在机器学习等领域,是否被顶会接收被认为是一种论文质量评价标准,但并不是唯一的标准。随着深度学习的广泛发展,机器学习顶会的投稿数量呈爆炸式增长,在被拒稿的论文中也有很多颇具影响力的研究。
近日,Reddit 上就有一个帖子引起网友热议:哪些论文是被顶会拒稿,但却非常有影响力?令人惊讶的是网友列举出一些家喻户晓的研究,包括 YOLO、transformer XL,甚至还有 Google 搜索引擎的网页排名算法 PageRank。
![]()
发帖人表示机器学习顶会的审稿机制存在问题,让一些论文难以脱颖而出。这可能是出现这种现象的原因之一。
实际上,很多优秀的研究在一开始并不被看好。就像 2021 年诺贝尔物理学奖获得者 Parisi 博士在颁奖典礼上提到的,对于他获得诺贝尔奖的研究,最初论文审稿人给出的评价是:「这篇文章不值得浪费纸张打印出来」。然而,经过时间和实验的检验,一些论文中的观点被证明是正确的,甚至卓越的。机器学习领域也是如此。
我们来具体看一下在这次讨论中,网友列举出哪些优秀的研究。
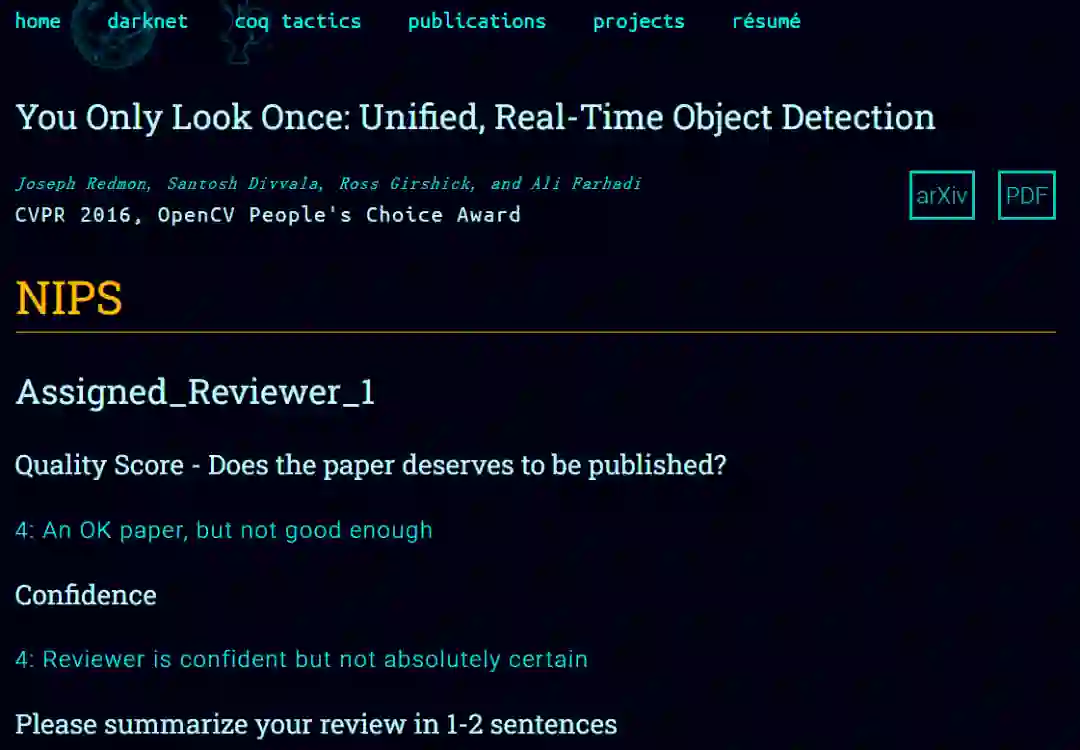
大名鼎鼎的 YOLO 算法,作为计算机视觉领域最知名的目标检测算法之一,在投稿 NIPS 时也不是一帆风顺。NIPS 给出的评价大体为:这是一篇不错的论文,但还不够好。之后 YOLO 这篇文章被 CVPR 2016 接收。有了这次教训,YOLO2 也是第一时间投稿 CVPR。
![]()
图源:https://pjreddie.com/publications/yolo/
![]()
论文地址:https://arxiv.org/pdf/1506.02640.pdf
Transformer-XL 为 Zihang Dai、Zhilin Yang 等人在 2019 年提出。这篇论文旨在进一步提升 Transformer 建模长期依赖的能力。核心算法包括:segment-level 递归机制、相对位置编码机制。Transformer-XL 可以捕获长期依赖,解决了上下文碎片问题,还提升了模型的预测速度和准确率。
然而Transformer-XL 在投稿 ICLR 2019 时被拒稿,之后作者基于 Transformer-XL 进行改进,提出了 XLNet,被 NeurIPS 2019 接收。而 Transformer-XL 则被 ACL 2019 接收。
![]()
论文地址 https://arxiv.org/abs/1901.02860
2012 年,Hinton 在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出 Dropout。当一个复杂的前馈神经网络用来训练小数据集时,会造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
这篇论文在 2012 年被 NIPS 拒绝,现在 arXiv 上作为预印本发布。
![]()
论文地址:https://arxiv.org/pdf/1207.0580.pdf
PageRank 是谷歌两大创始人谢尔盖布林(Sergey Brin)和拉里佩奇(Lawrence Page)在 1998 年联合撰写的论文《The anatomy of a large-scale hypertextual Web search engine》中提出的。PageRank 是 Google 搜索引擎中使用的网页排名算法,它的成功早已经过全球谷歌用户的考验。然而,或许是因为提出的想法太超前,这篇论文在 1998 年被 SIGIR 拒稿,后被 WWW 接收。
![]()
论文地址:https://snap.stanford.edu/class/cs224w-readings/Brin98Anatomy.pdf
SVM 算法分几个阶段提出。首先,它建立在早期工作的基础上,包括 1960 年代和 70 年代 Vladimir Vapnik 和 Alexey Chervonenkis 的研究之上。
1992 年,Bernhard E. Boser 、 Isabelle Guyon 以及 Vladimir Vapnik 合作写了一篇论文《A Training Algorithm for Optimal Margin Classifiers》,文中解释了如何获得这个函数以便它在干净的数据上工作。
这篇论文在一个相对面向应用、以神经网络为主导的机器学习会议 NIPS 上被拒绝,但在第二年一个更注重理论的会议 COLT 上被接收。
![]()
论文地址:https://dl.acm.org/doi/pdf/10.1145/130385.130401
知识蒸馏这一概念是 Hinton 等人在 2014 年提出,论文题目为《 Distilling the Knowledge in a Neural Network 》。知识蒸馏旨在把一个大模型或者多个模型组合学到的知识迁移到另一个轻量级单模型上,方便研究者部署。简单的说就是用新的小模型去学习大模型的预测结果。
![]()
论文地址:https://arxiv.org/pdf/1503.02531.pdf
计算机视觉当中的 SIFT 特征,在深度学习大火之前影响巨大,但是原作者 David Lowe 承认原稿被 CVPR 和 ICCV 拒了两次。
SIFT(Scale-Invariant Feature Transform)是一种用于检测和描述数字图像中的局部特征算法。它定位关键点并以量化信息呈现,可以用来做目标检测。此特征可以对抗不同变换而保持不变。
![]()
论文地址:https://www.cs.ubc.ca/~lowe/papers/iccv99.pdf
在今天看来,上述所列举的这些研究在AI领域地位举足轻重。但也逃不掉被顶会拒稿的命运。
也许,是机器学习顶会的审稿机制存在一些问题。去年,图灵奖得主 Yann LeCun 在论文被 NeurIPS 拒稿之后,在推特上发文称感到「proud」,表达了自己的不满。
类似的事情还发生在 2012 年,LeCun 曾给当时的 CVPR 大会主席、知名计算机视觉专家朱松纯写信,抱怨自己的论文报告了很好的实验结果,但是审稿的三个人都认为论文说不清楚到底为什么有这个结果,于是遭到了拒稿。LeCun 认为这说明 CVPR 等顶会的审稿机制令人失望。
值得一提的是,LeCun 和 Bengio 随后共同创办了 ICLR 会议,希望为「深度学习」提供一个专业化的交流平台。
在机器学习发展放缓的今天,领域内一些研究者提出了新的研究方向。尽管顶会不是评判研究价值的唯一标准,但审稿机制理应不断优化,避免卓越超前的研究思路遭到拒绝。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com