一文总览知识蒸馏概述
这是一篇关于【知识蒸馏】简述的文章,目的是想对自己对于知识蒸馏学习的内容和问题进行总结。笔者挑选了部分经典的paper详读,希望对于对KD有需求的同学提供一个概览和帮助。
引子
昆虫记里写道:”蝴蝶以毛毛虫的形式吃树叶积攒能量逐渐成长,最后变换成蝴蝶这一终极形态来完成繁殖”。虽然蝴蝶和毛毛虫两者本质是同一种生物,但是面对不同环境和任务的时候,形态不同——毛毛虫形态下可以更方便地吃树叶,保护自己,积蓄能量;而蝴蝶能飞,可以扩大活动范围,提高繁殖几率。
在监督学习里也是这样的,在训练模型时,我们通常采用复杂模型或者Ensemble方式来获取最好的结果,导致参数冗余严重,像BERT里有3亿参数。因此在前向预测时,需要对模型进行复杂的计算(或多个模型加权),导致工程性能较差。
Hinton在NIPS 2014workshop中提出知识蒸馏(Knowledge Distillation,下面简称KD)概念:
把复杂模型或者多个模型Ensemble(Teacher)学到的知识 迁移到另一个轻量级模型( Student )上叫知识蒸馏。 使模型变轻量的同时(方便部署),尽量不损失性能。
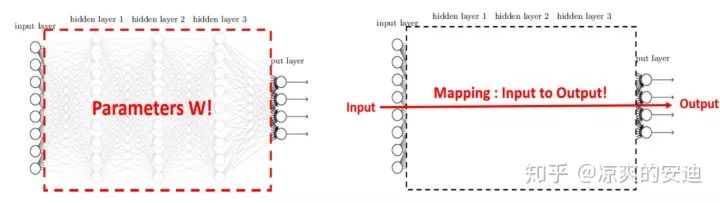
从定义上来看KD属于模型压缩、加速的一类玩法。(后面的研究也会将KD应用于模型表现的提升)。在这里,知识应该宽泛和抽象地理解,模型参数,网络层的输出(网络提取的特征)、网络输出等都可以理解为知识。
Overview & Timeline
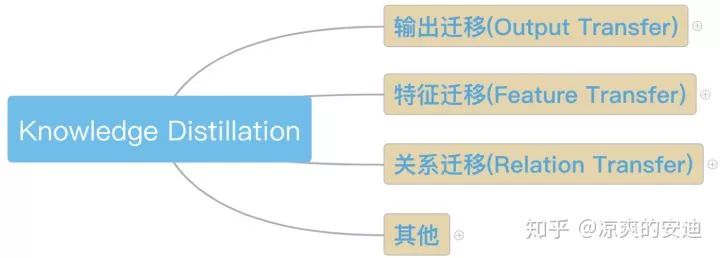
按照待迁移的知识类型,KD主要分为三个大类:
Output Transfer——将网络的输出(Soft-target,后面会介绍其含义)作为知识;
Feature Transfer——将网络学习的特征作为知识;
Relation Transfer——将网络或者样本的关系作为知识;
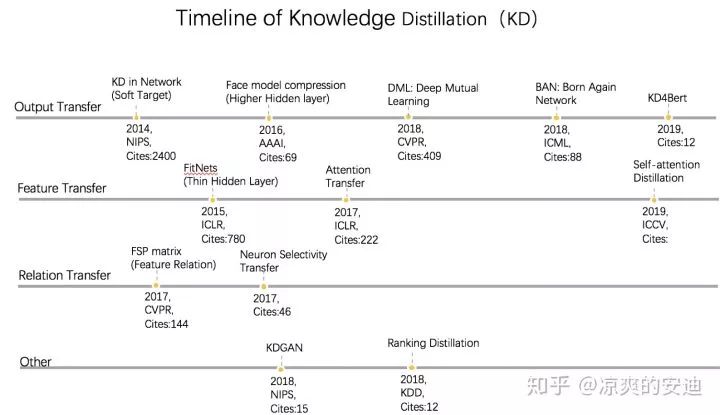
从时间线上来看,KD的发展脉络大致如下(部分论文):
在第二part中,对于Paper内容的概述也将大概按照KD的类别分别展开。
Papers
2-1 Output Transfer
Output Transfer——将网络的输出(Soft-target,后面会介绍其含义)作为知识。在该部分,将主要介绍以下几篇paper。

2-1-1 《Distilling the Knowledge in a Neural Network 》
【Meta info】Hinton,NIPS 2014 workshop,Cites:2400
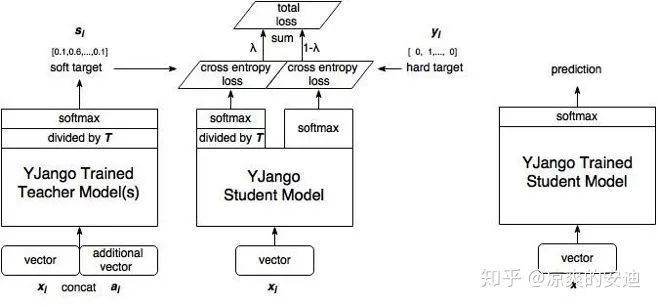
这篇paper是知识蒸馏的开山之作,由Hinton老爷子在NIPS 2014 workshop上提出,文章的思路非常简单、优雅。首先,我们对一些术语进行定义:
Teacher:原始较大的模型或模型Ensemble,用于获取知识
Student:新的较小的模型,接收teacher的知识,训练后用于前向预测
Hard target:样本原本的标签,One-hot
Soft target :Teacher输出的预测结果(一般是softmax之后的概率)
接下来,进入正题,介绍蒸馏的过程:

从模型效果上来看:
【Mnist】
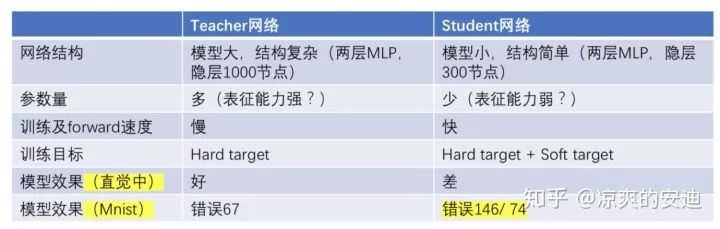
Teacher网络模型复杂,参数多,表征能力强,使用Hard Target作为训练目标,并且从直觉上来看,效果应该是好的(参数多),最终在测试集上错了67个。
Student网络模型简单,参数少,表征能力弱,在直接使用Hard target 作为训练目标时(不使用知识蒸馏),在测试集上错了146;使用Hard target + Soft target作为训练目标时,错了74个。
可以看出,加入了Soft target后,小网络从大网络中继承了大网络中学习的“知识”,但是这个实验中,最好的结果没有超过baseline。
【一个语音数据集】
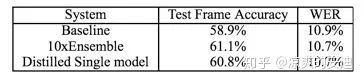
Teacher(baseline)网络准确率58.9%,10个Teacher集成的准确率为61.1%,而神奇的是,Student网络(简单模型蒸馏Ensemble网络)的效果居然超过了Teacher网络!
我们考虑下起主要效果的因子:
以Mnist数据集为例,对于数字9而言,数字9与数字4和7长得比较像。网络在进行训练时,我们如果能够将数字之间的相似关系传递给模型,则网络可能学习到更好的结果。

而对于Hard target和Soft target,

我们可以看出,软目标的优势在于:
弥补了简单分类中监督信号不足(信息熵比较少)的问题,增加了信息量;
提供了训练数据中类别之间的关系(数据增强);
可能增强了模型泛化能力。
What's more,关于软目标相关的思考,还有Label smoothing Regularization(LSR),即“标签平滑归一化”。LSR也是对“硬目标”的优化:

具体推导可以参考
Müller R, Kornblith S, Hinton G. When Does Label Smoothing Help?[J]. arXiv preprint arXiv:1906.02629, 2019.
在经典的蒸馏网络中,参数T是一个超参数——温度。T表示软目标要soft的程度:
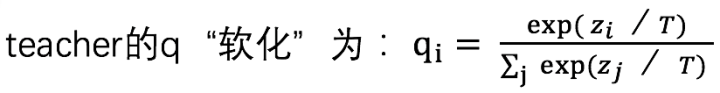
T = 1,公式同softmax输出后的结果;
T越接近0,公式越同One-hot编码,最大值趋向于1,最小值趋向于0;
提升T,则保留更多类别关系信息。
2-1-2 《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》
【Meta info】:2019, Cites:12
本文是对Bert网络进行蒸馏,其思想与经典蒸馏网络并无区别。
【背景】:
18年底,Bert在很多NLP任务上取得了STOA,但线上运算时,算力是“瓶颈”, 使用单核B70 CPU,Seq length=128时,QPS只有几十
KD在NLP应用较少
本文希望用Bi-LSTM网络蒸馏Bert网络
【网络Loss】:同经典KD,Loss分为两部分:
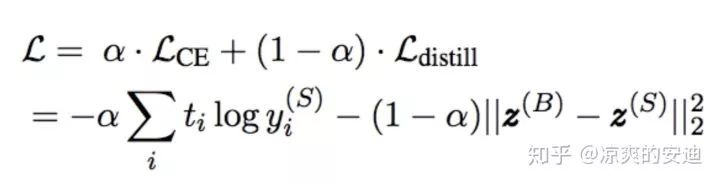
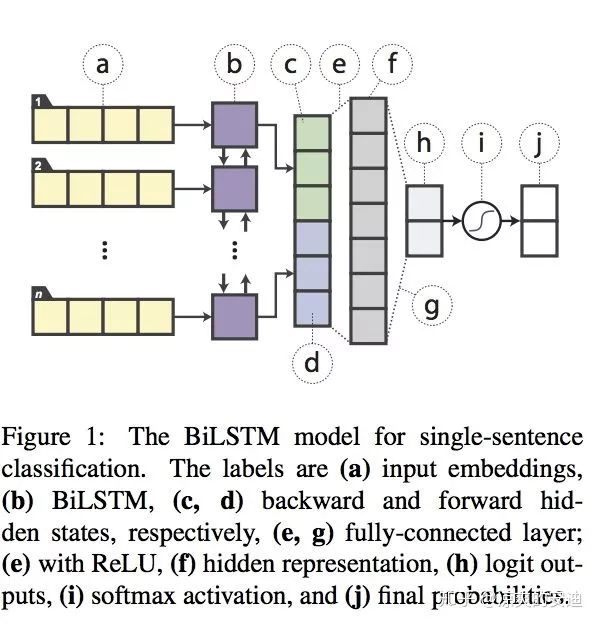
【网络结构】:
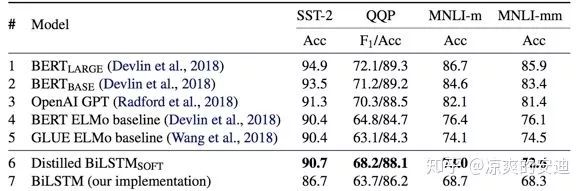
【效果】:可以看出蒸馏的结果弱于Bert但是比原始的双向LSTM效果好很多。
2-1-3 《Deep Mutual Learning》
【Meta info】:CVPR 2018,Cites:409
【背景】:
在经典的蒸馏过程中,teacher网络固定,只用来输出soft-target,难以学习student网络中反馈的信息,进而对训练过程进行优化
本文提出深度互学习,多个学生网络同时训练,通过真值和多个网络的输出结果“相互借鉴,共同进步”
本文不已模型压缩为主要目的,更多为了提升模型表现
【网络结构】(以两个网络为例):
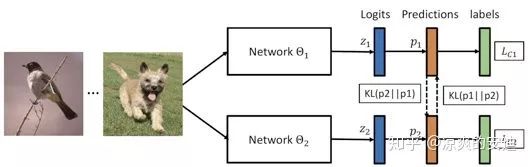
【网络Loss】:
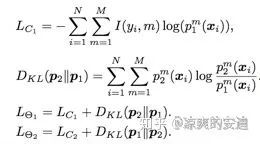
思路比较简单,Lc1是经典的交叉熵,Dkl是KL散度。
【实施】:

当存在多个子网络时:
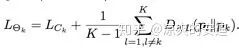
【效果】:
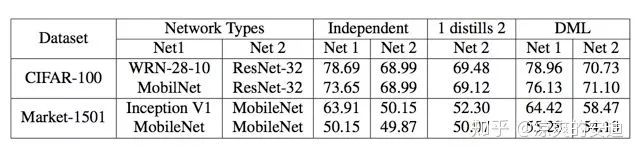
可以看出,在DML思路下,网络效果比单个网络有了明显的提升;效果比经典的蒸馏网络也提升较大。
【有效因子】:
类别概率中包含了更多信息(同经典KD)
深度互学习的方法可能找到了更平缓的极值点(意味着泛化能力更强,小的波动不会对预测产生较大的影响),如下图所示,DML网络的Loss和单独训练网络Loss接近,但是,当对参数添加噪声时,DML的Loss小于单独训练的Loss(当网络输出对于输入噪声的敏感程度比较差的时候,可以认为网络输出处于一个比较平缓的局部最优点)。
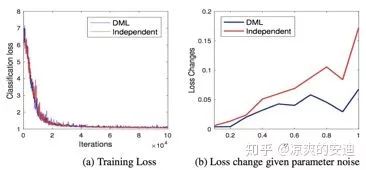
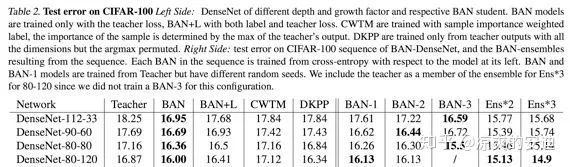
【2-1-4】《Born Again Neural Networks》再生网络
【Meta info】:CVPR 2018,Cites:409
【思路】:
再生网络也不已模型压缩为主要目的,更多为了提升模型表现
再生网络基于蒸馏的理念,提供了一种Esemble的思路
教师、学生网络结构相同,第n个学生目标训练第n+1个学生,“口口相传”
最后进行集成
【网络结构】:
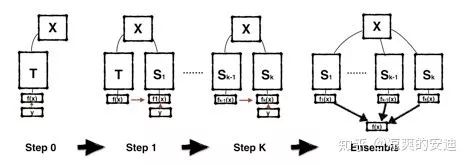
【效果】:
2-2 Feature Transfer
Feature Transfer——将网络学习的特征作为知识。在深度学习中,一般将隐藏层的输出看作是网络学习的特征,下面两篇paper中:第一篇paper以MLP为基础框架,则网络提取的特征为每个隐藏层的输出向量;第二篇paper以CNN为基础框架,则网络提出的特征为每层的Feature Map。

2-2-1 《FitNets: Hints for Thin Deep Nets》
【Meta info】:ICLR 2015,Cites: 780
[背景]:
Deep可能是DNN主要的拟合能力的重要来源,之前的KD工作都是用较浅的网络作为student net,拟合能力可能较弱
这篇文章把“宽”且“深”的网络蒸馏成“瘦”且“更深”的网络
[思路]:
学生网络不仅仅拟合教师网络的soft-target,而且拟合隐藏层的输出(教师抽取的特征);
第一阶段让学生网络去学习教师网络的隐藏层输出(特征迁移);
第二阶段使用soft targets来训练学生网络(输出迁移)。
【网络结构】:
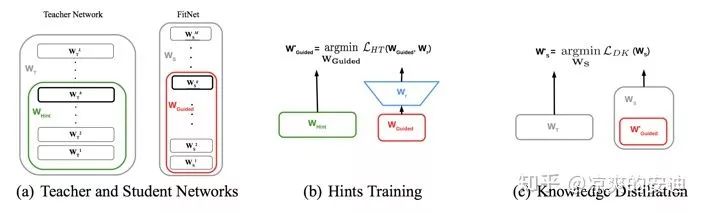
【实施】:

2-2-2 《Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer》
【Meta info】:ICLR 2017, Cites: 222
【思路】:
思路一:对卷积网络隐藏层输出的特征图——feature map(特征 & 知识)进行迁移(Attention transfer),让学生网络的feature map与教师网络的feature map尽可能相似
思路二:Loss对输入X求导,得到梯度更大的像素点,表明”更重要”,需要pay more attention
该特征迁移的方法也可以与soft-target的方式结合
【网络结构】:
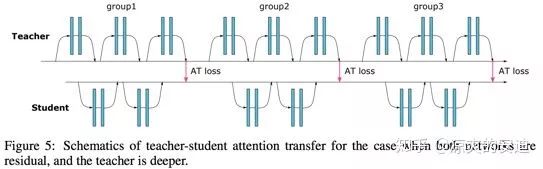
【思路1——Actication-based attention transfer】:
对卷积网络隐藏层输出的特征图——feature map(特征 & 知识)进行迁移(Attention transfer),让学生网络的feature map与教师网络的feature map尽可能相似;
该特征迁移的方法也可以与soft-target的方式结合。
【实施】:
首先将Teacher网络和Student网络都分成n个part(两者分part的数量相同),每个part内包含几个卷积核池化层都是可以的,不过为了提升预估的效率,一般学生网络每个part的网络结构比教师网络简单。同时,保证学生网络和教师网络每个part的最后一个卷积层得到的feature map的size大小相同,都是W * H(数量可以不同);
接下来,为了计算loss,每个part的最后一个卷积层C个W * H的特征图变换为1个W* H的的二维张量,原文提供了以下三种方式(比较简单可以回原paper详读):
特征图张量各通道绝对值相加;
特征图张量各通道绝对值p次幂相加;
取特征图张量各通道绝对值p次幂最大值
然后,计算教师网络和学生网络的特征图差异,并使其变小。
【网络Loss】:
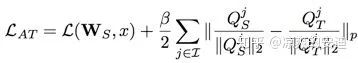

【思路2——Gradient-based attention transfer】:
Loss对输入X求导, 判断损失函数对于输入X的敏感性,pay more attnetion to值得注意的像素(梯度大的像素)
【网络Loss】:
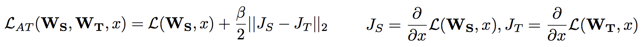

2-3 Relation Transfer
Relation Transfer——将网络或者样本的关系作为知识。该部分将主要介绍以下一篇paper:

2-3-1 《A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning》
【Meta info】:CVPR 2017,Cites: 144
【思路】:学生网络学习教师网络层与层之间的关系(特征关系),“授之以渔”。
【网络结构】:
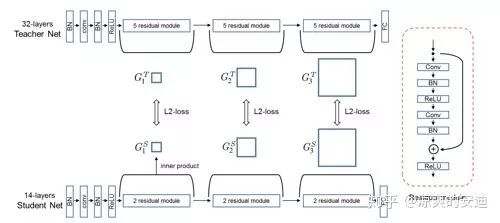
【实施】:
首先将Teacher网络和Student网络都分成n个part(两者分part的数量相同),每个part内包含几个卷积核池化层都是可以的,不过为了提升预估的效率,一般学生网络每个part的网络结构比教师网络简单。同时,保证学生网络和教师网络每个part的最后一个卷积层feature map的数量与下一个part第一个卷积层feature map的数量的数量相等;
定义”FSP matrix“用于衡量两层特征之间的关系,用前一层的特征图与下一层的特征图element-wise相乘并求和:

该步骤计算完毕后,可以得到一个m * n的 FSP matrix;
网络被分为了n个part,可以获取n-1个FSP matrix(上图中,分为了3个part,可以获取两个FSP matrix);
训练分为两个阶段:
第一个阶段,用FSP预训练学生网络的参数;
第二个阶段,用正常的分类loss优化学生网络。
【效果】:
在多个数据集上学生网络在参数减少很多的情况下,效果接近教师网络,且优于FitNets
2-4 Others
该部分将主要介绍以下的paper:

2-4-1 《KDGAN: Knowledge Distillation with Generative Adversarial Networks》
【Meta info】:NIPS 2018, Cites: 15
【背景】:
原始蒸馏网络中,学生网络难以学习到教师网络的所有“知识”,效果可能略差于教师网络
用对抗生成的方式模拟蒸馏的过程:生成器(学生网络,参数少、简单)负责基于输入X输出X的标签Y,判别器(教师网络,参数多、复杂)判断标签来自于学生网络还是真实的数据
前向计算时,只使用生成器,实现蒸馏的目的
【GAN】回顾:
GAN常用于图像生成:
经典GAN中,生成器G基于随机噪声生成图像;判别器D是一个分类器,判断图像是真实图像还是生成的。
最大-最小迭代训练:
固定G,用G的生成结果和真实数据优化D,使得V(D,G)尽可能大;
固定D,基于D的结果优化G,使得V(D,G)尽可能小;

KDGAN里作者提出了两种网络:NaGAN,KDGAN
思路1:【NaGAN】
【网络结构】(红框部分):

【实施】:

【优劣】:
KD需要样本少,但是通常不能保证学生网络的效果达到教师网络的程度;
NaGAN需要样本大于KD,但是通常可以使得学生网络效果和教师网络差不多。
思路2:【KDGAN】:
【网络结构】:

【实施】:
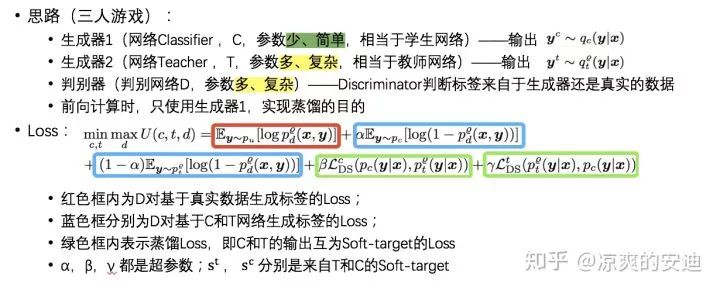
【训练过程】:
训练D:固定T和S,最大化似然函数。D更新时,希望将真实样本的标签判别为1;将C和T生成的标签判别为0,因此最大化D更新的损失函数;
训练T:固定D和S,最小化损失函数。损失函数分为两部分,第一部分为判别器D对于T生成的标签真实性的判别,T希望D判别的概率越小越好;第二部分为蒸馏Loss,T网络去拟合S网络输出的软目标;
训练S:固定D和T,最小化损失函数。损失函数分为两部分,第一部分为判别器D对于S生成的标签真实性的判别,S希望D判别的概率越小越好;第二部分为蒸馏Loss,S网络去拟合T网络输出的软目标。

迭代对抗训练。
2-4-2 《Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System》
【Meta info】:KDD 2018,Cites: 12
【背景】:
检索系统或者推荐系统中模型庞大,可以用蒸馏网络的方式提升工程效率;
目标是给一个query,预测检索系统的Top K相关的doc。
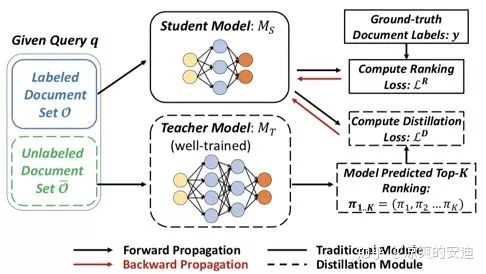
【思路】:
第一阶段训练教师网络,对于每个query预测Top K相关doc,补充为学生网络的Ground truth信息;
第二阶段教师网络的Top K作为正例加到学生网络中一起进行训练,使得学生网络和教师网络的预测结果更像。
【Loss】:
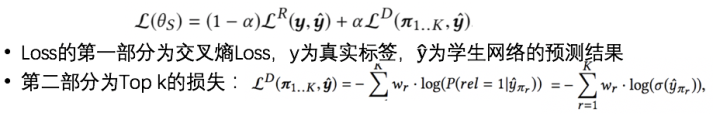
w_r为每条教师网络中预测的样本的权重,有两种方式生成:
对位置进行加权(即,Top 1到K的顺序);
对排序相关性进行加权(考虑教师网络预测的的Item与query的相关性程度)。
【网络结构】:
Discussion
简单回顾一下,把复杂模型或者多个模型Ensemble(Teacher)学到的知识→ 迁移到另一个轻量级模型( Student )上叫知识蒸馏;。知识蒸馏属于模型压缩、加速的一类,要求在模型变轻量的同时(方便部署),尽量不损失性能;后来也应用于模型表现的提升。
按照迁移知识的类型大致可以分为三大类:
Output Transfer——将网络的输出——Soft-target作为知识;
Feature Transfer——将网络学习的特征作为知识;
Relation Transfer——将网络或者样本的关系作为知识。
知识蒸馏提升了模型的工程表现,相对于其他模型压缩方式,如模型Int8而言,KD给了我们更多的想象空间,毕竟如DML等训练方式,可能在一定程度上提升模型的效果。
最后是一些Take Home Messages~

以上就是《知识蒸馏简述》的全部内容如果大家觉得有帮助,可以帮忙点个赞或者收藏一下,这将是我继续分享的动力~
参考文献
1. Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015, 14(7):38-39.
2. Tang R, Lu Y, Liu L, et al. Distilling Task-Specific Knowledge from BERT into Simple Neural Networks[J]. arXiv preprint arXiv:1903.12136, 2019.
3. Müller R, Kornblith S, Hinton G. When Does Label Smoothing Help?[J]. arXiv preprint
4. Zhang Y, Xiang T, Hospedales T M, et al. Deep mutual learning[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4320-4328
5. Furlanello T, Lipton Z C, Tschannen M, et al. Born again neural networks[J]. arXiv preprint arXiv:1805.04770, 2018.
6. Romero A , Ballas N , Kahou S E , et al. FitNets: Hints for Thin Deep Nets[J]. Computer Science, 2014.
7. Zagoruyko S, Komodakis N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer[J]. arXiv preprint arXiv:1612.03928, 2016.
8. Yim J, Joo D, Bae J, et al. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
9. Wang X, Zhang R, Sun Y, et al. KDGAN: knowledge distillation with generative adversarial networks[C]//Advances in Neural Information Processing Systems. 2018: 775-786.
10. Tang J, Wang K. Ranking distillation: Learning compact ranking models with high performance for recommender system[C]
11. Cheng Y, Wang D, Zhou P, et al. A survey of model compression and acceleration for deep neural networks[J]. arXiv preprint arXiv:1710.09282, 2017.
本文转载自公众号:深度传送门,作者:凉爽的安迪
推荐阅读
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。


