病毒影响了人们的身体,也在改变着人与人之间的关系。美国罗切斯特大学的计算机科学家正从推特舆情中分析新型冠状病毒大流行带来的社会影响,其结果令人深思。
自今年 1 月底以来,新冠肺炎(COVID-19)逐渐呈现全球范围流行趋势,成为国内外人们议论的中心。虽然早在 2 月世界卫生组织(WHO)就将该病毒命名为 2019 冠状病毒病(COVID-19),但在国外社交网络上仍有不少用户使用「武汉肺炎」、「中国病毒」这类完全错误的说法。
但使用这些词汇的人到底有多少?他们是什么样的人?使用这些词汇的心理动机是什么?近日,罗切斯特大学的研究人员对此进行了一系列研究。
![]()
根据 GDELT 数据,全球线上媒体报道范围内,提到「中国流感」一词的新闻报道量从 1 月 18 日开始上升,而世界卫生组织 WHO 的官方标准名词是 COVID-19。同时,与 COVID-19 有关的种族袭击事件的报道量也在增加。
随着新冠病毒的全球大流行,新冠病毒成为社交平台上用户讨论的热点。这些用户在提到 COVID-19 的时候,主要有两种提法,一种是使用「中国病毒」(Chinese Virus)或者「武汉病毒」(Wuhan Virus)这类词汇,另一种是使用「新冠病毒」(Coronavirus)这类词汇。
罗切斯特大学的研究团队使用 Tweepy API 抓取大量数据,并对选择这两种用词的人群从年龄、性别、政治倾向、地理位置以及更深层的心理层面进行了分析。
该研究团队于 4 月中旬发表了系列研究的第一篇论文《Sense and Sensibility: Characterizing Social Media Users Regarding the Use of Controversial Terms for COVID-19》,作者为罗切斯特大学 Goergen 数据科学中心 Hanjia Lyu、计算机科学系 Long Chen 和罗杰波,以及政治学系 Yu Wang。
论文链接:
https://arxiv.org/abs/2004.06307
![]()
该研究团队使用 Tweepy API 抓取了一千七百万条推特及其作者信息,试图研究选择这两种用词的人群在年龄、性别、用户层面特征(如粉丝数量、是否为大 V 用户)、政治倾向(在推特上粉了哪些重要的两党人物),以及地理位置上的区别。在研究中,团队还设计了分类器用于预测哪些推特用户更倾向于使用如「中国病毒」这类词汇。
根据对上百万条推特的分析,研究人员得出了很多值得关注的结论:
使用「中国病毒」这类表述的男性占比 61%;
使用新冠病毒这类表述的男性占比 56.2%;
使用新冠病毒这类表述的人里面,一半以上年龄在 35 岁以下;
来自乡村地区和城郊的推特用户更具有使用「中国病毒」这类表述的倾向;
在可确定政治倾向的人群中,唐纳德·特朗普的支持者最倾向于使用「中国病毒」这类表述,伊丽莎白·沃伦、皮特·布特吉(均为 2020 民主党前总统候选人)的支持者最倾向于使用中立词汇 ;
推特账户建立时间越长的用户越倾向于使用新冠病毒这类表述。
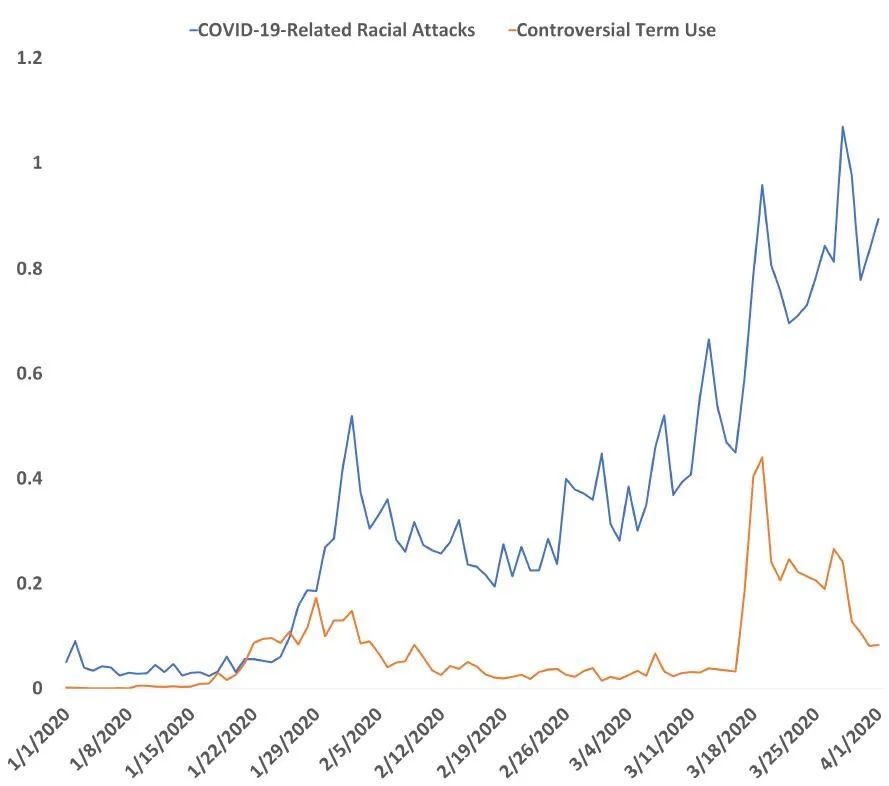
图 1 是全球有关「中国流感」以及 COVID-19 相关的种族袭击新闻报道的体量时间线。与 COVID-19 有关的种族袭击事件的新闻报道量仍在不断上升。已有研究发现部分媒体将 COVID-19 与「中国病毒」直接挂钩的报道对在全球范围内旅行的中国人精神健康造成了负面影响。除此之外,社交平台上「中国病毒」或「中国流感」的使用量也在增加。3 月 16 日,美国总统唐纳德·特朗普使用其推特账户明确将 COVID-19 称作「中国病毒」。尽管他在之后声称这种用法并没有种族含义,但针对在美亚裔的种族主义与歧视仍在美国社会蔓延。
![]()
图 1:「中国流感」与 COVID-19 相关种族袭击新闻报道的密度。
Matamoros-Fernandez 曾提出「平台种族主义」(platformed racism)的概念,如推特这样的社交平台其实是种族主义的放大器。使用有「中国病毒」这类表述指向 COVID-19 的时候可能是在发布仇恨言论,仇恨言论反映了存在于社会内的矛盾。在社交平台上,仇恨言论的传播极度迅速,甚至可以跨平台,并且留存较长的时间。即便事后被有意识删除,人们仍旧可以在互联网的其他地方甚至线下找到痕迹。
罗切斯特大学的研究聚焦于分析使用「中国病毒」词汇或「新冠病毒」词汇的人群在年龄、性别、用户层面特征(如粉丝数量、是否为大 V 用户)、政治倾向(在推特上粉了哪些重要的两党人物),以及地理位置上的区别。
为了找到这样的用户,该研究以「中国病毒」和「新冠病毒」为关键词,抓取使用了这两类词汇的推特及其发布者,将推特里有「中国病毒」的划分为CD组,将推特里有「新冠病毒」的划分为ND组。经过分析,该研究得到了以下发现。
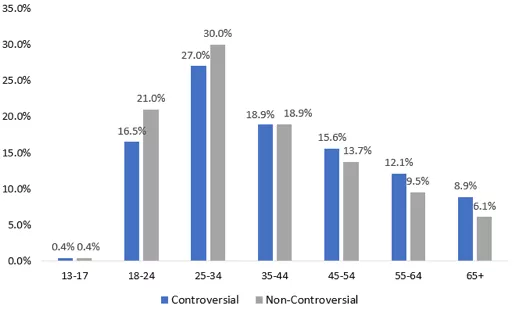
图 2 展示了两组人的年龄分布。在两组内,25-34 岁是用户数量最多的年龄段,这也与全体推特用户的年龄分布一致。然而两个组的各年龄段占比却显著不同(p<0.0001)。ND 组的用户普遍更年轻,21% 的用户集中在 18-24 岁,而 CD 组里这一年龄段的用户只占 16.5%。从中可以看出,45 岁以上的用户更可能使用「中国病毒」这类表述。
![]()
该研究进而发现,ND 组里女性用户占比比 CD 组里女性占比更高。而在比较了用户的粉丝数(#followers)、好友数(#friends)、状态数(#statuses)、点赞数(#favourites)、小组数(#listed_membership)这 5 个用户特征(推特上的「社会资本」)后可知,社会资本(social capital)更高的用户使用「中国病毒」这类词汇的比例更低。
对于这一点观察原因的推测是,这些用户有更多的观众,所以会在发布内容时更加谨慎。有发现表明,推特用户认为自己的状态(哪怕不是自己原创的)是自己的「财产」,所以在发布状态时会格外谨慎,在好友之间分享时也更加小心。
另一方面,研究发现 ND 组的用户账号成立时间中位数为 74 个月,而 CD 组里的账号成立时间中位数为 63 个月,差距几乎是一年。
此外,还有一些统计结果:倾向于共和党和支持唐纳德·特朗普的用户更加倾向于使用「中国病毒」这类词汇;居住在乡村的用户更加倾向于使用「中国病毒」这类表述。
喜欢说「中国病毒」的人通常关注共和党,进入社交网络时间较短比较莽撞?如果你觉得这些结论看起来比较浅显,该团队在第二篇论文的进一步研究中,给出了对推特用户更深层次的分析。
论文 2:《In the Eyes of the Beholder: Sentiment and Topic Analyses on Social Media Use of Neutral and Controversial Terms for COVID-19》
论文链接:
https://arxiv.org/abs/2004.10225
![]()
该团队这次获取了更多数据。通过 Tweepy API,研究人员共获取 2,607,753 条 CD 推特文本,69,627,062 条 ND 推特文本,从两个组中分别抽样两百万条作为最终的研究数据集。研究人员使用 Latent Dirichlet Allocation (LDA) 提取文本话题信息,最终在 CD 和 ND 组中分别提取出最重要的 5 个话题,每个话题包含 10 个单词。
下表展示了研究者根据 LDA 模型获得的 CD 与 ND 组的话题关键词。
![]()
为深入了解两组用户,该研究使用 Linguistic Inquiry and Word Count 2015 (LIWC2015) 提取文本所带的作者情绪以及心理层面信息,最终提取出 4 个总结性语言学变量,以及 12 个更详细的语言学变量。LIWC2015 是一个以预置字典为基础的文本分析工具,通过计算每种类型词汇在一篇文章中出现的频率,反映并捕捉文本的情感、作者的心理层面信息、作者的动机和时间(过去、现在、未来)关注度,以及作者所关心的事物信息。
ND 组用户的语言逻辑性更强,表达更真诚,情绪相对更积极正面
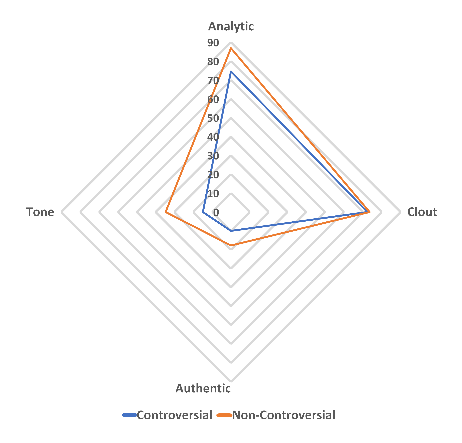
图 1 展示了 CD 和 ND 组文本在 4 项总结性语言学变量的得分。
![]()
CD 和 ND 组在「Clout」一项的得分相近。较高的「Clout」得分代表作者在写下这些文字的时候更多地站在一个专业的角度。与此同时,ND 组的「Analytical thinking」、「Authentic」以及「Emotional tones」得分都比 CD 组高。
「Analytical thinking」得分反映的是文本的逻辑性,较高的「Analytical thinking」分数意味着该文本更正式、更有逻辑。「Authentic」分数越高意味作者在写下这些文字的时候表达更为真诚。CD 和 ND 组的「Emotional tones」的得分都比 50 低,意味着两个组的文本主要情绪基调都是负面的,然而研究者从中发现了一些细微的差异:ND 组的文本相对 CD 组的文本更积极正面。
ND 组更关注自己未来的行为,CD 组用户更关注别人的现在或过去
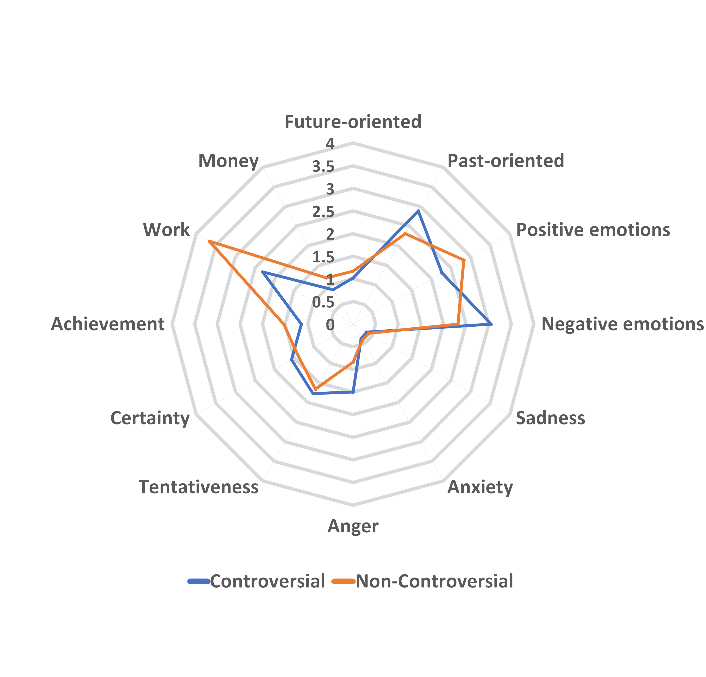
图 2 展示了 CD 与 ND 组在更为详细的 12 个语言学变量上的得分。
![]()
「future-oriented」和「past-oriented」分数通过分析作者使用的动词时态,来反映作者对时间点的关注。从上图中可以看出,ND 组的文字显示作者更关注未来,而 CD 组的文字显示作者更关注过去。为了更好地理解这两项分数的差异,本文采取了和 Gunsch et al. 类似的研究方法。
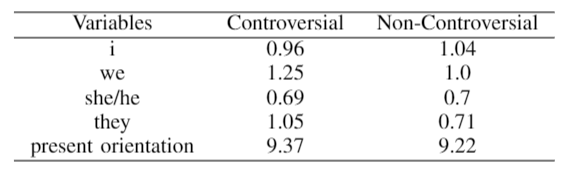
该研究进一步提取了另外 5 项语言学变量,包括 4 项人称代词的使用占比分数,以及 1 项时间点关注度分数。CD 与 ND 组这 5 项分数的情况如表 2 所示。
![]()
表 2:「i」、「we」、「she/he」、「they」以及 present-orientation 的得分。
CD 组的文本显示更多的是 other-reference (「they」),而 ND 组的文本显示的更多的是 self-reference (「i」、「we」)。两个组在「she/he」一项上的得分相近。对于现在的关注度,CD 组得分比 ND 组更高。
以上的发现与 Gunsch et al. 的发现类似,由此可以推测出,CD 组的文本更关注其他人在现在或过去的举动上,而 ND 组的文本更关注自己在未来的举动。
ND 组表现出更多的悲伤与焦虑,CD 组用户表现出更多愤怒
现有的研究发现,LIWC 可以识别出作者在书写时所表达的情绪。从上文的分析中研究者发现,CD 与 ND 组文本表达的主要情绪是负面的,其中 ND 组文本表达的情绪相对正面。这与研究者在图 2 中更详细的语言学变量「positive emotions」与「negative emotions」的发现是一致的。
然而,研究者在更为细致的」sadness」、「anxiety」与「anger」的变量中发现了微妙的差别。当人们在提及 COVID-19 时,ND 组的文本表现出更多的悲伤与焦虑,而 CD 组的文本表现出更多的愤怒。
ND 组用户的文本着重描述事实,CD 组用户的文本着重表达想法
「tentativeness」与「certainty」这两项语言学变量的得分反映的是作者所经历事件的发展程度,比方说事件已告一段落,抑或事件正在不断演变。在文本中,如果较多地使用」always」或者」never」这类词汇,会产生一个较高的「certainty」分数;如果较多地使用」maybe」或者」perhaps「这种词汇,文本则会产生一个较高的「tentativeness」分数。
在 CD 组的文本中,「certainty」和「tentativeness」分数较高,而 ND 组文本的这两项得分均相对较低。
对于这一微妙差别,该研究有一个有趣的猜想。从 1986 年开始,Pennebaker et al. 开始从不同的文本范畴中收集语言样本,包括博客、expressive writing、小说、日常对话、纽约时报、以及推特。他们将 LIWC 应用于这些样本,与该研究一样提取出了这些语言学变量的得分。在他们的发现中,纽约时报文本的「tentativeness」与「certainty」分数都是最低的,而博客、expressive writing、以及日常对话的这两项语言学变量的分数都相对较高。该研究的猜想与这一发现相关:CD 组的文本更类似博客、expressive writing 或者日常对话,更关注表达想法,而 ND 组的文本更类似于纽约时报这样的新闻报道,着重描述客观事实。
McClelland 发现人们在描述时使用的词汇会反映出个人需求,「achievement」分数便是通过计算该类词汇的使用频率来反映作者对于「achievement」的需求。
ND 组文本的「achievement」分数比 CD 组文本分数更高。关于这一发现的假设是,这一分数偏高,可能反映了 ND 组用户对于战胜 COVID-19 疫情更强烈的心理需求。
关于个人所关注的事物,ND 组文本的「work」与「money」分数更高,说明 ND 组的用户可能更关注工作及财务话题。对于工作的讨论不仅是在家办公所带来的工作状态的改变,也有很大一部分与失业率上升有关。
经过大量数据分析后,研究人员得出了对使用「中国病毒」这类表述人群的一系列结论,让我们对有偏见人群有了更深层的认识。
同时这也提醒我们,语言除了沟通用途外,还承载了社会、文化等诸多内涵。除了在这件事中用合适的词汇表示「COVID-19」之外,对于语言的使用,我们还需要思考更多。
参考文献
A. Matamoros-Fernández, ``Platformed racism: The mediation and circulation of an Australian race-based controversy on Twitter, Facebook and YouTube." Information, Communication & Society, 20(6), 930-946, 2017.
C. Lin, “Social reaction toward the 2019 novel coronavirus (COVID-19)." Soc Health Behavior, 3:1-2, 2020.
D. C. McClelland, “Inhibited power motivation and high bloodpressure in men.,”Journal of Abnormal Psychology, vol. 88,no. 2, p. 182, 1979.
I. Gagliardone, D. Gal, T. Alves, and G. Martinez, ``Countering online hate speech." Unesco Publishing, 2015.
J. W. Pennebaker, R. L. Boyd, K. Jordan, and K. Blackburn,“The development and psychometric properties of liwc2015,”Tech. Rep., 2015.
M. A. Gunsch, S. Brownlow, S. E. Haynes, and Z. Mabe,“Differential forms linguistic content of various of politicaladvertising,”Journal of Broadcasting & Electronic Media,vol. 44, no. 1, pp. 27–42, 2000.
Y. R. Tausczik and J. W. Pennebaker, “The psychologicalmeaning of words: Liwc and computerized text analysis meth-ods,”Journal of language and social psychology, vol. 29,no. 1, pp. 24–54, 2010.
Y. Zheng, E. Goh, and J. Wen, ``The effects of misleading media reports about COVID-19 on Chinese tourists’ mental health: a perspective article." Anatolia, 1-4, 2020.
Z. Waseem and D. Hovy, ``Hateful symbols or hateful people? predictive features for hate speech detection on twitter." In Proceedings of the NAACL student research workshop pp. 88-93, 2016.
4 月 28 日 20:00,机器之心联合华为昇腾学院开设的线上公开课《轻松上手开源框架 MindSpore》第三课将正式开讲,主题为《MindSpore 代码流程分析》,主要介绍 MindSpore 端到端调用流程与算子开发流程,扫码即可免费报名。
![]()