美图影像实验室(MTlab)10000 点人脸关键点技术全解读
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文授权转自公众号AI科技评论
能支持全方位姿态、各种极端表情,且在移动端达到500fps 的超高运行速度。
编者按,日前,美图影像实验室(MTlab, Meitu Imaging & Vision Lab)推出「10000 点 3D 人脸关键点技术」——利用深度学习技术实现 10000 点的人脸五官精细定位,该项技术可以在 VR 游戏中构建玩家人脸的 3D 游戏角色并且驱动,也可以应用于虚拟试妆试戴和医疗美容领域等。本文为美图影像实验室 MTlab 基于该技术的独家解读。正文如下:
简介
在计算机视觉领域,人脸关键点定位在视觉和图形中具有广泛的应用,包括面部跟踪、情感识别以及与多媒体相关的交互式图像视频编辑任务。目前行业内常用的是 2D 人脸关键点技术,然而,2D 人脸点定位技术由于无法获取深度信息,不能分析用户的立体特征,比如苹果肌,法令纹等更加细致的用户信息,也无法分析出用户当前的姿态和表情。为了能够给用户的自拍添加动画效果,如面具、眼镜、3D 帽子等物品,并且提供更加智能的 AI 美颜美型效果,需要一套特殊的感知技术,实时跟踪每个用户的微笑、眨眼等表面几何特征。因此,美图影像实验室 MTlab 研发人员研发了 10000 点人脸关键点技术,将面部图像提升到三维立体空间,将用户的姿态、脸型以及表情分解开来,实时跟踪用户当前的姿态、表情、五官特征改变后的面部形态,调整后的图像更加自然美观。

基于 3DMM 的人脸关键点定位方法
1. 三维形变模型 (3DMM)
1999 年,瑞士巴塞尔大学的科学家 Blanz 和 Vetter 提出了一种十分具有创新性的方法——三维形变模型 (3DMM)。三维形变模型建立在三维人脸数据库的基础上,以人脸形状和人脸纹理统计为约束,同时考虑了人脸的姿态和光照因素的影响,生成的人脸三维模型精度较高。
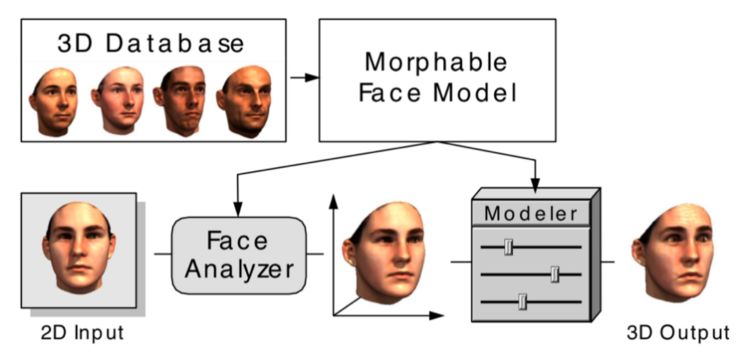
3DMM
如上图所示 3DMM 的主要思想是:一张人脸模型可以由已有的脸部模型进行线性组合。也就是说,可以通过改变系数,在已有人脸基础上生成不同人脸。假设建立 3D 变形的人脸模型由 m 个人脸模型组成,其中每一个人脸模型都包含相应的脸型和纹理两种向量,这样在表示新的 3D 人脸模型时,就可以采用以下方式:
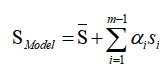
其中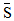
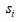
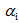
Blanz 和 Vetter 提出的 3DMM 虽然解决了人脸变形模型的表达问题,但其在人脸表情表达上依然存在明显不足。2014 年时,FacewareHouse 这篇论文提出并公开了一个人脸表情数据库,使得 3DMM 有了更强的表现力,人脸模型的线性表示可以扩充为:
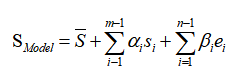
在原来的脸型数据基础上,增加了表情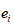
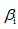
2. 美图 MT3DMM 模型
为了能够更加精细地刻画不同人脸的 3D 形状,并且适用于更广泛的人种,MTlab 的研发团队采用先进的 3D 扫描设备采集了 1200 个不同人物、每人 18 种表情的 3D 人脸数据,其中男女各半,多为中国人,年龄分布在 12~60 岁,模型总数超过 20000 个,基于这些数据,建立了基于深度神经网络的 MT3DMM 模型。相比于目前主流的 3DMM 模型,MT3DMM 具有表情丰富,模型精度高,并且符合亚洲人脸分布的特点,是目前业界精度最高的 3D 人脸模型之一。
3DMM 模型,代表了一个平均脸,也同时包含了与该平均脸的偏差信息。例如,一个胖脸在一个瘦脸模型基础上,通过调整五官比例可以得到胖脸模型。利用这种相关性,计算机只需要利用用户的脸与平均人脸的偏差信息,就能够生成专属于用户的 3D 模型。不仅如此,这些偏差还包括大致的年龄、性别和脸部长度等参数。但是,这样也存在一个问题,世界上的人脸千变万化,要将所有人脸与平均人脸的偏差都存储下来,3DMM 模型需要集成大量面部的信息,然而目前的开源模型在模仿不同年龄和种族人脸方面的能力十分有限。
如下图 BFM 的人脸数据基本都是外国人脸,跟亚洲人脸的数据分布存在差异;Facewarehouse 的数据主要是亚洲人脸,但是用 Kinect 扫描的模型则存在精度较低的问题;SFM 开源的数据只包含了 6 种表情,并且模型的精度较低,无法满足我们的需求;LSFM 数据包含了较多的人脸数据,但是不包含表情,无法用于用户表情跟踪。

BFM 和 SFM 数据中的部分数据
扫描出来的模型虽然是高精度的模型,但是不包含具体的语义信息。因此,MTlab 的 3D 研发团队专门为此开发了一套自动注册算法,无需人工进行标定就可以对扫描模型进行精细化注册,如下图所示:
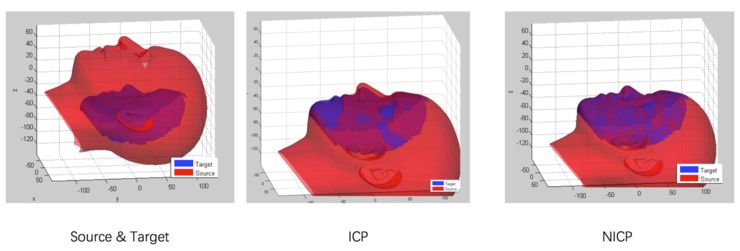
注册流程
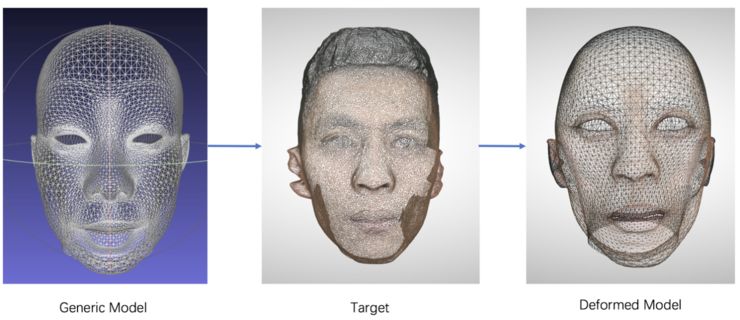
模型生成结果
最终,MTlab 将所有注册好的 3D 模型组合成 MT3DMM 数据库,用于 10000 点面部关键点定位。高精度的扫描模型也为开发其它功能提供了更多的可能。
3. 数据制作
为了能够发挥深度学习的大数据优势,需要给神经网络提供大量的数据,MTlab 研发人员设计了一套高复杂度的数据制作算法,同时配合高精度的 MT3DMM 模型制作出大量的训练数据。相比目前主流的训练数据制作方法,MTlab 的训练数据可以有效的解耦脸型,表情以及姿态信息,在进行精确的稠密点人脸定位的同时,进行 AR 特效以及精准的人脸表情驱动。
从上面的公式可以将人脸重建的问题转化成求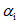
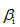
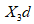
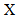
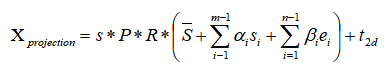
这里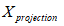
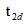
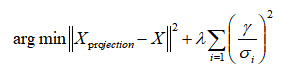
这里加了正则化部分,其中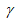
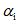
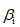
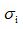
目前的 3D 重建算法大多都是将姿态,脸型以及表情参数一起优化,并不能将这三者独立开来,为了能够解耦姿态,表情,以及脸型之间的关系,MTlab 的数据包含了一个人同一姿态下的不同表情,以及同一表情下不同姿态的数据集,采用 Joint Optimization 策略来计算每个人的脸型,姿态以及表情参数,得到解耦后的参数数据可以真实反应出当前人脸的姿态信息,脸型信息以及表情信息,极大的丰富了应用场景。
4. 神经网络训练
传统的 3D 人脸重建算法,不管是单图重建、多图重建还是视频序列帧重建,都需要通过凸优化算法优化出所需要的参数,为了能够让算法在移动端实时运行,MTlab 研发人员采用深度神经网络进行 End-to-End 学习,通过神经网络强大的学习能力替代了凸优化过程的大量计算。通过研究分析目前移动端较快的网络(SqueezeNet、Shufflenet V2、PeleeNet、MobilenetV2、IGCV3)的特性,MTlab 研发人员提出了一种适合移动端网络,并且具备低功耗特性的 ThunderNet,配合 MTlab 研发的 AI 前向引擎和模型量化技术,在美图 T9 上运行帧率达到 500fps。MT3DMM 神经网络训练的要点如下:
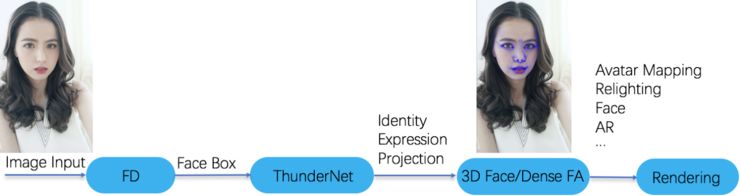
MT3DMM 整体流程
数据增益:为了适应 In-the-wild 图像,需要让算法对低分辨率、噪声、遮挡或包含运动和不同的光照场景下具有强鲁棒性,MTlab 采用了海量的数据,并用算法扰动模拟了各种真实环境下的数据进行训练。
网络结构:使用了 MTlab 自研的 ThunderNet 网络结构,在速度和精度上都超过了同规模的快速网络,包括 SqueezeNet、Shufflenet V2、PeleeNet、MobilenetV2、IGCV3,并具有低功耗的特点。
损失函数:Loss 主要采用了参数 Loss、KeyPoints Loss、3D Vertexes Loss 以及 Texture Loss,并且用相应的权重去串联它们,从而使网络收敛达到最佳效果。实验发现,参数 Loss 可以获取更加准确的参数语意信息,KeyPoints Loss 可以使最终的稠密人脸点贴合人脸五官信息,3D Vertexes Loss 能更好地保留用户脸部 3D 几何信息,Texture Loss 则可以帮助网络实现更好的收敛效果。
最终,在得到网络输出的参数后,MTlab 用 MT3DMM 模型解码出相应的人脸 3D 模型,根据姿态以及投影矩阵就可以得到面部稠密人脸点。模型都是经过参数化后,每一个点都有其相对应的语义信息,可以通过修改 3D 模型对图像进行相应的编辑。美图手机上光效相机、个性化美颜档案、3D 修容记忆、美颜立体提升、3D 姿态调整、App 萌拍动效、美妆相机万圣节妆容、彩妆、Avatar 驱动等功能都采用了该项技术。
· 参考文献 ·
V. Blanz and T. Vetter. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques, pages 187– 194, 1999.
Cao C, Weng Y, Zhou S, et al. Facewarehouse: A 3d facial expression database for visual computing[J]. IEEE Transactions on Visualization and Computer Graphics, 2014, 20(3): 413-425
Huber P, Hu G, Tena R, et al. A multiresolution 3d morphable face model and fitting framework[C]//Proceedings of the 11th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications. 2016.
Booth J, Roussos A, Zafeiriou S, et al. A 3d morphable model learnt from 10,000 faces[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 5543-5552.
Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 116-131.
Wang R J, Li X, Ling C X. Pelee: A real-time object detection system on mobile devices[C]//Advances in Neural Information Processing Systems. 2018: 1963-1972.
Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4510-4520.
Sun K, Li M, Liu D, et al. Igcv3: Interleaved low-rank group convolutions for efficient deep neural networks[J]. arXiv preprint arXiv:1806.00178, 2018.
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~




