【从头开始GAN】Goodfellow开山之作到DCGAN等变体
1Goodfellow开山之作到DCGAN等变体
Flood Sung 授权新智元转载
来源:知乎
【导读】 虽然目前GAN的酷炫应用还集中在图像生成上,但是GAN也已经拓展到NLP,Robot Learning上了。
前言
GAN的火爆想必大家都很清楚了,各种GAN像雨后春笋一样冒出来,大家也都可以名正言顺的说脏话了[微笑脸]。虽然目前GAN的酷炫应用还集中在图像生成上,但是GAN也已经拓展到NLP,Robot Learning上了。与此同时,在与NLP的结合过程中,我们很惊讶的发现,GAN和增强学习的Actor-Critic有曲艺同工之妙呀!Deepmind 的大神Oriol Vinyals也特地写了篇文章Connecting Generative Adversarial Networks and Actor-Critic Methods 来倡议大家研究一下两者的结合。这大大引起了我对GAN的兴趣,感觉条条大路通AI呀。GAN和RL有点像当年的量子力学和相对论,那么是不是会有一个GAN和RL的统一场论呢?这显然值得期待。
因此,好好从头分析一下GAN还是很有必要的。
既然是从头开始GAN,那么要说的第一篇文章必须是GAN的开篇,也就是2014年Ian Goodfellow的这篇开山之作。
在这篇paper,我们发现其实Ian Goodfellow仅用一段话就说完了GAN:

简单的说GAN就是以下三点:
(1)构建两个网络,一个G生成网络,一个D区分网络。两个网络的网络结构随意就好.
(2)训练方式。G网络的loss是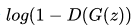
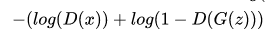
(3)数据输入。G网络的输入是noise。而D的输入则混合G的输出数据及样本数据。
那么我们来分析一下这样的训练会产生什么情况?G网络的训练是希望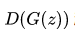
那么,这样相互对抗会产生怎样的效果呢?Ian Goodfellow用一个简单的图来描述:
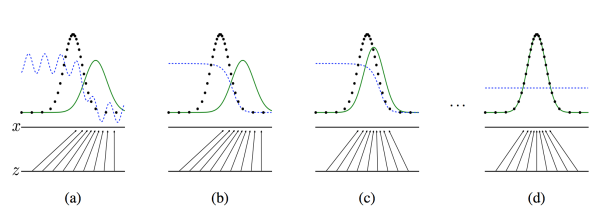
我们也好好说一下上面这几个图。第一个图是一开始的情况,黑色的线表示数据x的实际分布,绿色的线表示数据的生成分布,我们希望绿色的线能够趋近于黑色的线,也就是让生成的数据分布与实际分布相同。然后蓝色的线表示生成的数据x对应于D的分布。在a图中,D还刚开始训练,本身分类的能力还有限,因此有波动,但是初步区分实际数据和生成数据还是可以的。到b图,D训练得比较好了,可以很明显的区分出生成数据,大家可以看到,随着绿色的线与黑色的线的偏移,蓝色的线下降了,也就是生成数据的概率下降了。
那么,由于绿色的线的目标是提升概率,因此就会往蓝色线高的方向移动,也就是c图。那么随着训练的持续,由于G网络的提升,G也反过来影响D的分布。假设固定G网络不动,训练D,那么训练到最优,
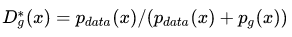
因此,随着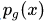
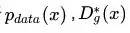
作者在文章中花了很大的篇幅证明整个网络的训练最终会收敛到
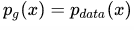
,我们这里就不探讨了,还是看看具体的算法及实现。

这里面包含了一些重要的trick及训练方法:
(1)G和D是同步训练的,但是两者的训练次数不一样,G训练一次,D训练k次。这主要还是因为初代的GAN训练不稳定。
(2)注意D的训练是同时输入生成的数据和样本数据计算loss,而不是cross entropy分开计算。实际上为什么GAN不用cross entropy是因为,使用cross entropy会使D(G(z))变为0,导致没有梯度,无法更新G,而GAN这里的做法D(G(z))最终是收敛到0.5。
(3)在实际训练中,文章中G网络使用了RELU和sigmoid,而D网络使用了Maxout和dropout。并且文章中作者实际使用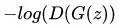
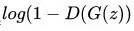
在这篇开山之作的最后,作者就分析了GAN的优缺点。GAN可以任意采样,可以使用任意的可微模型(也就是任意神经网络都可以)。GAN生成的图像更加sharp,也就是work更好,这个是最关键的,意味着它值得推广。当然了,作者也直接说了GAN不好训练这一bug。
在Future work中,作者也提到了使用GAN的各种可能性,包括conditional GAN,半监督学习等等。也许Ian Goodfellow在发表这篇文章的时候就已经意识到这将开创一个新的领域了。

GAN开始出名恐怕是因为DCGAN这篇文章。该文章做出了让人难以置信的效果如上图所示。这是GAN在图像生成上的第一次非常成功的应用,也从此开始,一大堆和图像生成相关的paper就出来了。
那么这篇paper对GAN做了什么改造呢?核心可以说就一点,就是使用卷积神经网络,并且实现有效训练:
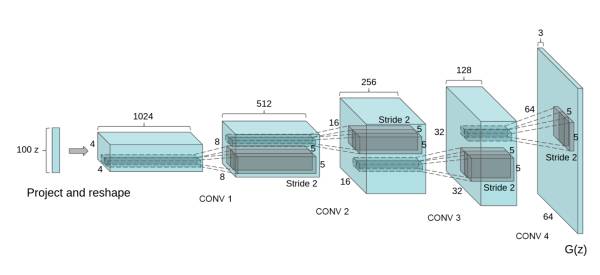
GAN在开山之作中就提出了,不好训练。那么DCGAN不但训练成功了,还拓展了维度,这就比较厉害了。DCGAN一共做了一下几点改造:
(1)去掉了G网络和D网络中的pooling layer。
(2)在G网络和D网络中都使用Batch Normalization
(3)去掉全连接的隐藏层
(4)在G网络中除最后一层使用RELU,最后一层使用Tanh
(5)在D网络中每一层使用LeakyRELU。
文章中作者也没有说为什么就这么做,只是因为看起来效果好。就是纯粹工程调出来了一个不错的效果。
那么具体说一下DCGAN的网络模型:
(1)G网络:100 z->fc layer->reshape ->deconv+batchNorm+RELU(4) ->tanh 64x64
(2)D网络(版本1):conv+batchNorm+leakyRELU (4) ->reshape -> fc layer 1-> sigmoid
D网络(版本2):conv+batchNorm+leakyRELU (4) ->reshape -> fc layer 2-> softmax
G网络使用4层反卷积,而D网络使用了4层卷积。基本上G网络和D网络的结构正好是反过来的。那么D网络最终的输出有两种做法,一种就是使用sigmoid输出一个0到1之间的单值作为概率,另一种则使用softmax输出两个值,一个是真的概率,一个是假的概率。两种方法本质上是一样的。
网上最出名的复现当属 carpedm20/DCGAN-tensorflow,而另一个极简版本是sugyan/tf-dcgan
下面我们来说说经过GAN训练后的网络学到了怎样的特征表达。
首先是用DCGAN+SVM做cifar-10的分类实验,从D网络的每一层卷积中通过4x4 grid的max pooling获取特征并连起来得到28672的向量然后SVM,效果比K-means好。然后将DCGAN用在SVHN门牌号识别中,同样取得不错的效果。这说明D网络确实无监督的学到了很多有效特征信息。
然后就是比较有意思的了,看G可以通过改变z向量,生成怎样不同的图片。不同的z向量可以生成不同的图像,那么,z向量可以线性加减,然后就可以输出新的图像,前面的图就是这种演示。非常神奇,说明z向量确实对应了一些特别的特征,比如眼镜,性别等等。这也说明了G网络通过无监督学习自动学到了很多特征表达。
总的来说,DCGAN开创了图像生成的先河,让大家看到了一条崭新的做深度学习的路子,如何更好的生成更逼真的图像成为大家争相研究的方向,而这一路到BEGAN,已经可以生成超级逼真的图像了,真是难以置信。
GAN中输入是随机的数据,没有太多意义,那么我们很自然的会想到能否用输入改成一个有意义的数据,最简单的就是数字字体生成,能否输入一个数字,然后输出对应的字体。这就是CGAN要做的事。
做法是非常的简单的:
就是在G网络的输入在z的基础上连接一个输入y,然后在D网络的输入在x的基础上也连接一个y:
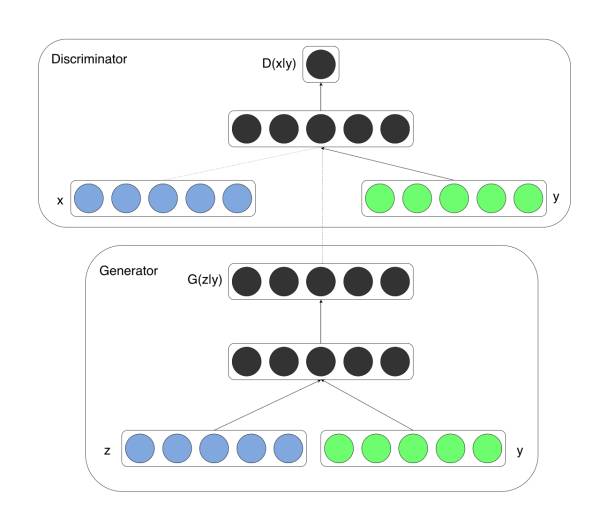
改变之后,整个GAN的目标变成:
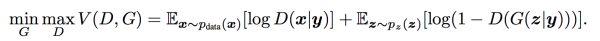
训练方式几乎就是不变的,但是从GAN的无监督变成了有监督。只是大家可以看到,这里和传统的图像分类这样的任务正好反过来了,图像分类是输入图片,然后对图像进行分类,而这里是输入分类,要反过来输出图像。显然后者要比前者难。
基于这样的算法,作者做了两个任务:一个是MNIST的字体生成任务,另一个是图像多标签任务。这里就谈MNIST字体生成任务,要求输入数字,输入对应字体。那么这里的数字是处理成one hot的形式,也就是如果是5,那么对应one hot就是[0,0,0,0,0,1,0,0,0,0]。然后和100维的z向量串联输入。
然后大家可以发现,这样的训练通过调整z向量,可以改变输出。这样就解决了多种输出问题:

可以看到可以生成不同形状的字体,只是生成质量还是有待改进,但是这已经足够验证CGAN的有效性了。
有了CGAN,我们可以有一个单一输入y,然后通过调整z输出不同的图像。但是CGAN是有监督的,我们需要指定y。那么有没有可能实现无监督的CGAN?这个想法本身就比较疯狂,要实现无监督的CGAN,意味着需要让神经网络不但通过学习提取了特征,还需要把特征表达出来。对于MNIST,如何通过无监督学习让神经网络知道你输入y=2时就输出2的字体?或者用一个连续的值来调整字的粗细,方向?感觉确实是一个非常困难的问题,但是InfoGAN就这么神奇的做到了。
怎么做呢?作者引入了信息论的知识,也就是mutual information互信息。作者的思路就是G网络的输入除了z之外同样类似CGAN输入一个c变量,这个变量一开始神经网络并不知道是什么含义,但是没关系,我们希望c与G网络输出的x之间的互信息最大化,也就是让神经网络自己去训练c与输出之间的关系。mutual information在文章中定义如下:
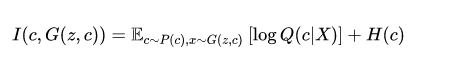
其中的H为c的entropy熵,也就是log(c)*c,Q网络则是反过来基于X输出c。基于I,整个GAN的训练目标变成:
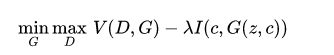
有了这样的理论之后,就具体如何训练的问题了。
相比CGAN,InfoGAN在网络上做了一定改变:
(1)D网络的输入只有x,不加c。
(2)Q网络和D网络共享同一个网络,只是到最后一层独立输出。
这是很早之前写的,因为觉得写的1w字貌似也还有点用,还是发出来吧。由于时间有限加上知乎上也已经有大量GAN的分析解读,本来打算把GAN最新的文章也拿来分析分析,决定还是算了,望见谅。
本文来自知乎用户Flood Sung。
☞ 【智能自动化学科前沿讲习班第1期】上海交大倪冰冰副教授:面向图像序列的生成技术及应用初探
☞ 【智能自动化学科前沿讲习班第1期】University of Central Florida 的Guojun Qi:LS-GAN
☞ 【智能自动化学科前沿讲习班第1期】微软秦涛主管研究员:从单智能体学习到多智能体学习
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【原理】十个生成模型(GANs)的最佳案例和原理 | 代码+论文
☞ 【教程】经得住考验的「假图片」:用TensorFlow为神经网络生成对抗样本
☞ 【模型】基于深度学习的三大生成模型:VAE、GAN、GAN的变种模型
☞ 【大会】还记得Wasserstein GAN吗?不仅有Facebook参与,也果然被 ICML 接收
☞ 【学界】邢波团队提出contrast-GAN:实现生成式语义处理
☞ 【专栏】阿里SIGIR 2017论文:GAN在信息检索领域的应用
☞ 【学界】康奈尔大学说对抗样本出门会失效,被OpenAI怼回来了!
☞ 警惕人工智能系统中的木马、病毒 ——深度学习对抗样本简介
☞ 【生成图像】Facebook发布的LR-GAN如何生成图像?这里有一篇Pytorch教程
☞ 【智能自动化学科前沿讲习班第1期】国立台湾大学(位于中国台北)李宏毅教授:Anime Face Generation
☞ 【变狗为猫】伯克利图像迁移cycleGAN,猫狗互换效果感人
☞ 【论文】对抗样本到底会不会对无人驾驶目标检测产生干扰?又有人发文质疑了
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【专栏】基于对抗学习的生成式对话模型的坚实第一步 :始于直观思维的曲折探索
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【最新】OpenAI:3段视频演示无人驾驶目标检测强大的对抗性样本!
☞ 【论文】CVPR 2017最佳论文出炉,DenseNet和苹果首篇论文获奖
☞ 【深度学习】解析深度学习的局限性与未来,谷歌Keras之父「连发两文」发人深省
☞ 苹果重磅推出AI技术博客,CVPR合成逼真照片论文打响第一枪
☞ 【Ian Goodfellow 五问】GAN、深度学习,如何与谷歌竞争
☞ 【巨头升级寡头】AI产业数据称王,GAN和迁移学习能否突围BAT垄断?
☞ 【高大上的DL】BEGAN: Boundary Equilibrium GAN
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【最全GAN变体列表】Ian Goodfellow推荐:GAN动物园
☞ 【DCGAN】深度卷积生成对抗网络的无监督学习,补全人脸合成图像匹敌真实照片
☞ 【开源】收敛速度更快更稳定的Wasserstein GAN(WGAN)
☞ 【Valse 2017】生成对抗网络(GAN)研究年度进展评述
☞ 【开源】谷歌新推BEGAN模型用于人脸数据集:效果惊人!
☞ 【深度】Ian Goodfellow AIWTB开发者大会演讲:对抗样本与差分隐私
☞ 论文引介 | StackGAN: Stacked Generative Adversarial Networks
☞ 【纵览】从自编码器到生成对抗网络:一文纵览无监督学习研究现状
☞ 【论文解析】Ian Goodfellow 生成对抗网络GAN论文解析
☞ 【推荐】条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上
☞【Geometric GAN】引入线性分类器SVM的Geometric GAN
☞ 【GAN for NLP】PaperWeekly 第二十四期 --- GAN for NLP
☞ 【Demo】GAN学习指南:从原理入门到制作生成Demo
☞ 【学界】伯克利与OpenAI整合强化学习与GAN:让智能体学习自动发现目标
☞ 【人物 】Ian Goodfellow亲述GAN简史:人工智能不能理解它无法创造的东西
☞ 【DCGAN】DCGAN:深度卷积生成对抗网络的无监督学习,补全人脸合成图像匹敌真实照片
☞ 带你理解CycleGAN,并用TensorFlow轻松实现
☞ PaperWeekly 第39期 | 从PM到GAN - LSTM之父Schmidhuber横跨22年的怨念
☞ 【CycleGAN】加州大学开源图像处理工具CycleGAN
☞ 【SIGIR2017满分论文】IRGAN:大一统信息检索模型的博弈竞争
☞ 【贝叶斯GAN】贝叶斯生成对抗网络(GAN):当下性能最好的端到端半监督/无监督学习
☞ 【贝叶斯GAN】贝叶斯生成对抗网络(GAN):当下性能最好的端到端半监督/无监督学习
☞ 【GAN X NLP】自然语言对抗生成:加拿大研究员使用GAN生成中国古诗词
☞ ICLR 2017 | GAN Missing Modes 和 GAN
☞ 【学界】CMU新研究试图统一深度生成模型:搭建GAN和VAE之间的桥梁
☞ 【专栏】大漠孤烟,长河落日:面向景深结构的风景照生成技术
☞ 【开发】最简单易懂的 GAN 教程:从理论到实践(附代码)
☞ 【论文访谈】求同存异,共创双赢 - 基于对抗网络的利用不同分词标准语料的中文分词方法
☞ 【LeCun论战Yoav】自然语言GAN惹争议:深度学习远离NLP?
☞ 【争论】从Yoav Goldberg与Yann LeCun争论,看当今的深度学习、NLP与arXiv风气
☞ 【观点】Yoav Goldberg撰文再回应Yann LeCun:「深度学习这群人」不了解NLP(附各方评论)
☞ PaperWeekly 第41期 | 互怼的艺术:从零直达 WGAN-GP
☞ 【谷歌 GAN 生成人脸】对抗创造新艺术风格,128 像素扩展到 4000
☞ 【原理】只知道GAN你就OUT了——VAE背后的哲学思想及数学原理



