ICLR 2020:从去噪自编码器到生成模型

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
在我看来,几大顶会之中,ICLR 的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020 的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是 Learning Generative Models using Denoising Density Estimators [1] 和 Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces [2]。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。
去噪自编码
两篇论文的根本出发点都是去噪自编码器,更准确地说,它利用了去噪自编码器的最优解。
基本结果:若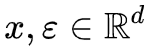
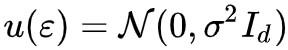
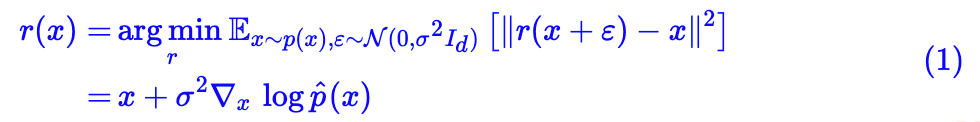
其中=[p∗u](x)=∫p(x−ε)u(ε)dε=∫p(ε)u(x−ε)dε 指的是分布 p(x) 和 u(ε) 的卷积运算,具体含义是 x+ε 的概率密度,换言之,如果 p(x) 代表真实图片的分布,那么如果我们能实现从
中采样,那么得到的是一批带有高斯噪声的真实图片。
结果 (1) 也就是说加性高斯噪声的最优去噪自编码器是能显式地计算出来,并且结果跟分布的梯度有关。这个结果非常有意思,也非常深刻,值得我们多加回味。比如,式 (1) 告诉我们 r(x)−x 实际上就是对(带噪声的)真实分布梯度的估计,而有了真实分布的梯度,其实可以做很多事情,尤其是生成模型相关的事情。
证明:其实 (1) 的证明并不困难,变分目标得到:
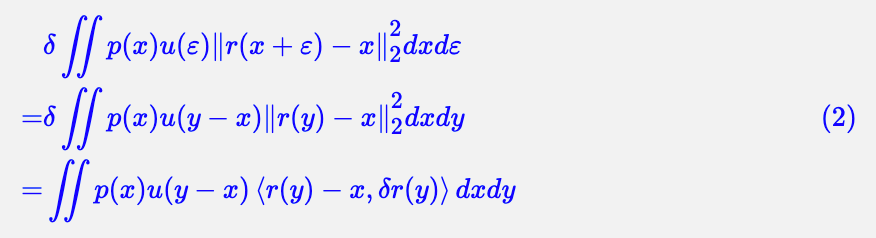
所以 ∫p(x)u(y−x)(r(y)−x)dx=0,即:

代入表达式:
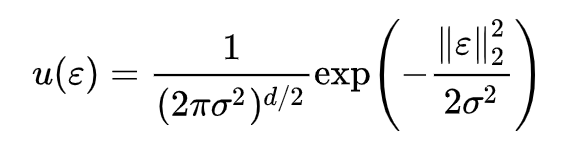
即得:

曲径通幽处
我们首先来介绍一下 Learning Generative Models using Denoising Density Estimators [1] 的思路。按照 GAN 和 VAE 的通常习惯,我们是希望训练一个映射 x=G(z),使得从先验分布 q(z) 中采样出来的 z 都能被映射为一个真实样本,用概率的话说,那就是希望拉近 p(x) 和下述的 q(x) 的距离:
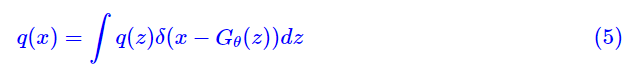
为此,GAN 常用的优化目标是最小化 KL(q(x)∥p(x)),这个观点可以参考《用变分推断统一理解生成模型和能量视角下的GAN模型(二):GAN=“分析”+“采样”。但是,由于前面估计的是的梯度,我们可以换个目标:最小化
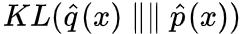
为了,我们可以进行演算:
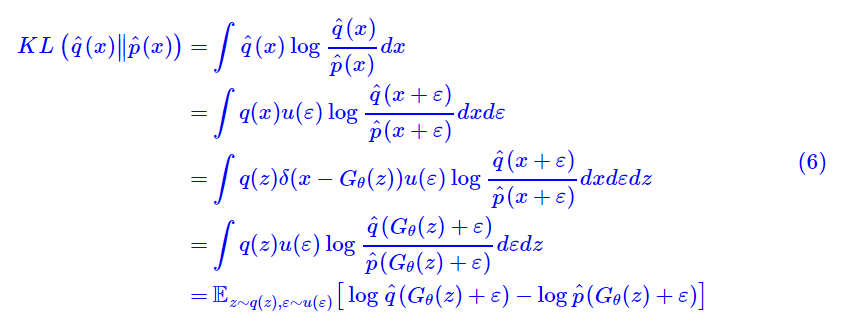
这个目标需要我们能得到和
的估计。我们可以用神经网络构建两个
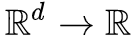
和
,然后分别去最小化:
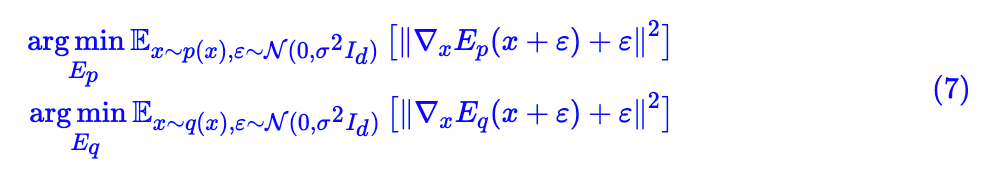
也就是用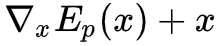
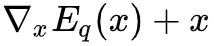

也就是说在相差一个常数的情况下,正比于
,
也正比于
,而常数不影响优化,所以我们可以将
和
替换到 (6) 里边去,得到:
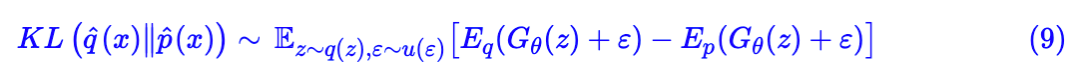
这就得到了一个生成模型的流程:
选定先验分布 q(z),初始化,事先求好
。循环执行下面的 3 步直到收敛:
1. 选一批z∼q(z),选一批噪声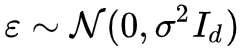
;
2. 利用这批带噪声的假样本训练;
3. 固定 Ep, Eq,用梯度下降根据 (9) 更新若干步。
这篇论文的实验比较简单,只做了 mnist 和 fashion mnist 的实验,证明了它的可行性:
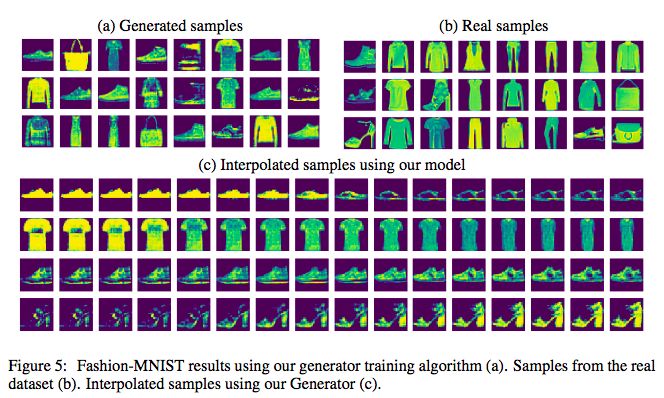
▲ fashion mnist的生成效果
峰回路转间
另外一篇论文 Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces [2] 就更粗暴直接了,它相当于去噪自编码器跟能量视角下的 GAN 模型(三):生成模型=能量模型 [3] 的结合。
因为 (1) 已经帮我们得到了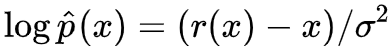
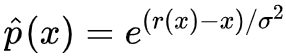
采样就完成任务了。当然采样出来的图片是有噪声的,我们还需要它采样出来的结果传入 r(x) 去噪一下,即:
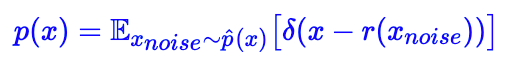
问题是怎么从采样呢?Langevin 方程!设
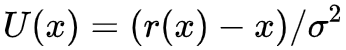
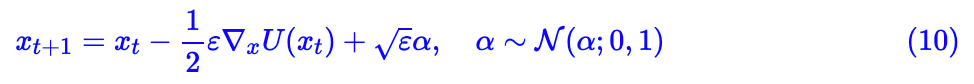
当 ε→0 且 t→∞ 时,序列所服从的分布就是从
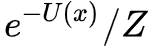
于是,从这个过程,就被 Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces 用这么一种粗暴直接(但我觉得不优雅)的方法解决了,所以训练完去噪自编码后,就自动地得到了一个生成模型了。
总的过程是:
1. 训练去噪自编码器 r(x),得到;
2. 用迭代过程 (10) 采样,采样结果是一批带噪声的真实样本;
3. 将第 2 步的采样结果传入 r(x) 去噪,得到无噪声的样本。
当然,论文还有很多细节,论文的核心技巧是用了退火技巧来稳定训练过程,提高生成质量,但笔者对这些并不是很感兴趣,因为我只是想学习一些新奇的生成模型思想,拓宽视野。不过不得不说,虽然做法有点粗暴,这篇论文的生成效果还是有一定的竞争力的,在 fashion mnist、CelebA、cifar10 都有相当不错的生成效果:

▲ fashion mnist、CelebA、cifar10上的生成效果
曲终人散时
本文介绍了投稿 ICLR 2020 的两篇类似的论文,都是利用去噪自编码器来做生成模型的,因为之前我没了解过相关思路,所以就饶有兴致对比阅读了一番。
且不说生成效果如何,我觉得它们都是颇具启发性的,能引起我的一些思考(不仅是 CV,还包括 NLP 方面的)。比如 Bert 的 MLM 预训练方式本质上也是一个去噪自编码器,那有没有类似 (1) 的结果?或者反过来,类似 (1) 的结果能不能启发我们构造一些新的预训练任务,又或者能不能借此说清楚 pretrain + finetune 这种流程的本质原理?
相关链接

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客




