Kaggle Tweet Sentiment Extraction 第七名复盘

这是前段时间结束的Kaggle比赛,之前在GDG的Kaggle meetup直播里我也有提到过,最终我们队获得了第七名,这篇文章分享一下我的参赛收获和感受。
首先感谢队友曹老师和Morphy,特别是曹老师,如果没有曹老师我肯定中途就弃赛了。我的代码已经传到Github,感兴趣的朋友可以看一看,里面包含了我所有的commits,可以完整看到我方案的演进。
https://github.com/thuwyh/Tweet-Sentiment-Extraction
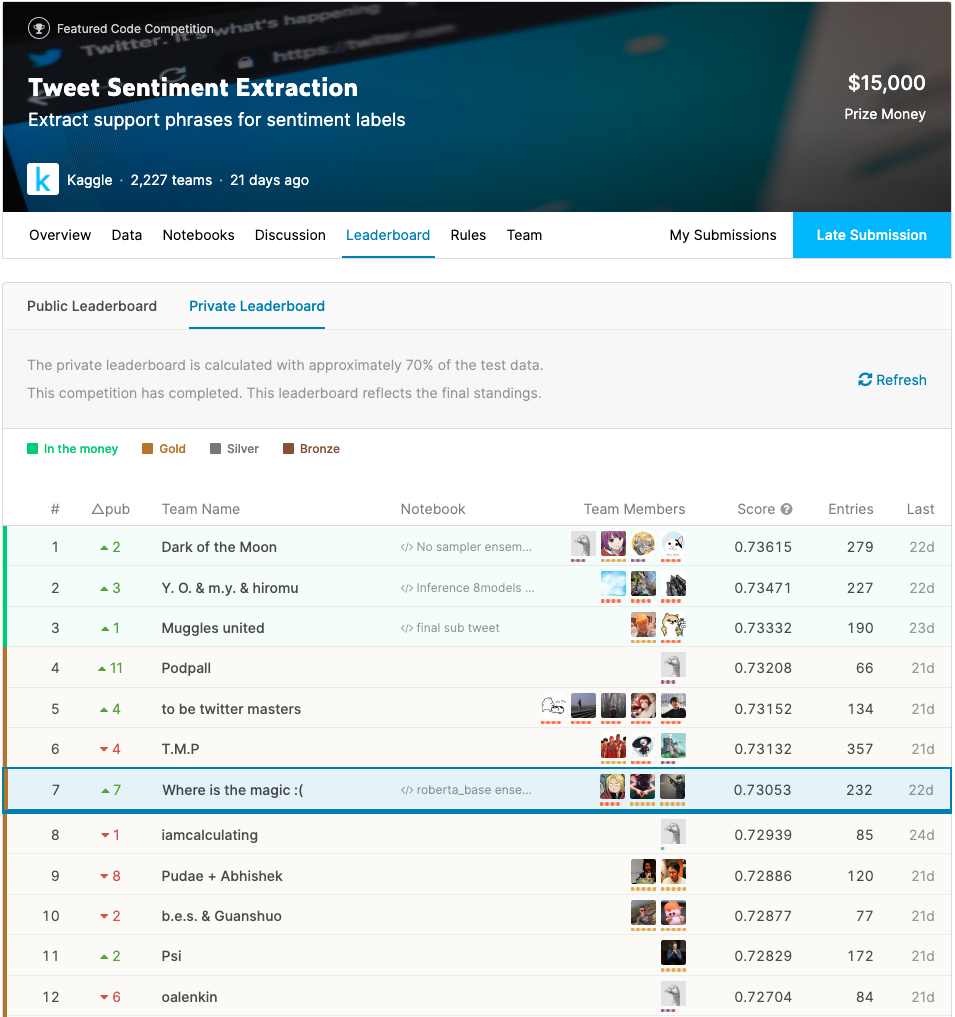
赛题回顾
比赛叫做Tweet Sentiment Extraction,对于给定的tweet和情感极性,需要选手从文本中找出支撑情感的部分。例如下面这条数据
"My ridiculous dog is amazing."
[sentiment: positive]
模型应该返回amazing这个词。比赛的评价指标是word-level Jaccard score,它的含义看下面的实现就一目了然了。
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))
Baseline及一些改进
在比赛的初期讨论区和kernel分享区基本就定下了解题思路的基调,即用机器阅读理解(MRC)的方法来做span prediction。具体的说,就是把数据提供的情感词作为question,把tweet作为context,把预测对象作为answer。
模型也很简单,在RoBERTa后面接一个QuestionAnswering head预测start和end位置就可以了。这道题一个比较神奇的地方就是RoBERTa的效果比普通的BERT要好一些。
在这个框架下,大家也都做了一些改进,例如:
-
在语言模型输出后面加dropout -
concat语言模型的多层输出结果 -
引入FGM等对抗训练方法
以上都是一些比较常规的操作,也比较容易实现,而且其中的对抗训练是比较稳定能提分的。还有一些稍微复杂一点的trick,例如:
-
在词级别进行数据增强,例如同义词替换,随机删词 -
在token级别的增强 -
label smoothing -
蒸馏
因为是span prediction任务,数据增强如果做成随机动态的,需要考虑到改词后对label的影响,这是实现的一个小难点。英文的同义词替换可以使用wordnet来做,相比中文的一些同义词库来讲质量是比较高的。我实验下来这部分也能提一些分,但不是特别显著。
label smoothing和蒸馏是很相关的两个技术,因为他们都需要用到KL散度作为损失函数。做QA任务通常是对位置用CrossEntropyLoss,但是如果label不是一个确定的位置而是平滑过或者是teacher model预测得到的分布,就需要使用KLDivLoss。我也是趁这个比赛补了一补相关的知识,感觉还蛮有趣的,感兴趣的朋友可以参考这篇文章[1]。
标签平滑在论坛里被吹得挺神,在曹老师的模型上也确实有不错的表现。我在做的时候遇到了一个小问题,蛮值得思考的。我们知道早先Google在Inception网络上就使用过这个技巧,对于Imagenet这个分类问题标签的种类是确定的K=1000类,所以在Inception论文[2]里直接用一个系数来控制平滑的强度,即平滑后的标签
但是如果用同样方法在这些长短不一的句子上做平滑,其实是不合适的。每个位置的平滑概率反比于句子的长度,也就是K,所以我认为更好的确定平滑强度的方法是先确定一个单位平滑强度,再根据句子总长来确定原标签的权重。
针对数据特点的方法
这次的数据总体质量很差,噪声(其实是错误)很多,给参赛者带来了很多困扰。主要的噪声模式有两种,一种是把整个句子都标注成了支撑情感的selected_text,第二种是数据中有大量“断头词”出现在标签中。下图给出了一些例子。
对于第一种整句都是标签的情况,早期很多参赛者就发现了对于neutral类型的情感,绝大部分selected_text都和text一样,所以一直流行直接将text作为预测结果的粗暴后处理方法(jaccard值可达0.96);但对于其他情感,我们在人工审阅数据之后并没有发现什么规律。我只好硬着头皮设计了一个辅助的分类任务让模型自己学习,实测下来有些微的提升,但并不明显。
对于“断头词”的情况,我们在比赛的末期终于发现了其规律,即所谓的Magic。这种情况应该是由于标注流程的失误导致的。例如Twitter数据里有很多@用户的情况,也许是出于隐私的考虑,这份比赛数据集会把相关的文本删除,但由于删除脚本的问题会导致文本中多出一个空格。我们猜测标注者看到的数据应该是没有多余空格的,类似于使用' '.join(text.split())处理过。这就会导致标出来的span相对于原text的位置产生了位移。且位移的大小就等于多余空格的数量。
在发现这个规律后,我先是采用规则平移标签修复了selected_text,获得了不含“断头词”的标签,再用干净的模型进行预测,最后再用规则反向平移标签。曹老师则仍然使用原始标签训练,只在预测时加入平移后处理。
这部分只能对这个比赛适用,不能对其他任务的处理提供太多的启发,如果读者感兴趣可以参考我开源的代码,我就不展开说明了。在赛后发现前排队伍使用了更“智能”的方法来建模这个问题。他们在普通的token level模型基础上套了一层char level模型,让机器自行学习这个前后处理的过程,非常fancy。感兴趣的朋友可以去讨论区看他们的方案。
关于比赛的一些感想
不知不觉Kaggle账号注册也快三年了,大大小小参加了20多个各种类型的比赛。从这些比赛里我收获了很多,认识了很多朋友,也学到了很多知识。但现在已经明显感觉到比赛的边际效用在大幅的减小。
很重要的一个原因是我感觉比赛的质量下降了。以这个比赛为例,主办方居然连标签数据都搞错了,而且在长达几个月的赛程中,没有人去修复它。我完全无法理解这种过拟合错误标签的意义是什么,所以越做越痛苦,大概做了一个多月就不想做了,一度弃赛。后面在曹老师的鼓励下才坚持到最后,发现了trick,用正确的标签训练了模型。虽然这个比赛有点极端,但即使数据没有错,比赛的目标是错的或不可达到的情况近来屡见不鲜。越来越多的比赛会有巨大的Shakeup,很多选手辛辛苦苦搞几个月最后结果还不如最开始讨论区放出的baseline kernel。这一方面提醒我们算法不是万能的,很多事情就是无法使用机器学习预测;另一方面这种负反馈很容易给参赛者特别是初学者的学习热情浇上一盆冷水,比赛带来的愉悦感大受影响。
另一个原因是随着工作年限的增加慢慢地会体会到算法只是价值链条中的一环。比赛是在一个相对封闭的环境里解决别人抽象好的问题,但现实中解决问题的要义可能正是打破这种封闭,例如做更合理的问题定义、改进采集流程获得更高质量的数据等等。之前很多同时期做比赛的GM比如植物、涛神都渐渐淡出了比赛圈更多地投入到工作中可能也是因为这个原因。
但不管怎么样,如果三观摆正,比赛还是一个快速学习提高的有效途径。而能稳定地在多个比赛里做到top1%,应该也是对能力很好的证明。建议初学者在开始投入一个比赛前,可以先进行一下可行性分析,识别出高质量比赛,避免踩坑。
关于这个比赛就写到这,大家有什么问题可以去github提issue或者加我们的微信群交流。
参考资料
交叉熵、相对熵(KL散度)、JS散度和Wasserstein距离: https://zhuanlan.zhihu.com/p/74075915
[2]Rethinking the Inception Architecture for Computer Vision: http://arxiv.org/abs/1512.00567
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



