稀疏化是神经网络轻量化的重要手段,其中细粒度剪枝和结构化稀疏各有利弊。如何取二者之所长,实现更强大的模型压缩能力和端侧加速能力呢?本文将为大家介绍「细粒度结构化稀疏」。
前不久,英伟达黄老板从自家烤箱里端出了最新款基于 Ampere 架构的 A100 GPU。跟以往的新产品一样,Ampere 相比上一代产品性能有很大提升,并具备多个重要的新特性,其中之一就是细粒度结构化稀疏。这一特性能够为神经网络提供最多两倍的加速,本文我们就来一探究竟。
近年来,深度神经网络在很多领域得到成功应用,但这些网络往往体量巨大,需要很高的计算力和存储空间支持。这使得它们在手机等嵌入式设备中的应用比较困难。神经网络轻量化就是针对这一问题的研究领域。
轻量化的常用手段有:网络低精度化、低秩化近似、网络蒸馏、轻量化结构的设计与搜索,以及本文要讲的稀疏化等做法 [1]。
网络参数稀疏化,简单来讲就是通过适当的方法减少较大网络中的冗余成分,以降低网络对计算量和存储空间的需求。稀疏化可以通过稀疏化约束或权重剪枝等多种方法实现。其中逐元素 (element-wise,亦称细粒度) 稀疏化操作得到的是一个非结构化的网络结构(如下图左),这一做法通常能够达到较高的参数效率,从而有效地减少模型对存储空间的要求。
![]()
剪枝单元示意,依次为:单个权重,权重向量,
单个卷积核通道,整个卷积核。图像来源[2]
但是使用这一做法获得的网络中所保留的非零权重是随机出现的。这一特点与现代计算硬件加速器中的访存机制不相适应,因此这类稀疏化无法对网络进行有效的硬件加速。
在细粒度剪枝中,剪枝的操作单元是单个权重本身。在结构化剪枝中,被剪除的单元是更大的、有规则的权重组。很显然这一剪枝单元中的成份之间需要保持一定的空间相邻性,以提升稀疏化后网络的推理效率。
如上图所示,剪枝的单元可以是权重中的向量,卷积核单个输入通道,或者整个卷积核。剪枝的单元还可以是权重张量中的一个连续的区块。这些做法都是通过使得非零权重在空间上更紧凑,降低权重索引的复杂性,获得对硬件友好的稀疏结构。但是在同等性能下,结构化剪枝方法的参数效率与细粒度剪枝相比通常有较大差距[2]。
结构化稀疏提升了网络推理速度,但是牺牲了模型的性能,而原始的细粒度剪枝在推理速度上提升效果不佳。
细粒度结构化稀疏架构能有效的缓解这一矛盾,在尽量保持原始细粒度稀疏结构高参数效率优点的同时获得对加速硬件友好的网络结构 [3,4,5]。
因此细粒度结构化稀疏在模型权重中引入了特殊的约束,这里我们以全连接网络层为例对这一约束进行解释。
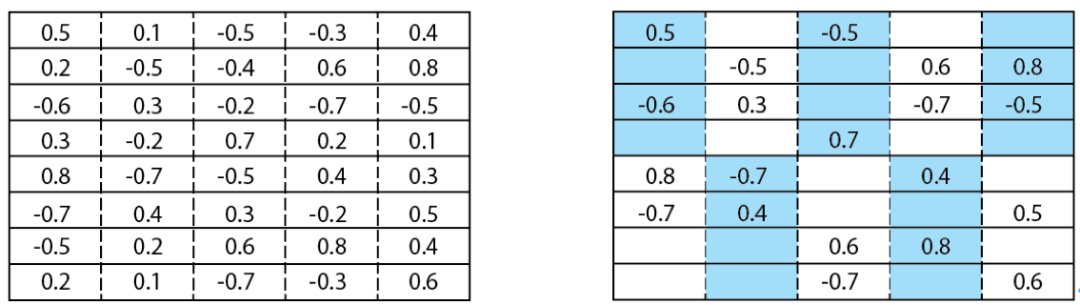
全连接层网络的权重可以用类似如下左图的矩阵来表示,对网络的稀疏化过程首先将权重分组,这里所举的示例以 4 个相邻的权重为一组。而后在每个权重组内限定固定个数的非零权重数目对权重进行稀疏化。如下右图所示,在稀疏化处理后,每个权重组(同一颜色块)中都正好留下 2 个非零权重,也就是 50% 的稀疏度。
![]()
左:剪枝前的权重;右:按细粒度结构化稀疏剪枝后的权重(组大小为 4)。
通过对模型施加这一结构约束,我们获得了规整的结构,权重的随机性被限制在了每个组内。这部分随机性带来的问题可以通过将同一组权重对应的数据完全装载到计算核心的寄存器上来解决,从而避开随机访问外存带来的延迟问题。这一结构同时也允许我们对网络推理计算在组边界上进行分割, 从而更好的将计算分块化以最大程度利用的加速器的多核并行计算能力。
这一例子中的结构正好和英伟达在 A100 中使用的一样,在这一稀疏度下网络中一半的计算因为权重为 0 被跳过。英伟达选择了 4 个权重为一组,延续了他们之前在 Volta 架构中引入的张量核 (Tensor Core) 结构中所使用的 4x4 数据结构。
在 A100 中所采用的设计只支持 50% 的原生稀疏度,这和我们在近期网络剪枝论文中读到的经常剪枝到很高稀疏度的网络还是很不一样的。50% 的稀疏度对于网络构成的约束不是那么强,多数情况下能够比较容易地做到无损剪枝。
A100 的硬件设计决定了只能支持 50% 这一种稀疏度,要想支持其他的稀疏度就得改变权重组的大小和组内非零权重的数量。
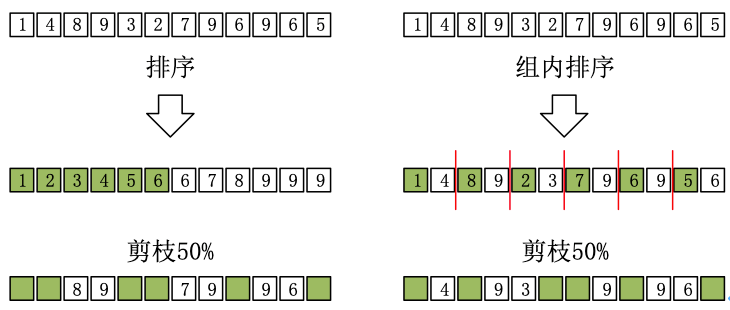
那么如果使用更大一些的权重组及保留更少的非零权重比例,会出现什么样的情况呢?对细粒度结构化稀疏网络的剪枝与常规的稀疏网络剪枝情况不大一样。常规的稀疏网络剪枝操作过程中,如下图左所示被剪对象是在一个较大的候选池中选出,所以重要特征被剪掉的概率相对较小。而在细粒度结构化稀疏网络的剪枝中(下图右),每次剪枝的候选池大小就是权重组的大小(本示例中组大小为 2),所以有用权重被剪掉的概率要比普通剪枝大很多。
![]()
剪枝示例。左:全局剪枝能稳定的剪除小权重;右:分组剪枝过程可能导致重要权重被剪掉。
从理论计算来看,使用较大的权重组会对模型构成相对较弱的约束;与同等稀疏度的非结构化稀疏相比较,结构化细粒度稀疏带来的额外约束会随着稀疏度的增加而上升[5]。换句话说,细粒度结构化稀疏会在权重组较大、稀疏度不是太高的情况下,效果相对较好。所以可能将细粒度结构化稀疏与通道级的结构化剪枝结合会获得更优的模型。
在英伟达给出的技术方案中,他们建议首先训练非稀疏网络,而后对网络进行细粒度结构化剪枝,再使用学习率重卷 (learning rate rewinding) 的方式对网络进行重训练。这里的 learning rate rewinding 就是对剪枝后的网络使用原始网络的学习率安排表进行重训练 [6]。
A100 中的网络稀疏度不高,那么如果要将模型结构扩展到更加稀疏的情况,学习率重卷是否仍能达到较好的结果呢?这一点还有待研究。研究 [5] 使用了一种叫做 targeted dropout[7]的训练方法,在该方法中被剪除的权重有机会得到恢复,因而能更好的应对细粒度结构化稀疏中小权重组造成的压力。实验显示这一做法的效果优于常用的 iterative pruning[1]。
细粒度结构化稀疏的研究应用目前还处在较初期的阶段,由于其独特的硬件友好特性相信这一设计未来会被更多的加速器采用。
1. Deng B, Li G, Han S, Shi L and Xie Y. Model Compression and Hardware Acceleration for Neural Networks: A Comprehensive Survey. Proceedings of the IEEE, vol. 108, no. 4, pp. 485-532, April 2020, doi: 10.1109/JPROC.2020.2976475.
2. Mao H, Han S, Pool J, Li W, Liu X, Wang Y and Dally W. Exploring the Regularity of Sparse Structure in Convolutional Neural Networks. arXiv preprint arxiv:1705.08922.
3. Wu X, Liu X, Li W, and Wu Q. Improved expressivity through dendritic neural networks. Advances in neural information processing systems. 2018.
4. Yao Z, Cao S, Xiao W, Zhang C, and Nie L. Balanced sparsity for efficient dnn inference on gpu. Proceedings of the AAAI Conference on Artificial Intelligence. 2019.
5. Yu Z, Wang C, Wang X, Wu Q, Zhao Y, and Wu X. Cross-Channel Intragroup Sparsity Neural Network arXiv preprint arXiv:1910.11971.
6. Renda A, Frankle J, and Carbin M. Comparing rewinding and fine-tuning in neural network pruning. International Conference on Learning Representations. 2020.
7. Gomez A, Aidan N, Zhang I, Swersky K, Gal Y, and Hinton G. Targeted dropout. Openreview.net. 2018.
世界人工智能大会线上活动(WAIC)是由上海市政府打造的国际顶级人工智能会议。为进一步促进人工智能技术与产业相融合,推动开发者技术生态建设,WAIC 2020年黑客马拉松将于7月9日-11日期间举办。
机器之心联合优必选科技与软银机器人公布两大赛题,邀请全球开发者来战。更多精彩赛题将于近期公布,欢迎关注。