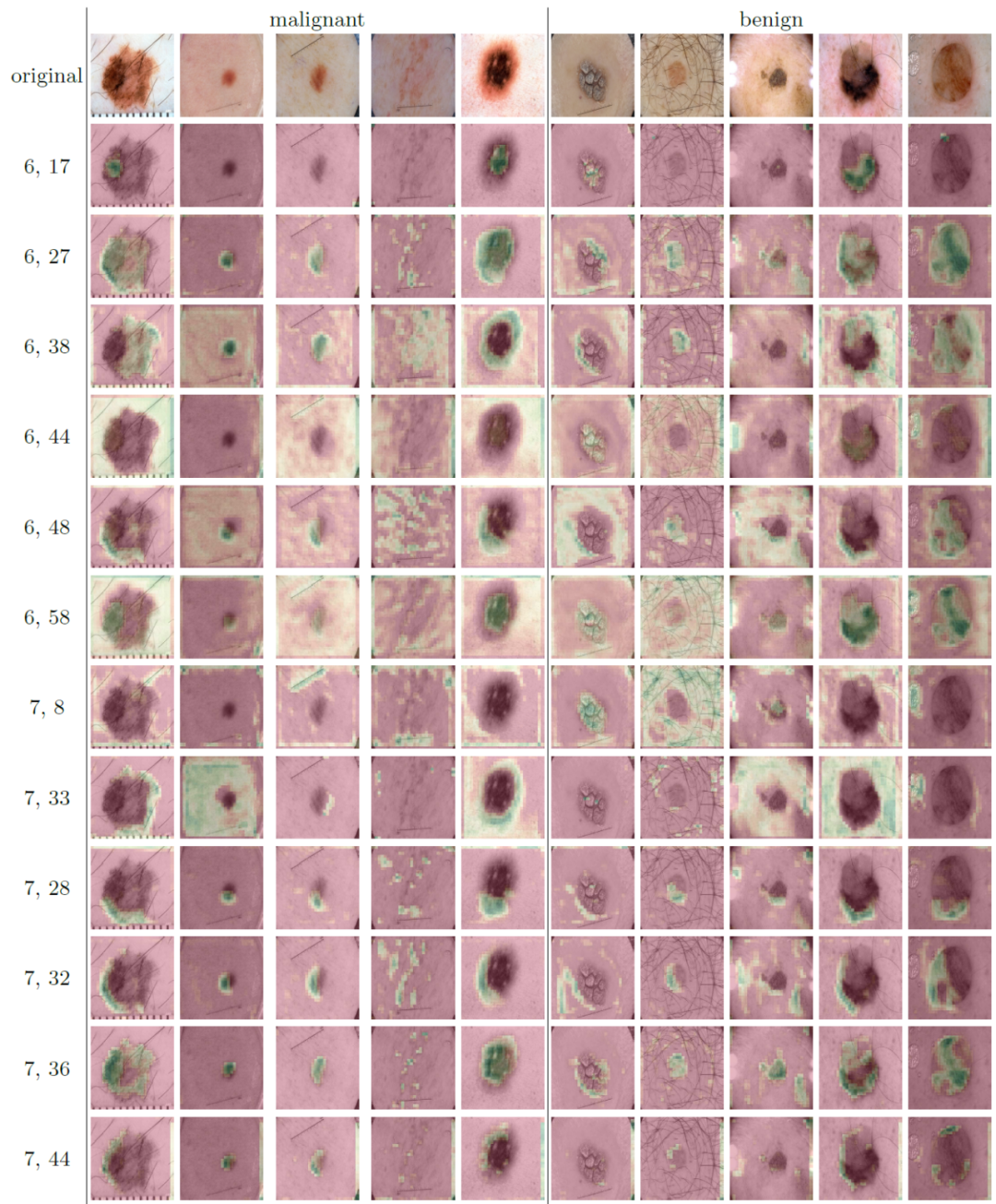
最后,通过特征图,图 6 给出了对不同图像上激活的全面概述。
![]()
本文分析了由 CNN 学习到的皮肤病医学图像中的特征,该 CNN 是为皮肤病变分类而训练得到的
。通过可视化 CNN 的特征图可以看到,高级卷积层在与皮肤科医生所使用的类似的概念中具有较高激活度,例如病变边界、病变内的暗区、周围皮肤等。此外,作者还发现,一些特征图在各种图像伪造影区域具有较高激活度,如镜面反射、凝胶涂抹应用和标尺。
尽管本文对 CNN 学习到的特征给出了一些分析和评论,但并不能解释 CNN 检测到的特征与其输出之间的任何因果关系。此外,通过特征图,并没有发现任何能精确突出皮肤科医生扫描过程中重点关注的其他结构,如球状体、圆点、血管结构等。作者认为,为了使 CNN 能够成为皮肤科医生更好的决策支持工具,还需要在这一领域进行更多的研究。
3.1、通过深度生成模型学习可解释的解剖学特征:在心脏重构中的应用[7]
![]()
心脏几何结构和功能的改变是引发心血管疾病的常见原因。然而,目前的心血管疾病诊断方法往往依赖于人的主观评估以及医学图像的人工分析。近年来,深度学习方法在医学图像的分类或分割等任务中应用取得了成功,但在特征提取和决策过程中仍然缺乏可解释性,这就限制了深度学习方法在临床诊断中的价值。
本文提出了一个三维卷积变分自动编码器(VAE)模型用于心脏病患者的医疗图像分类。该模型利用了从 3D 分割中学习到的可解释的任务相关解剖学模式(Anatomic Pattern)
,此外,还允许在图像的原始输入空间中可视化和量化所学习到的病理学特定重构模式。
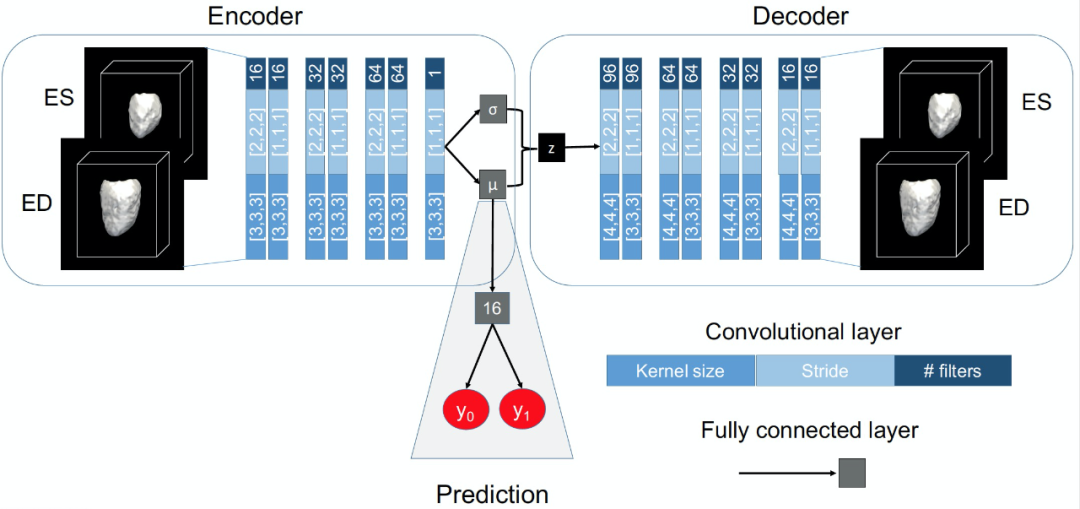
本文所提出模型的示意图如图 1 所示。输入 X 为双通道输入的受试者在舒张末期(End-diastolic,ED)和收缩末期(end-systolic,ES)的三维左室心肌节段(3D left ventricular myocardial segmentations)。利用三维卷积 VAE,通过编码器网络学习潜在空间中代表输入分段 X 的 d 维概率分布,并将该潜在分布参数化为 d 维正态分布 N(μ_i, σ_i),其中,μ_ i 表示平均值,σ_i 为标准差。在训练过程中,解码器网络通过从学习到的潜在 d 维流形中采样向量 z 来学习重建输入 X 的近似值。同时,一个由多层感知器(MLP)构成的判别网络(在本文中称为预测网络 prediction)被连接到平均向量μ上,并被训练用于区分健康志愿者(healthy volunteers,HVols)和肥厚型心肌病(hypertrophic cardiomyopathy,HCM)受试者。使用下述损失函数进行端到端训练:
![]()
其中,L_rec 表示重建损失,可以通过输入 X 和重建之间的 Sorensen Dice 损失来计算得到 L_rec。L_KL 是 Kullback-Leibler 散度损失,其目的是使 N(μ, σ)尽可能接近其先前的分布 N(0, 1)。L_MLP 是 MLP 分类任务的交叉熵损失。潜在空间维数为 d=64。
在测试阶段,通过将预测得到的μ传递到 z(不从潜在空间采样)来重建每个输入分段,最后,在训练阶段完成分类任务。
![]()
本文提出的模型架构允许在原始分割空间中可视化网络学习的特征
。利用 MLP 学习到的权值,通过使用链式规则将梯度从分类标签 C 反向传播到μ_i 来计算疾病分类标签 C(y_C)的偏导数。给定一个随机选择的健康组织形状,可以使用导出的梯度沿着潜在编码可变性的方向移动受试者的潜在表示,使用迭代算法将该可变性分类到 C 类的概率最大化。从健康形状的平均潜在表示开始,在每个步骤 t 利用下式迭代更新μ_i:
![]()
本文选择λ=0.1。最后,每一个步骤 t 的每一个潜在表示μ_t 都可以通过传递给 z 的方式来解码得到分割空间,从而实现相应重建片段的可视化处理。
本文实验使用了
一个由 686 名 HCMs 患者(57±14 岁,27% 为女性,77% 为白种人,采用标准临床诊断的 HCM)和 679 名健康志愿者(40.6 ±12.8 岁,55% 为女性,69% 为白人)组成的数据库
进行研究。参与者接受了 1.5T 的心血管磁共振(Cardiovascular magnetic resonance,CMR),采用的是西门子(德国埃尔兰根)或飞利浦(荷兰贝斯特)设备。采用平衡的稳态自由进动序列获得电影图像,包括左心室短轴平面上的一组图像(体素大小为 2.1x1.3x7mm^3,重复时间 / 回波时间为 3.2/1.6ms,翻转角度为 60°)。使用一个先前发表并得到广泛验证的心脏多图谱分割框架进行舒张末期(ED)和收缩期(ES)的分割。
作为预处理的第一步,采用多图谱辅助上采样方案提高了二维叠加分割的图像质量。对于每个分割片段,将基于 landmark 的 20 个 ED 和 ES 的人工标注的高分辨率图扭曲映射到它的空间中。然后应用一个稀疏控制点集的自由形式非刚性配准(最近邻插值)并与多数投票一致性进行融合。第二步,通过基于 landmark 和强度的刚性配准将所有增强处理后的片段对齐到相同的参考空间中,以消除姿势的变化影响。在提取左心室心肌标签后,使用一个以左心室 ED 心肌为中心的边界框,裁剪每个片段并将其填充到 [x=80, y=80, z=80, t=1] 维。最后,对所有的片段进行人工质量控制,以排除包含层间强烈运动或左心室覆盖不足的扫描。作为附加测试数据库,作者选择了 ACDC MICCAI17 挑战训练数据库中的 20 个 HVOL 和 20 个 HCM,使用上述相同的方法进行预处理。将数据库划分成训练集、评估集和测试集,分别由 537 名(276 名 HVOL,261 名 HCM)、150 名(75 名 HVols,75 名 HCM)和 200 名(100 名 HVols,100 名 HCM)受试者组成。
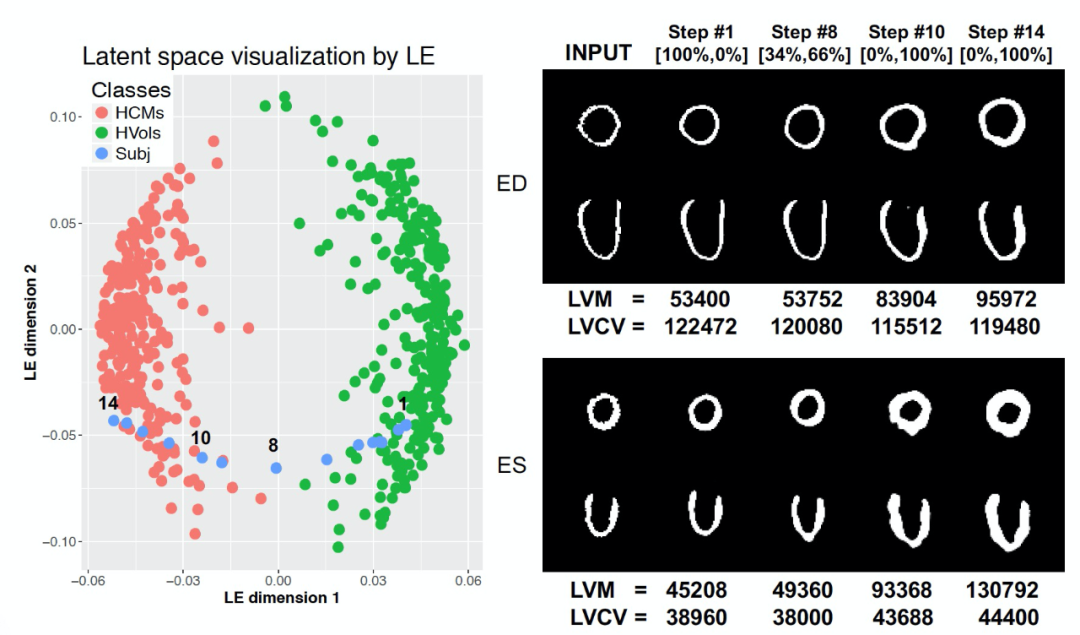
为了使潜在空间有可解释性,作者利用了一种潜在空间导航 (latent space navigation) 的方法: 从训练集中随机选择一个健康分割片段,使其分类为 HCM 的概率最大化。图 2 中右侧图中给出了在 ED 和 ES 阶段所选对象的原始片段、对应 VAE 重建结果,以及在潜在空间导航方法的四个不同迭代下重建的片段。图 2 中左侧图所示,为了进行可视化展示,使用拉普拉斯特征映射(Laplacian Eigenmaps,LE)将训练集片段的潜在 64 维表示μ与在每次迭代 t 中获得的潜在表示μ_t 一起缩减为二维空间。该技术允许建立一个潜在表示的邻域图,可用于监控所研究的从 HVol 簇到 HCM 簇的转换(浅蓝色点)。在右侧图示给出的每个步骤中,通过计算心肌体素的体积来计算每个片段的左心室心肌质量(LV mass,LVM)。此外,还将具有左心室腔标签的 LV 图谱分割非刚性地注册到每个分割片段中,通过计算血量体素(blood pool voxels)的体积来计算左心室压腔容积(LV cavity volume,LVCV)。最后,对于每个迭代,作者还报告了由预测网络计算得到的成为 HVol 或 HCM 的概率。从 HVol 到 HCM 的几何转换过程中,LVM 增高,LVCV 降低,室间隔壁厚度不对称增加,这也是这种病典型的重塑模式。
![]()
图 2. 左侧,训练集中每个受试者潜在表示μ的 LE 二维表示(红色和绿色圆点),通过潜在空间导航方法得到的随机健康形状的潜在表示μ_t 的 LE 二维表示(浅蓝色圆点);右侧,通过潜在空间导航方法得到的随机健康形状的潜在表示μ_t 的 LE 二维表示,以及对应于在 4 次示例性迭代时μ_t 的解码片段,同时还给出了 HVOls 和 HCM 的概率,以及计算出的 LVM 和 LVCV
本文提出了一个深度生成模型用于自动分类与心脏重构(cardiac remodeling)相关的心脏病,该模型利用的是直接从三维分割中学习的可解释任务特定解剖特征。本文所提出的模型的体系结构经过特殊设计,能够在原始分割空间中可视化和量化所学特征,使分类决策过程具有可解释性,并有可能实现对疾病严重程度的量化分析。此外,作者还提出了一种简单的方法能够在网络学习的低维流形中导航,作者给出的实验结果表明所得到的潜在表示能够用于监控患者的潜在临床效用。
本文提出的方法是可解释深度学习分类方法在医疗图像诊断中的一个有效应用,它可以
帮助临床医生改进诊断,并为患者分层处理提供参考
。这种方法并不局限于心脏领域,后续可以将其扩展到其他与病理形态变化相关的图像分析任务中。
3.2、MDNet:一个语义和视觉可解释的医学图像诊断网络[8]
![]()
近年来,深度学习技术的迅速发展对生物医学图像领域产生了显著的影响。例如,经典图像分析任务,如分割和检测等,支持从医学元数据中快速发现知识,帮助专家进行人工诊断和决策。再比如,医学中的自动决策任务(例如诊断),通常可被视为标准的深度学习分类问题。不过,现有的分类模型隐藏了其结论的基本原理,缺乏可解释的理由来支持其决策过程,通常不能直接作为辅助诊断的最佳方案。
在临床实践中,医学专家通常会撰写诊断报告,记录图像中的显微发现,以便辅助医生诊断病情和选择治疗方案。教会深度学习技术 / 模型自动模仿这一过程是可解释深度学习在医疗图像诊断领域中的有效应用。一个模型如果能够从视觉和语义上给出其诊断结果的基本原因解释,那么这个模型就具有重要的应用价值。
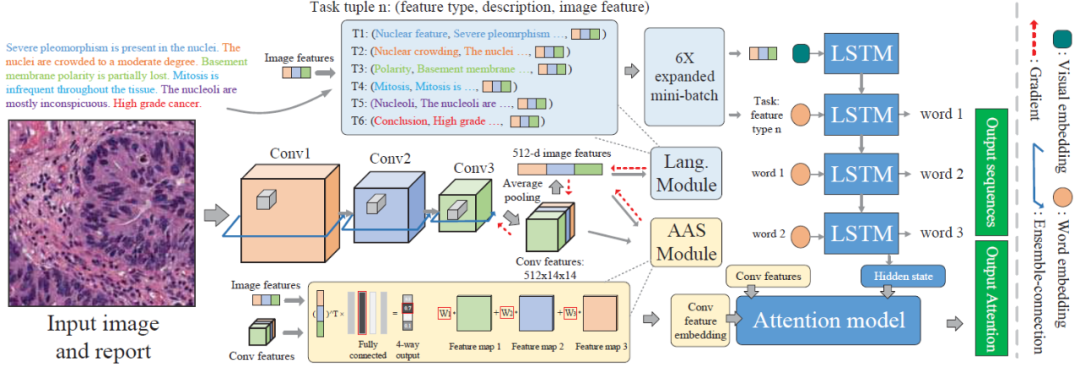
本文提出了一个
统一的网络(medical image diagnosis network,MDNet),它可以读取图像,生成诊断报告,通过症状描述检索图像,并将网络注意力可视化,通过建立医学图像与诊断报告之间的直接多模态映射为网络诊断过程提供依据
。MDNet 的完整应用过程见图 1。
![]()
为了验证 MDNet 的有效性,本文将 MDNet 应用于膀胱癌病理图像数据库的诊断报告中。在膀胱病理图像中,膀胱组织尿道细胞核大小和密度的变化或尿道肿瘤增厚,均提示癌变。对于这些特征的准确描述有利于诊断病情,对早期膀胱癌的鉴别至关重要。为了训练 MDNet,作者重点解决了从报告中直接挖掘判别性图像特征信息的问题,并学习了直接从报告句子词到图像像素的多模态映射。这个问题在医疗图像诊断中是非常重要的,因为支持诊断结论推理的判别性图像特征在报告中是 "潜伏" 的,而不是由特定的图像 / 对象标签明确提供的。有效利用报告中的这些语义信息,是进行图像语言建模的必要条件。
作者提出,本文是第一个研究开发可解释的基于注意力的深度学习模型,该模型可以明确地模拟医学(病理)图像诊断过程。对于图像建模部分,利用 CNN 实现了基于大小变化的图像特征进行图像表示。对于语言建模部分,利用 LSTM 从报告中挖掘判别信息,计算有效梯度来指导图像模型训练。作者使用端到端的训练方式,将注意力机制整合到语言模型中,并提出增强其与句子中词(Sentence Words)的视觉特征一致性,以获得更清晰的注意力图。
残差网络 ResNet 能够实现网络内部的信息流动。每一个跳连接(Skip-connected)的计算单元称为剩余块。在一个有 L 个残差块的 ResNet 中,第 l 个残差块的前向输出 y_L 和损失 L 的梯度即其输入 y_l 的定义分别为:
![]() (1)
(1)
![]() (2)
(2)
其中,F_m 由连续批归一化、整流线性单元(ReLU)和卷积模块组成。
残差块中的一个跳转连接提供了两条信息流路径,因此随着网络的深入,网络中总的路径数目呈指数级增长。这种指数集成(Exponential Ensembles)提高了网络性能。ResNet 中连接卷积层的分类模块包括全局平均池化层(a Global Average Pooling Layer)和全连接层。这两个层的数学描述如下:
![]() (3)
(3)
其中,p^c 表示类别 c 的概率输出,(i, j)表示空间坐标,w^c 表示应用到 p^c 上的全连接层权重矩阵的第 c 列。将公式(1)插入到公式(3)中,p^c 为加和集成输入的加权平均:
![]() (4)
(4)
作者认为,在这种情况下,在分类模块中使用单一的加权函数不是最优的。这是因为所有合集的输出都共享分类器,以至于其单个特征的重要性被削弱。为了解决这个问题,作者建议将集合输出解耦,并对它们分别应用分类器:
![]() (5)
(5)
与公式 (4) 相比,公式(5)为每个集合输出分配了单独的权重(w_1)^c 和(w_L)^c,这使得分类模块能够独立决定来自不同残差块的信息重要性。作者对 ResNet 架构进行 "重新设计" 来实现上述思想,即采用一种新的方式来跳转连接残差块,定义如下。
![]() (6)
(6)
其中,⊗为连接操作。将这种跳转连接方案定义为集合连接(Ensemble Connection)。它允许残差块的输出直接并行地流经并联的特征图到分类层,这样分类模块给所有网络集合输出分配权重,并将它们映射到标签空间。由图 2 可以看出,这种设计也保证了信息流的畅通无阻,克服了梯度消失效应。
![]()
图 2. MDNet 的整体说明,以膀胱图像及其诊断报告为例。图像模型生成一个图像特征,以任务元组和由辅助注意力锐化(Auxiliary Attention Sharpening,AAS)模块计算的 Conv 特征嵌入(用于注意力模型)的形式传递给 LSTM。LSTM 根据指定的图像特征类型执行预测任务
在语言建模方面,使用 LSTM 通过最大化句子上的联合概率来建模诊断报告:
![]() (7)
(7)
其中,{x0,......,xT }是句子词(编码为独热向量)。LSTM 参数θ_L 用于计算几种 LSTM 内部状态。通过上下文向量 z_t 将 "软" 注意力机制整合到 LSTM 中,以捕捉局部的视觉信息。为了进行预测,LSTM 将上一时间步 x_(t-1)的输出以及隐藏状态 h_(t-1)和 z_t 作为输入,并计算下一个词 x_t 的概率,如下所示:
![]() (8)
(8)
其中,E 为字嵌入矩阵。G_h 将 h_t 解码到输出空间。
注意力机制动态计算一个权重向量来提取支持单词预测的部分图像特征,该特征被解释为一个明确网络捕捉视觉信息位置的注意力图。注意力是支持网络视觉解释能力的主要部分。作者提出了辅助注意力锐化(Auxiliary Attention Sharpening,AAS)模块,以提高注意力机制的学习效果(见图 2 描述)。与将直接监督放在权重向量 a_t 上的处理方式不同,作者提出利用全局平均池化的隐含类特异性本地化属性来解决这个问题,以支持图像 - 语言的对齐处理。利用下式计算 z_t:
![]() (9)
(9)
其中,W_att 和 W_h 为学习嵌入矩阵。C(I)表示由图像模型生成的维度为 512×(14·14)的卷积特征图。c 表示通过 w^c 嵌入得到的 196 维的卷积特征。
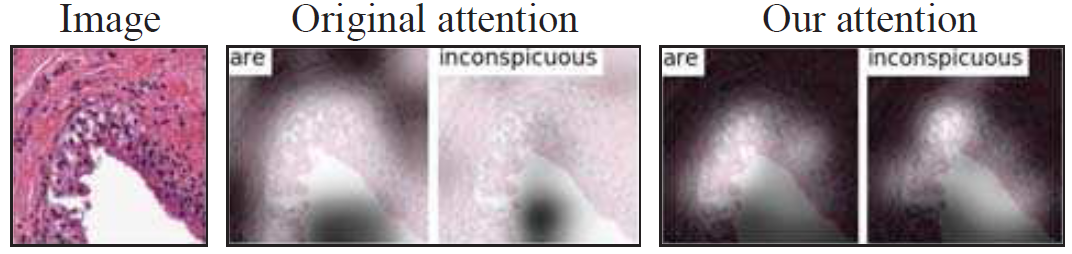
经典注意力机制在 LSTM 里面隐性地学习 w^c。而 AAS 增加了一个额外的监督来显式学习,以提供更有效的注意力模型训练,具体可见图 2。图 3 给出了经典方法和本文所提出方法的定性对比结果。
![]()
图 3. 经典方法(中间)和本文方法(右边)生成的注意力图。本文方法能够在关键信息区域(尿道)中产生更多的焦点注意力
CNN 提供一个编码的图像特征 F(I)作为 LSTM 输入 x_0,然后用一个特殊的 START token 作为 x_1 来告知预测过程开始。生成有效的梯度 F(I)是图像模型优化的关键。
一份完整的医学诊断报告会对图像中的多种症状进行全面的描述,然后会具体针对一种或多种类型疾病的给出专门的诊断结论。例如,放射学图像包括多个疾病标签,每个症状具体描述一种类型的图像(症状)特征。有效地利用不同描述中的语义信息对通过 LSTM 生成有效的梯度 F(I)至关重要。
在本文方法中,专门令一个 LSTM 从特定的描述中鉴别信息。所有的描述模型都共享 LSTM。这样一来,每个图像特征描述模型就成为了一个生成完整报告的函数,将该函数定义为 K。在训练阶段,给定一个包含 B 对图像和报告的小批量,将小批量发送到图像模型后对每个样本进行内部复制,得到一个 K×B 大小的小批量作为 LSTM 的输入。LSTM 的输入和输出分别定义为:
![]() (10)
其中,W_F 表示学习的图像特征嵌入矩阵,S(e)表示第 e 个图像特征类型的独热表示。使用 (x_1)^e 通知 LSTM 目标任务的开始。在后向传播阶段,将全部复制的梯度 F(I) 融合起来。
整个模型包含了三组参数:图像模型 D 的参数θ_D、语言模型 L 的参数θ_L 和 AAS 模块 M 的参数θ_M。MDNet 的完整优化问题如下:
(10)
其中,W_F 表示学习的图像特征嵌入矩阵,S(e)表示第 e 个图像特征类型的独热表示。使用 (x_1)^e 通知 LSTM 目标任务的开始。在后向传播阶段,将全部复制的梯度 F(I) 融合起来。
整个模型包含了三组参数:图像模型 D 的参数θ_D、语言模型 L 的参数θ_L 和 AAS 模块 M 的参数θ_M。MDNet 的完整优化问题如下:
![]() (11)
(11)
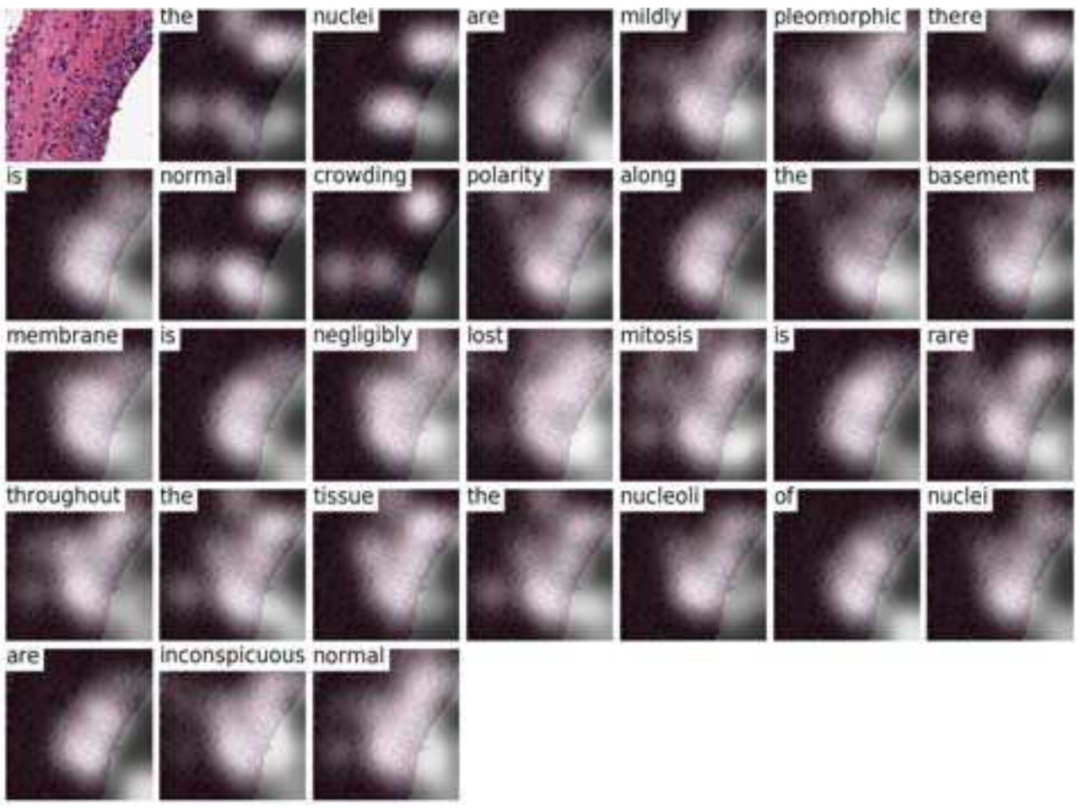
其中,{I,l_c,l_s}表示训练三元组。可以直接使用梯度下降算法求解θ_M 和θ_L。但更新θ_D 需要同时依赖于两个模块的梯度。本文提出一种反向传播机制,允许两个模块的复合梯度相互适应。基于递归生成网络和多层感知器的混合体来计算梯度,θ_D 的更新如下:
![]() (12)
(12)
本文实验使用的数据库为膀胱癌影像诊断报告数据库(The bladder cancer image and diagnostic report dataset,BCIDR)。该数据库中的图像采用 20 倍物镜获取,从 32 例有乳头状尿路上皮肿瘤风险的患者的膀胱组织中提取苏木精和伊红(H&E)染色切片,拍摄全幻灯片图像。从这些载玻片中,随机抽取 1000 张靠近尿路上皮肿瘤的 500x500 RGB 图像(每张幻灯片生成的图像数量略有不同)。使用一个网络界面来显示每个图像(没有病人的诊断信息),然后请病理学家为每个图像提供了一段描述观察结果的文字,以明确五种类型的细胞外观特征,即核多形性状态(the state of nuclear pleomorphism)、细胞拥挤状态(cell crowding)、细胞极性(cell polarity)、有丝分裂(mitosis),突出核(prominence of nucleoli)。病理学家给出的诊断结论分为四类:即正常、低恶性潜能乳头状尿路上皮肿瘤(papillary urothelial neoplasm of low malignant potential,PUNLMP)/ 低度恶性肿瘤、高度恶性肿瘤和信息不足。在这个过程之后,四个医生(非膀胱癌专家)用他们自己的语言撰写了另外四个文字描述,但是他们在撰写过程中参考了病理学家的描述以保证准确性。因此,每幅图像中总共有五篇描述报告。每份报告的长度在 30 到 59 个字之间。随机选取 20%(6/32)的患者数据(包括 200 张图像)作为测试数据,其余 80% 的患者数据(包括 800 张图像)用于训练和交叉验证。
作者选择经典的图像字幕方案(image captioning scheme)作为基线对比方法[9],该方法首先训练 CNN 来表示图像,然后训练 LSTM 生成描述。此外,实验中使用 GoogLeNet 而不是它最初使用的 VGG,因为前者在 BCIDR 上的性能更好。作者单独训练了 MDNet 中的图像模型,记做 EcNet,且训练了一个小型的 EcNet 用于实验(深度 38,宽 8,包括 2.3M 参数)。实验中用于对比的全部模型共享预训练 GoogleNet 和 EcNet。在训练 LSTM 时,作者测试了使用和未使用微调 CNNs 的情况。
MDNet 本身是基于端到端的训练方式得到的,不过为了与基线方法进行对比,作者在消融实验中测试了两种使用基线策略训练 MDNet 的情况。在这两种情况下没有应用优化处理,因此与基线方法的差异是任务分离的 LSTM 和整合注意力模型。
图 4 给出了生成报告的实验结果示例。使用本文提出的注意力模型计算得到了句子引导的注意力,其中每个注意力图对应一个预测单词。参考病理学家的观察结果,本文方法计算得到的注意力图能够集中关注于有效信息区域而避免引入更多的无效信息区域。
![]()
图 4. 图像模型预测诊断报告(左上角)。语言模型关注每个预测单词的特定区域,最受关注的是尿路上皮肿瘤,它被用来诊断癌症的类型
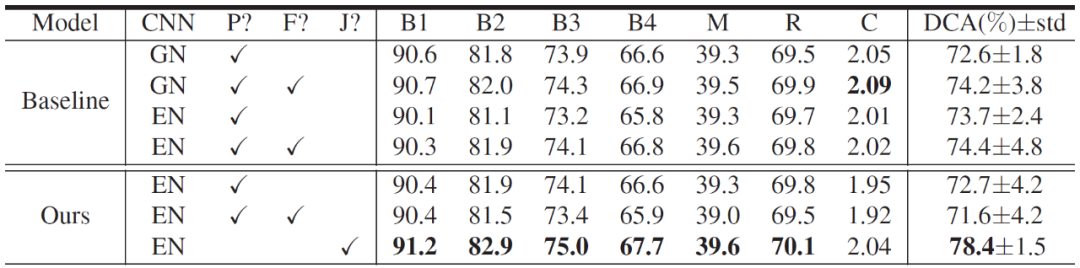
表 1 给出了一个诊断报告生成实验示例。实验结果给出了常用的图像字幕评价指标得分,包括 BLEU(B)、METEOR(M)、Rouge-L(R)和 CIDEr(C)。诊断报告的语言结构比自然图像标题更具规则性。实验结果表明,标准 LSTM 可以捕捉到总体结构,从而得到与 MDNet 相似的度量分数。本文实验更关注的是训练得到的模型是否准确地表达了病理意义上的关键词。实验结果中还给出了从生成的报告句子中提取的预测诊断结论准确性(diagnostic conclusion accuracy,DCA)。由实验结果可知,MDNet 效果远优于其它基线方法。此外,实验结果还表明采用微调预训练方法,例如 EcNet 和 GoogleNet,能够获得更好的效果,但同时会提升模型的不稳定性(标准差较大)。
表 1. 生成描述质量和 DCA 评分的定量评价。P、 F 和 J 分别表示是否使用预先训练的 CNN、在训练 LSTM 时是否微调预训练 CNN,以及是否使用 MDNet。第 5 行和第 6 行为消融实验结果,GN 和 EN 表示 GoolgeNet 和 EcNet
![]()
本文提出了一种非属性深度学习模型:MDNet,用以建立医学图像和医学诊断报告之间的多模态映射关系。MDNet 为可解释深度学习技术在医疗图像诊断中应用提供了一个新的视角:生成诊断报告和与报告对应的网络关注(Network Attention),借助于注意力机制使得网络诊断和决策过程具有语义和视觉上的可解释性。
基于本文的工作,作者提出了如下的研究方向:建立大规模病理图像报告数据库、实现对小生物标记物定位的精细关注、将改进后的 MDNet 应用于全幻灯片诊断等。
本文关注的是可解释深度学习技术在医疗图像诊断中的应用。很多深度学习技术在实际应用中都获得了较好的效果,例如图像识别、文本识别、语音识别等。这些技术得以推广应用的领域主要是智能客服、翻译、视频监控、搜索、推荐系统等等,这些领域共通的特点是 “对模型 / 算法的可解释性要求不高” 并且“容错率高”。以智能客服应用为例,可以利用深度学习技术提高所生成问答语句的准确度,且生成错误的回答语句并不会对用户有直接的危险。但是如何生成的这些文本、不同参数与文本 / 语句 / 字符的关系究竟是什么,这些问题并没有答案,在实际应用即使没有明确这些答案也不影响利用深度学习技术改进智能客服的水平,人们也不会因为没有明确答案就否定智能客服给出的结论。但是在医学领域,模型 / 算法的可解释性要求就非常高了。试想,你会根据一条不知道什么原因、不知道根据什么判断得出的结论去治疗疾病么?你会相信一条不知道如何解释的病情诊断意见么?
结合目前应用于医疗图像诊断中的两类可解释深度学习方法:属性方法和非属性方法,本文具体分析了几篇文章如何根据 CNN 特征、利用生成模型或注意力机制实现或分析医疗图像诊断的可解释性。从几篇文章的分析结果可以看出,每篇文章提出的方法针对的都是不同疾病图像、不同成像种类的图像,这也是深度学习 / 机器学习方法应用于医学领域的一个显著特点:方法是疾病 / 成像模式相关的。不同疾病的图像区别太大,目前的研究主要局限在针对具体疾病图像具体分析适用的可解释模型 / 方法。不过,这些方法都是可解释深度学习技术在医疗图像诊断领域中应用的有益探索,随着越来越多的研究人员关注可解释性,期望能推动深度学习技术在医学领域中的规模化推广应用。
[1] Singh, Amitojdeep , S. Sengupta , and V. Lakshminarayanan . "Explainable deep learning models in medical image analysis." Journal of Imaging 6.6(2020):52. https://arxiv.org/pdf/2005.13799.pdf
[2] Meyes, R.; de Puiseau, C.W.; Posada-Moreno, A.; Meisen, T. Under the Hood of Neural Networks: Characterizing Learned Representations by Functional Neuron Populations and Network Ablations. arXiv preprint arXiv:2004.01254 2020.
[3] Alber, M.; Lapuschkin, S.; Seegerer, P.; Hägele, M.; Schütt, K.T.e.a. iNNvestigate neural networks. Journal of Machine Learning Research 2019, 20, 1–8. http://arxiv.org/abs/1808.04260
[4] Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). arXiv preprint arXiv:1711.11279 2017.
[5] Lee, H.; Kim, S.T.; Ro, Y.M. Generation of Multimodal Justification Using VisualWord Constraint Model for Explainable Computer-Aided Diagnosis. In Interpretability of Machine Intelligence in Medical Image Computing and Multimodal Learning for Clinical Decision Support; Springer, Cham, 2019; pp. 21–29.
[6] Van Molle, P.; De Strooper, M.; Verbelen, T.; Vankeirsbilck, B.; Simoens, P.; Dhoedt, B. Visualizing convolutional
neural networks to improve decision support for skin lesion classification. In Understanding and Interpreting
Machine Learning in Medical Image Computing Applications; Springer, Cham, 2018; pp. 115–123. https://arxiv.org/pdf/1809.03851.pdf
[7] Biffi, Carlo , et al. "Learning Interpretable Anatomical Features Through Deep Generative Models: Application to Cardiac Remodeling." (2018).
https://arxiv.org/pdf/1807.06843.pdf
[8] Zhang Z , Xie Y , Xing F , et al. MDNet: A Semantically and Visually Interpretable Medical Image Diagnosis Network[J]. 2017:3549-3557. https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhang_MDNet_A_Semantically_CVPR_2017_paper.pdf
[9] A. Karpathy and L. Fei-Fei. Deep visual-semantic alignments for generating image descriptions. In CVPR, 2015.
本文作者为
仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为
模式识别
、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。




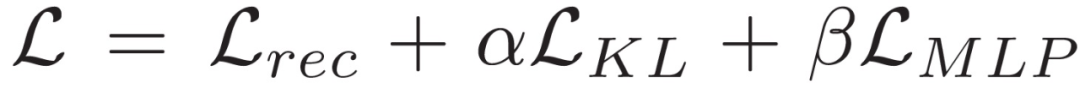
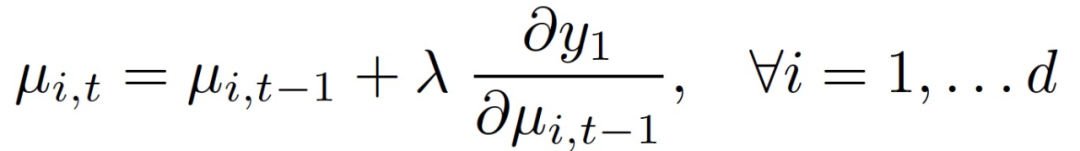


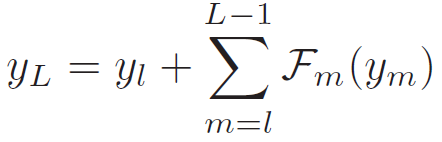
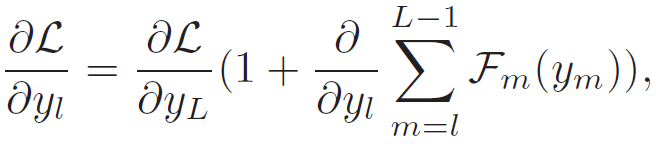
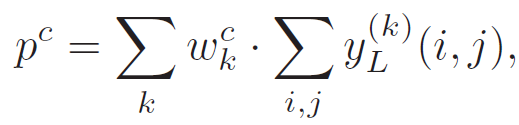
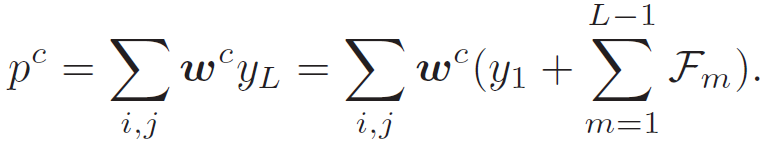
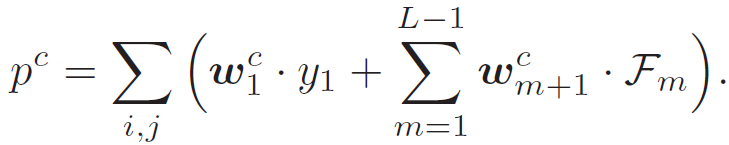
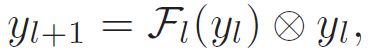
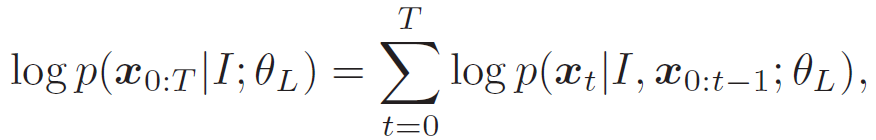
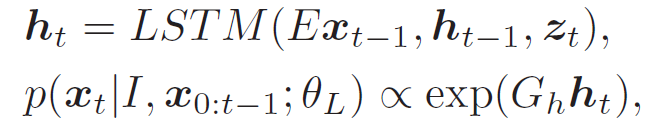
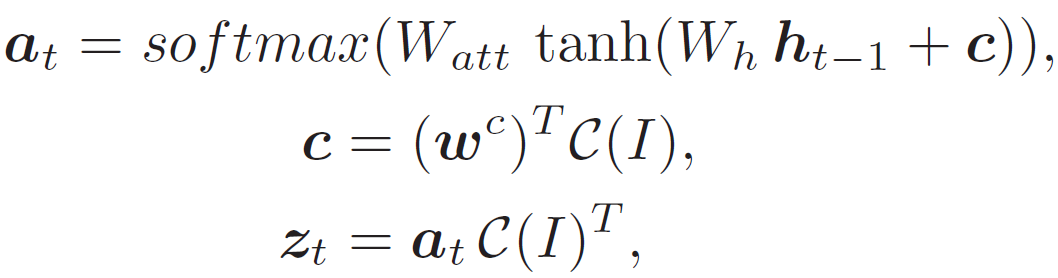
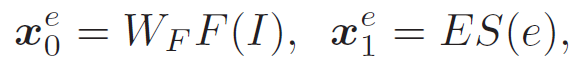 (10)
(10)