46.1 mAP!MimicDet:缩小一阶段和两阶段目标检测之间的差距 | ECCV 2020
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI深度学习视线
这是一种通过直接模仿两阶段特征来训练一阶段检测器的新颖高效框架,旨在缩小一阶段和两阶段检测器之间的精度差距。在COCO上,基于ResNeXt-101可达46.1 mAP!
paper:
https://arxiv.org/abs/2009.11528
作者单位:商汤科技, 香港中文大学
1
摘要

2
本文思路
在本文中,我们提出了一个新的训练框架MimicDet,它可以有效地缩小一级和二级检测器之间的精度差距。
2.1 MimicDet思路
具体来说,网络在训练过程中既包含一段检测头,也包含两段检测头。
两阶段检测头
称为T-head (teacher head),是一个具有大量参数的网络分支,目的是为稀疏采样的建议盒提取高质量的特征。
一级检测头
称为S-head (student head),用于检测所有密集anchor-box的轻型分支。
由于原始的教师和学生网络是异构的,他们的特征地图有空间错位。为了解决这一问题,我们利用了引导可变形conv层,其中每个卷积核可以有一个由轻量级神经网络计算的偏移量。变形偏移量可以通过模拟T-head生成的位置一致性特征来优化。通过特征匹配,优化特征对的相似度损失和MimicDet中的检测损失。因此,s形头的特征可以从t形头的特征中得到更好的性质。
在推理过程中,丢弃t头,即采用纯单级检测器进行目标检测。该机制保证了MimicDet继承了两种体系结构的高效率和高精度。与传统的对象检测模拟方法不同,在MimicDet中,教师和学生共享同一骨干,模拟对象是在不同的检测头之间,而不是在不同的骨干之间。因此,它不需要预先培训一个教师模型,也不需要一个更强的骨干模型来充当教师。这些特性使得MimicDet效率更高,并且可以扩展到更大的模型中。
2.2 性能提升方案
为了进一步提高MimicDet的性能,还提出了几种专门的设计方案。
设计分解后的检测头,分别在分类分支和回归分支上进行模拟。分解后的双路径模拟dual-path mimicking使T-head更容易获得有用的信息。
此外,我们提出了交错特征金字塔staggered feature pyramid,从中提取一对不同分辨率的特征。对于每个anchor-box,分别从特征金字塔的不同层次获得T-head的高分辨率特征和S-head的低分辨率特征。从而使MimicDet在不增加计算成本的情况下,更能获得t形头的高精度和s形头的高效率。
3
MimicDet 架构
MimicDet的概述如图1所示。在推理阶段,MimicDet由主干、 refinement
模块和一级检测头S-head组成。在训练阶段,我们增加了一个两阶段的检测头作为Teacher,称为T-Head,来指导S-Head,提高其性能。我们将在接下来的部分详述每一个组成部分。
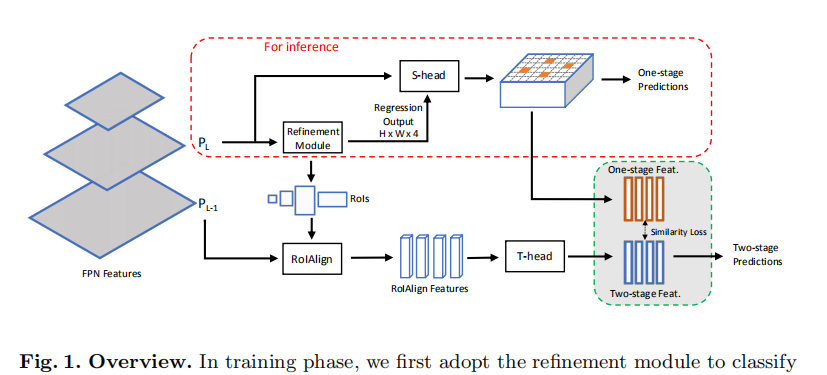
3.1 Backbone and Staggered Feature Pyramid
具体来说,P6在C5上采用3×3 stride-2卷积生成,P7在P6上采用ReLU后加3×3 stride-2 conv计算。所有特征金字塔的通道数为256。在主干中有一个微妙但至关重要的修改,就是我们在训练阶段保持从P2到P7的金字塔特征,而不是P3到P7。然后我们将这些特征分组为{P2, P3, P4, P5, P6}和{P3, P4, P5, P6, P7}两组,构建交错特征金字塔。T-head使用的是前者的高分辨率特征集,而后者的低分辨率特征集用于Shead和细化模块。这种布置满足了单级水头和两级水头的不同需要。对于one-stage的MimicDet中的头,效率是最重要的,而在two-stage中作为教师模型的检测精度则更为关键。低分辨率特征使T-head检测更快,高分辨率特征使T-head检测更准确。
在推断阶段,引入交错特征金字塔是没有成本的,因为我们只使用低分辨率的特征金字塔,并没有生成P2以提高效率。
3.2 Refinement Module
我们在特征金字塔P3到P7上分别定义了从32^2到512^2的锚。 不同于以往在feature map的某个位置定义多个锚点,我们在1:1的长宽比下,每个位置只定义一个锚点。 采用这种稀疏的锚点设置来避免特征共享,因为one-stage头中的每个锚点盒都需要有一个专属的、明确的特征来进行头的模拟。
与传统的基于RoI的定位策略相比,Refinement模块中anchor-box的稀疏性更强,因此Refinement模块中anchor-box的标签分配与传统的基于RoI的定位策略不同。 我们根据物体的尺度将它们分配到P3到P7的特征金字塔中,每个特征金字塔学习在特定尺度范围内检测物体。 具体来说,对于pyramid Pl,目标对象的有效标度范围计算为[Sl×n1, Sl×n2],其中Sl为级别l的基本标度,设置该系统来控制有效标度范围。我们实证设定Sl = 4×2^l, n1 = 1, n2 = 2。 任何小于S3 *n1或大于S7 *n2的对象将分别分配给P3或P7。
3.3 Detection Heads
T-head
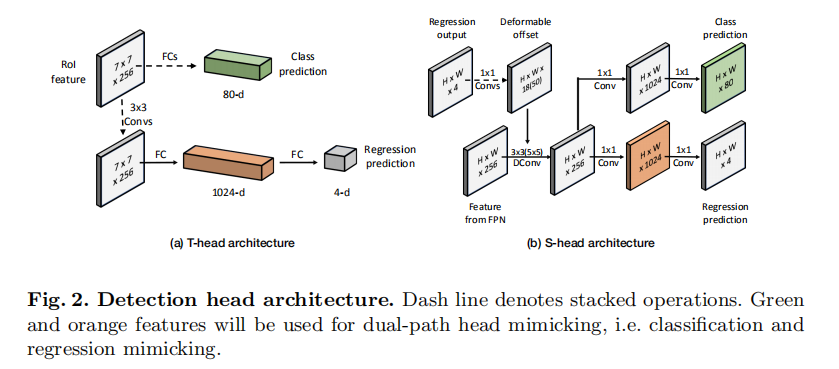
如图1所示,交错特征金字塔高分辨率集合的T-head访问特征,即比原始特征提前一层。首先采用RoIAlign操作,为每个锚框生成7×7分辨率的位置敏感特征。然后将T-head分成两个分支进行分类和回归。
在分类分支中,每个锚盒的特征分别用两个1024-d fc层处理,然后用一个81-d fc层和一个softmax层预测分类概率。
在另一个分支中,我们采用4个连续的3×3对256个输出通道,然后将特征平化成一个向量。
接下来,平化特征将通过两个fc层依次转化为1024-d回归特征和4-d输出。如图2所示,在训练S-head时,以81-d的分类logits和1024-d的回归特征作为模拟目标。标签的分配基于阈值为0.6的IoU标准。分别利用交叉熵损失和L1损失对分类和回归分支进行优化。
S-head
S-head是一种不采样直接对特征金字塔顶部进行密集检测的one-stage检测头。我们将S-head设计成一个轻量级的网络,可以克服特征不对称,并学习通过模仿T-head来提取高质量的特征。
如前所述,引入Refinement模块将破坏锚框与其相应特性之间的位置一致性。位置不一致会导致S-head和T-head表示面积的差异,不利于头部的模拟。因此我们使用可变形卷积来捕获不对齐的特征。变形量由微网络计算,微网络将细化模块的回归输出作为输入。
S-head的架构如图2所示。微网络由三个1×1对流和64、128个中间通道组成。然后使用一个5×5可变形的256通道conv和两个sibling 1×1 convs提取1024-d特征用于分类和回归分支。然后用两个单独的1×1 convs来生成预测。为了进一步减少计算量,我们在最高分辨率P3中将5×5变形conv替换为3×3变形conv。为了语义一致性,保持T-head的标签分配策略和丢失函数不变。
在实验中我们发现,尽管Refinement模块已经剔除了一些容易的负样本,但特定类的正样本比例过低。为了解决这一问题,采用了硬负挖掘来缓解类不平衡问题,即在S-head中,总是选取顶端分类损失的box样本来优化分类损失。
3.4 Detection Heads
我们用Bs表示Refinement模块调整的所有锚盒的集合,Bt表示T-head采样的Bs的稀疏子集。基于Bt,我们将Bm定义为用于优化模拟损失的随机采样子集。给定Bm,通过对其应用T-head,可以得到对应的两阶段分级特征集F_tc和回归特征集F_tr。同样,也可以得到Bm在S-head中的分类回归特征,分别表示为F_sc和F_sr。具体来说,在S-head中,其输出特征图的每个像素对应于Bs中的一个锚盒。为了得到调整后锚盒的S-head特征,我们回溯到其初始位置,在S-head特征图中提取该位置的像素。
我们对模拟损失的定义如下:
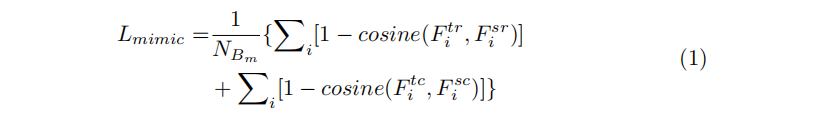
最后,我们正式将多任务训练损失定义为:
L = LR + LS + LT +Lmimic
其中LR、LS和LT分别表示Refinement模块的损失,S-head和T-head.
4
实验结果
4.1 Ablation Study
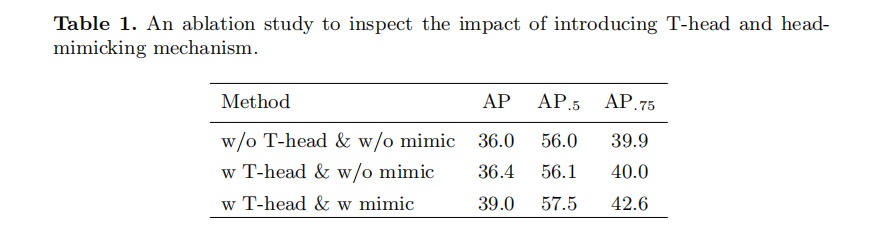
How important is the head mimicking
Design S-heads
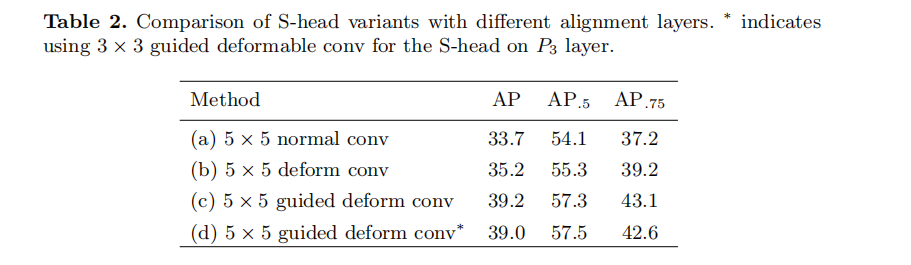
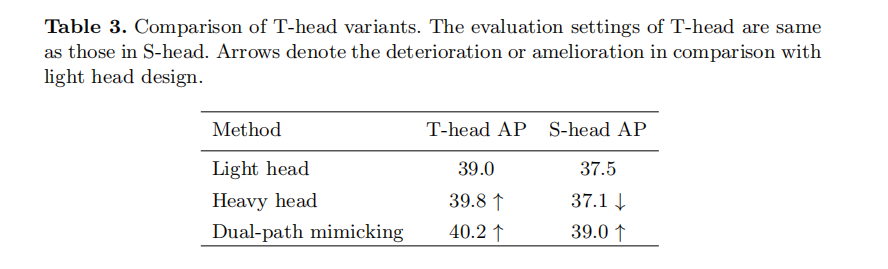
Design T-heads
Design T-heads Staggered feature pyramid

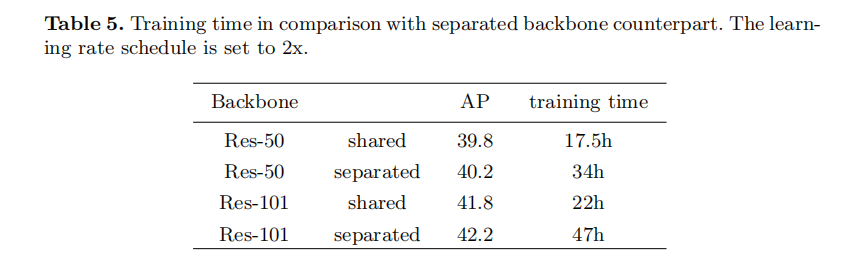
Shared backbone versus separated backbone
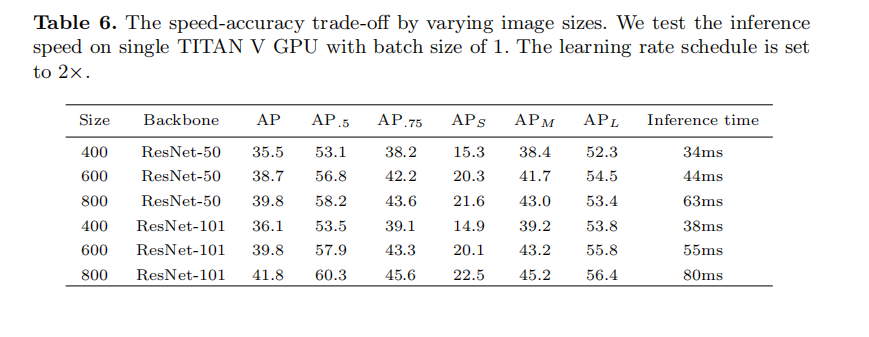
Speed/Accuracy trade-off
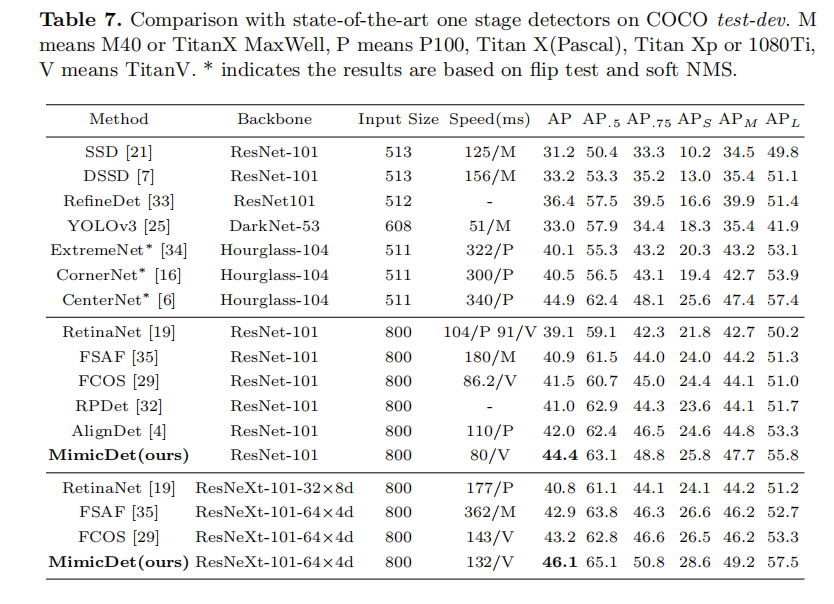
4.2 Comparison with State-of-the-art Methods
资料下载
在CVer公众号后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4100人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!

