每日论文 | Jeff Dean本科论文曝光;用遍布式注意力机制进行预测;文本摘要新方式出炉
Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-Sequence Prediction
目前先进的机器翻译系统都是基于解码编码器网络的,即首先对输入序列进行编码,然后生成一个输出序列。它们都通过注意力机制连接,并基于解码器状态对固定的编码源tokens重组。对此,我们提出了一种替代式方法,网络的每个图层都会根据已经生成的输出序列重新编码源tokens,所以网络中遍布注意力机制类型的结构,结果非常不错,并且使用的参数也更少更简洁。
地址:https://arxiv.org/abs/1808.03867
Improving Abstraction in Text Summarization
对抽象的文本进行总结,关键是将长文本缩短,但仍包含有用的信息。但是,现有的方法仍不能用文本中未出现过的新颖短语进行表达。我们提出了两种方法提高生成摘要的水平。首先,我们拆分了从源文本中寻找相关部分的语境网络解码器,之后与训练了可以将先验知识加入到语言生成中的模型。之后,我们提出了一种新的衡量标准,鼓励模型生成新表述。
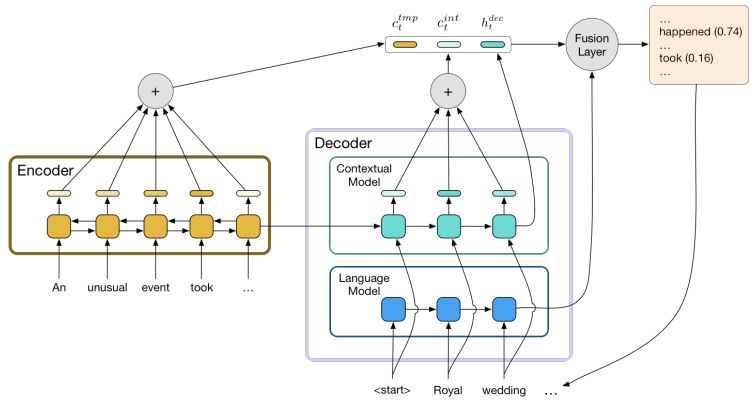
地址:https://arxiv.org/abs/1808.07913
Parallel Implementations of Neural Network Training:Two Back-Propagation Approaches
本文是谷歌大脑的掌门人Jeff Dean大四时写的论文,主要研究了用C对神经网络进行平行训练。其中第一种方法是模式分区方法,在这种方法中,每个处理器都会呈现出这个网络。第二种方法是在可用处理器之间,对神经网络的神经元进行分类。

地址:https://drive.google.com/file/d/1I1fs4sczbCaACzA9XwxR3DiuXVtqmejL/view






