AI计算量每年增长10倍,摩尔定律也顶不住 | OpenAI最新报告
晓查 发自 凹非寺
量子位 编译 | 公众号 QbitAI
今天OpenAI更新了AI计算量报告,分析了自2012年以来AI算法消耗算力的情况。
根据对实际数据的拟合,OpenAI得出结论:AI计算量每年增长10倍。从AlexNet到AlphaGo Zero,最先进AI模型对计算量的需求已经增长了30万倍。

英伟达的黄仁勋一直在强调摩尔定律已死,就是没死也顶不住如此爆炸式的算力需求啊。
至于为何发布AI计算量报告?OpenAI说,是为了用计算量这种可以简单量化的指标来衡量AI的发展进程,另外两个因素算法创新和数据难以估计。
每年增长10倍
OpenAI根据这些年的实际数据进行拟合,发现最先进AI模型的计算量每3.4个月翻一番,也就是每年增长10倍,比摩尔定律2年增长一倍快得多。
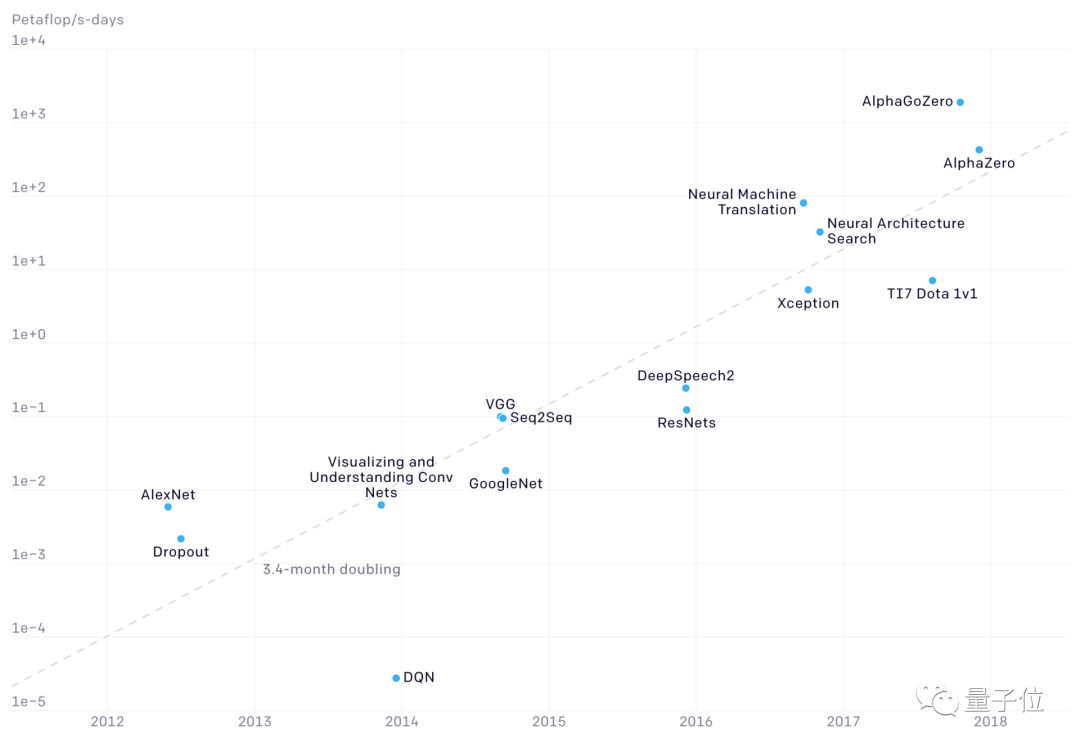
上图中的纵坐标单位是PetaFLOPS×天(以下简写为pfs-day),一个pfs-day是以每秒执行1015次浮点运算的速度计算一天,或者说总共执行大约1020次浮点运算。
需要注意的是,上图使用的是对数坐标,因此AlphaGoZero比AlexNet的运算量多了5个数量级。
从2012年至今,按照摩尔定律,芯片算力只增长了7倍,而在这7年间AI对算力的需求增长了30万倍。硬件厂商是否感觉压力山大?
OpenAI还分析了更早期的数据,从第一个神经网络感知器(perceptron)诞生到2012年AI技术爆发前夕的状况。
在之前的几十年中,AI计算量的增长速度基本和摩尔定律是同步的,2012年成为AI两个时期的分水岭。
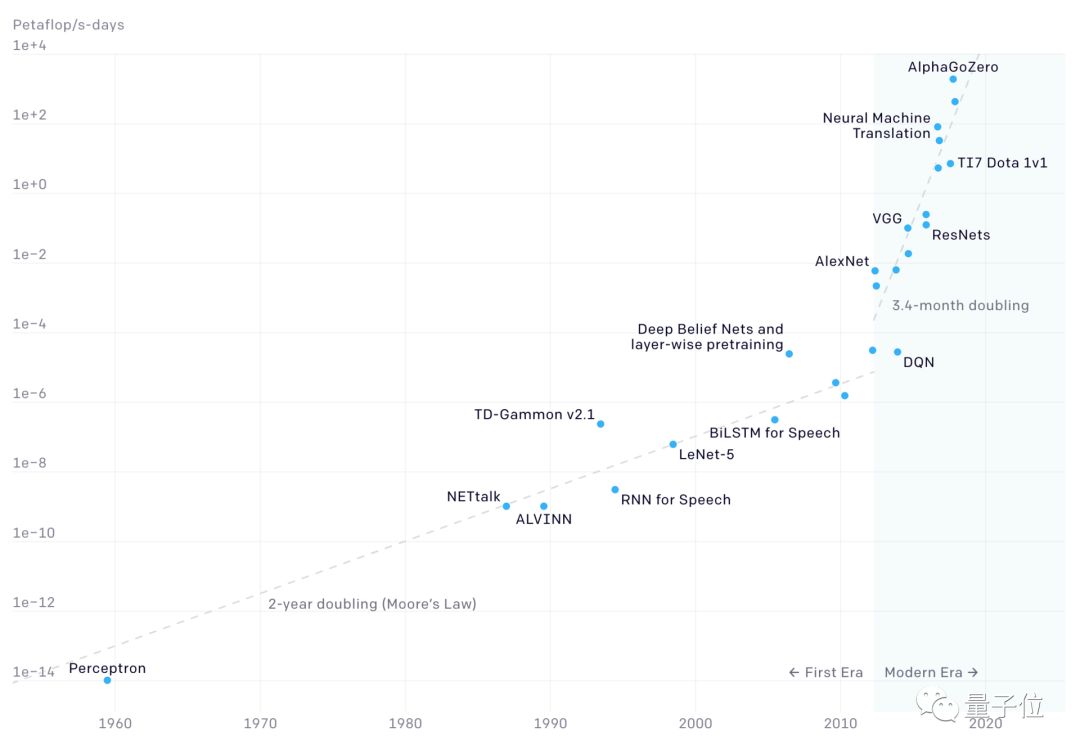
(注:OpenAI原报告引用18个月作为摩尔定律的翻倍时间,之后修正为2年。)
AI硬件的4个时代
对算力的爆炸式需求也催生了专门用于AI运算的硬件,从1959年至今,AI硬件经历了4个不同的时期。
2012年之前:使用GPU进行机器学习运算并不常见,因此这部分的数据比较难准确估计。
2012年至2014年:在多个GPU上进行训练的设备并不常见,大多数使用算力为1~2 TFLOPS的1到8个GPU,计算量为0.001~0.1 pfs-day。
2014年至2016年:开始大规模使用10~100个GPU(每个5~10 TFLOPS)进行训练,总计算量为0.1-10 pfs-day。数据并行的边际效益递减,让更大的训练量受到限制。
2016年至2017年:更大的算法并行性(更大的batch size、架构搜索和专家迭代)以及专用硬件(TPU和更快的连接),极大地放宽了并行计算的限制。
未来还会高速增长吗?
OpenAI认为,我们有很多理由相信,AI计算量快速增长的需求还会继续保持下去。但是我们不必太过担心算力不够。

首先,越来越多的公司开发AI专用芯片,这些芯片会在一两年内大幅提高单位功率或单位价格的算力(FLOPS/W或FLOPS/$)。另一方面并行计算也会成为主流,没有太强的芯片还可以堆数量。
其次,并行计算也是解决大规模运算的一个有效方法,未来也会有并行算法创新,比如体系结构搜索和大规模并行SGD等。
但是,物理规律限制芯片效率,成本将限制并行计算。
如今训练一个最大模型需要的硬件购置成本高达几百万美元,不是每个企业都可以像英伟达那样,用512个V100花费10天训练一个模型的。
报告地址:
https://openai.com/blog/ai-and-compute/
— 完 —
问卷福利!人工智能行业白皮书即将发布
量子位&IDC中国将联合发布「2019中国人工智能行业白皮书」,并于12月6日MEET大会重磅发布,特请小伙伴们填写一下问卷,谢谢大家支持~
填写福利:发布后第一时间获得白皮书,AI内参、大会观众票3折优惠券。 点击下图即可填写问卷、领取问卷福利:

榜单征集!三大奖项,锁定AI Top玩家
2019中国人工智能年度评选启幕,将评选领航企业、商业突破人物、最具创新力产品3大奖项,并于MEET 2020大会揭榜,欢迎优秀的AI公司扫码报名!


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



