可解释人工智能
·

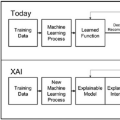
深度神经网络在计算机视觉、计算语言学和人工智能等领域的广泛应用无疑带来了巨大的成功。然而,DNNs成功的基本原理、DNNs的可信性和DNNs对抗攻击的恢复能力仍然很大程度上缺乏。在可解释人工智能的范围内,对网络预测解释可信度的量化和DNN特征可信度的分析成为一个引人注目但又有争议的话题。相关问题包括: (1)网络特征可信度的量化; (2)DNNs解释的客观性、鲁棒性、语义严谨性; (3)可解释神经网络解释性的语义严谨性等。重新思考现有可解释机器学习方法的可信性和公平性,对可解释机器学习的进一步发展具有重要的价值。
本教程旨在将关注人工智能可解释性、安全性和可靠性的研究人员、工程师以及行业从业人员聚集在一起。本教程介绍了一些关于上述问题的新发现,这些发现来自演讲者最近的论文和一些经典研究。对当前可解释人工智能算法的优点和局限性的批判性讨论提供了新的前瞻性研究方向。本教程预计将对医疗诊断、金融和自动驾驶等关键工业应用产生深远影响。
https://ijcai20interpretability.github.io/

成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2021年3月3日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年3月3日