近年来,神经机器翻译(Neural Machine Translation,NMT)已经事实上成为了主流的机器翻译方法,其在大多数主流语言对上的翻译效果大大超过了传统的统计机器翻译模型,并已经部署到了如 Google Translate 等商用场景中。
NMT 通常采用带有注意力机制(Attention Model) 的编码器-解码器框架(Encoder-Decoder Framework)。
在这个框架中,输入的源语言句子首先被编码器编码成一个词内容表示序列;
基于这些源端的表示,解码器逐词地生成源语言句子的译文。
其中,在生成每个词时,其通过注意力机制来从源端获取到当前要翻译的词对应的端词汇级别内容信息,这就像人类译者在翻译时需要知道此时对应的源端内容一样(我们称该内容为“当前,Present”)。
与此同时,NMT 也应该像人类一样能够获悉当前时刻已经翻译过的源端内容(过去,Past)和还没翻译的内容(未来,Future)。
这样一来,过去、当前和未来这三类动态变化的内容状态就构成了每个时刻翻译的完整的源端上下文信息(Past+Present+Future=Holistic)。
之前的一些研究已经表明,NMT 模型很容易面临翻译忠实度欠缺的问题(Inadequate Translation Problem),例如过度翻译(Over-translation) 和欠翻译(Under-translation)。
这个问题很大程度可归因于 NMT 对动态变化的已翻译和未翻译内容的识别不佳。
为此,我们在之前的一个工作中首次展示了如果显式地建模机器翻译中的过去和未来信息可以一定程度地缓解这个问题,并且提升 NMT的翻译质量(Zheng et al., TACL2018)。
我们当时分别使用了两个 RNN 来建模过去和未来信息,不足的是,RNN建模的结果分别对应源端哪些内容却不是那么容易确定。
在本文的工作中,我们认为在每个时刻显式地将源端的词分为对应当前翻译过去和未来的两组,会让NMT 得以更好地识别和利用翻译中的动态完整的上下文,也能带来更好的对模型行为的解释性。
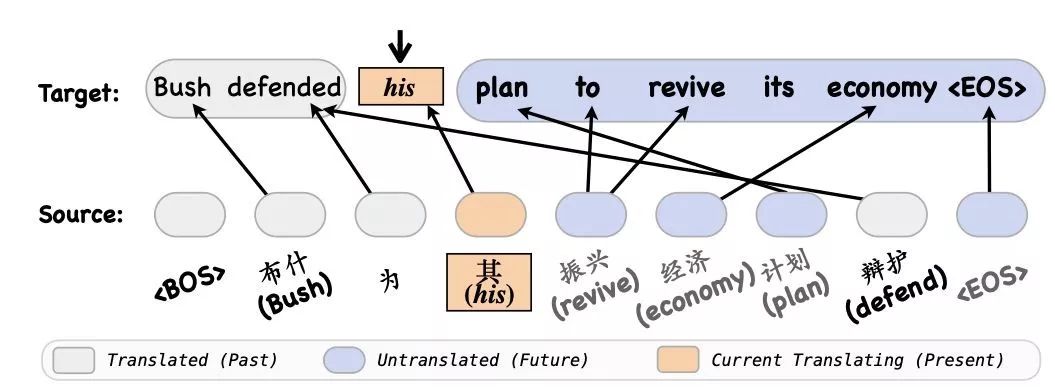
该过程如图 1 所示。
我们发现这个过程可以形式化成“部分-整体分配(Parts-to-Wholes Assignment)”:
源语言各个词语(部分)被分配到两个不同的组,即过去和未来(整体)。
图1:
显式把源端词分成过去和未来两组。
该例子中当前待翻译的目标词为“his”。
为此,我们在本文中基于胶囊网络(Capsule Network,Sabour et al., NIPS2017)提出了一种新的动态路由机制,我们称之为“有指导的动态路由(Guided Dynamic Routing,GDR)”来实现对该过程的建模。
前面说到,我们期望的区分过去和未来的过程可以被形式化成“部分-整体分配”过程,而胶囊网络及其配套的动态路由机制在以往的工作中展现出了适合建模该过程的强大能力。
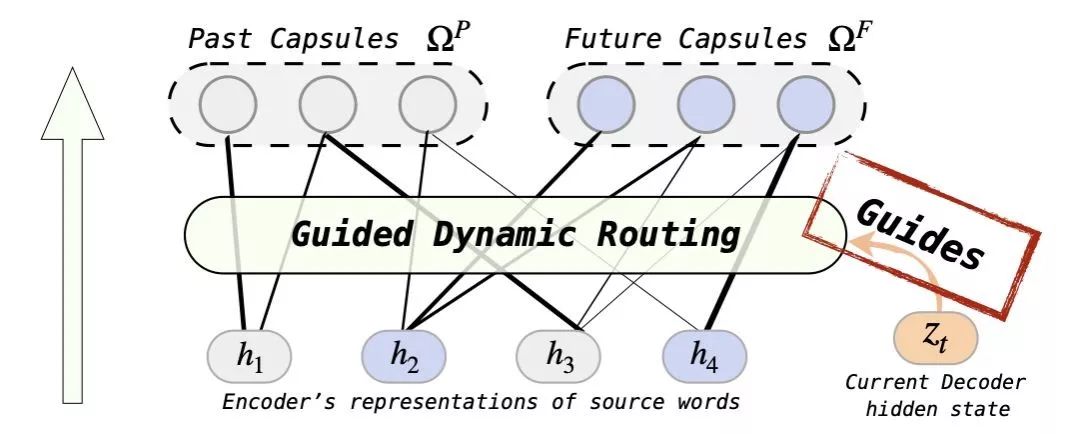
原始的动态路由机制是自发地将信息动态分配到不同的组中,而我们期望分配源语言词到过去和未来信息的过程受到当前翻译状态的指导。
因此,我们改进并提出了一种新的动态路由机制来建模我们的目标。
我们的方法如下:
我们首先用两组 Capsule 来分别表示过去和未来信息
我们提出了一种新的动态路由机制,称之为“有指导的动态路由(Guided Dynamic Routing,GDR)”。GDR 的路由过程受到当前翻译的状态(解码器表示)指导,通过多次路由迭代更新每个源端词应该分别到其对应的 Capsule(过去或未来)的概率,从而可以得到对应当前翻译时刻的过去和未来表示(图 2)
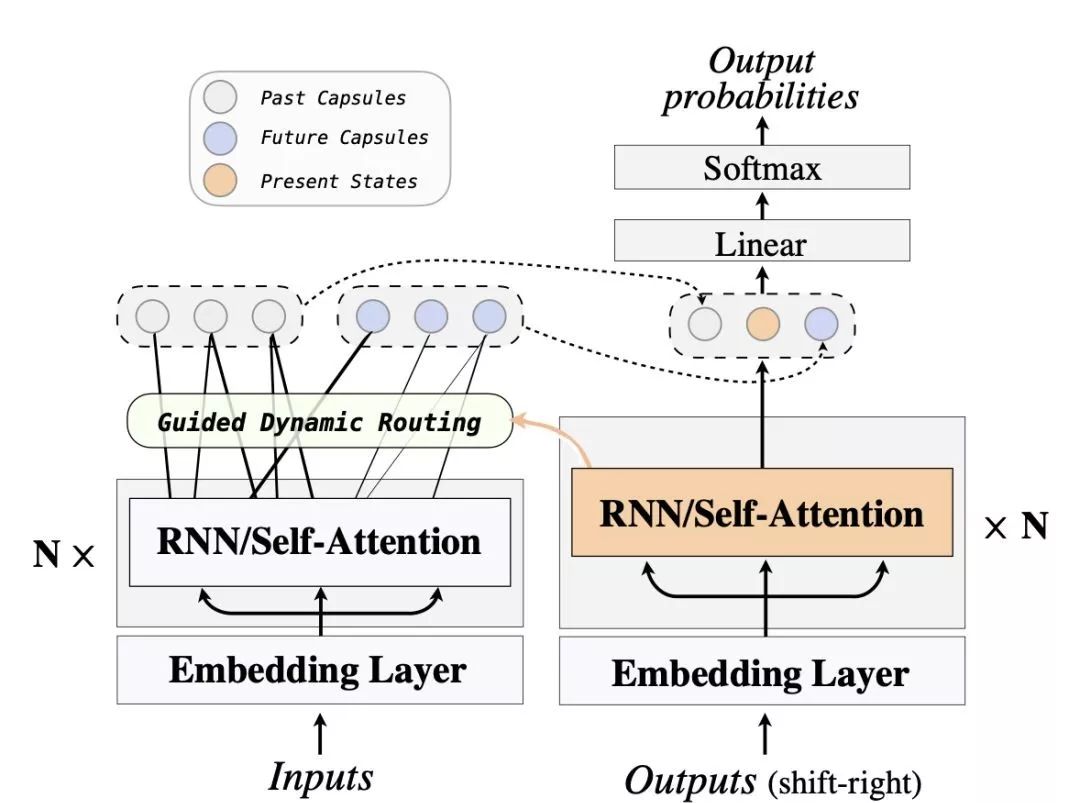
最后,我们将GDR 得到的过去和未来表示与解码器的隐层表示一起构成一个当前翻译对应的动态且完整上下文表示,用以提供一个全局的视角来预测当前的译文(图 3)。该方法可以应用到任一常见的编码器解码器框架上,如 RNMT 和 Transformer
为了让这两组 Capsule 确实能通过 GDR得到我们期望的信息,即一组是过去内容,一组表示未来内容,我们还设计了两种不同的辅助监督信号来帮助 GDR 对识别和分配的学习。
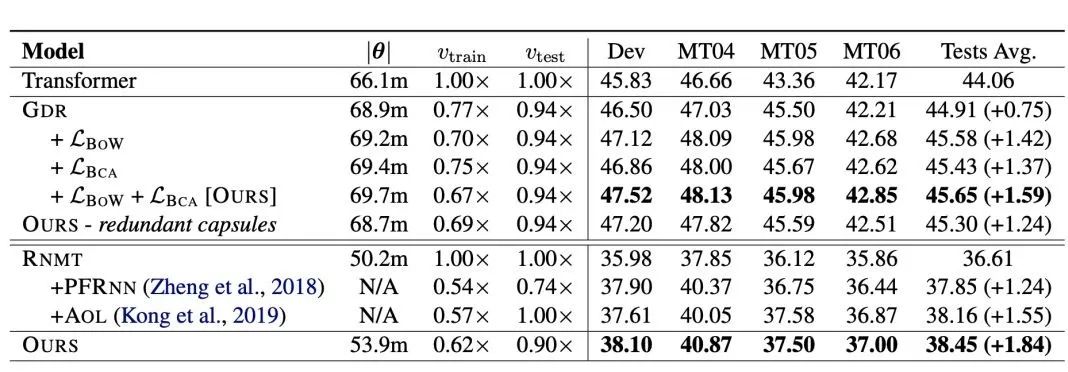
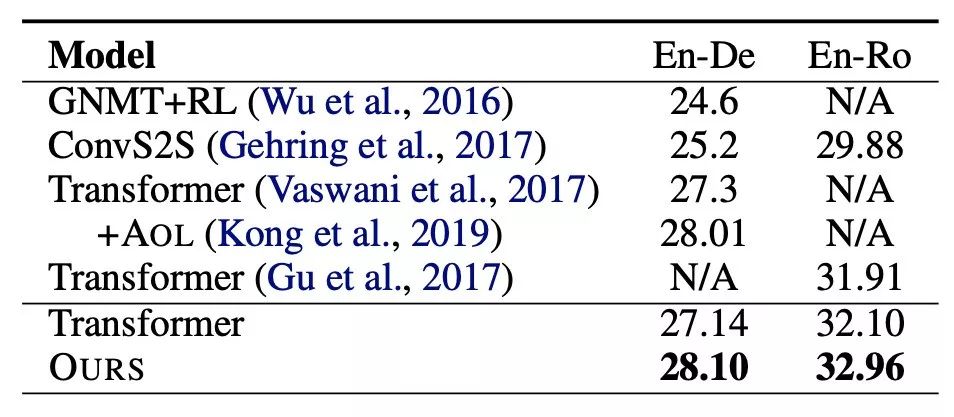
我们的方法在 3 个不同语言对上的实验都得到了有效的提升(表 1,2)
我们的方法在 2 个不同的 NMT 架构,RNMT 和 Transformer,上都得到了一定提升,说明了我们方法可以很容易兼容任意主流的编码器解码器框架(表 1)
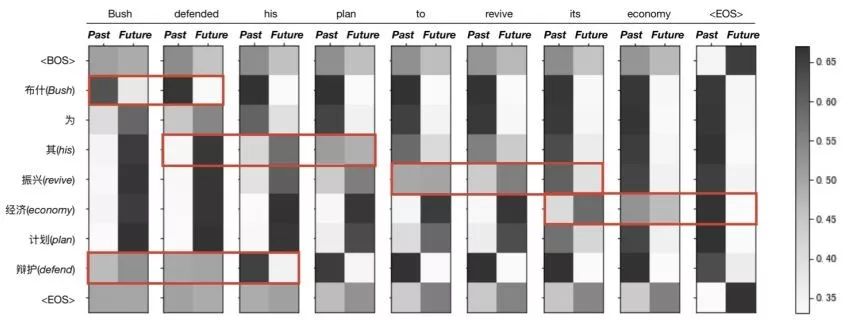
我们的方法确实学到了识别和区分过去和未来信息的能力,我们通过可视化实验证明了该方法具有很好的解释性(图5)
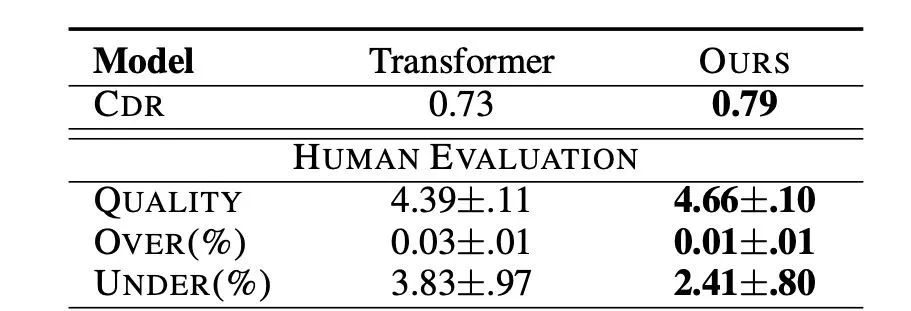
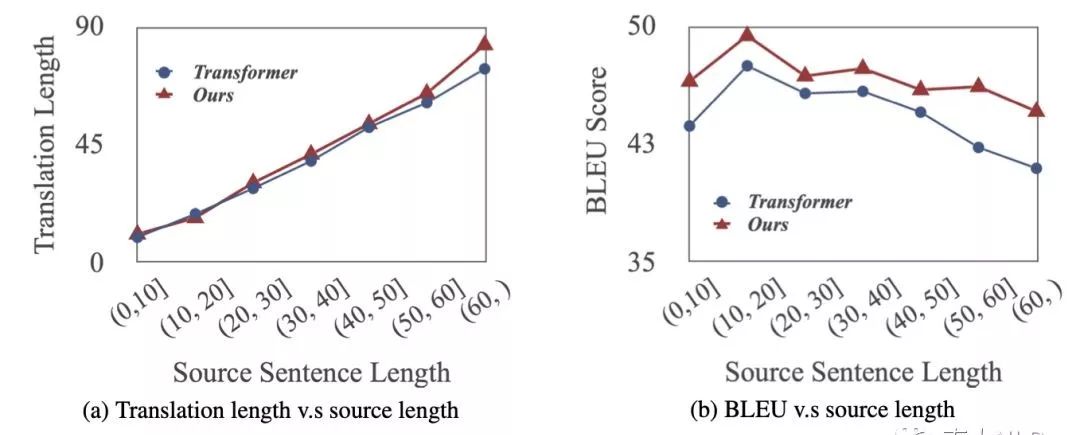
我们的方法缓解了翻译忠实度欠缺的问题:我们通过人工评价和长度实验分析发现我们的模型生成了比 Transformer 更忠实更高质量的译文(图 6,7)
图 5:GDR 分配概率可视化。可以看到在目标译文翻译的前后,其对应源端内容分配概率的变化。总的来看,分配到过去的概率在逐渐累积,分配到未来的概率逐渐衰减
图 7:
长度实验分析。
我们的模型可以生成更好更忠长的译文
在本文中,我们展示了在神经机器翻译中建模动态过去未来对翻译质量和忠实度的帮助。
我们将识别和区分过去未来信息形式化成“部分-整体分配”过程,并提出了一种新的“有指导的动态路由”来建模该过程。
该方法能应用到任意NMT架构中,基于当前翻译状态的指导动态地识别出此时对应的源端过去和未来内容,从而为预测译文提供一个完整的上下文信息。
我们通过实验证明了该方法在多个机器翻译实验场景中的有效性,并且证明了该方法确实学到了我们预期的识别能力,具有很好的可解释性。
另外,该方法还可以应用到文本摘要任务中。
Sara Sabour, Nicholas Frosst, Geoffrey E. Hinton. Dynamic Routing Between Capsules. Advances in Neural Information Processing Systems 30 (NIPS 2017)
Zaixiang Zheng*, Hao Zhou*, Shujian Huang, Lili Mou, Xinyu Dai, Jiajun Chen, and Zhaopeng Tu. Modeling Past and Future for Neural Machine Translation. Transactions of the Association for Computational Linguistics (TACL), Volume 6, pages 145-157, 2018
![]()