基于RASA的task-orient对话系统解析(三)——基于rasa的会议室预定对话系统实例
作者:邱震宇(华泰证券股份有限公司 算法工程师)
知乎专栏:我的ai之路
本文为授权转载,原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/81430436
本文是解析rasa框架系列的第三篇,前面两篇分别从总体架构、NLU模块、对话管理模块等维度对rasa框架的内部机理和代码模块做了解析。本文从实际项目的角度,以会议室预订为目标场景,分享如何使用rasa框架定制一个特定场景的任务型对话系统。主要内容包含:设计会议预定的话术场景和对话系统需要具备的功能;使用rasa构建会议预订系统的整个流程。
备注1:由于设计到内部项目的细节隐私,不会讲的太细,但是会把大致的思想流程分享出来。另外,本文中的一些流程或者设计也不一定是对的,只是本人的一点实践经验,如果有更好的想法, 非常非常欢迎给出建议。
备注2:本系统不是data-driven,因为做该场景的时候,是零数据。所以只能用rule-based的方法来做对话管理。当然NLU部分还是会用到一些NLU模型。
会议预订系统设计
说是系统设计,其实主要是设计会议预订的话术场景。什么叫话术场景?即用户如何通过多轮对话、每一轮通过什么样的问法、机器在每一轮对话中如何回应用户并引导用户给出关键信息、最终完成一个会议室预订流程的各种不同场景。这里举个简单的例子来说明一下:
user:帮我订明天上午9点的会议室
bot:请问预计的会议时长是多长呢?
user:大概两个小时左右吧,大概有10个人参加
bot:请问您有期望的会议室地点吗?
user:最好在XXX地点
bot:当前推荐您预订如下会议室:XXX时间-XXX时间,XX地点,XX会议室,是否确认?
user:en
bot:已为您成功预订该会议室,请准时参会。
上述例子只是众多话术场景中的一个。虽然会议室预订场景相对比较简单,但是由于牵扯到多个槽位属性,槽位之间也存在关联关系,同时对话系统需要支持多轮对话,因此工作量也是不小的。
在实践中,我将话术场景设计分为如下几个子任务,分别是:
意图设计
槽位设计
NLU模块设计
对话策略设计
话术模板设计
意图设计
这里的意图跟大多数讲对话系统中的意图不太一样。因为如果按照传统对话系统中的意图概念来设计,该系统实际上就只有一个意图,即预订会议室。实际上,本系统中的意图更精细化。例如表达肯定的意图confirm、表达否定的意图negative,用户给出时间属性的预订意图booking_time等等。为什么要设计如此细粒度的意图呢?原因有两点:
因为是rule-based,因此做对话管理和对话策略时,要考虑与用户的交互。在很多实际场景下,通常会由bot来主导对话的进行。比如上面的例子中,为用户推荐了一个会议室后,需要用户给出一个confirm或者negative的意图,以便让bot来决定是否预订会议室。
在之前的文章中,已经解析过rasa中的action和policy的内容。实际上,action是被动触发的,因此需要用户提供触发意图(如给出时间属性的预订意图)来唤醒一个action。
具体设计的意图本文不会全部列出,仅给出意图设计的一些范式。
1、预订会议室意图。这里除了仅仅给出预订会议室的意图之外,还需要考虑用户带其他属性的复合意图。如给出时间的预订意图,给出地点的预订意图,同时给出时间和地点的预订意图。这些意图除了本身的涵义不同以外,还牵扯到不同槽位的预填充。关于槽位的预填充在后面的rasa环节会具体说明。
2、用户的回应意图。包括表达肯定的意图,否定的意图,或者无所谓的意图,强制退出的意图等等。
槽位设计
会议预订的流程逻辑比较简单,因此槽位的设计也很直观。主要包括时间,地点,会议人数。
时间槽位主要包括起始时间,结束时间,时长。
地点槽位根据我们实际的场地需求来订,这里就不具体列出了。
除此之外,还需要额外的槽位信息,包括用户id,当前的会话id,会议预订状态,会议预订流程开始时间等。这些额外槽位设计的原因是为了做系统的会话管理和会话跟踪记录。(这里的会话不是对话系统中的会话,有点像http的会话管理。)具体的内容在后续章节会详细解析。
关于后续槽位的填充,主要还是根据用户提供的文本信息,抽取其中的属性来填充。在此之上,还需要补充一些人工规则,对有复杂逻辑的槽位进行填充。这些操作都是在下面要介绍的NLU模块中完成。
NLU模块设计
在rasa系列的第一篇文章中已经对rasa的NLU模块进行了解析。rasa可以很方便得集成不同类型的NLU组件,提供实体抽取功能。因为之前有同事已经有开发过成熟的实体识别工具,所以我就直接将该工具集成到了rasa_nlu中。在不做任何改动的情况,我已经可以对一些简单的时间,地点进行属性抽取,例如日期+时间点,会议城市、楼栋等。同时为了适配会议预定的场景,还做了一些小的改动。
例如:用户输入了明天九点的会议室,大概有两个小时。此时,实体识别工具能够提取出会议的起始时间和会议时长两个属性值。但是在调用会议查询和会议预定接口(这两个接口都是现成的)时,需要会议的起始时间。因此,需要通过一些简单的逻辑计算,由起始时间和会议时长,得到会议结束时间的属性值。
再举个例子:用户输入了订明天一上午的会议室,此时实体识别工具能够识别"明天一上午"的时间属性,但是无法得到具体的起始和结束时间和会议时长槽位。此时需要使用一些规则去匹配这样的说法,并转换为最终的起始时间槽位09:00:00,结束时间槽位12:00:00,会议时长槽位3小时。
上面主要是介绍了时间方面的属性提取。关于地点的属性提取,由于牵扯到公司的具体的办公驻地名称,因此需要增加人工规则,将驻地名称添加到实体识别的处理流程中。这里再一次证明了单纯使用data-driven的模型是无法cover所有的实际使用场景,必须要结合一定的人工规则,才能保证最大的场景覆盖率。
对话策略设计
由于当前没有任何对话的数据,所以无法做data-driven的对话策略,因此只能选择使用rule-based的方法。这里就选择了在上一篇文章中提到的formPolicy策略。它有一个对应的action:form。作为整个对话策略的核心,有必要额外用一点篇幅来解析一下这个form。
当form的action被触发时,对话会自动进入form的执行流程。在每一轮对话时,当用户向bot发送一条消息时,会调用form的run方法,执行一些操作。下面贴出run方法的主要代码:
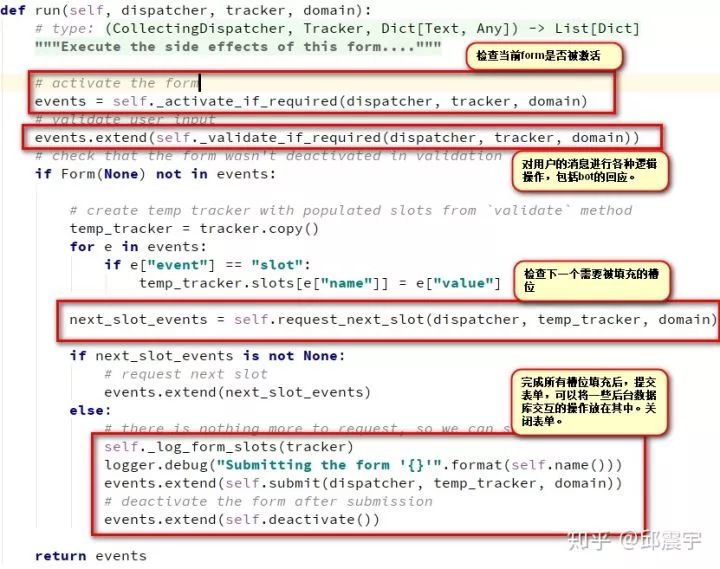
如图所示,run方法基本包含了一个单轮对话中的所有bot的逻辑操作。其中,dispatcher,tracker,domain等对话概念在上一篇文章中都已经解析过。这里我要重点提一下validate_if_required方法。该方法的主要内容如下:
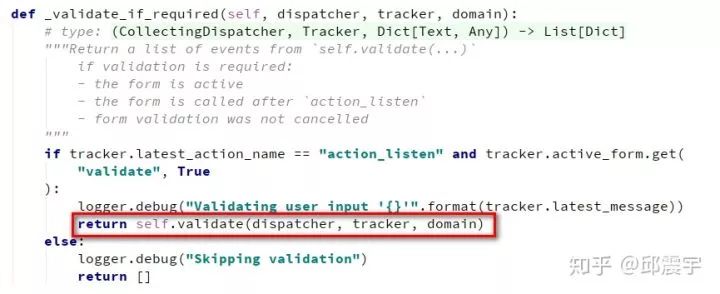
重点看一下红框标出来的地方。这里调用了一个validate方法。在实际项目中,主要是重写这个方法处理用户发送的信息文本以及执行其他比较复杂的操作,其大致的流程如下:
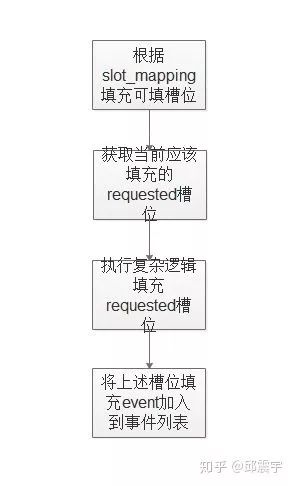
首先解释一下slot_mapping。为了简化槽位填充逻辑,在一些简单场景下,可以利用NLU模块提取出来的实体,直接映射到某个槽位的值,或者甚至可以直接将用户发送的纯文本作为值填充到槽位中。
例如:用户输入了明天九点到11点的会议室。这是NLU模块识别出了这是一个时间段,同时开始时间为:XXXX-XX-XX 09:00:00,结束时间为:XXXX-XX-XX 11:00:00,且会议时长为2小时。此时这三个属性就分别对应了起始时间,终止时间,会议时长三个槽位。在slot_mapping的类方法中将该三个属性与对应的三个时间槽位进行字典映射,就可以达到目的。
当然,单独使用formPolicy策略是不够的。不知道大家注意到没有,我多次提到了唤醒一个action或者关闭一个action的操作,这个操作在rasa中是如何完成的呢?答案是借助其他策略。在rasa中预置了一种策略叫MemoizationPolicy。这个策略的主要功能是从用户配置的话术模板库中读取用户预定义的话术流程模板,当用户输入的文本包含的意图或者意图与实体的集合匹配了某个话术流程时,则该策略会根据传入的最大对话轮数参数装载固定历史轮数的话术流程。我们可以在话术流程模板中定义当用户发送什么样的消息时会触发form的action,以及定义当form action被关闭后应该执行什么样的action。当然还有一种策略也能在一定程度上实现上述功能,这个策略叫MappingPolicy,它的主要思想是用户直接配置用何种intent来触发对应的action,需要在domain.yml中配置。但是该策略不是很灵活,因此我也没有使用,有兴趣的同学可以自己去尝试一下。
基于上述的原因,在使用formPolicy之外,还需要用到包括MemoizationPolicy等其他策略。有关于话术流程模板的设计将在下一小节详细说明。这里要先说下多策略集成的问题。
在前一篇介绍rasa对话管理的内容时,提到了可以使用多个策略的组合来完成对话任务。这里补充一下,rasa是通过PolicyEnsemble策略来实现多个策略的集成。有两种实现集成机制的方法:
使用机器学习中的模型集成。这个方法,如果大家做过数据竞赛,应该比较熟悉。rasa支持sklearn,tensorflow以及rasa本身的策略集成训练。
简单集成方法,即根据策略预测的下个action的概率置信度来选择。置信度就是每个策略在预测下个action的概率时的可靠程度,置信度越高,说明可靠程度越高。一般基于规则的策略的置信度都是比较高的。这个是比较简单粗暴的方法,在没有数据、场景比较单一的时候还是比较适合的。
使用简单集成方法的方式很简单,直接在config.yml中将需要使用的所有policy名称进行配置应用就可以了。
话术模板设计
本小节就上一章节提到的话术流程模板内容,给出详细的介绍。在rasa中,有一个概念叫story。我们可以将某个场景下的一些对话流程通过模板的形式配置在story中,一个story对应一个完整的对话流程,包括对话如何开始,中间如何处理以及最后如何结束。在rasa中,我理解它有两个作用:
用于data-driven模型的对话模型训练。
为MappingPolicy策略提供话术模板。
这里,我们重点关注第二个方面。上面说到MappingPolicy策略可以帮助我们去定义何时触发一个form,以及当form结束时如何进行下面的流程。这里给出一个实例。

其中*号表示为用户的意图,以-为开头的表示bot执行的action。上述story中,用户通过简单的会议预定意图激活了form的action:meeting_form。当form执行完成后,将form的名称置为null,表示关闭该form。然后bot执行操作utter_goodbye(这是一个话术模板例子,前一篇文章中介绍过,它也代表一个简单的action)。最后需要将整个会话状态重置,等待下一次该用户的唤醒。
当然,用户除了简单说出会议预定的意图外,还会有其他更复杂的意图场景。例如指定了会议开始时间的会议预定、指定会议时长的会议预定、指定会议地点的会议预定等,甚至是上述场景的组合。下面给出这种话术流程的实例:
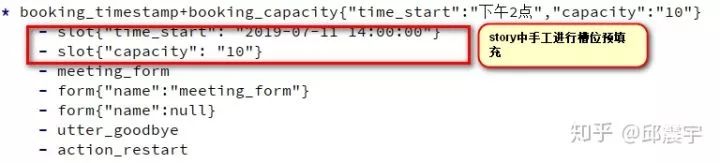
可以看到除去开头略微复杂了一些,大部分的流程还是与上面的类似。首先是使用了booking_timestamp和booking_capacity的组合意图,rasa支持通过形如"+"或者其他符号进行组合的方式配置组合意图,这样就能大大减少意图的冗余配置。另外,意图中还附带了可填充的槽位值,可以通过上述方式在进入form之前将部分槽位预先进行填充。
那么如何设计上述的对话流程呢?具体内容就不多说了,这里就简单说一下大致的模式:
对于会议室预定流程来说,要将用户可能的话术都要考虑进去。首先要能识别用户的复杂意图,包括是否带时间、地点、人数等其他会议属性,其次要将每个意图可能附带的可填充槽位进行填充。最后按照整个对话的逻辑流程,按部就班将对话一轮一轮配置下来。
rasa构建系统
在对话场景设计完后,就可以基于rasa构建对话系统了。下面就简单罗列一下使用rasa构建的大致流程:
编写配置domain.yml文件,配置内容包括:设计的槽位,NLU需要识别的实体列表、意图列表,bot回复用户的模板,配置可在story中直接引用的action,配置自定义的form。
编写配置config.yml文件,配置内容包括:使用的NLU模块类(实体抽取、意图识别等),使用的策略列表。
编写stories.md文件,设计话术流程模板。
开发自定义的NLU模块,根据实际需要添加所需的模块。我在做会议预定时,只添加了extractor和classifier模块,分别对应实体抽取和意图识别两个模块,可以结合人工规则和机器学习模型。
开发自定的form action模块,在validate中定义自己的处理逻辑。当然也可以重写action的run方法,在其中添加自己的逻辑。
配置endpoints.yml文件,这个文件是用于配置action服务地址的。因为之前说过action是一个独立于主流程的服务,因此需要配置其服务接口。
配置credentials.yml文件,因为我是将会议预定作为一个独立开放的api服务提供给业务方,而rasa支持将对话系统封装成一个restful_api服务。另外提一句,rasa使用的是sanic的异步web框架。因为对话系统是一个多用户的异步服务,所以需要支持多个用户的同时使用。它本身也具有会话管理的功能,但是对于我这个项目场景来说不太足够,因此我自己实现了一个简单的会话管理功能。具体内容将在下一小节中说明。
要构建一个完整的对话系统,除了上述流程外,还需要考虑更多功能。这里我重点说两个方面:用户验证和会话管理。
用户验证
会议预定系统是公司内部的一个OA子系统,需要跟员工的工号绑定,同时进行验证。因此在做会议预定的对话系统时需要考虑到这一点。rasa是支持配置用户验证功能的,使用的是基于JWT的用户权限验证功能。在实际项目中,由于我的上层调用方已经实现了用户验证,为了提升我进行会议查询和预定的调用效率,不需要再rasa端配置用户权限,直接接收上层下发的用户消息就可以了。
会话管理
会话管理也是一个对话系统必须具备的功能。在实际项目过程中,主要集中在会话的超时管理以及会话数据的跟踪记录两个方面。
首先是会话的超时管理功能。如果用户在会议预定过程中,有一段时间没有做任何操作(可能是忘了,也可能改主意不再继续流程),这时应当设置一个超时机制,将会话状态重置。rasa本身不具备这个功能,需要自己去实现。我的实现方案是将会话的起始时间作为槽位。每次会议预定流程开始的时候,会计算当前的时间并将其填充到槽位中。每一轮对话开始时,会将该会话开始时间槽位值与当前时间比较,若超过预设的值,则判为超时,重置整个对话状态。
另一个会话数据的跟踪记录,主要是将会话的所有信息入库保存,一方面可以用于debug会话系统,另一方面也可以在系统实际投入使用时积累数据,用于后续的模型训练用。
具体如何实现上述功能呢?有两种方法:
1、使用rasa本身的内置组件。前两篇文章中,介绍过tracker这个概念。在rasa中还有一个组件模块叫tracker_store。顾名思义,就是tracker的序列化工具。它支持多种方式存储对话状态信息。例如内存存储;redis存储;非关系型数据库存储;关系型数据库存储等等。它存储的信息也比较全,如果没有特殊需求的话,还是不错的选择。这里贴一个关系型数据库存储的字段示例:
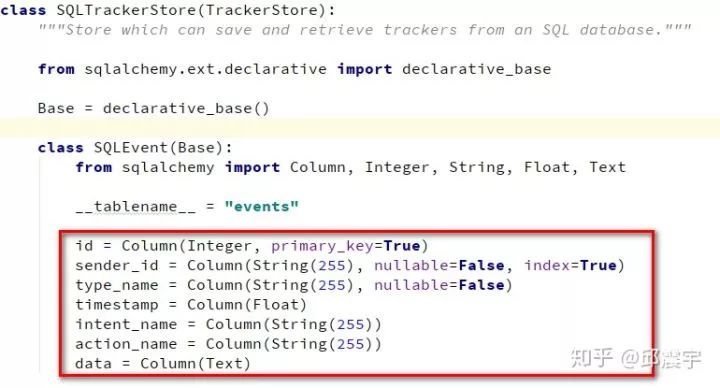
2、自己实现会话数据存储。rasa内置的对话数据存储有时候并不能满足我们的需求,如它并不会去获取会话id等信息来存储。此时,就需要自己实现该功能。具体的操作其实也很简单,就是将所有对话的信息在每一轮对话结束后保存到一个字典中,然后使用统一的数据库接口入库,需要注意的一点是入库操作最好在action的run方法的最后执行,防止遗漏一些信息。
总结
本文以实际的会议预定场景为基础,结合了本人在实际项目中的经验,详细介绍了如何从头到尾设计并开发一个具体场景下的任务型对话系统。本人内容大多是个人的实际经验,希望能为其他同学在做相关的项目时带来一些启发。当然,由于能力有限,上述所有的流程思想可能存在错误或者不合理的地方,如果有更好的想法,欢迎随时来讨论。
关于rasa系列,目前计划就暂时写到这,后续如果有其他的新的使用心得,会以番外篇的形式呈现。欢迎大家阅读与指正。
相关文章:

