基于RASA的task-orient对话系统解析(一)
作者:邱震宇(华泰证券股份有限公司 算法工程师)
本文为授权转载,原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/75517803
由于换工作以及家里的事,很久没有写东西了。最近因为工作内容,需要做任务型对话系统的相关研究和开发。趁此机会,总结一下rasa框架的基本内容,包括基本架构,代码级别的分析,以及使用上的一些tips。需要注意,本文不会详细描述如何简单构建一个小demo的流程,这个在rasa的doc和一些博客上都有很好的例子,我这里就不重复引用了。贴一些链接,有兴趣的同学可以去这些地方看看。

备注:主要聚焦于非端到端的任务型对话系统开发。即将对话系统分为以下模块:
意图识别,槽填充,对话管理,response生成(即NLG)。
RASA简介
关于rasa本身,看了网上的一些博客,已经有不少同学写了相关的内容,因此这里就不做重复的叙述。
直接引用rasa在github上的叙述:Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
划重点:NLU, dialogue management
很明显,它能够提供对话系统中的两个核心模块:NLU和对话管理。
NLU:利用规则、机器学习,统计学习,深度学习等方法,对一条人类语言进行文本分析,分析得到的主要结果为意图intent以及实体entity信息。其中,意图对应task-orient对话系统中的intent。而实体信息则用于对话系统中的槽填充。
对话管理:在rasa中,对话管理的主要职责是通过NLU的分析得到的意图和实体信息,进行槽位填充,然后结合前几轮对话的状态,根据某种策略(策略可以是人工规则,或者机器学习,深度学习,强化学习训练得到的策略模型),决定应当如何对当前用户的对话进行回应。因此rasa的对话管理是包括槽填充的。
除了上述两个核心内容外,rasa当然还提供其他功能,如response生成,与其他对话系统前端平台对接的接口,以及不同类型的对话模拟接口(包括shell命令行模式,restful api调用模式等),对于从头开发一个对话系统来说,这个框架还是省去了不少基建的工作。
下面用一张图来表示rasa的整体流程:
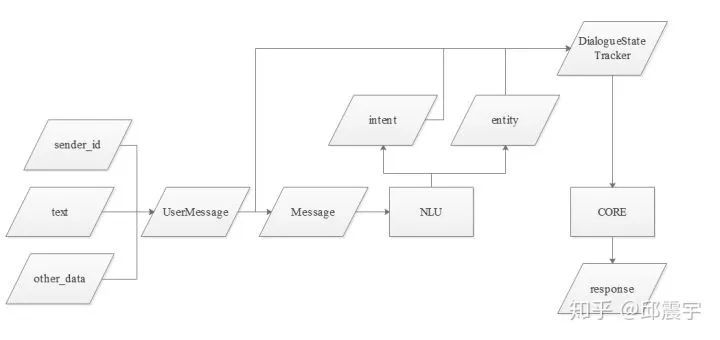
由图可知,当一条用户的表达到达chatbot时,由NLU对封装后的Message进行文本分析,得到意图和实体信息,然后由对话管理核心模块接受原始的用户消息和NLU的分析结果,根据一些策略,生成某个回复。
其中,本文聚焦于NLU模块,CORE模块放到下一篇来讲,包括CORE的状态记录对象tracker以及封装的UserMessage.
RASA整体架构
首先,看一下rasa框架的代码结构。如图所示:
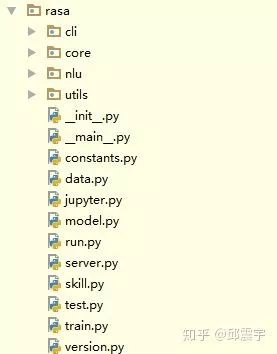
本文涉及的rasa版本是1.1.8,当前rasa在pip上的版本为1.2.5,版本间代码有轻微变动,不过与0.1.X版本相比,代码结构有很大不同,将之前的rasa_core和rasa_nlu合并到了rasa的主路径下,作为core和nlu的子package。这两个包对应的就是rasa的核心功能NLU和对话管理的模块。下面分别对这两个模块的代码内容做一个结构上的解析。
NLU模块
在看代码之前,需要先介绍几个NLU模块里面的一些概念术语以及不同概念之间的关联关系,明确了这个之后,看代码就比较清晰了。
component:在我们做任何自然语言处理的任务时,不止是用单纯模型去做一些分类或者标注任务,在此之前,有相当一部分工作是对文本做一些预处理工作,包括但不限于:分词(尤其是中文文本),词性标注,特征提取(传统ML或者统计型方法),词库构建等等。在rasa中,这些不同的预处理工作以及后续的意图分类和实体识别都是通过单独的组件来完成,因此component在NLU中承担着完成NLU不同阶段任务的责任。component类型大致有以下几种:tokenizer,featurizer,extractor,classifier。当然还有emulators,这个主要用于进行对话仿真测试,我目前还没使用过,就不多描述这个组件了。
pipeline:有了组件之后,如何将组件按部就班,井然有序地拼装起来,并正常工作呢?因此就有了pipeline这个概念,其实在机器学习领域,pipeline这个概念已经存在很长时间了,它在很多框架中都有,比如大名鼎鼎的sklearn。使用pipeline的好处在于可以合理有序管理不同任务阶段的不同组件工具,当组件数量较多时,pipeline的好处就非常明显了。而在rasa中,pipeline的使用更为便捷,是通过yml配置文件实现。即开发者只需要定义好自己的组件,然后将组件配置在配置文件中就可以,即插即用。下图是一个简单的pipeline配置实例:
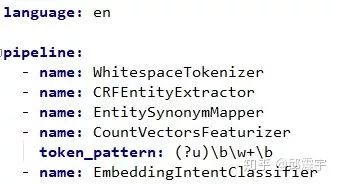
tips1:这里注意一点,配置的组件名称name对应的是组件类的类名。而后面跟着的key-value键值对,对应的是组件类需要传入的初始的参数。
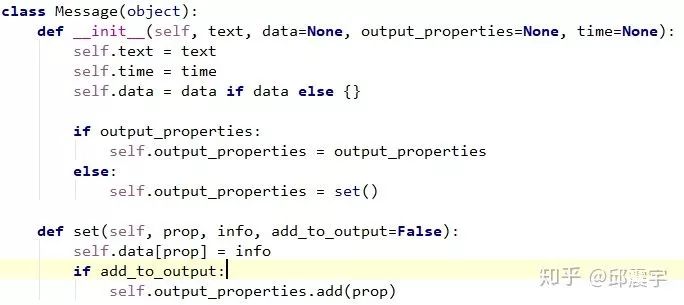
message:在rasa中,用户发送到chatbot的所有对话内容,都需要被封装在一个对象中,这个对象就是Message.而在整个rasa工作流中,存在两个不同的message封装对象,一个是UserMessage,另一个是Message。其中UserMessage是最上层的封装对象,即直接接收用户从某个平台接口传送过来的消息。而Message则是当用户消息流到NLU模块时,将用户消息进行封装。关于UserMessage的内容在后面代码详解时会涉及到,这里先解释一下Message对象。看一下它的类部分定义,其实很简单,就是将用户的对话文本,以及时间进行封装,由于这个Message是贯穿整个NLU工作流的统一数据对象,因此还承载着记忆各个组件临时生成的中间结果(比如分词和词性标注的结果)以及最终得到的意图和实体信息。其中data存放的是意图和实体信息,在后续组件处理时,还会再Message中增加一些变量存储中间结果,即set成员方法的职责。
对上面三个概念明确以后,下面列出不同组件的代码结构:
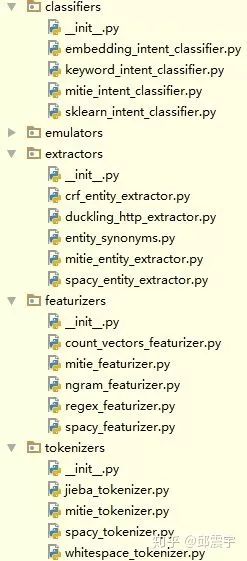
在rasa中,已经预置了一些组件,方便用户直接使用。当然有些组件是需要先进行训练,得到模型后,才能使用,而有些则是使用正则表达式或者关键词等规则,直接就可以使用。
以CRFEntityExtractor为例,讲解一下Component的主要核心要素。

首先看到,该类继承了一个EntityExtractor,这是一个二级组件抽象类(我自己定义的说法),这个二层抽象类继承自Component这个一级抽象类。因为不同组件承担的任务不同,有些组件任务比较单一,可以直接继承Component比如tokenizer,classifier,而有些组件的任务比较复杂,则需要制定这一类型的二级接口,方便扩展,如featurizer,extractor。
其次,每个component需要定义一个类变量provides和requires,分别表示这个组件所提供的中间成果和依赖的上游任务。对于CRFEntityExtractor来说,它提供了实体的抽取,同时为了进行实体抽取,需要先对文本进行分词,因此需要上游任务先完成tokenizer任务,提供tokens的中间成果。
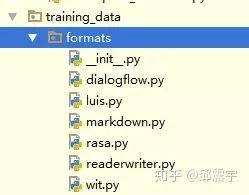
train方法。既然是使用条件随机场来进行实体抽取,那么就需要进行模型训练。因此需要定义train方法,来训练模型。关注train方法的两个参数training_data和config。其中,config就是之前提到的配置pipeline的配置文件的读取对象。training_data是TrainingData类型的对象。你可以将其类比于pytorch中的data_loader功能,它的主要作用是对训练数据进行封装,拆分训练集验证集,做数据校验等工作。说到这里,提一下rasa支持的原始训练数据的存放格式,主要支持markdown,wit,luis等文件格式,当然也可以提供json格式的数据。rasa如何读取这些格式的训练数据则是在如下代码包里定义:

persist和load方法。当模型训练完成后,需要保存和加载模型,对生产环境上的实时业务流进行处理,因此需要定义persist和load方法加载模型。
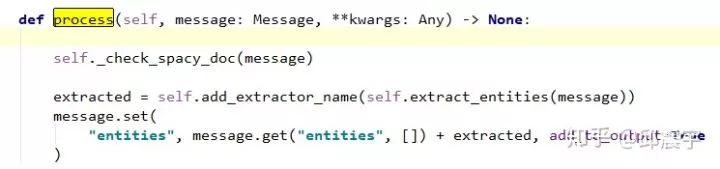
process方法。这个可以说是组件里面最重要的一个方法。当前面一通操作之后,只得到了模型,如何调用这个模型并处理文本,就是process方法的工作了。最后在message中增加一个dict,名为entities,用来存放提取的实体信息,包括实体的类型,实体的在文本中的start和end的位置信息等。
tips2:对于对话中,涉及到的所有intent和实体,均需要在配置文件中进行定义,方便各个组件在做相应的文本分析时进行lookup-table查找。这个配置文件叫domain.yml,一个简单的实例如下:

tips3:这里说一个实用技巧。在实际的对话场景中,用户的一个utterance(表达)通常会带有不止一个意图,有的人会将这种情况当做一个复合型单意图,将其添加到domain配置文件中。但是实际上大可以不必这么麻烦,此时相当于从一个意图多分类问题,转变为一个意图多标签分类问题,即每条数据可能不止一个标签,此时只需要将模型的最后一层softmax层,替换为n个sigmoid分类器就可以。在训练数据中,我则需要配置这种训练数据,将多个意图使用某个符号"+"或者"_"等进行字符串拼接。在classifier中进行处理。这样就无需在domain配置文件中配置诸如inform_affirm这样冗余的意图了。
rasa中已经集成了许多有用的组件,可以看到针对中文文本,有jieba分词,另外还有专门对时间信息进行提取的组件ducklingHTTPExctractor,要使用这些组件都需要安装相应的依赖包。如果上述组件不能够满足业务需求,则开发者可以自己定义所需的组件,定义的组件的最低要求就是实现我上述讲的那些要素(不需要训练模型的可以不实现train方法)。

