【QA】哈工大张伟男:任务型对话系统
点击上方,选择星标或置顶,每天给你送干货
阅读大概需26分钟
跟随小博主,每天进步一丢丢


| 来源: 中国人工智能学会 公众号(ID: CAAI-1981)

演讲嘉宾介绍
报告导读
对话系统一般可以分为两种,即任务型对话系统(也称作目标导向型对话系统)和闲聊对话系统。本讲习班主要介绍任务型对话系统,其多用于垂直领域业务助理系统,如微软小娜、百度度秘、阿里小蜜以及我们研发的对话技术平台(DTP)等。这类系统具有明确需要完成的任务目标,如订餐、订票等。我们将首先介绍任务型对话系统的背景和定义,然后依次介绍其中的关键技术,包括自然语言理解(包括领域意图的识别和语义槽的填充)、对话管理(包括对话状态跟踪和对话策略优化)以及自然语言生成;接着介绍任务型对话系统的评价方法和国内外相关技术评测任务;最后对任务型对话系统的技术和应用趋势进行展望。
报告内容
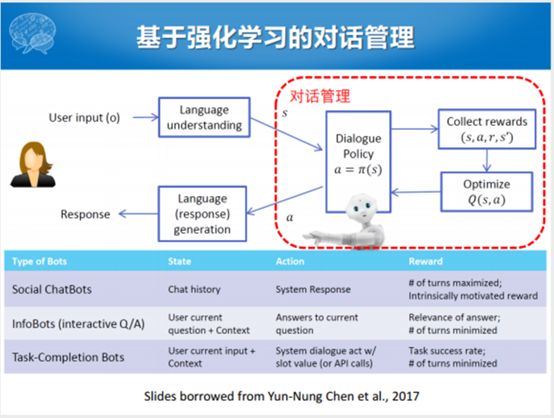
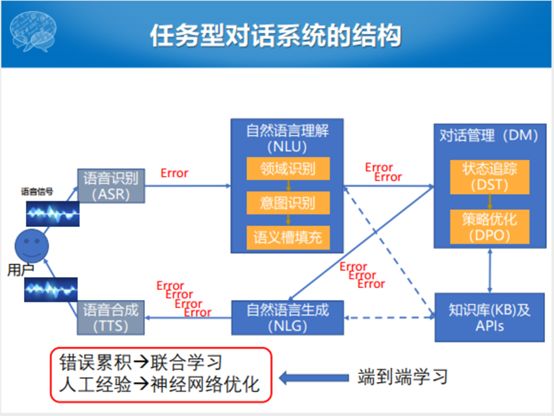
整个的任务型对话的框图里面,除了输入之外,除了语音信号和文本之外,比较大的三个模块就是自然语言理解,对话管理和自然语言生成。对话管理和语言生成的过程当中会遇到知识库和APIs。APIs在实际的应用过程中,可能会调一些查天气和地理位置的APIs,这些都可以被包含在任务型对话资源里面。
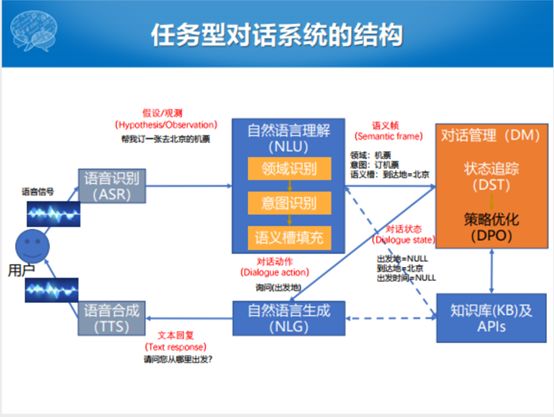
文本输入的句子,通过语义槽的填充之后,就识别出这样一个结果。输入的语言理解的状态,经过中间的对话管理的处理之后,得出来一个对话的动作(action)。比如,我们得出来一个动作是询问出发地,这个询问出发地的对话动作就会输入给自然语言生成的模块,自然语言生成模块就根据这个动作产生一个自然语言文本的回复“请问您从哪里出发”。
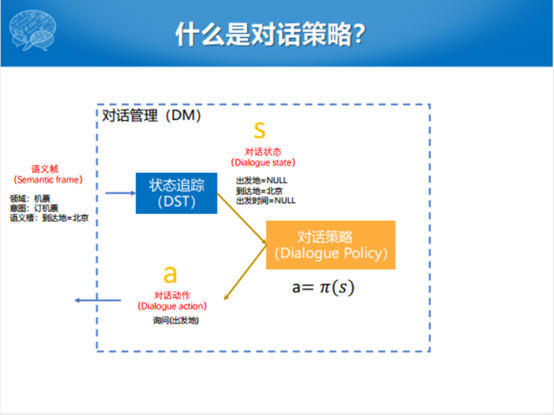
对话策略抽象一下,就是以对话的状态为输入,通过一个π函数来产生这样一个动作。怎么给它形式化呢,对话状态是序列的,开始的状态到结束的状态,整个对话的状态就是一个序列化的状态。根据这样一个状态集合,这个动作集合也是有穷的,在集合中可以枚举的。在这样一个对话状态的空间和对话状态的输入过程中,想建立起一个对应的关系。通过这样的对应关系,估计出来多轮对话的过程中,每一个自然语言的背后都有相应的动作与之对应。
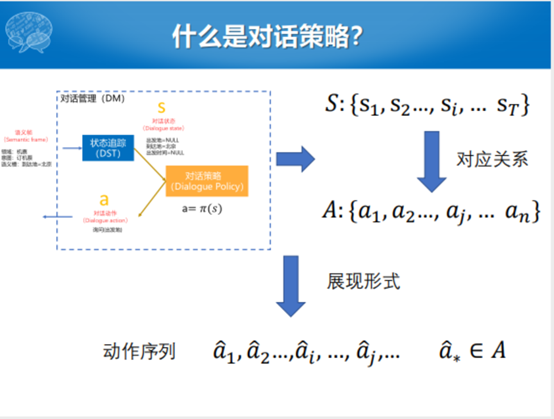
对话策略模型的输出就是这样一个动作的序列。整个的对话策略学习的目的或者输出大家都了解了,看一下怎么做这件事情,怎么样决策,根据一个状态产生什么样的动作。其实最简单的就是MIT提出来的类似于规则的对话状态控制流程。比如,在这个里面对话动作和对话状态绑定在一起,从最开始的地方接受一个输入,接受了输入以后就更新了对话的历史,以及对话的状态,我们就去判断。当然这个判断过程也是对话状态自动处理的部分,我们判断是不是模糊的查询,是不是包含着不确定性的,这个有一个判断机制。如果是非常模糊的话,就回去问用户,让用户重新输入。如果不是模糊的话,就有一系列的对话动作的处理模块,每处理一块就产生一个对话状态的维度和特征。最后的时候,判断是否需要回退到系统,需要的话产生一个系统的回复,再更新对话的历史和对话状态。如果是不能由机器或者模型产生后续的回复或者结果的话,我们还是回退到最开始的部分,采用一种澄清的方式让用户确认输入。
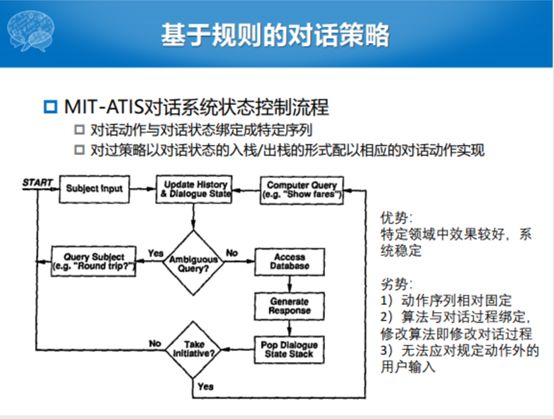
可以看到整个的方式其实就是一个比较偏向于规则的对话控制流程。在特定的领域或者特定比较小的任务上面,效果比较好。而且系统比较稳定,规定了这样的流程,规定了状态的转移的过程,就做的比较好;劣势也比较明显,动作状态序列都是固定的。算法与对话过程绑定,修改算法即修改对话过程。然后必须规规矩矩地按照系统的提示回答问题,否则流程就无法响应我们的需求。
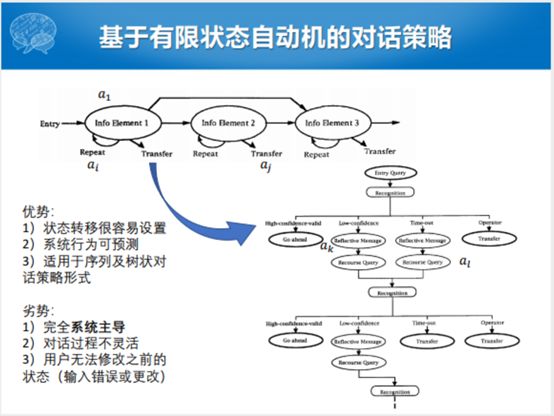
这个是最开始的MIT做的工作,当然这个ATIS的对话系统尽管比较早,对后面的影响比较大。另外一个比较早期的,基于有限状态自动机的对话测录。比如,说在搭建工业级或者对话流程控制没有那么复杂的场景下,有穷状态自动机的对话策略现在还在广泛的应用。整个过程就是把对话和对话状态之间的转移过程看成有限状态自动机,可以转换成一个树形结构。这种有穷状态自动机有什么好处呢?状态转移很容易设置,有状态转型的图模型,就转成树形的结构。整个系统是可预测的,适应用树状的策略决策模式。劣势也是比较显而易见的,跟ATIS没有特别大的区别,完全是系统主导的,人要配合系统,对话的状态不是特别灵活,用户没有回退的机制。
后面就出现了基于表格的对话策略。这种对话策略跟现在的策略比较相似了,有点类似于语音提取信息的方式,就用表格的形式表示对话的信息。整个过程有一个好处,我们人和机器可以混合主导,我们可以问机器一些问题,机器在这个过程当中也会问人的问题。不断地维护、更新表格的信息。表格上的信息有一个好处,我们可以更新。假如说这一轮说错了,下一轮还可以更新出来,这个更新的就在条目上。首先是混合主导,再就是容错性比较好且可更新。劣势是整个过程需要一个预设的脚本,就像我们说的系统生成的话都是预设的。根据什么样的上半句,拼接后半句,也不够灵活。

还有一个把脚本用到了对话策略的例子。MIT的Galaxy2是通过脚本流控制的,表格的形式没有一个明确的结构的过程,是通过不断地更新的过程,最终找到上面还有什么信息,缺什么信息,更新了什么信息,最后给你什么信息。但是这个Galaxy2有一个明显的自顶向下的规划结构,把这个大的Domain意图当成server,然后把Domain下面的一些意图当成Program。对每一个下面的这些语义槽当成更下层的规则。最后针对每一个槽或者针对每一个意图规定了一些若干个操作,比如有输入操作,有检索操作,有存储操作,有输出操作。一个脚本化或者流化的对话控制就是这样一个过程。我们看每一个节点都是对话的动作,但是这种对话动作序列的过程不是自动化生成的过程,而是由脚本控制的。这个也是一样的,下边四个变量,rule是什么样的,Input、output怎么实现的。它的优势就是任务扩展方便。多层的结构有点像现在的层次化或者是Domain到意图再到槽的自顶向下的构架,逻辑比较清晰,任务扩展相对方便一些。劣势就是这些规则都是手工定义的,对话流控制需要预设,也没有可学习的过程。

总结一下上面介绍的。无论是基于规则的也好,还是基于流控制的,还是有限自动机的。对话的动作之间是独立或局部依赖,以及不能对整体的动作序列进行建模,只能一个动作一个动作进行建模。另外就是对话策略的输出是一个确定的,就是下一个动作,而不是下一个动作在所有的动作空间上面的概率分布,这也是目前已有的之前讲过方法的几个不足的地方。

后面就是基于规划的方法。什么叫基于规划的方法?Wasson在1990年的时候给规划进行了一个定义,通过创建一个动作序列来实现某个目标的求解方法,并尝试预测执行该规划的效果。创建一个动作序列就是人机对话中的若干问题和若干回复,最终实现的目标是帮人完成相应的任务,后面的人就想能不能通过规划的方法来做对话策略的学习,也就是后面的基于规划的方法来求解对话策略学习的过程。

当然这个规划也有两种:一种就是相对来说会比较固定,就是人写这个规划库。比如,我们知道已有的数据里面,动作的序列是什么样的,就一条一条的把动作序列写出来,相对来说这种就比较的简单。当然如果写的规划库的数量足够多的话,其实鲁棒性还行。我们希望系统能够自动化一点,这里面考虑到动态的规划,不是动态规划算法。动态的规划就是给定这样一个输入的序列,希望是一个整体的考虑,是建模联合分布,但是实际的过程中,我们其实可以进行Markov的假设,动态规划的过程就是给定若干个前续的动作序列,预测后续的动作序列是什么样的。这个过程就是通过规划的方式进行进行求解对话的过程。
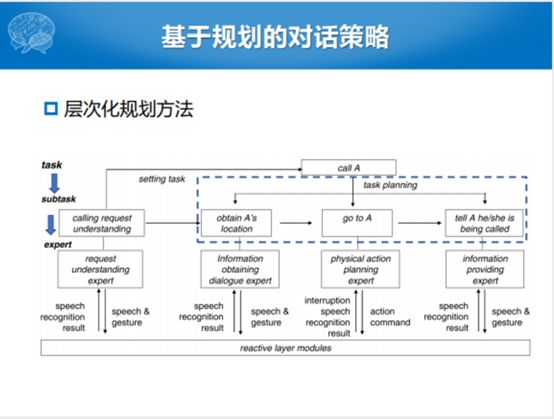
除了刚才的静态或者说规划库的方法和动态的规划之后,还有层次化规划的方法。这个可以看成是基于层次化的对话策略学习的,在规划版本上的扩展。把这个任务自顶向下做一个分解,这个里面涉及到了一个事儿,我要告诉有一个A同学,在寝室楼下阿姨这里来了一个电话,正好A的同寝的人来了,阿姨就说你告诉A同学说有电话找他。这个B同学就要做几件事情,第一件事情要知道A到底是在寝室,在洗澡间还是在厕所。知道A的位置之后就要走到A这块,说你有一个电话在楼下找你,就把这样整个任务分成了三个子任务。总体来说,这种层次化的方法,一方面有一个比较清晰脉络的逻辑。整个规划的方法从上层大的任务分解到子任务,子任务分解到操作,每一个都有相应的属性,跟之前的层次化的方法特别的像。这样的方法还是存在一定的问题,首先对系统的错误比较敏感,鲁棒性比较差。对话策略清晰归清晰,但是相对固定,灵活性不够。第三是策略和任务绑定,很难在任务间迁移,策略决策过程是和任务和领域是强相关的。
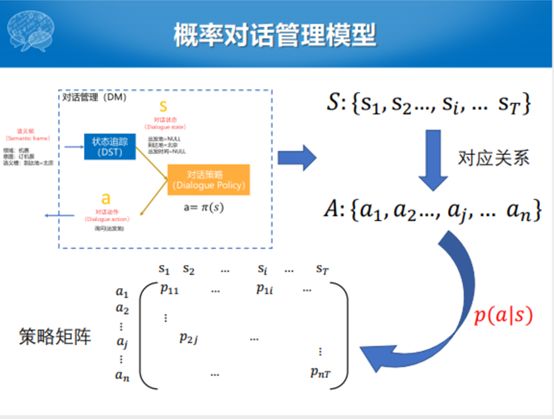
上个世纪或者是本世纪初这一段时间,2000年到2010年之前大家都在想,固定的不行就搞概率的。能不能使用概率对话模型估计从对话状态到动作序列的对应关系,只不过方式就变成了学概率,求解整个对话状态序列和动作序列概率矩阵。每一个矩阵上面的相应位置的元素就对应着给当前状态下给A的状态是什么样的。学习对话策略的过程,其实就是在策略矩阵上面不断优化的过程。
最简单的一种方式,或者能够比较自然地应用这种策略矩阵求解概率化的方式就是强化学习。强化学习的框架也比较简单,主要有对话的Agent,这个里面有对话状态跟踪和对话学习两块。这个里面有Action,在对话里面就是对话的动作,这个对话的动作是问用户一个问题,或者跟用户确认一下信息,或者向用户展示一个信息。
动作之后,还有就是用户会针对对话管理系统给出的动作进行一部分反馈,有的人把这块表示成大的就叫环境(Environment),也有的人把这块表示成Interpreter和一个Environment,这里面表示这两种形式都可以。但是这里面其实不光是Environment,还要对对话产生的动作进行一个表示,表示之后产生一个对话的奖励,回馈给对话系统。整个过程之中,除了Interpreter的奖励之外,还会产生对用户输入的识别以及对话状态的建模。Agent这边对话管理的动作实际是到Environment这块,出口是从Interpreter出去的。
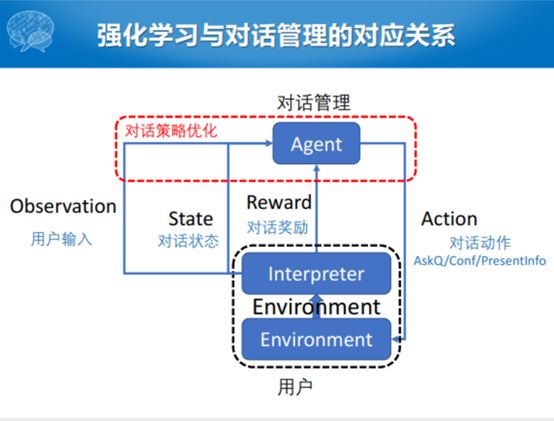
我们把强化学习的比较粗的框架和我们的任务型对话的策略学习相关联的。Action就是对话的动作,系统产生什么样的话。针对用户产生的话,我产生什么反应,我是接受还是反馈,有一个相应的reward。整个对话管理对应着对话策略的优化过程。已有的基于强化学习的对话策略学习或者对话管理这个部分都完成哪些事呢?针对不同类型的,如果是闲聊的,问答的和任务型的,在强化学习框架下面,它的状态、动作、奖励都不大一样。
比如,任务型的bot在强化学习的框架之下,这个对话状态就是用户当前的输入以及历史对话的上下文。这里面不一定是这种纯文本的方式,包括了前面的对话状态追踪过程当中对话的表示。这些动作其实刚才给大家解释地比较清楚了,系统采取什么样的方式回复,以及里面到底是否包含确认的话。例如,我跟用户确认是不是要订12月16日的航班,这是典型的确认的动作,这里还包含了12月16日信息槽的信息。整个动作之中,还包含着若干个对话的值,这个过程之中调一些API过来,这些都是一部分。
我们从系统中已经拿到了这样一个动作之后,我们会给动作打一个分,或者系统会评论一个值,但是任务中,第一个事就是经过这样系统的反馈之后,我们对话到底成没成功,我帮你完没完成具体的任务,这个是指示性的信号,要么是0,要么是1。当然这个轮次要尽量的少,所以我们整个在任务型对话之中的状态、动作和奖励函数表达的是什么意思,我给大家简单的解释一下。
我们关注的就是对话管理这一块,对话管理这一块我们主要关注于对话策略学习的过程。这里面涉及到怎么样去收集或者定义reward,怎么样优化状态和动作之间的关系,当然现在通常来说用的都是Q函数。
我们说基于强化学习的对话管理,通常来说有两个比较重要的过程。一个是我们怎么样让用户能够参与到整个系统的构建的过程中,现在比较火的就是叫Human-in-the-loop。当然这种方式有一种不好,就是确实耗时耗力,那我们不用它的话,初始系统化又不是太好。所以现在比较大的方向就是要有一定人的参与,但是又不能太耗费人力。另外就是怎么样定义对话奖励函数,两个方面,尽可能提高完成的任务成功率和尽可能的减少平均对话的函数。

如果用形式化的方式表示,这也是现在比较多的任务型对话奖励的形式,我们完成任务对话的之中,我们设置系统轮次最大值。我们给系统20轮机会,20轮之后再无法完成用户的任务就把你停掉,这个就是Nmax,取值就是0和1。这个N是我当前进行任务型对话的过程之中,我实际已经进行了多少轮,我们看什么时候是0呢?虽然最终成功了,达到了轮次,也是最大的轮次,这个时候20-20就是0。如果你用20轮,我只用10轮就搞定了,而且还成功了,这个R就是10,是比较大的数值。当然最好的就是1轮,但是这个不太可能。
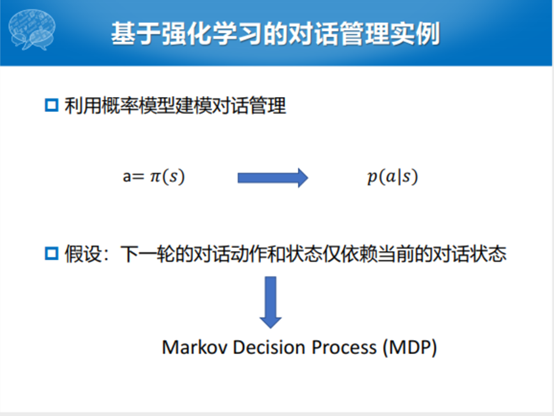
通过奖励函数的定义,就可以大概知道整个系统优化的方向是什么样的方向。最简单的方式,刚才也说整个大的背景就是概率的策略学习的框架下,采用强化学习的方式去做策略的估计和学习。最简单的方式我们就假设一下,好的方式是我们给定之前所有对话状态的联合分布和估计后面对话动作的分布。但是实际不大可能,因为计算量太大了,通常就会采用Markov假设,假设下一轮的动作只跟当前的对话状态有关系。这种情况下,自然而然地就用MDP的方式进行建模。
MDP建模对话策略的过程分为三个部分。这个策略矩阵就是对话状态和对话动作之间概率的对应关系。上面是转移函数,根据给定对话状态和给定这样当前轮次的对话轮次的动作,产生下一次对话状态是什么样的。我们可以看成是当前状态和下一个状态的转移过程。如果A有所有的对话空间的话,实际上就是一个分布,或者说我们可以把它取成一个从某一个对话状态所有的可能动作的估计。

最后是比较重要的奖励函数,通常来说,这个奖励函数都被估计成所有的奖励。在所有的动作状态空间之上,再估计的时候就是动作期望的值。后面的奖励函数就不那么简单了,是一个期望概率的估计值。这里面实际上策略矩阵就是对话策略,奖励函数就是对话策略学习优化的目标函数。

整个过程也比较简单,目标就是用MDP的方式给定对话状态序列,优化对话奖励函数。整个过程就是要建模期望,这个期望就是整个基于值迭代方式的这后半部分。这部分可以认为是奖励,这部分可以认为是状态转移的函数。
整个过程可以采取值函数的方式,更自然的方式是采用Q函数的方式。最重要优化的方式就是用Q值来模拟给定当前的状态和当前的动作,然后求解能够使Q函数达到最大值A的过程。其实这整个过程跟我们对话策略优化的根本目标是一致的,根据这个状态求取这样一个对话动作,决策下一步回复给用户什么内容。

大家可能觉得这个对话状态可能是有穷的,对话动作也是有穷的,为什么要进行策略优化。比如,做好之后就查那个表,给定一个状态之后就查表里面哪一个动作的概率最大。但是通常来说不这么做,通常来说少量数据的情况下表是不准的。所以我们只能不断地训练去更新那个表,当然训练好了之后,实际应用过程中可以进行查表的,怎么样取样,怎么样变得更好。在实际的更新或者是学习过程中,这个对话状态和动作的组合空间是非常大的。

所有的问题都在于现在的空间大,精确估计转移函数非常难,要求期望的一部分,第一项就是转移函数的T,我们没有精确地估计这个转移函数,为什么呢?假如说有这样四个动作,这四个Action每一个slot,假如说这个slot有四个槽,这四个槽上面,每一个槽认为有多种取值,在日常中这是非常常见的。确认与否的有4个确认的动作,每一个动作的值上面也是已确认和不确认两种。这438也可以看成是438种情况,在这种动作和空间中组合一下看对话策略有多少种。这个状态空间就是2的8次方×438就是112128。也不要被理论上的状态空间吓倒,其实很多是无效的,通过预测的剪枝,大大缩小这个状态空间。但是仍然非常巨大,所以整个对话策略需要进行优化的。
比较简单的方式就是我们用动态规划的方式。这有一个好处,大家学过算法都知道,动态规划有一个好处就是算过的东西不用再算了,下一次直接拿过来就行了。基本思想就是给定一个初始的对话策略,假如说每一个都是均匀分布的,都是1/N,给定一个初始化的状态之后,扫描整个对话状态和动作空间,从而递归地估计值函数。典型的方式就是值迭代的方式,通过后一个状态的值,定义前一个值,这种方法也是往前看一步,尽管当前的值不知道怎么回事,但是可以往前看。真正选择下一个状态的时候,递归往回带的时候,可以选择下一个状态里面值最大的状态把它带回去。当值函数被替代之后,不断地重复,直到把对话状态都计算一遍。

这里面还有一个问题,就是动态规划的方式,尽管可以通过策略缩小状态空间,缓解对话状态和动作空间巨大的事情。但是基本假设其实还是扫描整个的空间,可以通过剪枝,可以通过什么样的规则预先制定对话状态和动作之间的冲突方式,缩小这个状态空间。不管缩到多小,这种方法的特点就是要扫描整个状态空间。那能不能通过采样的方式部分的估计,通过部分的样本估计整个样本的分布。训练深度学习也会使用采样的方式,包括以前做LDA也是采样的方式估计的。

自然而然就想到能不能采样一下,不一定每一次都求全局最优解,就求最近的最优解就可以了。比如说利用随机的策略,随机的初始化对话的策略,我们用π表示对话的策略函数,对于序列中出现的训练数据中的(s,a)对,就是状态和动作之间的组合对,然后更新Q函数。这里面a*表示的是当前使得这个Q函数达到最大值的动作状态的A是什么样的。我们当前选择到A等于最优状态A的时候,我们就以这样对话的方式更新已有的矩阵。总之这是一种比较简单的方式,这种方式叫做epsilon-soft policy。大家更多的听见的是叫epsilon-greedy,但是这个epsilon-greedy跟这个类似。
如果看epsilon-soft policy的更新策略,如果让这个epsilon趋近于0,就变成了什么呢?当a使得这个Q最大的时候,就让整个的动作对话状态是1,否则就是0。如果是采用这种方式,其实就不是概率性的空间,就是确定的。假如还是对话策略矩阵的话,本身能看到基本上都是经过行列交换,总能换出来若干个单位变向量组成的矩阵。当epsilon-soft policy趋近于0的时候,就是一个相对的对话策略。

刚才提到了我们要求当前的状态,求一个当前的Q函数值最大的动作。怎么样进行Q函数的更新,两种方式,也是通过采样的方式,第一种方式就是通过Monte Carlo采样的方式。这里面先查数,看这个已有的训练数据里面当前给定的状态和动作出现多少次,出现次数越多,当前给出这个动作的可能性就越大,执行度就越高。另外一个是实际上给定这样一个动作和这样一个状态之后,产生一个即时奖励是什么样的。这个即时奖励不是说往后看,不是像Alpha go似的,下一步棋看最终的胜利是多少,而是当前下一步棋,吃了你几个子,我就可以拿到一个reward,或者叫即时的reward。
更新的过程就是一个平均采样的过程,因为除了一下当前的(s,a)出现对数的总和,我们Q函数的更新策略就是算一下当前的Q值得到了多少的奖励,然后把所有可能性都加到一起,再除以所有的可能性,整个Q就是更新的过程。另外一种更新的过程,当前的这一步的决策,不足以支撑我们选择最优的Q函数,再往后看一个状态,看一个动作,我们让这个动作和当前的Q函数之间的差值加上一个相应的因子,加上一个相应的参数再乘以相应的因子,更新这样的Q值。这个里面的α就是一个learning rate,是当时可调的参数,这里面的r就是给定当前动作的即时奖励。这里面最大的差别要么只看当前,要么我们往下看一下,差别就在这里。
刚才讲到动态规划方法扫描动态空间比较费事,虽然达到全局的最优,后面采样的方法也可以达到一定的近似的解。这里面有人对比一下基于动态规划的方法和采样的方法。

其实这里面可以看到,动态规划的方法,要访问到很大很大的状态空间才能够准确地估计出规划策略的值。基于采样的方式我们就这么多对话状态和动作的空间之后,我们可能进行一个值估计,等到访问到的对话状态的空间到了动态规划初始空间的时候,采样的方式基本上达到最优了。整个采样的方式相对于动态规划的方式来讲还是比较高效的,能够在一个相对少的访问的对话状态和对话空间之上达到比较优化的方式。
总结一下对话策略学习的方式有哪些优缺点。首先DP动态规划的算法要搜索整个状态空间,效率比较低,但是通常来说能够达到最优解。采样的方式不一定能够达到最优解,通过实际的图也可以看到实际的效果还成。另外采样的方法在通常的实际的过程中,不是一次采样就结束,需要多次采样的方式。如果这样采样的方式把人融合进来的话,或者拿到真实用户反馈情况的话,多次采样也不是很实际的。每次采样尽管比动态规划的方式访问的空间低,但是也有很大的状态空间,不能拿这样的状态空间进行反馈。所以我们说整个的实际理论上有真实用户参与学习的方式下,这种采样的方式也不是特别实际。有没有相对来说不需要人介入那么多,还能在整个过程当中比较实际应用起来的呢?既然真实的用户用不起来,我可以用一个模型进行左右互博来学习。这种方式,如果大家对阿尔法的算法有所了解,媒体上也宣传AlphaGo左右互博自我更新的过程,就是说的用户模拟器的过程。整个用户模拟器的动机就是没有办法用大量的人,即使是采样也没有办法进行在线的对话策略学习,产生对话状态你就给我一个分数,不切实际,成本比较高。
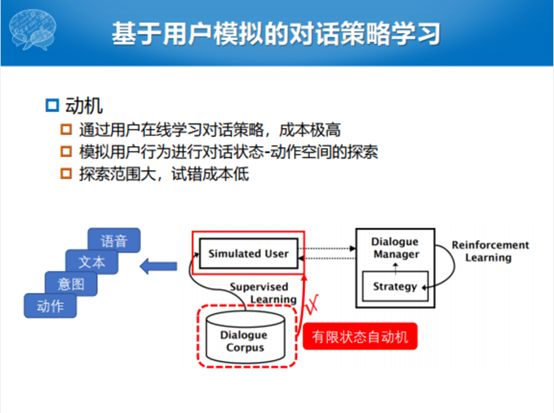
能不能用简单的方式训练一个模拟器,模拟器再去训对话模型。在整个过程中,相当于一个模型训另外一个模型。数据库有多少个空间,多少个槽的范围,通常来说对话的模型是知道的。这个模型就是所说的用户模拟的过程,怀揣着这样的意图,人的意图也可以通过这种方式告诉模型,如果用用户模拟器的话,就可以用最简单的方式,每一次都用熵值最大的槽,用这种方式不断地训对话模型,试错成本特别低。AlphaGo一晚上要下几万盘棋,而且它能够探索到很大的范围。我们说动态规划方式可以探索对话状态的空间,采样的方式没有办法探测整个空间。用户模拟的方式可以用低成本的方式去试,同时可以把整个的空间试到,不需要那么多人参与。讲了相对比较基础的对话策略基本的做法,以及我们怎么样去把人的因素考虑进来,怎么样让对话模型自己训练自己。
通过刚才的介绍,看到有几方面。首先就是怎么样定义,或者怎么样初始化,怎么样更新这个对话的策略,以及采用什么样的Q函数去学习。我们有没有更优化一点的Q函数的学习方式?还有没有更客观的,就拿任务完成的方式和对话轮次的方式定义这个奖励函数,有没有更好一点的。比如说你同样是两个系统,以同样的任务完成率完成一个任务,用户就是喜欢用你的,但是已有的奖励函数就没有定义,所以我们想优化的方向,其中一个方向就是能不能够更好地定义更客观的一个奖励函数。最后一个方向,就是我们刚才说的对话模拟,我们怎么样让这个对话模拟器更接近于人。最简单的实现方式就是用这种有限状态自动机的方式去训练模拟器,用模拟器访问数据库,不断地问模型这个问题,整个过程中提升模型跟人的交互的能力。最后一个就是可能优化的方向,也是最近有进展的方向,就是能不能有更真实的对话模拟器。

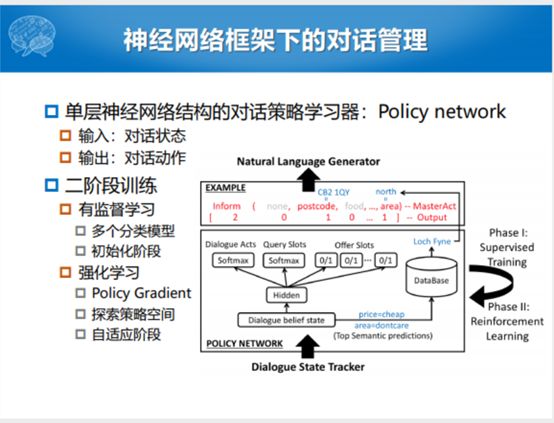
接下来就是分四个工作分别介绍一下四个方向的进展。第一个进展就是更简单的对话策略学习的方式。现在随着2014年深度学习火起来,大家就给出一大套对话策略估计的方式,有深度学习,深度神经网络。能不能用深度神经网络的东西做这个事情,一个想法就是用单层的神经网络结构的对话策略学习器。最开始就是Policy network的方式,这个也是非常的纯粹,输入就是对话状态,输出就是对话动作,所有的智能都是参数里面蕴含着,整个架构就是这样的架构。然后我们忽略上面的NLG的过程,实际它的输入就是state,输出就是Act。每一个阶段是总归有少量的或者上千条的人人对话数据对,我拿它做一个初始化,初始化的过程中是有监督的学习,我们通过这种方式来学习到对话的动作的分布是什么样的,当前的Query里面蕴含着哪些slot也是用这个估计的,以及需要问用户哪些问题,每一个过程都是一个独立的二分类的过程,通过这样的方式先训练一下。再一个过程之中就有Policy的强化学习和方式,不断探索这个策略空间,就是初始化加上后学习的内容。
更优化的Q值函数,这个深度Q值网络,最深的时候就是AlphaGo的时候,这个Q函数之前的方式可以用值迭代的方式更新。但是有一个问题,我们怎么样来估计下一个状态S和给定这个A,下一个动作A1的奖励值。传统的方法可以用Bernoulli方程的方式去求解,但是时间复杂度特别高。深度神经网络出来之后,就想反正输入是一个状态和动作,你就要估计一个Q值,我用一个MLP行不行,就把这个对话策略学习形式变化一个前馈全连接网络,从而变得更加简单,不管什么参数都蕴含在W矩阵里面。当然这个训练过程中还是采样的方式,采用采样的方式,去更新那个π函数,我们说用Monte Carlo的方式来更新所有W的参数,这种方式也是后面提到的微软2018年发表的BBQ-learning的方式。

更加客观的奖励函数上面的进展。现在定义的奖励函数特别刚性,要么成功,要么不成功。同样成功的情况下,用户对哪一个系统更满意不知道。一个简单的方式就是把用户的满意度,用变量的方式,比如定五档,从1-5,5是最满意的,1是不那么满意的,2可能是稍微满意一点,3是满意,4是很满意,5是特别满意。把用户的成功率转化成满意度的方式,离散化的取值范围弄到奖励函数里面,这个奖励函数是原始没有变过奖励函数的变化形式,把原来的用对话成功率的方式建模,变成满意度的建模方式的时候,相对来说客观一点的奖励函数的时候,是可以通过这个方式是近似的。
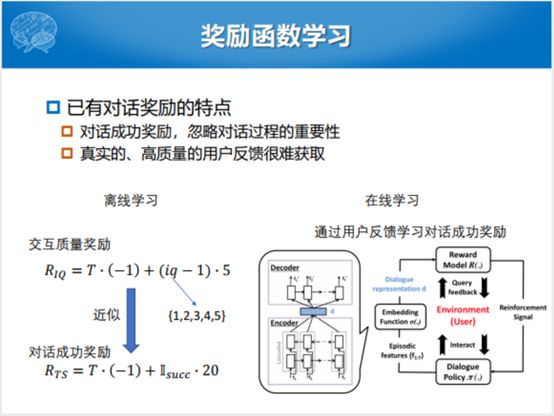
更加真实的一个用户模拟器方面,也是微软提出来这样一个模型。原来要么是机器人,要么是人跟NLU,要么就是这个机器人,就叫对话模拟器,根据dialogue corpus去学,学完了之后不断地去训练dialogue model,人参与度不高。在整个框架下,分成左右两部分,第一部分是人教Simulator,整个过程中,投入很小的精力初始化,初始化之后就跟这边去学。人看到有一些状态和动作之间的转移方式不对,再去纠正它,再去训练它。通过这种分时分阶段的对话的模拟,能够训练更好的,就是Simulator和这个人越来越像。
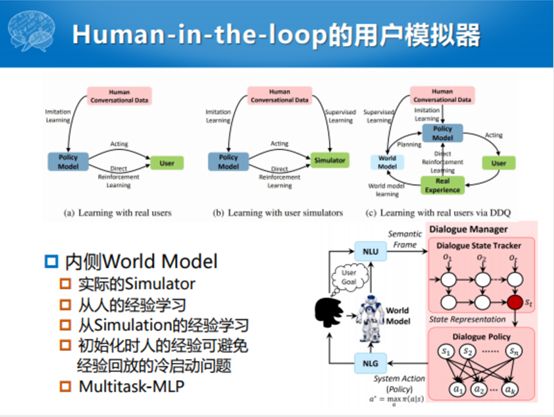
对于任务型对话系统,在对话管理之后,就是对话生成的过程。对话生成的过程,也是在这样一个整体框图下面,这个对话管理之后已经产生了一个动作。假如说这个动作就是我们期望的动作,根据这个动作怎么样产生一个类似于人一样的回复呢?这种方式可以简单,也可以复杂。简单的方式,我们说可以整个从对话的动作到自然语言语句的过程任务是非常明确的。以前主要的步骤分为三步,一个是文本规划,生成句子的语义帧序列,再就是生成关键词、句法等结构信息,最后就是表层规划,生成辅助词及完整的句子。这个里面自然语言的生成不特指对话系统的自然语言生成,NLU那是一个大概念,只不过我们在对话系统里管的第一步也叫NLU。同样NLG也是比较大,生成新闻、评论,生成高考作文、公文、假新闻,这都是自然语言生成的过程。

还有比这个更简单的方法,是什么方法呢?就是写文本,反正对话动作是有限,询问出发地或者确认目的地,雇两个人写一条给一块钱,你就写吧,询问出发地。一个人写“您从哪里出发”,另一个同学写“请问您从哪里出发”,确认目的地还是两个人分别去写,当然这个里面会把相应的目的地的槽空出来。总之我们雇了一些人,就能够实现我们这个目的,假如对话系统够简单,我们再用比较简单的策略选择的过程的话,搭起任务型对话系统挺简单的,特点就是简单、机械,成本有点高,你得给标注者一定的钱,有多少人工就有多少智能。

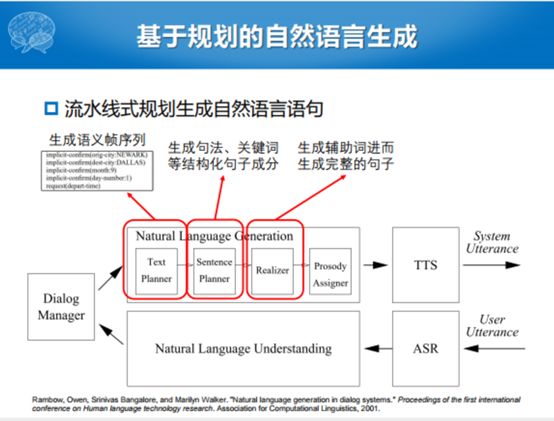
其实通常来说,我们都不会这么做,最简单的方式就是流水线式规划生成自然语言生成。通过这种Dialogue manager已经产生了对话的动作,然后还是“三步走”,第一步生成一个语义帧的序列,这种序列里面包含着我要生成什么样的句子。我现在就要生成一个确认句子,确认句子之后,要生成一定的句法、关键词和结构化的成分,这个部分相当于把句子主干拼出来了。然后往这个里面塞助词、标点符号、感叹号,最终通过这个“三步走”的方式,把自然语言的句子分出来了。当然如果是一个语音对话系统,最后还要把文字转化成语音播出去,如果是文本的话,直接把完整句子反馈给用户就完事了。除了流水线式的规划的方式之外,因为我们说这是2001年左右的工作,后面到了2002年我们能不能用一些统计学习的方式代替一下部分的流水线的规划方法的某一个模块,就出现了这种方式。
统计学习方法能够事先决策。句子生成过程中,规划多少属性,以及属性的空间里面,我们要规划了若干个属性之后,具体挑哪几个进行规划的生成。整个过程有一个表层规划的过程,就是句子规划、表层规划和句子生成的过程。流程没有太大的变化,还是规划的“三步走”。但是表层规划上面,用统计语言模型进行训练之后,就变成了用n-gram的方式去训练,这是传统的统计模型。我们再用基于语言模型句子生成的方式,比如说这里面“吃苹果”就比“吃太阳”的概率高,我们在规划过程中生成“吃苹果”的概率就比较高。
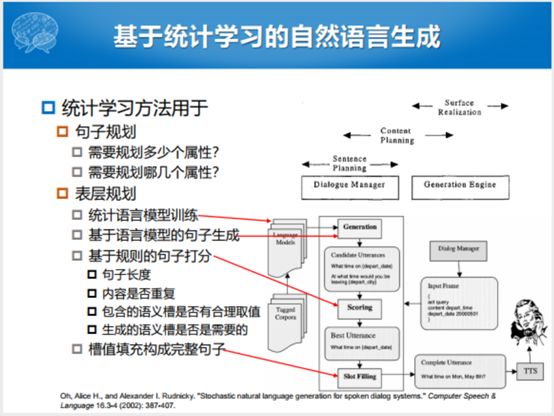
最后再若干个生成。不止生成一个,有若干个候选。我们有一套规则生成若干个候选进行打分,这个规则包括但不限于:句子长度。包含的语义槽有合理的取值。如果生成的语义槽不给一个合适的值,你生成的句子是不完整的句子,可能也不太有特别高的分值。还有生成的语义槽是否是需要的,我最开始规划的属性你生成出来没有,或者你生出来不是规划范围之内,我们就可以认为你这个槽是不需要的。最终通过这种方式得到完整的自然语言的句子。
后面到了深度学习的时代,这是2015年的时候,很自然的方式就是统计语言模型可能有一个局部的相关性。我们用RNN的方式建模整体的特性,用双向的RNN做了一下,整个过程分为两步走,跟规划的方式前两步捏在一起,前两步捏在一起之后,有一个去词汇化的过程,把这个槽和值抽出来,抽出来这样一个方式,抽成slot name和slot food这样的方式。通过这样的方式之后RNN建模,等到最后形式的时候,其实跟上一个自然语言生成的方式有点像,只不过最终用RNN生成模板,再通过对话已有的状态和对话采集到的语义槽的值,生成自然语言句子的时候,把值填进去。这个过程跟之前比较相似,但是比较好的就是采取了双向RNN的模式进行的语言模型的生成。
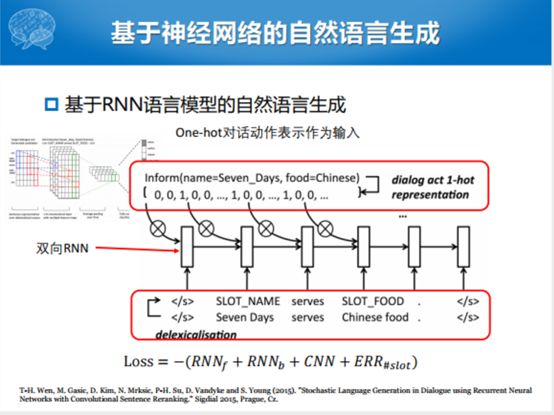
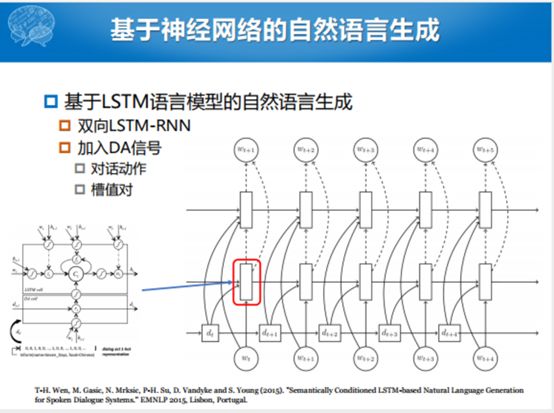
这个是双向的RNN,但是这个里面的每一个unit替换成了LSTM,加入了Domain Act,就是对话动作的信息。除了对话动作的信息,还加入了槽值对的信息,整个过程还是用双向的LSTM生成句子。把DA信号加进去主要加的是这部分。这个就是自然语言生成这部分,这部分没有特别多的工作,大家可能大部分的工作集中在NLU和DM方面。
随着技术发展的过程,把这种Pipeline的方式从头到尾的生成,走了一圈的技术模块把回复返回给用户。这个过程中有一个问题,在语音识别和自然理解过程当中有错误,这个错误传到DM这块就会叠加,DM再传到自然语言生成还会叠加,自然语言生成再往语音合成还会有错误,这就是错误累积的过程。能不能联合学习的方式,整个的错误累积的过程能不能用神经网络优化方式取代这种人工接待的方式。研究端到端学习的人就开始做工作了,端到端成为一个黑盒,整个系统不要那么多步骤。
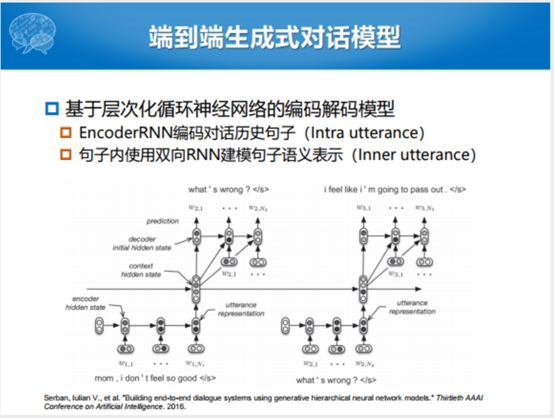
实际的状态就是端到端的生成式对话模型,最开始可以看到的不是任务型的对话,是开放域的对话,是2016年蒙特利尔大学他们提出的模型叫做HRED的模型,这样一句话建模的时候,你可以从第一个词建模到最后一个词。如果你说给你一个对话历史,建模多轮的情况下,建模整个的对话历史,建立多轮的形式下,给我一个合理的回复,怎么样建立对话历史。他们就提出一个简单粗暴的方式,句子和句子之间也用RNN去Encoder。
HRED不是针对任务型对话做的,出来以后在开放域对话的表现还可以,没有那么多诟病,其实更好一点的方式不是以那种粗暴的建模方式去建。既然现在的深度学习发展的这么好,我们能不能用深度学习把Pipeline保留,但是我把Pipeline中的每一个部分都用深度神经网络去代替,比如说NLU用数据标注的方式去识别,用MLP的方式去识别意图,填充槽。整个的Policy network这块因为也提出来过基于深度学习,对话策略学习的方式。自然语言生成的方式也可以用RNN的方式学习。可以串联在一起,虽然不是完完整整的端到端的过程,但是每一个过程都是端到端。当然用的就是CNN+RNN的方式。这个句子模板也是用Attention-based RNN实现的。
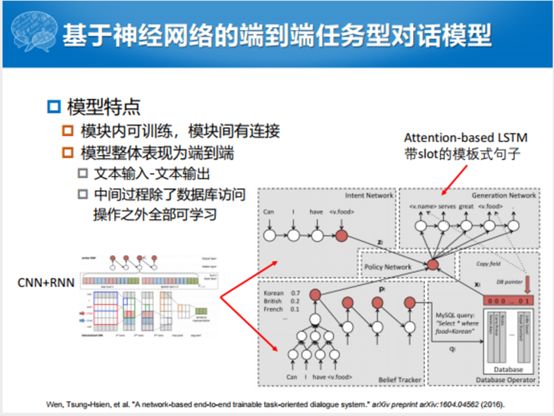
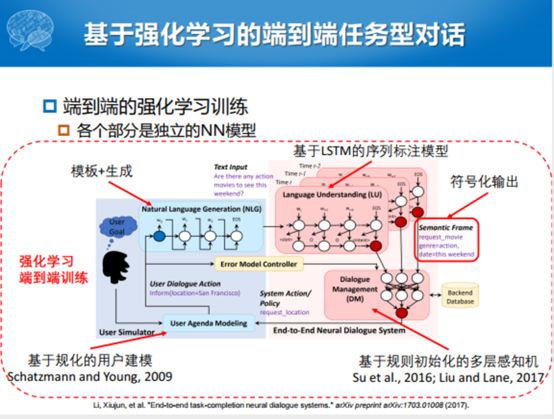
除了深度学习之外,大家也知道这个强化学习,能不能用Pipeline的方式在结合过程当中,错误累积尽可能的少。微软他们提出来的工作框架比较好,唯一的不好在于所有的工作都是拿已有的工作做的。这个是模板+生成的方式,这个是基于LSTM的序列标注模型,这个是符号化输出,这个是基于规则初始化的多层感知机,这个工作唯一的创新就是提出了强化学习的框架,但是里面任何的东西都是用的别人的。整合到一起也是不错的方式,第一次实现了除了模块内部是端到端可学习的过程之外,把若干个模块之间用强化模式串联起来了。
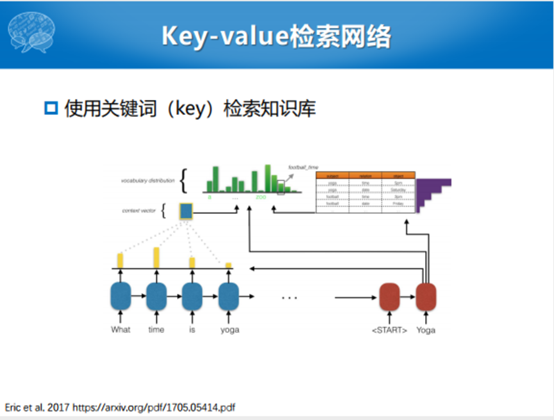
为了想做到完全的端到端,Eric和Manning提出了一个完整的端到端模型和相关的数据集。这种模型不把语义槽东西显式建模,把任务型拆成若干个单轮对话。问你一个问题回答一个槽,把整个过程当中一个一个离散化,变成了用Seq2Seq的模型一步一步的生成。生成过程之中会用注意力的机制,在解码过程中会选当前的输出。因为有一个数据库,这个数据可以认为是所有的任务型对话的数据,无论是状态还是取值的可能性,都包含在数据表达里面。解码的时候就想,解码这句话的时候究竟是从用户输入的词里面拷贝,还是在给定的候选的数据库里面揪一个词出来的过程。整个过程就变成了一个Seq2Seq的过程,生成的话还是像任务型的这种方式。

后续的能不能不采用这种方式去决策,每一个过程当中到底是拷贝值还是生成值。数据库里面的词是有限的,把那些词都拿出来,解码的过程中,每生成一个词看解码,是从正常的词表中做decoder,如果判断出来是在后面数据中的词做decoder,实际上就把整个任务型问用户槽的特征加入到了这样一个回复之中,也是关键词的方式进行的一个生成过程。
既然有若干个数据库里面的值,能不能采用一种更有意思的方式,先把用户输入表示成一个对话的状态。当然我们说这个里面可以考虑更长的上下文,整个任务型对话进行了10轮了,我们把10轮对话的历史表示成对话的状态,对话建模的过程可以用Seq2Seq的方式建模。表示成对话状态的分布之后,我们把可能用到的数据库里面的unit的值拿出来进行表示。表示成之后,进行一个联合的拼接,拼接了之后,加入了decoder的也包含了可能用到的数据库里面的Unit的值。利用检索的方式,结合Seq2Seq的方式建立多轮的对话。
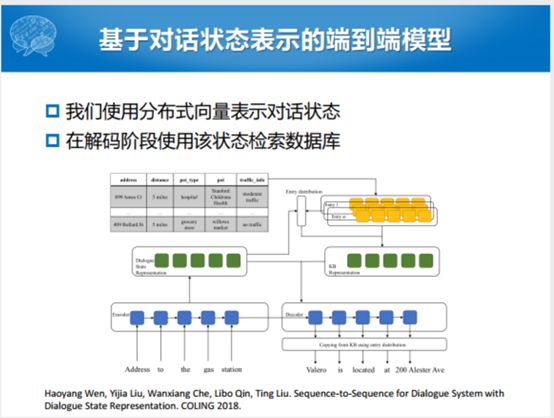
这个不足就在于可能对于检索回来的Unit的里面值,一个unit对应一个entry,有一个问题,解码出来的值。尽管对应的是这样的条目,但是我们解码中,因为我们是一个unit一个unit去建模的,因为建模了所有的unit,解码这个东西的时候,不一定真正的能把它拿出来,在解码具体值的时候,就用错相应的数据里面的值,对于我们生成的过程是有问题的。整个这个过程,我们在数据库或者Interpreter建模之下,我们加一个约束。只让它在确定的某一行之后,在这一行里面决定用哪一个Unit的值参与到解码过程之中。这个工作的模型图就是这样的。整个过程采用的训练方式就是知识库检索部分是采用无标注的训练数据,我们检索出来哪一个是知识库需要的数据不一定。采用两种训练的方式,第一种就是规则式的训练方式,用检索模型去检索,检索最多的,每一次检索的时候都有几列,如果整个队列出来比较多的列,我搜索十次有五次就对应到其中一个列,我们就认为这个列就是我们当前的Query对应的结果,通过这种方式就实现了无标注。除了这种方式之外,我们假如检索了10次,有5次就是同一个,那那个就是1,上面的就是0,这种1、0的这种方式就导致了训练过程中不可微的问题,比较简单的解决方法就是把1、0的方式进行建模。建模的方式就变成了5次是相应的过程定义成0.9,的剩下五次定义成0.002的方式,通过这种Gumbel-Softmax的方式进行连续化的表示,使之变成了可微的过程。通过这种方式,看到都能提升一定的效果,利用这个Gumbel-Softmax的方式会提升更高。
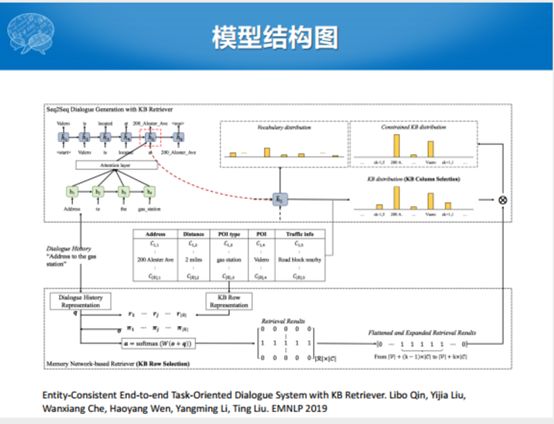
最后总结一下端到端任务型对话系统的状态。任务型对话系统整体的基本框架还是没有变。但是在端到端这块的努力,最有效的尝试就是在每一个过程当中用一个端到端的模型去训练,但是整体上面要么用Pipeline的方式,要么用强化学习串起来,每一个模块都进行统计化、学习化,模块之间的联系仍然存在而且必要。

任务型对话系统这么多模块,怎么去评价是另一方面。第一方面就是评价什么,这个任务型对话系统中哪些需要评价,其实每一个过程都需要评价。这里面就涉及到整体和部分之间评价的关系,整体上面其实我们也之前也说到了,整个任务型对话系统优化两个大的方向,一个是对话成功率,一个是平均对话轮数。其实整个过程之中,既然有这样优化的目标,相对来说就有一个这样的客观评价的指标。

这个就是我们对话奖励优化的目标和方向,这两个就是一个客观的指标。我们也说了更优的奖励函数是考虑到主观指标就是人的用户满意度,把用户满意度离散化,离散成若干值,这个用户满意度就是刚才所列的交互的质量,就是IQ的值。我们说用户满意度可以是一个连续值,也可以是一个离散的值,我们如果把它弄成离散的1-5的值,跟客观的指标有对应的关系,能够建立不同的用户满意度的不同的奖励函数。
介绍完整体的评价之后,介绍分布的评价,这个NLU就是为了得到语义帧,意图也有相应的识别,语义槽也有相应的识别,整体的评判可以在Frame Acc过程里面做。DM的过程,对话管理分成两个大的部分,一个是对话状态追踪,一个是对话策略优化,对话状态识别包括这个里面有主题的对话行为和对话类型的识别。对话策略优化,优化的还是两个部分,最终的对话成功率,因为没有单独的对话奖励函数的方向进行评价。

自然语言生成这块,就是NLG也有一定评价的方式。但是NLG看成语言模型的方式,评价指标可以采用语言模型的评价指标,这里面用的比较多的有几个统计的指标,包括字符串级别的,还有语义级别的。这个也有一个问题,这里面所有的字符串级别的评价指标是从机器翻译和文档文摘摘要借鉴过来的,是否适合对话生成这样的任务,我们值得商榷。当然也有人讨论过,如何不用这个评价指标来评价,他们觉得这些指标和人主观评价指标相关性比较差。更合理的方式就是用主观的方式叫几个人过来打分,这种方式比较费时费力,目前来说生成式的对话评价比较难,当然这一块也是持续可以做的方向。
最后我们给一些对话技术评测的介绍,每一个相应的评测都有相应的数据集,如果感兴趣的话可以下载这样的数据集做做这样的任务。
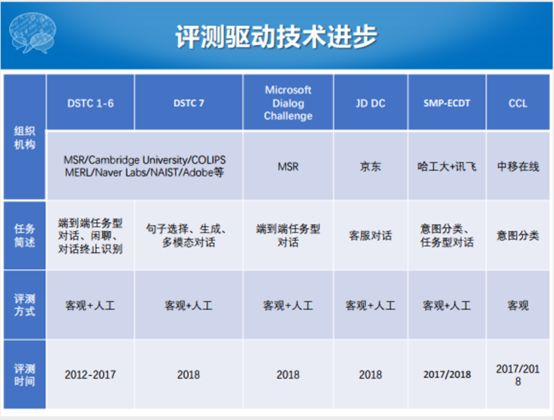
最后介绍一下我们中文人机对话技术评测,我们举办第三年了,联合了科大讯飞和华为。这里面有几个任务,每一年推出两个任务。第一个就是用户意图分类,对于一个对话系统或者任务型对话系统来说,不可能就处理一个领域的事,手机上的Siri可以让它查天气,可以搜索,还可以问有没有日历或者信息的需求。我们认为每一个东西都是一个Domain。Siri要做的第一件事就是我们要分到哪一个Domain去处理,如果查天气一定不能弄到定闹钟那里去,我们就想做这个任务。科大讯飞第一次给我们的数据,相对来说比较简单,我们有31个类。两个大类要么是聊天,要么是任务类。任务类下面细分为30个垂直领域,你给我讲一个笑话,还是讲一个故事都算是一个垂直的领域。实际上这个任务就是做31分类的任务。

第二个就是比较难,让你搭一个完整的对话系统。我们评测的过程都是由科大讯飞语音资源部的人员评测,真的是人工的评测,哪一个任务型对话系统比较好。然后我们给定了大概三个领域,机票、火车票和酒店。给它已有的讯飞的数据库,数据库里面包含很多酒店、机票和火车票的信息。评价的难点在于给定相同的输入的时候,即使是同一个人,跟不同的系统聊的时候,系统的反馈不一样,很难在两个对话片断上通过客观的方式上判断哪一个好,哪一个不好。只能使用人工评价,这就是用了大量的人力来做这个事,就是为了保证整个评测数据比较客观。

数据也是提供完整的用户意图,描述事例和静态的数据集、数据库。我们这里面也设置了最大的轮数50轮,即Nmax我们设置成50。对参赛队伍的容忍度还是很高的,一般都是设20,我们是设50。另外一个评价指标除了客观的对话轮数和完成度之外,我们还有四个指标。第一个指标是用户的满意度,还有一个是回复语言的自然度。另外我们问到了你这个数据库里面没有的值,或者没有的领域之后,你整个对话系统能不能够合理的引导或者拒绝我这个问题,这个也是一个评价的指标。
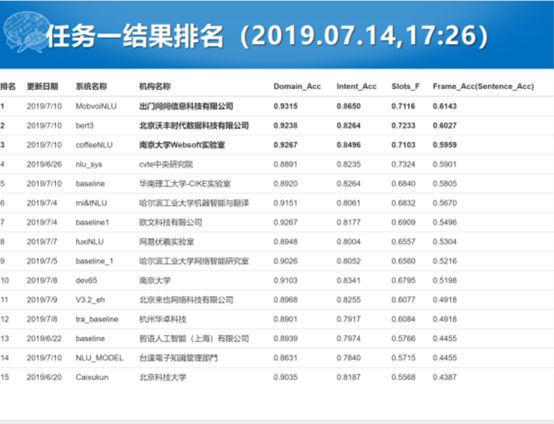
我们今年换了两个任务,提升了任务的难度,任务1不再是领域分类,而是要做领域、意图、语义槽的识别。这个特别难,跟我们以前说的任务1来说任务增加了很多的难度,我们评测的指标也比较严苛,要让这些全做对才叫对。最终我们看一下指标,出门问问在Domain上面刷了到了0.9分,全体的ACC能达到0.61,这个是整个参赛队伍整体的排名。
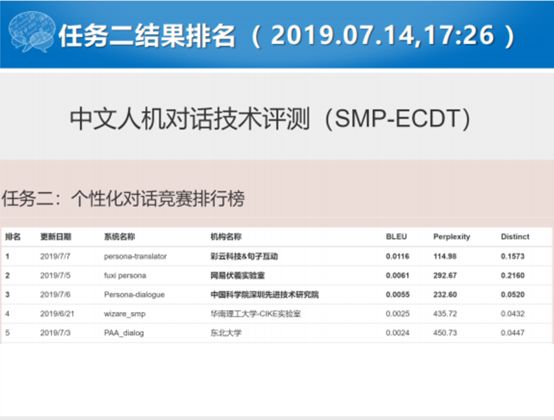
任务二是闲聊的项目,我们前两届都没有引入闲聊的项目。这届我们想能不能引入一个开放域对话的任务,这里面引入了一个个性化对话生成的任务。这个任务就是我们给定一个人与人之间对话的数据片断,给出两个用户,这两个人若干属性的属性值。你拿这个做一个训练数据,测试的时候给你一个属性的值的时候,你要能够生成和属性值不矛盾或者一致的对话。这就是考验对话系统,通过显式的对话的个性信息来建模生成符合属性信息对话的能力。这个也比较难,从头到尾大系统都比较难,最后成功提交有5家。
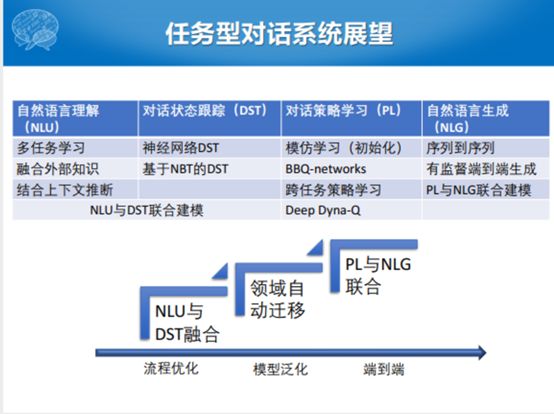
最后对我们今天讲的任务型对话做一个总结和展望可能的趋势。我们今天从自然语言理解讲到对话管理和对话状态追踪,也说到了多领域和多语言的趋势,这个也是特别重要的。我从对话策略开始讲,从规则到规划到概率再到神经网络的方式。我们也给了自然语言生成和端到端的进展,紧接着讲了评价的方式。最后我们给出一些展望,自然语言理解有多任务学习的方式,融合外部知识,知识的引入,另外还有就是结合上下文自然语言理解的推断。对话状态跟踪这一块都是神经网络的方式,但是除了单独的技术发展趋势之外,NLU和DST联合建模的时候也有。对话策略学习这块, BBQ-learning怎么采样,怎么更新的,用什么样的方式去做这个事情。除了本领域以外,一个Domain之内可以进行一个跨领域、跨任务的学习,包括策略学习和端到端自然语言的生成的结合。整个的发展趋势,从流程优化到模型泛化再到端到端是一个大的趋势,但是端到端不是那么自然的。先是NLU与DST的结合,然后是PL与NLG的联合。
没参与的小伙伴参与下,毕竟质量很高,希望中奖的是你们当中的一个!
可折现可邮寄!



