MIT高赞深度学习教程:一文看懂CNN、RNN等7种范例(TensorFlow教程)

新智元2019新年寄语
2018年人工智能成为重塑世界格局的关键。谷歌BERT模型刷新多项自然语言处理纪录,DeepMind则用星际争霸II对局再次引爆机器智能无限可能。阿里与华为分别推出AI芯片,作为底层支撑的计算体系结构也将迈入黄金十年发展期。
新智元2018年实现全球超过50万核心产业用户互联。2019新春,中国人工智能将迎来全新的竞争挑战与生态建设契机,新智元邀你与全球人工智能学术、产业精英一起,以开放的胸怀和坚毅的决心,成就AI新世界!
——新智元创始人兼CEO 杨静

新智元报道
来源:medium
作者:Lex Fridman 编辑:肖琴
【新智元导读】作为MIT的深度学习基础系列课程的一部分,本文概述了7种架构范例的深度学习,每个范例都提供了TensorFlow教程的链接。
我们不久前介绍了 MIT 的深度学习基础系列课程,由 MIT 学术研究员 Lex Fridman 开讲,将介绍使用神经网络解决计算机视觉、自然语言处理、游戏、自动驾驶、机器人等领域问题的基础知识。
更多阅读:
【免费资源】MIT《深度学习基础》第一课 68 分钟视频 + 69 页 PPT
作为讲座的一部分,Lex Fridman 撰文概述了 7 种架构范例的深度学习,每个范例都提供了 TensorFlow 教程的链接。以下是麻省理工学院课程 6.S094 的深度学习基础课程第一课的视频:
深度学习是表示学习 (representation learning):从数据中自动形成有用的表示。我们如何表示世界,可以让复杂的东西对我们人类和我们构建的机器学习模型来说都显得更简单。
对于前者,我最喜欢的例子是哥白尼于 1543 年发表的日心说,日心说认为太阳是宇宙的中心,完全推翻了之前把地球放在中心的地心说。在最好的情况下,深度学习可以让我们自动完成这一步,从 “特征工程” 过程中去掉哥白尼 (即,去掉人类专家)。

日心说 (1543) vs 地心说 (6th century BC)
在高级别上,神经网络可以是编码器,可以是解码器,也可以是两者的组合:
编码器在原始数据中找到模式,以形成紧凑、有用的表示 (representations)。
解码器从这些表示中生成高分辨率数据。生成的数据可以是新的示例,也可以是描述性知识。
其余的则是一些聪明的方法,可以帮助我们有效地处理视觉信息、语言、音频 (第 1–6项),甚至可以在一个基于这些信息和偶尔的奖励的世界中采取行动 (第 7 项)。下面是一个总体的图示:
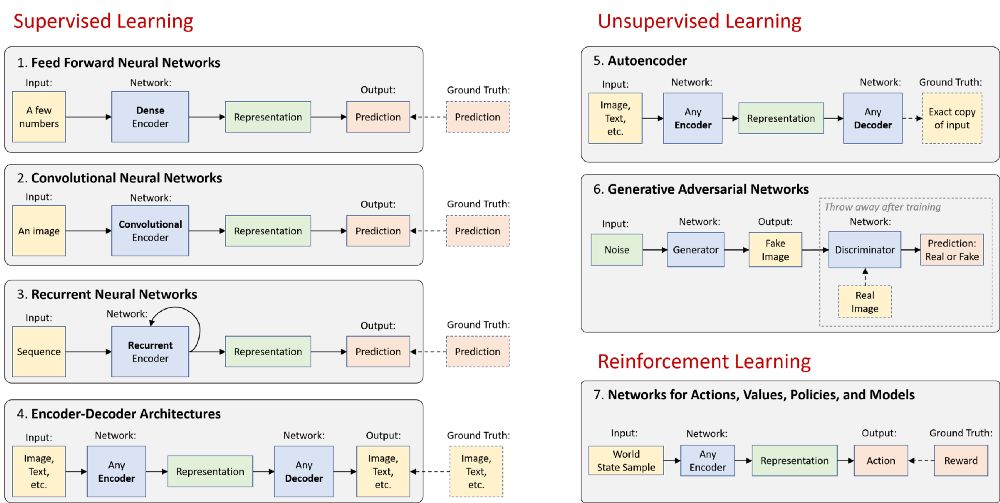
在下面的部分中,我将简要描述这 7 种架构范例,并提供每个范例的演示性TensorFlow 教程的链接。请参阅最后的 “基础拓展” 部分,该部分讨论了深度学习的一些令人兴奋的领域,不完全属于这七个类别。
TensorFlow 教程地址:
https://github.com/lexfridman/mit-deep-learning/blob/master/tutorial_deep_learning_basics/deep_learning_basics.ipynb
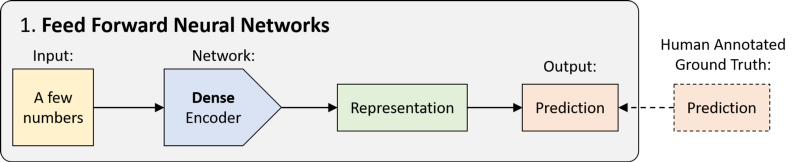
前馈神经网络 (Feed Forward Neural Networks, FFNNs) 的历史可以追溯到 20 世纪 40年代,这是一种没有任何循环的网络。数据以单次传递的方式从输入传递到输出,而没有任何以前的 “状态记忆”。从技术上讲,深度学习中的大多数网络都可以被认为是FFNNs,但通常 “FFNN” 指的是其最简单的变体:密集连接的多层感知器 (MLP)。
密集编码器用于将输入上已经很紧凑的一组数字映射到预测:分类 (离散) 或回归 (连续)。
TensorFlow 教程:请参阅我们的深度学习基础教程的第 1 部分,其中有一个用于波士顿房价预测的 FFNNs 示例,它是一个回归问题:
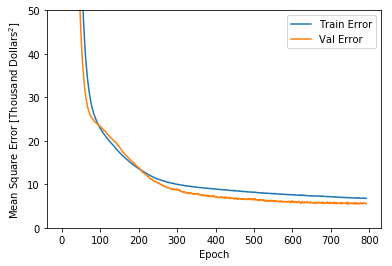
网络学习时在训练集和验证集上的误差

CNN(又名 ConvNets) 是一种前馈神经网络,它使用一种空间不变性技巧来有效地学习图像中的局部模式,这种方法在图像中最为常见。空间不变性 (Spatial-invariance ) 是指,比如说,一张猫脸的图像上,左上角的猫耳与图像右下角的猫耳具有相同的特征。CNN 跨空间共享权重,使猫耳以及其他模式的检测更加高效。
CNN 不是只使用密集连接的层,而是使用卷积层 (卷积编码器)。这些网络用于图像分类、目标检测、视频动作识别以及任何在结构上具有一定空间不变性的数据 (如语音音频)。
TensorFlow 教程:请参阅我们的深度学习基础教程的第 2 部分,了解用于对 MNIST 数据集中的手写数字进行分类的一个 CNN 示例。
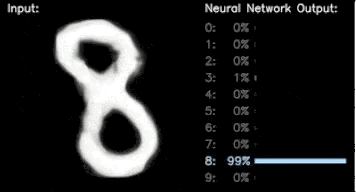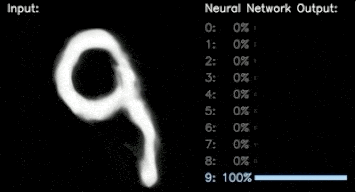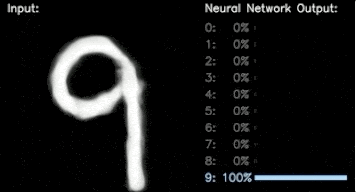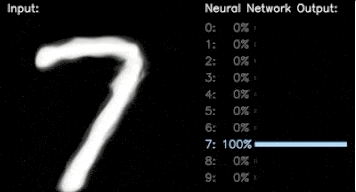
分类预测 (右),生成的手写数字 (左)。

RNN 是具有循环的网络,因此具有 “状态记忆”。它们可以及时展开,成为权重共享的前馈网络。正如 CNN 在 “空间” 上共享权重一样,RNN 在 “时间” 上共享权重。这使得它们能够处理并有效地表示序列数据中的模式。
RNN 模块有许多变体,包括 LSTM 和 GRU,以帮助学习更长的序列中的模式。它的应用包括自然语言建模、语音识别、语音生成等。
TensorFlow 教程:训练循环神经网络是很有挑战性的,但同时也允许我们对序列数据进行一些有趣而强大的建模。使用 TensorFlow 生成文本的教程是我最喜欢的教程之一,因为它用很少的几行代码就完成了一些了不起的事情:在字符基础上生成合理的文本:
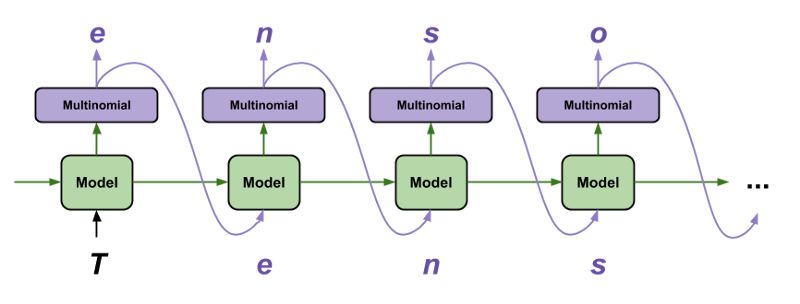
使用 TensorFlow 生产文本
使用 TensorFlow 生产文本教程:
https://www.tensorflow.org/tutorials/sequences/text_generation

前 3 节中介绍的 FFNN、CNN 和 RNN 都只是分别使用密集编码器、卷积编码器或循环编码器进行预测的网络。这些编码器可以组合或切换,取决于我们试图形成有用表示的原始数据类型。“Encoder-Decoder” 架构是一种更高级的概念,通过对压缩表示进行上采样的解码步骤来生成高维输出,而不是进行预测。
请注意,编码器和解码器可以彼此非常不同。例如, image captioning 网络可能有卷积编码器 (用于图像输入) 和循环解码器 (用于自然语言输出)。Encoder-Decoder 架构的应用包括语义分割、机器翻译等。
TensorFlow 教程:请参阅驾驶场景分割的教程,该教程演示了针对自主车辆感知问题的最先进的分割网络:

使用 TensorFlow 的驾驶场景分割
地址:
https://github.com/lexfridman/mit-deep-learning/blob/master/tutorial_driving_scene_segmentation/tutorial_driving_scene_segmentation.ipynb
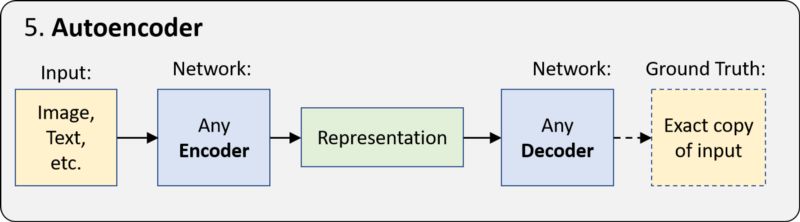
自动编码器 (Autoencoder) 是一种采用 encoder-decoder 架构的更简单的 “无监督学习” 形式,并学习生成输入数据的精确副本。由于编码的表示比输入数据小得多,网络被迫学习如何形成最有意义的表示。
由于 ground truth 数据来自输入数据,所以不需要人工操作。换句话说,它是自我监督的。自动编码器的应用包括无监督嵌入、图像去噪等。最重要的是,它的 “表示学习” 的基本思想是下一节的生成模型和所有深度学习的核心。
TensorFlow 教程:在这个 TensorFlow Keras 教程中,你可以探索自动编码器对 (1) 输入数据去噪和 (2) 在 MNIST 数据集进行嵌入的能力。
地址:
https://www.kaggle.com/vikramtiwari/autoencoders-using-tf-keras-mnist
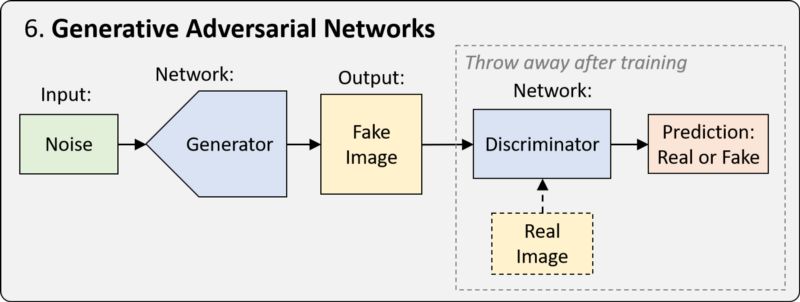
GAN 是一种用于训练网络的框架,GAN 网络经过优化,可以从特定的表示中生成新的逼真样本。最简单的形式是,训练过程涉及两个网络。其中一个网络称为生成器(generator),它生成新的数据实例,试图欺骗另一个网络,即鉴别器 (discriminator),后者将图像分类为真实图像和假图像。
在过去的几年里,GAN 出现了许多变体和改进,包括从特定类别生成图像的能力、从一个域映射到另一个域的能力,以及生成图像的真实性的惊人提高。例如,BigGAN (https://arxiv.org/abs/1809.11096) 从单一类别 (毒蝇伞) 中生成的三个样本:

BigGAN 生成的图像
TensorFlow 教程:有关 GAN 变体的示例,请参阅关于 conditional GAN 和 DCGAN 的教程。随着课程的进展,我们将在 GitHub 上发布一个关于 GAN 的最新教程。
conditional GAN:
https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb
DCGAN:
https://github.com/tensorflow/tensorflow/blob/r1.11/tensorflow/contrib/eager/python/examples/generative_examples/dcgan.ipynb
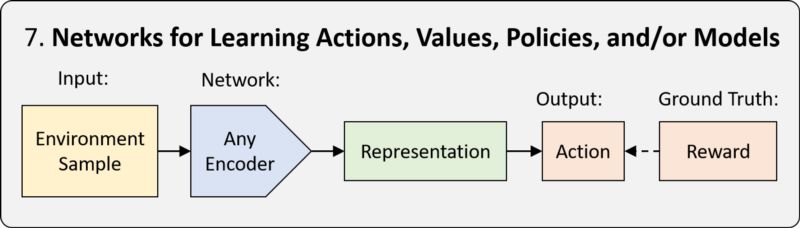
强化学习 (RL) 是一个框架,用于教一个 agent 如何以一种最大化回报的方式行动。当学习由神经网络完成时,我们称之为深度强化学习 (Deep Reinforcement learning, Deep RL)。
RL 框架有三种类型:基于策略的 (policy-based)、基于价值 (value-based) 的和基于模型的 (model-based)。区别在于神经网络的任务是学习。详细解读请参见本系列课程的第 6 讲。
Deep RL 允许我们在需要做出一系列决策时,在模拟或现实环境中应用神经网络。包括游戏、机器人、神经架构搜索等等。
教程:我们的 DeepTraffic 环境提供了一个教程和代码示例,可以快速地在浏览器中探索、训练和评估深度 RL 智能体,我们将很快在 GitHub 上发布一个支持 GPU 训练的TensorFlow 教程。

MIT DeepTraffic: Deep Reinforcement Learning Competition
MIT DeepTraffic:
https://selfdrivingcars.mit.edu/deeptraffic-documentation/
https://github.com/lexfridman/deeptraffic
在深度学习中有几个重要的概念并不是由上述架构直接表示的,包括变分自编码器(VAE)、LSTM/GRU 或神经图灵机中的 “记忆” 概念、胶囊网络,以及注意力机制、迁移学习、元学习概念,以及 RL 中基于模型、基于价值、基于策略的方法和 actor-critic 方法的区别。
最后,许多深度学习系统将这些结构以复杂的方式组合起来,共同从多模态数据中学习,或者共同学习解决多个任务。这些概念在本系列课程的其他课程中都有涉及,更多的概念将在接下来的课程中介绍:

加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信 aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后请修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)
加入新智元社群,成就AI新世界!




