超详细干货 | 三维语义分割概述及总结
点“计算机视觉life”关注,置顶更快接收消息!
本文详细解析三维语义分割的几个主流方案,文末给出了对比
作者任浩帆,杭州电子科技大学智能信息处理实验室大三学生。长江后浪推前浪啊
文中含大量链接,因公众号限制无法显示,可在文末点阅读原文查看
本文提纲:
0. 三维表示的数据结构0.1. Point cloud0.2 3D voxel grids0.3 collections of images/muti-view0.4 polygon1. PointNet1.1 提升准确度的关键步骤1.1.1. 解决无序性1.1.2. 解决几何旋转问题1.2 网络结构1.3 结果2. PointNet++2.1 网络结构2.2 自适应的特征提取层2.2.1 MSG(Multi-scale grouping)2.2.2 MRG(Multi-resolution grouping 2.3 特征传播2.4 结果3. PointSIFT4. SPG4.1 geometric partition
4.2 构建SPG 4.3 得到上下文特征
4.4 上下文分割
5. 3P-RNN 5.1 Pointwise pyramid pooling
5.2 RNN for context ensemble
6. pointwize 7. 效果比较 8. 总结
语义分割需要两部分
classification: 需要全局信息
segmentation:更加依赖全局信息和局部信息
一般的网络结构是:
提特征-特征映射-特征图压缩(降维)-全连接-分类,其实就是encoder-decoder的过程,比如在二维的的pspnet,fcn等等, 可能还有CRF去调整
0. 三维表示的数据结构

0.1. Point cloud
本质是对三维世界几何形状的低分辨率重采样,因此只能提供片面的几何信息 点云的一些feature:
1. normal 法向量
2. intensity 激光雷达的采样的时候一种特性
强度信息的获取是激光扫描仪接受装置采集到的回波强度,此强度信息与目标的表面材质、粗糙度、入射角方向,以及仪器的发射能量,激光波长有关
3. local density 局部稠密度
4. local curvature 局部曲率
5. linearity, planarity and scattering propesed by [this paper]Dimension- ality based scale selection in 3D lidar point clouds
6. verticality feature proposed by Weakly supervised segmentation-aided classification of urban scenes from 3d LiDAR point clouds
无序性点云实际上是无序的,比如有8个点云,你放到矩阵里面,是有顺序的,但是实际上打乱顺序也都表示的是同样的一个点云。换句话说,
不同的矩阵表示的是同一个点云,而你分割的结果肯定不可能对于不同的输入表示矩阵,结果不一样。
如果有N个点,就需要对N!permutations invariant
解决方法:
sorting
但是实际上不存在这样一个稳定的从高纬度到1维度的映射
RNN
数据的一些抖动也得到了增强
symmetric function
几何旋转性:相同的点云在空间中经过一定的刚性变化(旋转或平移),坐标发生变化。 不论点云在怎样的坐标系下呈现,网络都能正确的识别出。这个问题可以通过STN(spatial transform network)来解决。二维的可以看一下这个,实际上就是一些放射变换之类的。
Point cloud rotations should not alter classification results抽密度不均匀采样的时候,点云的稠密度,一般是不一样的,距离镜头近的物体点云稠密度比较大,距离远的比较稀疏。如下图:

也有一些方法去解决这种问题,比如PU-Net: Point Cloud Upsampling Network这几点就要求在点云的处理过程要非常的鲁棒。
不规则性点云不像grid和pixel,有很规范的格式,所以并不能直接的采用CNN,这是一个很严重的问题。当然也有一些提出一些直接能够对点云做操作的网络,
Pointwise Convolutional Neural Networks Binh-Son,但是从效果看起来,似乎比pointnet要差一些,但是不是差的特别大,有些地方有略超过pointnet的地方,但是我觉得计算量。。。。。。。会很大
还有一些方式比如就是将点云转换成其他方式,SegCloud uses 3D con- volutions on a regular voxel grid,但是点云转换成volme的方法效率很低,而且这个过程丢失掉一些细节
0.2 3D voxel grids
类似二维的三维卷积,是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了;
体素的方式呢,SPG的作者认为do not capture the inherent structure of 3D point clouds
相关方法:Subvolume, voxelnet
0.3 collections of images/muti-view
这样的好处是可以直接采用一些二维的算子去处理,特征被view pooling procedure聚合起来形成三维物体;常见方法MVCNN
0.4 polygon
可以运用一些mesh的表达和合适的算法,比如三角剖分等等。
这三种数据结构是可以相互转换的,但是貌似三维结构的表示相互转换,时间复杂度比价高
1. PointNet
主页 | 论文 | 补充材料 | Code | 会议报告讲解论文视频 | 作者答疑解惑 | 作者中文讲解视频 | Open3D-PointNettime:Dec 2, 2016
Input: coordinates(x,y,z)
Output: labels. added by computing normals and other local or global features
在这个网络之前其他的方式都是对三维数据表达进行转换变成规则, 比如:
voxelization ----- 3D CNN
Projection/rendering --- 2D CNN
1.1 提升准确度的关键步骤
1.1.1. 解决无序性
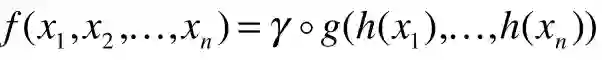
用来解决unorder set的问题。所谓对称函数,比如f(x1,x2) = x1 + x2, 互换x1,x2不影响结果。就是unorder set问题的一个数学表述
h:特征提取
g是simple symmetric function
r是更高维度的特征提取
在Fig5中,测试了三种方法,最后发现max pooling对解决无序性效果最好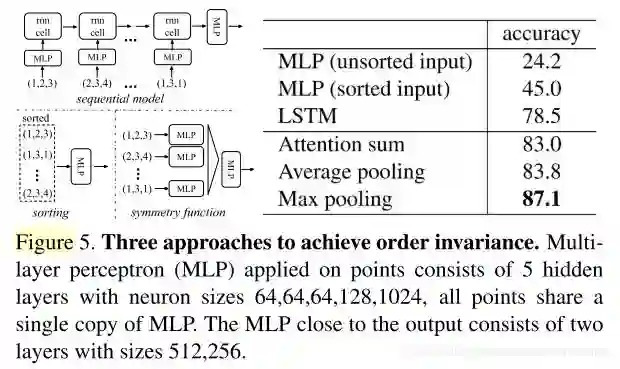
Fig5是关于选取不同g对于结果的如何影响。以下是经过实验论文采用的方法
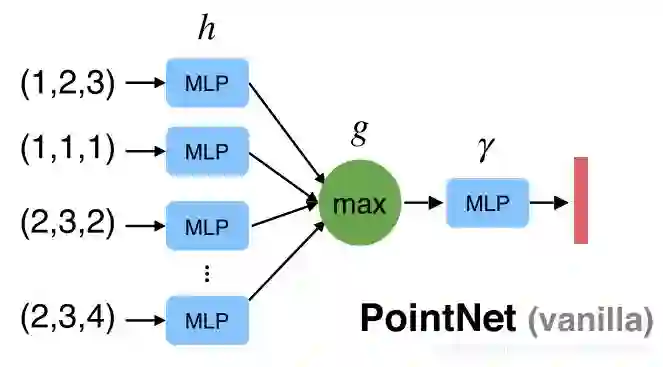
1.1.2. 解决几何旋转问题
背景我们知道对于多维空间,只要找到一个合适的旋转矩阵和平移矩阵这两个矩阵就可以构成一个仿射变换(齐次坐标可以将这两个变换表示成一个矩阵),但是点云分割是一个多分类的问题,平移对于整体的点云分类影响不是很大,你可以理解一个向量在原点,和将平移一下,他的指向是不会变的。(形象化的展示可以看《线性代数的几何意义》)
所以如果是点云是这样一个矩阵 A = N x M
N:表示点云有N个点
M:表示点云的feature,可以是坐标,x,y,z,这样的话就是3列,还可以有在0.0中提到的一些其他feature,比如法向量之类的。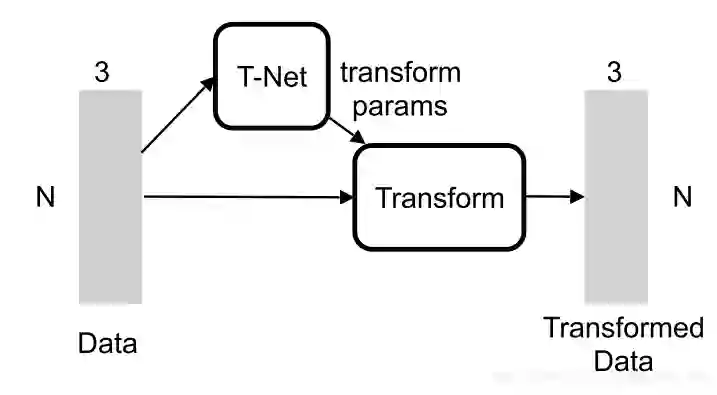
或者右乘一个矩阵C = M x M 的矩阵也可以对A矩阵做旋转变换
B和C都是方阵是为了保持变换之后我们的点云矩阵A维度不变,不损失信息。区别仅仅在于B是对矩阵的行空间做变换,C是对列空间做变换。
按照之前的说法,点云的无序性就是行空间不一样,具体的说就是矩阵A第i行和第j行互换,但是表示的点云是一样的。所以对于A左乘B做行空间的变换没有意义。所以我们如果要旋转的话要用矩阵C对列空间进行变换,而我们知道最后分类是通过点云列空间上那个class的值最大去判断输入哪一个类别的。所以列空间的变换是真正有意义的
这篇论文用了一个网络T-net去两次拟合这个矩阵C
原生输入变换这里做转换的原因应该是为了让网络在做初步的特征提取前的,一个预处理
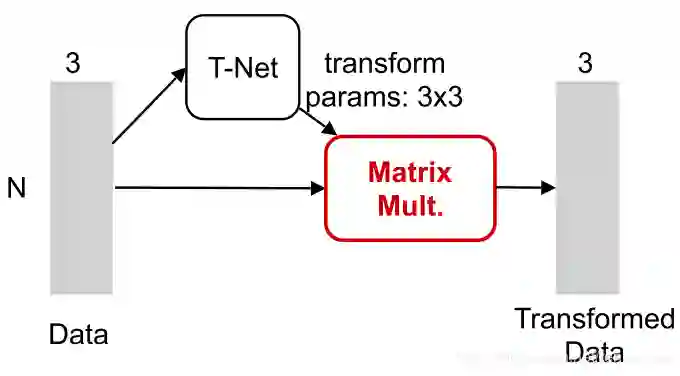
特征转换(Embedding Space Alignment)根据网络的整个pipeline,这里是为了在较低特征维度的层面上经过一个类似activation function的作用,找到一个合适的超平面,让网络之后能够学习到更好的特征。类似二维的这里
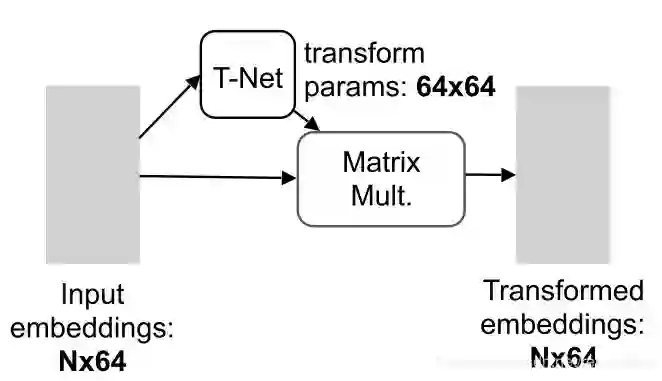

这个正则项的意思是使得那个旋转矩阵要尽可能接近于一个正交矩阵。论文里面说,因为在特征空间里面的转换矩阵的维度要远远比原生空间里面的转换矩阵维度高很多,具体就是64*64 > 3*3。因为纬度高所以优化的难度大,所以加入了这个正则项。(A is the feature alignment matrix predicted by a mini-network. An orthogonal transformation will not lose information in the input, thus is desired)
思考我觉得实际上有些奇怪,我们知道旋转矩阵本身就是正交矩阵是为了保持旋转前后模长不变,那为什么之前那个变换没有加这个正则呢?可能作者做过时间,对效果可能没影响,或者影响不大,反而增加了时间复杂度。
但是这个正则项的影响,在论文中的Robustness test测试的时候是准确度提高了0.5% 其他的两个变换,加和没加对准确度的影响如下:

可见想法很好,但是提高并不是非常明显。但是论文作者觉得加入了正则项之后(We find that by adding the regularization term, the optimization becomes more stable and our model achieves better performance)
1.2 网络结构
我记得之前看到,kolmogorov理论指出,了对于分类问题,理论上只要两层hiddenlayer的mlp就足以解决任意复杂的分类问题
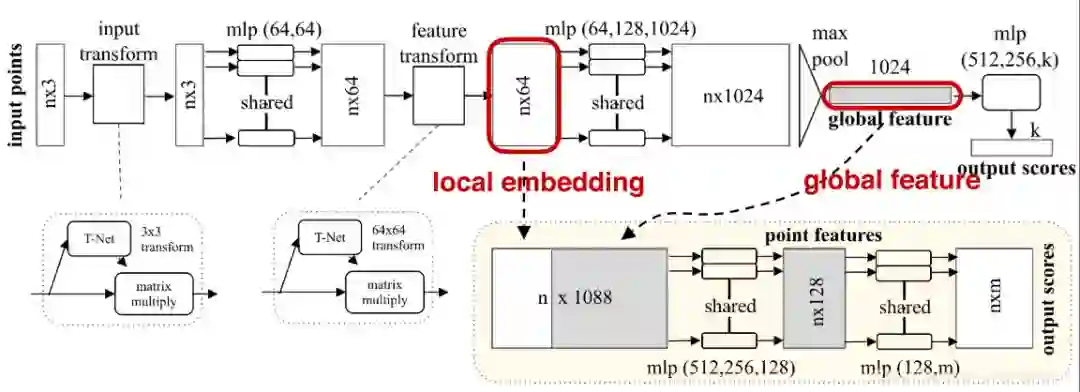
输出两个score,一个只是简单的分类,另一个score是将类别具体做确定,确定具体属于哪一类
1.3 结果
时间复杂度:0(N),N是点云个数处理速度经验估计大概:每秒100万个点用1080x GPU,这个速度相当的快point cloud classifica- tion (around 1K objects/second) or semantic segmentation (around 2 rooms/second)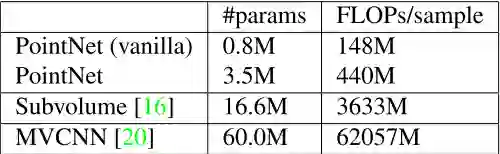
2. PointNet++
上海交大的工作。核心贡献就是提出了一个3d-sift的submodel,文章里有很详细的算子说明,这里就不多做介绍了。
主页 | 论文 | code | Open3D-PointNet2-Semantic3Dtime:Jun 7, 2017
Pointnet++是在pointnet基础上改进的。解决了pointnet在局部特征上提取的不足。我们先来看一下效果
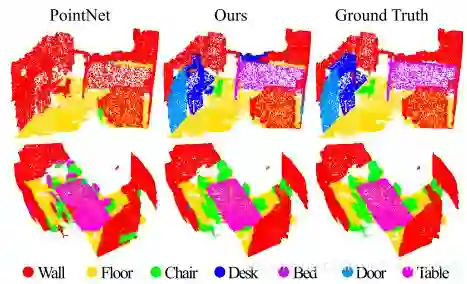
2.1 网络结构
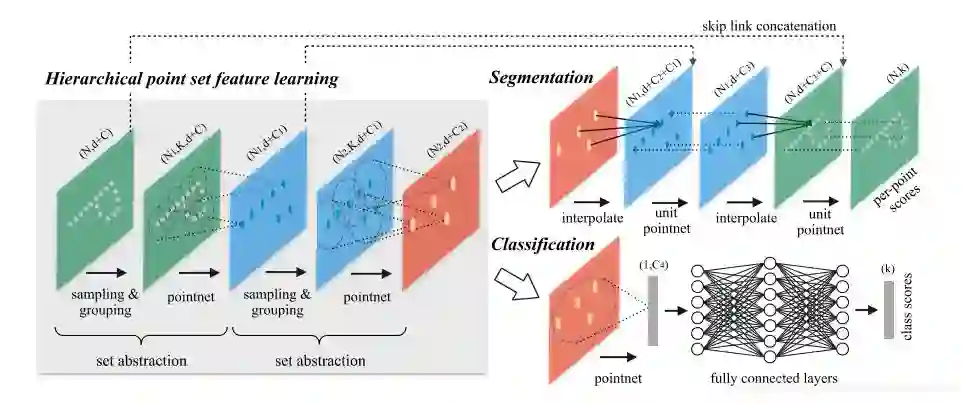
论文中的特征提取大部分使用poinenet去做的。poinet(vanilla)就相当于point++的一层
网络的输入和输出:input: ,N points withe d-dim coordinates and C-dim point featureoutput:
Sampling layer -- defines the centroids of local regions
input:
output: 这里因为是局部区域的质心,所以N‘就代表了N’个局部区域的N‘个质心
innovation
1.在质心数量相同的情况下,用FPS去采样,比随机采样能够更好的覆盖整个点集
2.和CNN去扫描向量空间的数据空间分布来讲, FPS产生的感受野是相对独立,因为是最远点。
Grouping layer -- constructs local region sets by finding “neighboring” points around the centroids
CNN, 每个降采样的像素点都是有临近的像素,构成的,所以决定点的领域取决于你的metric distance
Ball query可以通过设置一个上线,找到邻域内的所有点
KNN找到邻域内的固定数量的点.
Compared with kNN, ball query’s local neighborhood guarantees a fixed region scale thus making local region feature more generalizable across space, which is preferred for tasks requiring local pattern recognition (e.g. semantic point labeling).
input: ,
output: groups of point with size of
each group corresponds to a local region
K is the number of points in the neighborhood of centroid points
K varies across groups but the succeeding PointNet layer is able to convert flexible number of points into a fixed length local region feature vector.
Approaches for grouping
PointNet layer -- encode local region patterns into feature vectors.
input:
output:
再输入pointnet之前,我们先要先要把局部区域的坐标做一个线性变换,so that we can capture point-to-point realations in the local region
2.2 自适应的特征提取层
为了解决点云抽密度不均匀的问题
2.2.1 MSG(Multi-scale grouping)

质心:一个局部领域里面的所谓中心位置的点,就是把N个点坐标加起来除以N。
对于每一个质心,通过学习多尺度的特征,能更好的学习fine-grained patterns。在训练的过程当中,随机的丢弃掉了一些点。所以就能让网络对不同的稠密度有鲁棒性但是这样的计算量是比较大的,对于每一个质心,都需要去遍历。
2.2.2 MRG(Multi-resolution grouping (MRG)
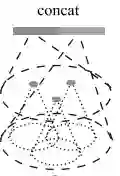
假设concat下面的vector左边的那个是 层经过特征提取的,右边是 层经过pointnet得到的的。 表示的是质点, 层表示的是没有经过上采样的点。如果说点云本身比较稀疏的话,那么左边的特征提取意义不大,因为如果本身稀疏的话,那么你上采样之后就会变得更加稀疏。所以对原生的特征提取更加意义。反之亦然。
点云稀疏的时候,后边的权重增加,左边的权重减小。点云稠密的时候,后边的权重减小,左边的权重增加。
2.3 特征传播
因为我们提取到的是质点的一些特征,我们在这个过程中随机丢掉了一些点。所以我们要想办法去得到每一个点的特征。一个方法就是把每一个点当成质心,这。。。你懂得。所以我们采用差值的方法去和我们上采样质心之前的层去比较,让二者尽可能近似。论文选用的插值方法是:inverse distance weighted average based on k nearest neighbors
最后连接特征的时候用了unit pointnet,作用类似与1*1卷积
2.4 结果
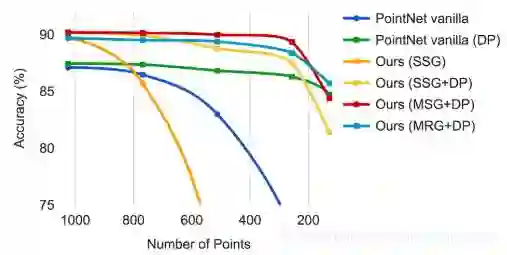
3. PointSIFT
主页 | 论文 | codeJul 2, 2018
在SA步骤,不使用pointnet++的方式,也能够去抓取更好的点。
在平面sift的情况,检测到一个极值点之后16*16,分成4份,总计每个像素的梯度方向,合成一个组。
类似的就是将每一个点周围分成八个子领域,实现方向性,尺度的话,就是多次叠加人这个层。
其他的一些网络,再降采样的过程中丢失了更多的点,而Pointsitft可以抓取更多有效的点。
4. SPG
论文 | codeMar 28, 2018
这篇论文采用的是无监督的方式去做的,当然也用到了PointNet。但是采用超点了广义最小割的方法去解决这个问题,想法可以说是非常好的一种方式。
superpoint graph<font color=red>这种表达方式非常好,只有可以研究一下这篇文章的先验文章,related work 之后再重新看一下</red>
SPG一种能很好的表示点云的组织形式的结构,能很好的表达图像的上下文关系。通常的场景的点云有百万级别个点,但是用SPG可以在保持丰富特征的前提下,降采样到几百个点,这样就可以用一些pointnet之类的去处理。
SPG本质就是一种广义的有权有向图。节点表示一些简单的形状,边描述了丰富的边缘特征来表述的邻接关系。(Its nodes represent simple shapes while edges describe their adjacency relationship characterized by rich edge features.)
整体流程

4.1 geometric partition
这一步得到的应该是superpoints,这一步你可以理解成一个局部的聚类,但是并不在意能不能检索到物体,实际上相反,是将物体拆分成一些简单的几何形状,每一个几何形状实际上就代表一个superpoint,或者说是semantically homogeneous 看一下这张图片就明白了:
根据结果来看,貌似是可以适应的去确定一个superpoint中的raw points的多少,也就是一个局部的聚类。Another advantage is that the segmentation is adaptive to the local geometric complexity.In other words, the segments obtained can be large simple shapes such as roads or walls, as well as much smaller com-ponents such as parts of a car or a chair。
文章是借用了【Weakly Supervised Segmentation-Aided Classification of Urban Scenes from 3d LIDAR Point Clouds】里面的能量函数去做的
the global energy: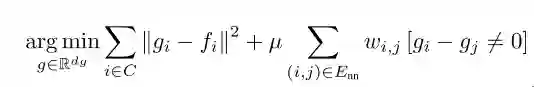
4.2 构建SPG(superpoints graph)
数学表达: S: superpoints : adjacency bwtween superpoints referred to as superedges : superedge 的feature,具体文章中这个feature用了很多,见Table1
4.3 得到上下文特征(contextual info)
首先先得到每一个superpoints的descriptor,通过embedding到一个固定维度的向量 当中,每一个superpoints的嵌入都是孤立的。
我们只使用graph convolution去得到contextual info。在动态降采样大np=128的点,少于np的superpoints将会被代替,实际上由于maxpool的影响,是没关系的,但是实际过程中very small superpoints of less than nminp = 40 points in training harms the overall performance。
输入pointnet之前:normalized position、 observations oi、 geometric features fi输出pointnet之后:the original metric diameter of the superpoint is concatenated to stay covariant with shape sizes.
4.4 上下文分割
终于到了最后一步,这里就是最后一步,分类的问题。
分类的对象是:用向量表示的抄点,和他在SPG中的local surroundings。这一步用了两个很重要的graph convolution:
Gated Graph Neural Networks2016
Edge-Conditioned Convolutions (ECC)2017
5. 3P-RNN
论文Pointnet使用mlp去对每一个点单独的产生local feature,之后通过symmetric max pooling去产生global feature, which is invariant against the permutations of points。但是有两个缺点:
failing to capture local structures represented by neighboring points
a point cloud is first subdivided into small volumetric blocks and each block is predicted independently without any connection
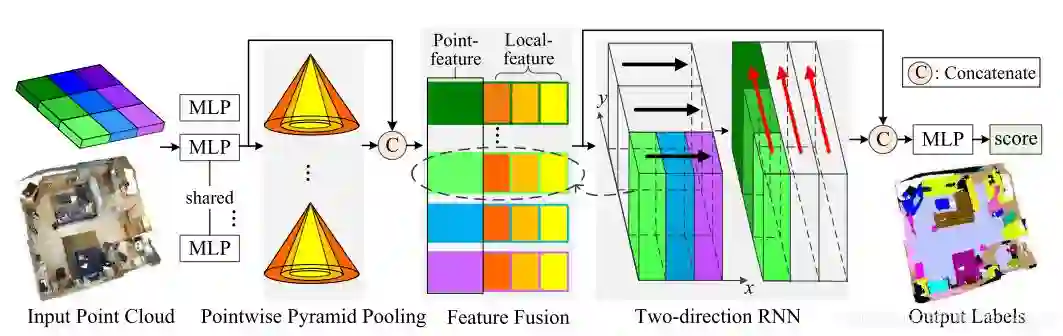
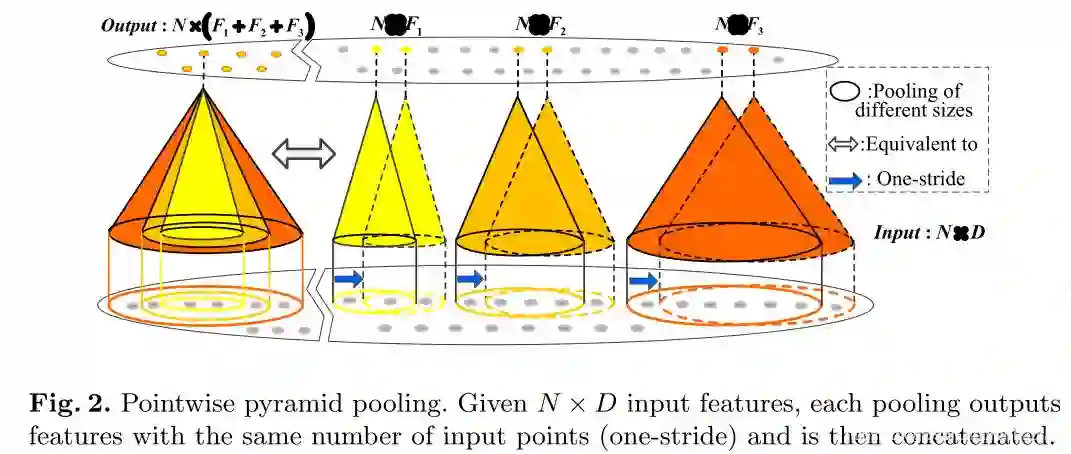
5.1 Pointwise Pyramid pooling
在pointnet,当中


f是MLP提取到的高级特征。ki denotes one-stride pooling window size。相比于pointnet来讲,这样做的好处是通过one-stride pooling,可以产生和输入点同样大小的vector,就是输入是
输出是:
,这样很显然抓取到了更好的local feature
5.2 RNN for context ensemble
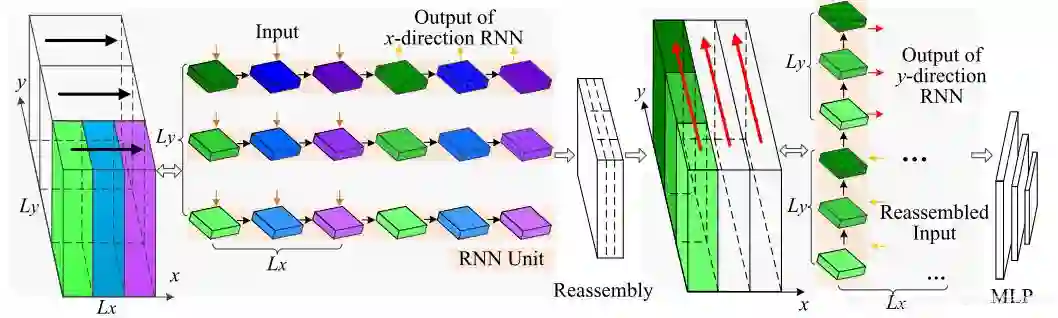
6. pointwize
论文 | code29 Mar 2018
效果和pointnet相比总体来讲略差,而且时间复杂度很高。看了一些结果semanticfusion的准确度在floor和table的准确度相对来讲要高一些。
卷积算子:

7. 效果比较
S3DIS为例子:
| Method | OA | mIoU |
|---|---|---|
| PointNet-----2 Dec 2016.V1 | 78.62 | 47.71 |
| 3P-RNN------September 2018 | 86.9 | 56.4 |
| SPGraph-----27 Nov 2017.v1 | 85.5 | 62.1 |
| PointSIFT-----------2 Jul 2018.Submitted | 88.72 | 70.23 |
| Pointwise | 56.5 | 81.5 |
8. 总结
总结一下,直接对三维信息做语义分割,有一些方法,本文对点云的处理做了一些总结,可以看到基本上都是对pointnet做的一系列的改进。改进的方向基本在于如何更好的得到局部的信息。但是算力仍然是一个严峻的问题,要想达到实时的效果,只依靠算法的改进恐怕很难,而且点云的这种表达方式,有着两个致命的缺点:一是噪声无法避免,二是数据量过于庞大。18-19年有一些点云分割相关的工作,但是似乎并没有一些很好的解决这些问题,还是在pointnet之后顺延的一些想法。值得注意的是18年ECCV有一篇depth-aware cnn的paper,在基本不增加计算量和参数量的前提上,成功的将depth和color image有效的融合在一起去提高二维图片的分割精度。这可以看作是将depth的三维信息fusion到二维当中提高了二维语义分割的精度。从这个角度来讲,depth是应该比point cloud更好的方式。另外值得关注的一个现象是,二维的语义分割通过depth投影到三维和接处理点云做语义分割相比,效果会非常差,反过来,语义分割好的点云投影到二维之后,从二维来看,分割效果也非常差,尤其是边缘信息。这其实也说明三维和二维实际上还是差别很大,不知道之后会不会有人一些类似于平面约束的方式去改善投影与反投影的效果。另外与slam相结合,构建语义地图的相关工作或者替代其中一个模块,比如semanticfusion,就是用二维分割再投影到三维,fusion++利用maskrcnn检测的物体做landmark,进行回环检测。类似的工作实际上都是用的二维投影三维,因为对于slam讲landmark可能不要求像素级别那么精细。总结起来,之后可能对于三维直接分割来讲,速度可能是一个比较难以解决的问题,可能的思路就是利用SPG的先聚类的方式降低复杂度,但是这就要求要有比pointnet速度更快的方式。另外从工程和经济成本上讲,是否有比较直接对三维物体做精细的语义分割也有待商榷。
推荐阅读

欢迎关注公众号:计算机视觉life,一起探索计算机视觉新世界~
觉得有用,给个好看啦~





