【泡泡图灵智库】用于单视图三维补全和重建的形状先验信息学习(ECCV)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Learning Shape Priors for Single-View 3D Completion and Reconstruction
作者:Jiajun Wu, Chengkai Zhang, Xiuming Zhang, Zhoutong Zhang, William T. Freeman, and Joshua B. Tenenbaum
来源:ECCV2018
编译:李永飞
审核:杨小育
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——用于单视图三维补全和重建的形状先验信息学习,该文章发表于ECCV2018。
基于单视图的三维形状补全或重构是一个很有挑战性的任务,因为对于某一观测数据,往往存在很多种可能对应的形状,而其中大部分是在真实世界中不大可能存在的。该领域最近的研究试图通过深度卷积神经网络来解决这一问题。事实上,该问题还存在另一往往被忽略的多义性:在所有可能的合理形状中,仍然有多种可以很好匹配观测图像的形状,也就是说单视图无法确定唯一的真实形状。已有的全监督学习算法2未考虑这一特性,因而经常输出多种可能的形状的平均,从而导致细节的丢失。本文提出了ShapeHD,通过整合深度合成模型和对抗学习的形状先验信息,解决了这一问题。学习到的先验信息作为一个正则项,只有在模型输出不自然(ps:自然界中不大可能存在的)的形状时加以惩罚。本文这一设计能够同时克服上述两种多义性。基于多个真实数据集的实验表明,本文的ShapeHD比当前最优的算法性能提高了很多。
PS:“三维形状补全”是指从深度图中恢复三维物体形状;“三维重构”是指从RGB图中恢复出三维物体形状。
主要贡献
本文主要贡献为:
1、 分析了单视图三维重构和补全上,结果存在的两种多义性;
2、 通过设计自然度评估,解决了网络同一视图对应多个可能形状的多义性问题。
算法流程
本文的主要工作是基于单视图的三维补全和三维重构,重点要解决的问题是:对于单视图观测数据,可能存在多种适合该观测数据,且在现实中可能存在的三维形状,传统的形状回归网络,由于只将生成的形状与真实形状之差作为损失函数,因此本质上是一个形状复现器,当某种观测对应多种可能的合理结果时,会导致网络输出的是多种可能合理结果的平均值,进而导致输出三维形状模型的细节的丢失。为解决这一问题,本文的思路是:生成的三维形状模型不仅要符合数据,还要符合我们的一些先验知识,这样就能避免由于平均而导致的形状的失真;“符合先验知识”的具体实现方法,就是通过生成对抗网络训练出一个自然度辨别器。下面对算法的具体实现细节进行简要的介绍:
1、 网络架构
本文的网络架构如图1所示。
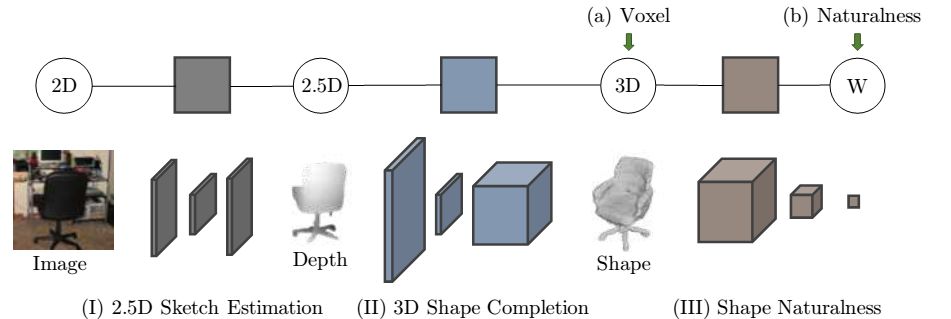
图1. 对于单视图形状重构任务,ShapeHD包含三部分:(I)一个深度估计器,用于从单视图中估计深度、表面法向量和轮廓图;(II)一个三维形状补全模块,用于从轮廓区域的深度图和表面法向量图中回归出三维形状;(III)一个预训练的对抗生成网络,用于自然度的估计。在三维形状补全网络的微调阶段,本文采用了两个损失函数:一是对输出形状的监督损失函数,另一个是由预训练的鉴别网络得到的自然度损失函数。
其中自然度鉴别网络,来源于对抗生成网络的鉴别器。为了解决生成对抗网络训练阶段的不稳定性问题,本文采用如下的损失函数:
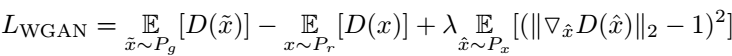
其中D为鉴别器,Pg和Pr 分别是合成形状的分布、真实形状的分布。最后一项为梯度惩罚项。
由此,本文的自然度损失函数可表达为:
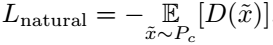
2、网络的训练
整个网络的训练分为两个阶段:第一阶段,上述三个网络分别进行预训练;第二阶段,将第一阶段训练得到的自然度辨别器的参数固化,其输出作为损失函数一部分,在新的损失函数
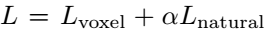
对前两个网络进行参数的微调训练。
主要结果
本文从三维形状补全和三维重构两个方面对算法性能进行了验证,主要的实验结果如下:

图2. 基于单视图深度图的三维形状补全结果。由左到右依次是:输入的深度图、标准视角下的形状重构效果图、其他视角下的形状重构效果图以及标准视角下的真值。得益于由对抗学习得到的自然度损失函数,ShapeHD能够恢复出具有细节的高精度形状。有时重构的形状虽然与真值有一定的差别,但是却可以看做输入的另一种可能的解释(比如,左边第三行的飞机)。
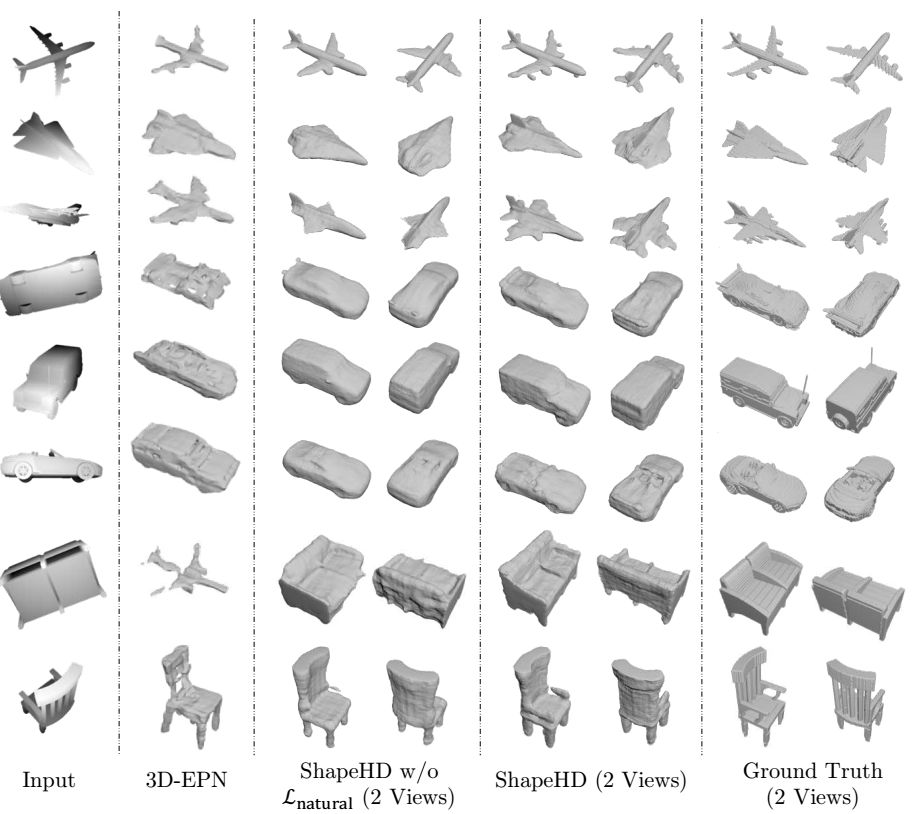
图3. 本文的结果、3DEPN的结果、本文方法剔除自然度损失函数的结果间的比较。比起3DEPN,本文得到的结果包含更多的细节。可以发现:对抗训练得到的自然度损失函数能够消除错误,增加细节(比如第三行飞机的机翼、第六行中车座椅以及第八行中椅子的扶手),平滑表面(比如第七行中沙发的背面)。

图4. 在真实扫描数据上的三维形状补全结果。本文的方法能够很好地从单视图中重构出三维形状。从左到右依次为:输入的深度图、本文结构的两个视角图以及物体的彩色图。
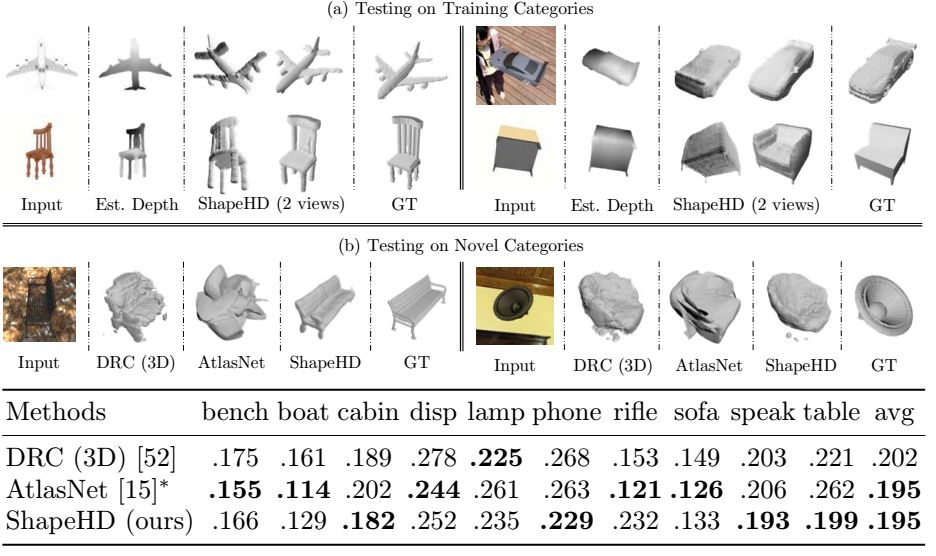
图5. ShapeNet中训练中未出现物体的重构结果。所有的算法训练都是使用ShapeNet中车、椅子和飞机的合成数据,测试时使用其他物体。DRC和本文的ShapeHD只需单幅图作为输入,AltasNet还需要物体的轮廓作为额外输入。
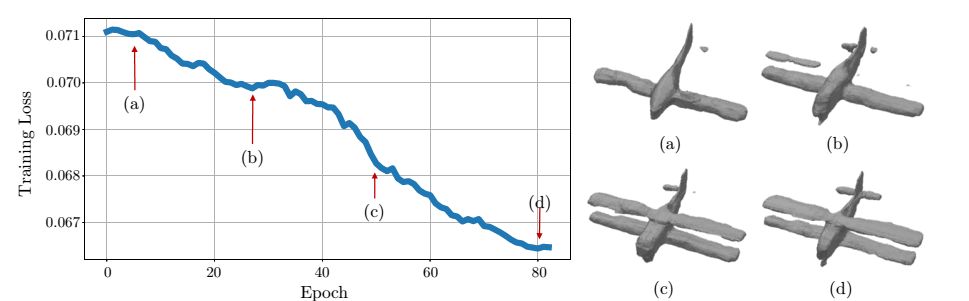
图6. ShapeHD训练过程的可视化。可以看出,随着细节的添加,预测形状的自然度损失函数降低。
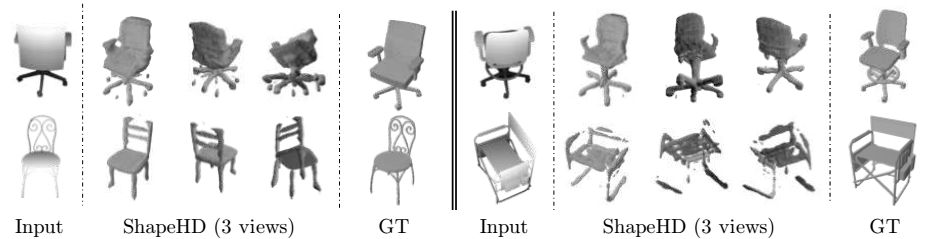
图7. 本文方法几种可能失败的情形。左上:物体可变形(比如,椅子的轮子相对于整体的位置发生变化)。右上:一些不常见的细节容易丢失(比如,轮子上方的环状物)。下方:一些比较细的结构容易被忽略并重构出其他错误的结构。

Abstract
The problem of single-view 3D shape completion or reconstruction is challenging, because among the many possible shapes that explain an observation, most are implausible and do not correspond to natural objects. Recent research in the field has tackled this problem by exploiting the expressiveness of deep convolutional networks. In fact, there is another level of ambiguity that is often overlooked: among plausible shapes, there are still multiple shapes that fit the 2D image equally well; i.e., the ground truth shape is non-deterministic given a single-view input. Existing fully supervised approaches fail to address this issue, and often produce blurry mean shapes with smooth surfaces but no fine details. In this paper, we propose ShapeHD, pushing the limit of single-view shape completion and reconstruction by integrating deep generative models with adversarially learned shape priors. The learned priors serve as a regularizer, penalizing the model only if its output is unrealistic, not if it deviates from the ground truth. Our design thus overcomes both levels of ambiguity aforementioned. Experiments demonstrate that ShapeHD outperforms state of the art by a large margin in both shape completion and shape reconstruction on multiple real datasets.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


