点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
![]()
【导读】今天,恰逢五四青年运动发源地北大建校122周年,B站发布了献给新一代的演讲《后浪》引发热议。北大助理教授朱占星在知乎为广大致力于投身深度学习研究的「后浪」们,提供了6个研究方向的建议。
![]()
这是120年前梁启超写下的热血台词,激励着一代代中国青年们。
100年前的今天,一群由大学生带头的运动,彻底掀起了探索强国之路的新文化运动,改变了当时的中国。
而如今,工作的压力、前途的渺茫,让社交网络上「丧」气弥漫。以至于有些人开始质疑当代的年轻人是「垮掉的一代」。
属于年轻人的B站,发布了一则超燃视频,回应质疑,向「丧气」宣战!
这个视频,再次提醒我们正处在无所畏惧的年纪,容得下更多元的文化;提醒我们,拥有比历史上任何一代都更广阔的视野。
我们坐拥最新科技,学习语言或者手艺、去地球上任何地方旅行、结识志趣相投的朋友变得前所未有的简单和方便。
我们应该给自己打打鸡血,就像海贼王里那些「愣头青」们一样,拼了命也要向着梦想前行
![]()
就像歌里唱的:我们是冠军(we are the champions)!
我们做着百年前人们想都不敢想的事情:人工智能、深度学习。而且,我们让中国在这个领域中,站在了世界之巅!
而追溯到1980年福岛邦彦新认知机的提出,深度学习的历史还不到50年。
北京大学数学科学学院助理教授朱占星在知乎上,为致力于深度学习的「后浪」们,提出了6点非常有参考价值的建议。
![]()
![]()
https://www.zhihu.com/question/385326992/answer/1164005349
《Understanding deep learning requires rethinking generalization》
地址:https://arxiv.org/abs/1611.03530
论文作者通过大量的系统性实验,展示了这些传统的方法是如何无法解释为什么大型神经网络在实践中能够很好地泛化。
朱占星提出,理解深度学习获得泛化能力的来源非常重要,需要掌握数据、模型和训练算法技巧的分析。
其次,了解深度学习学到的特征表示究竟是什么,宽度、深度、跳连等究竟在 representation learning 上所起的作用。
另外就是深度学习稳健性。包括对噪声变化、对结构变化、对对抗样本的稳健性。
朱占星认为在新模型的构建方面,主要目的是希望深度学习满足某种性质或要求。可以从以下几个方面入手:
-
可解释性强、可信能力强的模型的构建(有关可解释性的问题,我们下面会给出更详细的解读)
-
具有因果推断能力的模型。朱占星认为这是个很重要的方向,深度学习很大的成功在于模式识别和函数拟合,其他能力很弱
-
包括semi-supervised, self-supervised(或unsupervised), transfer learning ,meta-learning等。
朱占星提到,已有的深度学习的成功展现在大数据的有监督上,目前关于这些挑战场景上的理解还很少,虽然大家一顿猛发文章,本质是什么尚不清晰,尤其是背后的设计模型的核心 principle 是什么还是很模糊的。
新的数据结构下的问题,典型代表是graph,大型 table及结构化的数据上。
4 Learning-enhanced algorithms
这是朱占星自己起的名字。根据他的说法,Learning-enhanced algorithms主要指如何利用数据驱动的方式,尤其是深度学习强大表达能力和灵活性,来解决一些传统算法的瓶颈问题。
比如如何用learning的思路来解决一些组合问题中的搜索策略;如何从解决多个问题中总结数据或者问题的经验,来拓展到解决类似问题上。
朱占星称,对应用友好的模型和算法,尤其是精细场景以及实际落地应用中。
毕竟深度学习的很多问题是应用驱动的,如何更好的解决实际应用问题也极其关键。这里涉及很多,比如模型动态更新(包括类别,数据的分布变化,数据的异质,多模态等),快速部署(衍生很多加速算法等),便捷部署(衍生 automl),可视化,模块化等。
朱占星认为还有一个非常重要的方向就是软硬结合。不过最终深度学习这个框架和方法最终会像最小二乘法一样,被广泛应用,成为标准工具,但会不断的有新的东西能挖出来。
从朱占星的建议中我们其实也能够看出,可解释性将成为未来深度学习领域一个非常重要的研究方向。
深度学习模型能用「魔法」或「炼金术」提供人们想要的东西。然而,严酷的现实是,如果不对模型进行合理足够的解释,现实中的项目就无法落地。比如预测潜在的犯罪、司法量刑、信用评分、欺诈发现、健康评估、贷款借款、自动驾驶等,模型的解释是不可或缺的。
具体到深度学习/机器学习领域,尽管高度的非线性赋予了多层神经网络极高的模型表示能力,配合一些调参技术可以在很多问题上取得不错的效果。
![]()
大家如果经常关注AI新闻,深度学习的最新突破甚至经常让人产生AI马上要取代人类的恐惧和幻觉。
但正如近日贝叶斯网络的创始人Pearl所指出:「几乎所有的深度学习突破性的本质上来说都只是些曲线拟合罢了」。
他认为今天人工智能领域的技术水平只不过是上一代机器已有功能的增强版,
所以可解释性仍然任重道远。
广义上的可解释性,
指在我们需要了解或解决一件事情的时候,获得的可以帮助我们理解这件事的信息。比如我们在调试bug的时候,需要通过变量审查和日志信息定位到问题出在哪里。
反过来讲,如果在一些情境中我们无法得到足够的信息,那么这些事情对我们来说就是不可解释的。
比如刘慈欣的短篇《朝闻道》中提出的「宇宙的目的是什么」,这个问题一下子把无所不知的排险者卡住了,因为再高等的文明都没办法理解和掌握造物主创造宇宙时的全部信息,这些终极问题对我们来说永远都是不可解释的。
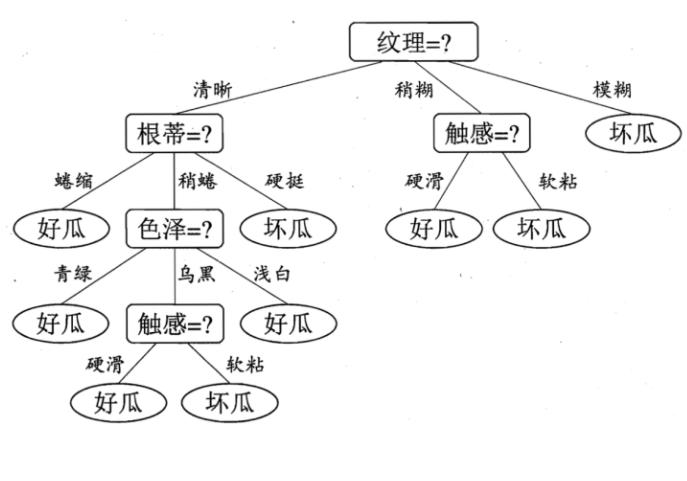
而具体到机器学习领域来说,以用户最友好的决策树模型为例,模型每作出一个决策都会通过一个决策序列来向我们展示模型的决策依据,以周志华老师的西瓜书为例,决策模型判断好瓜还是坏瓜,每一步都有详细的依据,根据纹理、根蒂、色泽、触感等进行判断。
而且决策树自带的基于信息论的筛选标准,也有助于帮助我们理解模型决策过程中哪些变量起到了关键作用。所以我们认为:决策树模型是一个具有比较好的可解释性的模型。
再以用户最不友好的多层神经网络模型为例,模型产生决策的依据是什么呢?以1/(e^-(21/(e^(-(2x+y))+1) + 31/(e^(-(8x+5*y))+1))+1) 是否大于0.5为标准(这已经是最简单的模型结构了),这一连串的非线性函数让人难以直接理解神经网络的“脑回路”,所以深度神经网络习惯性被大家认为是黑箱模型。
不可解释性的黑箱性质,将严重制约深度学习的应用和发展。在人类生命财产密切相关的领域如金融、医疗、健康、保险等,亟待可解释性的「后浪」。
作者夕小瑶是自然语言处理的研究者,也是知乎的优秀答主,一位「后浪」。
他花了小半年的时间研究词向量迁移到分类模型时的训练行为和结果可解释性问题,「相信根本没有人在乎这个问题的,简直感觉自己就是一个民科瞎搞的既视感」,一次次被拒,仍然死缠烂打求审稿人给建议,帮他完善这篇论文。
最终,论文没有被顶会接收,而是中了一个不怎么出名的水会。后来自己发现论文建模有缺陷,怕误导别人,所以在收到accept邮件后的第二天又发了封邮件主动撤稿了。
虽然历经半年最后在这件事情上零产出,但由衷感觉「解开深度学习黑箱是很有挑战性但也非常有意思的事情」。
在大多数人把调参奉为圭臬的时代,还是有一些年轻的「后浪」们,渴望探索深度学习的黑箱,即使很难,难到努力半年零产出,还是初心不改。
可解释性部分引用自:http://wangtingjun.com/posts/cfa2eaff/
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1300+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
请给CVer一个在看!![]()