智能滚动:让转录后的文本编辑、共享和搜索更容易

文 / Itay Inbar,高级软件工程师,Google Research
我们去年发布的 Recorder 是一款利用设备端机器学习 (ML) 将录音转录为文本,可突出显示音频事件并为标题标签提供合理建议,让音频录制变得更加智能和实用的全新的录音应用。通过转录功能,它使编辑、共享和搜索变得更加容易。Recorder 支持转录长时间的录音(最高可达 18 个小时!),有时用户很难找到所需的某一特定部分,因此需要一种全新的解决方案来快速浏览这种长度的转录文本。
Recorder
https://ai.googleblog.com/2019/12/the-on-device-machine-learning-behind.html
为提高内容的导航性,我们引入了智能滚动功能,这是 Recorder 中一项基于 ML 的新功能,可自动标注转录文本中的重要部分,从每个部分中选取关键字(如章节标题),然后将这些关键字显示在垂直滚动条上。接下来,用户便可以滚动浏览关键字,或点击关键字,快速导航到感兴趣的部分。Recorder 使用了轻量级模型,无需上传转录文本便足以在设备端执行,有助于保护用户隐私。
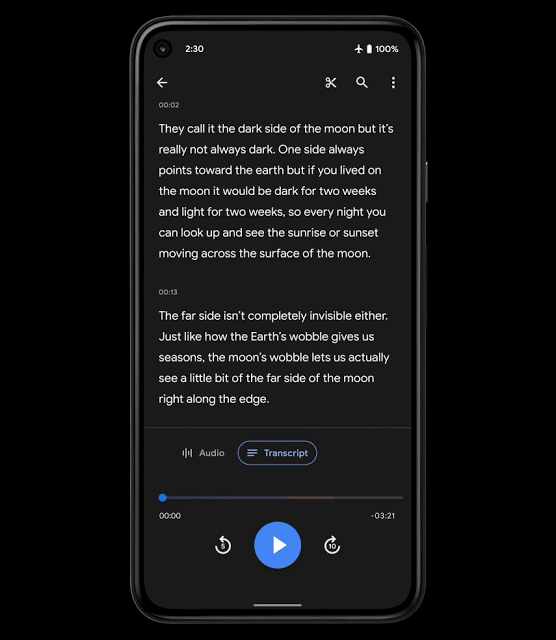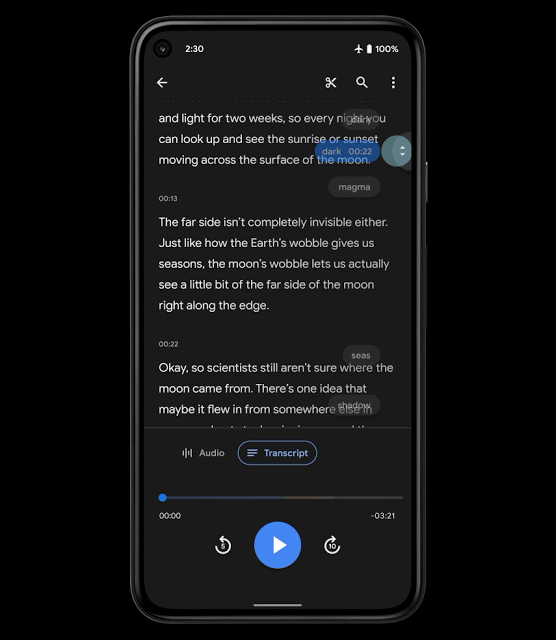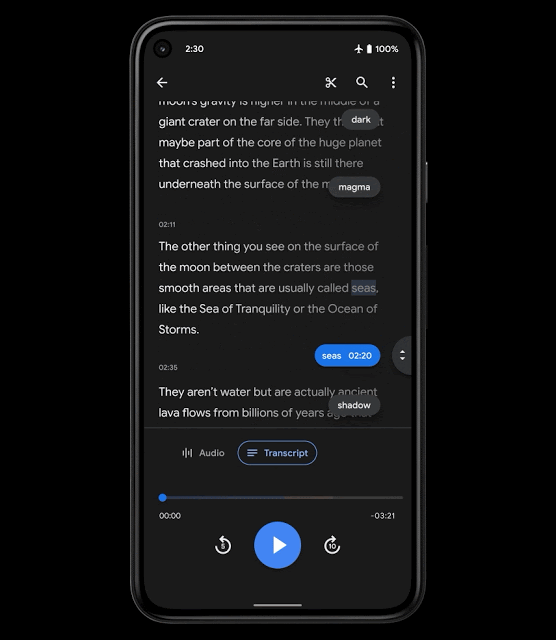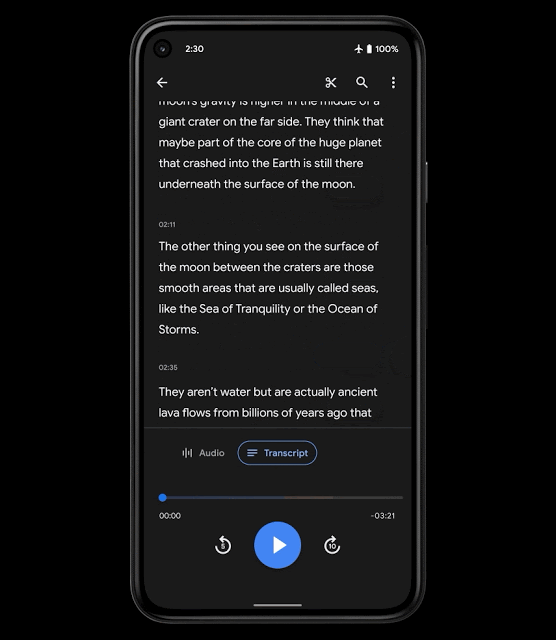
智能滚动功能用户体验
幕后信息
智能滚动 (Smart Scrolling) 功能由两项任务组成。第一项任务是从每个部分中提取关键字,第二项则是筛选出文本中信息最丰富的部分。
在每项任务中,我们都使用了两种不同的自然语言处理 (NLP) 方法:基于 Wikipedia 数据集中数据进行预训练的精简版双向 BERT 模型,以及经过精简的词频-逆文本频率 (TF-IDF) 模型。我们并行使用双向 Transformer 和基于 TF-IDF 的模型进行关键字提取和重要部分识别任务,同时使用聚类启发式算法,这样既能够利用每种方法的优势,又能避免它们各自的弊端(在下一节讨论)。
基于 Wikipedia 数据集
https://dumps.wikimedia.org/
双向 Transformer 是一种神经网络架构,采用自注意力机制以非连续方式实现对输入文本的上下文感知的处理。实现了对输入文本的进行并行处理,来识别转录文本中给定位置前后的上下文线索。
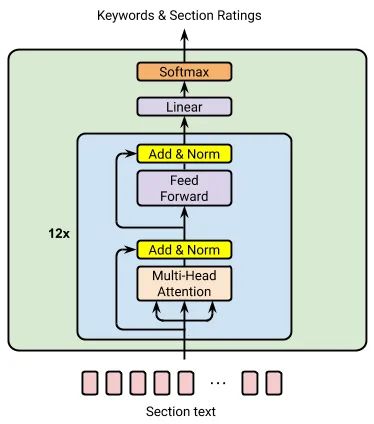
基于双向 Transformer 的模型架构
自注意力
https://arxiv.org/abs/1706.03762
TF-IDF 精简版通过比较术语在文本中的频率与其在训练数据集中的逆频率,对术语进行评分,从而在文本中找到独特的代表性术语。
两种模型均基于经过独立标注者标注和评估的公开可用会话数据集进行训练,会话数据集与预期产品用例属于相同领域,侧重于会议、讲座和访谈,可确保相同的词频分布(齐夫定律)。
提取代表性关键字
基于 TF-IDF 的模型通过为每个单词评分来检测信息关键字,分数即对应此单词在文本中的代表性。该模型的处理方式非常类似于标准 TF-IDF 模型,即通过比较给定单词在文本中的出现次数与在整个会话数据集中的出现次数,确定该单词在文本中的代表性。但该模型还考虑了术语的特异性,即术语的广泛性或具体性。此外,该模型随后会使用预训练的函数曲线将这些特征聚合为一个分数。同时,针对提取关键字任务,双向 Transformer 模型经过了微调,可对文本的深刻语义理解,从而提取精确的上下文感知关键字。
TF-IDF 方法相对保守,倾向于找到文本中不常见的关键字(高偏差),而双向 Transformer 模型的缺点则在于提取到的关键字方差较大。但是,如果同时使用,这两个模型就可以互补,形成偏差-方差的权衡。
从两个模型中检索到关键字分数后,我们就可以利用 NLP 启发式算法(例如加权平均值),删除各部分间的重复项,并消除停用词和动词,从而标准化并合并分数。该过程的输出即为每部分中建议关键字的有序列表。
评估各部分的重要性
下一个任务是确定哪些部分信息丰富且具有独特性,并将其突出显示。为了完成此任务,我们再次结合使用上述两个模型,评估每个部分的重要性,并生成对应的分数。我们通过获取该部分中所有关键字的 TF-IDF 得分,并根据其在该部分中的出现次数加权,然后计算这些单个关键字得分的总和,计算出第一个分数。我们通过双向 Transformer 模型运行各部分文本,并以此计算第二个分数,该模型也接受了各部分评分任务的训练。标准化并合并两个模型生成的分数,得出各部分的分数。
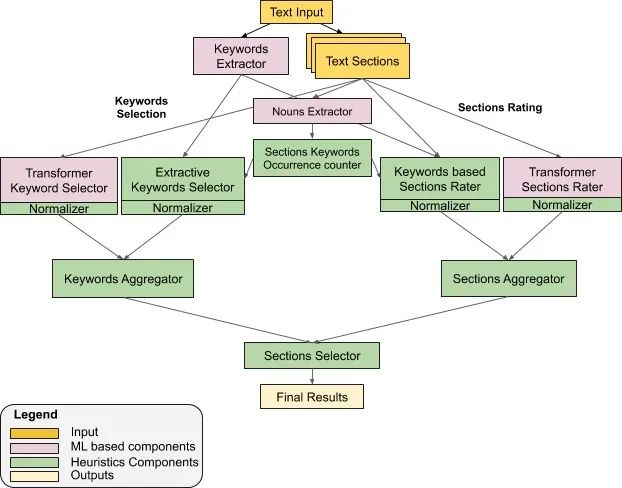
智能滚动流水线架构
一些挑战
智能滚动功能开发过程中的一个重大挑战是确定某个部分或关键字重要与否,换句话说,有些关键字或者部分对某个人可能非常重要,但对另一个人可能就不是很重要。关键是仅在可以从某些部分中提取有用的关键字时,才突出显示这些部分。
为此,我们配置了解决方案,用以选择得分最高的部分,这些部分也具有高评分关键字,并且突出显示的部分数量与录音的长度成正比。在智能滚动功能的环境中,如果某个关键字能够更好地代表相应部分的独特信息,则其评分会更高。
为了训练模型了解此标准,我们需要准备一个针对此任务定制的有标签训练数据集。我们与经验丰富的标注者团队合作,将这一标注目标应用于一小批示例中,建立初始数据集,以便评估标签的质量,并在与预期目标有偏差的情况下指导标注者。标注过程完成后,我们将手动检查标注的数据,并根据需要对标签进行更正,使其与我们对重要性的定义保持一致。
我们使用这个有限的有标签数据集进行了自动模型评估,建立模型质量的初始指标,这些指标精度较低,用于评估模型质量。这样我们就能够快速评估模型性能,并对架构和启发式算法进行更改。解决方案指标达到标准后,我们将采用更为准确的人工评估过程,对精心挑选的一组封闭示例进行评估,这些示例可代表预期 Recorder 用例。使用这些示例,我们通过可靠的模型质量评估调整模型启发式算法参数,以达到所需的性能水平。
运行时改进
Recorder 初始版本发布后,我们进行了一系列用户研究,了解如何提高智能滚动功能的易用性和性能。我们发现许多用户希望能够在录制完成后,立即获得导航性关键字和突出显示的部分。上述计算流水线在计算用时较长的录音时,可能需要花费大量时间,为此我们设计了一种部分处理解决方案,可将此类计算分摊到整个录制过程中。在录制过程中,应用会在每一部分捕获后对其进行处理,然后将中间结果存储在内存中。录制完成后,Recorder 会汇总中间结果。
在 Pixel 5 上运行时,此方法将长度为一小时的录音(约 9000 字)的平均处理时间从 1 分 40 秒缩短到仅 9 秒,而输出结果不会受到影响。
总结
Recorder 的目标是提高用户访问和浏览其录制内容的能力。我们已在这一方向上取得了实质性进展,现有 ML 功能可自动建议录音的标题词,并使用户能够搜索录音中的声音和文本。智能滚动还提供了其他文本导航功能,将进一步提高 Recorder 的实用性,即使录音较长,用户也能通过这些功能快速定位感兴趣的部分。
致谢
Bin Zhang、Sherry Lin、Isaac Blankensmith、Henry Liu、Vincent Peng、Guilherme Santos、Tiago Camolesi、Yitong Lin、James Lemieux、Thomas Hall、Kelly Tsai、Benny Schlesinger、Dror Ayalon、Amit Pitaru、Kelsie Van Deman、Console Chen、Allen Su、Cecile Basnage、Chorong Johnston、Shenaz Zack、Mike Tsao、Brian Chen、Abhinav Rastogi、Tracy Wu、Yvonne Yang。
更多 AI 相关阅读:





