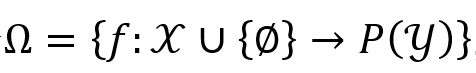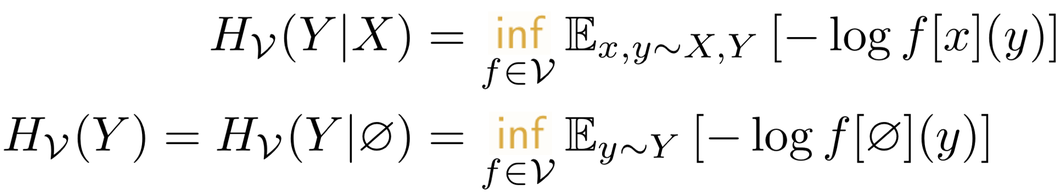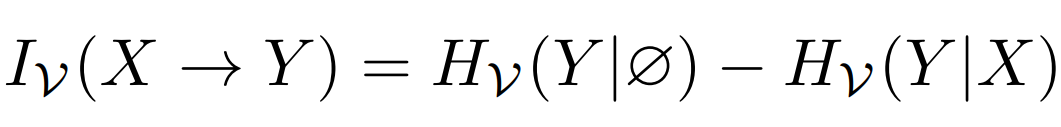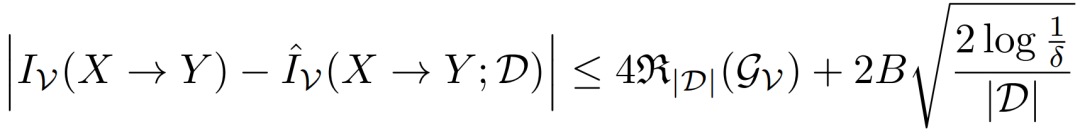编辑 | 丛末
本文是对 ICLR 2020 oral 论文《基于计算约束下的有用信息的信息论 (A Theory of Usable Information Under Computational Constraint)》的解读。
该论文由
北京大学2016级图灵班本科生许逸伦
,斯坦福博士生Shengjia Zhao, Jiaming Song, Russell Stewart,和斯坦福大学助理教授Stefano Ermon合作完成。在审稿阶段中
,该论文获“满分”接收
。
![]()
Arxiv Link: https://arxiv.org/abs/2002.10689
Openreview Link: https://openreview.net/forum?id=r1eBeyHFDH
香农互信息(Mutual Information)是一套影响深远的理论,并且在机器学习中的表示学习(Representation Learning)、信息最大化(Informax)、对比预测性编码(Contrastive Predictive Coding)与特征性选择;和结构学习(Structure Learning)中的贝叶斯网络的构建,均有广泛应用。但香农信息论没有考虑很重要的计算约束方面的问题,并假设了我们有无穷的计算能力。为了突出这个问题,我们考虑以下这个密码学中的例子。
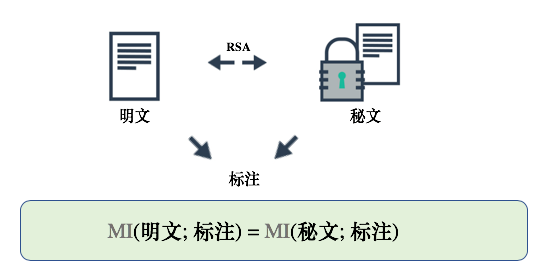
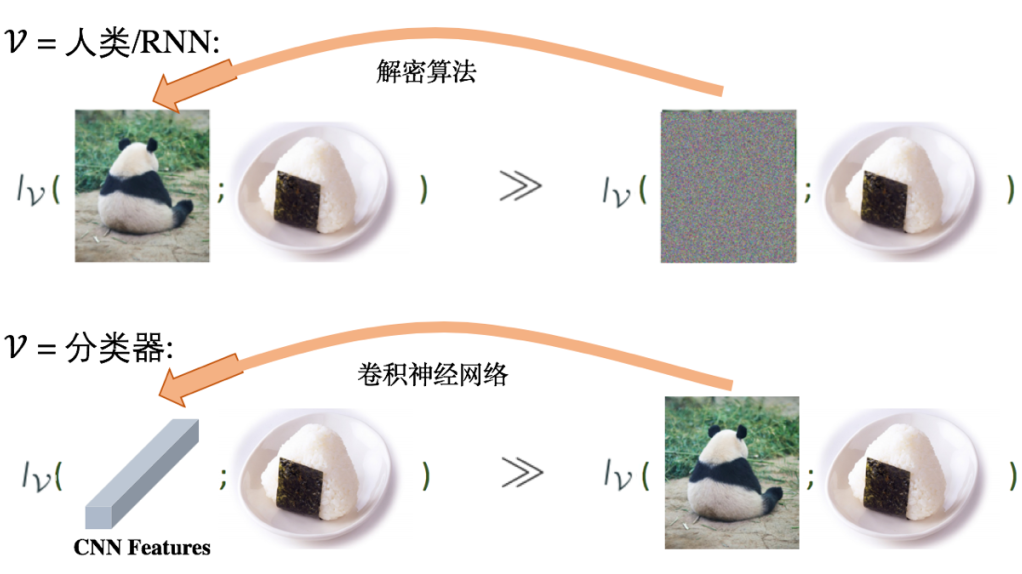
在我们的例子中,有一个带标注的明文数据集,同时有一个相对应的 RSA 加密后的秘文数据集。如果 RSA 的公钥已知,那么由于 RSA 是双射的,根据互信息在双射下的不变性,明文与秘文应该与其标注有着相同的互信息,如下图所示:
为了更直观地理解其中的不合理性,我们用相应的图片分别表示明文和秘文,如下图所示,加密后的图片看起来就像随机采样产生的噪声图片。
但是对于人类(或机器学习算法)来说,根据明文去预测标注显然比根据秘文去预测更容易。因此我们认为,在人类看来,明文与标注有着更大的互信息,但这与香农互信息矛盾。这个矛盾背后的原因正是因为香农互信息假设了观测者有无穷的计算能力,从而忽视了什么是对于观测者来说的有用信息。
另一个例子是,由香农互信息的数据处理不等式(data processing inequality)我们知道,神经网络的深层表示(CNN feature)与标注的互信息应少于原始输入与标注的互信息。但是在简单的分类器看来,深层表示与标注的互信息更大。
因此,香农互信息对无穷计算能力的假设与对基于观测者的有用信息的忽视带来了许多反直觉的例子。
除此之外,本文还证明了现有的对香农互信息的变分估计量(NWJ, MINE, CPC)或者有较大的方差,或者有较大的估计误差,比如 NJW 估计量的误差可以到互信息量的指数级别。
基于以上提到的香农信息论的缺点,本文利用变分 (variational)的思想提出了一种显示地考虑计算约束的信息量,并称之为 V(ariational)-information。
这个集合包含所有把一个随机变量 X 的具体取值映射到另一个随机变量的取值域上的概率测度 P(Y)。
什么是计算约束呢?首先见下面我们对条件 V-熵(conditional V-entropy)的定义(其中我们省去了不重要的预测族(predictive family)的定义,它本质上是加了些正则条件,感兴趣的小伙伴可以看下原 paper):
定义(条件 V-熵):X, Y 是两个取值在 X, Y 的随机变量,V ⊆ Ω 是一个预测族,则条件 V-熵的定义为:
计算约束体现在观测者被限制为 V ⊆ Ω,即取全集 Ω 的一个子集合 V。由于 V ⊆ Ω,因此定义中的 f[x] 是一个概率测度,f[x](y) 是该概率测度(如概率密度函数)在 y 处的取值。
直观地来看,条件 V-熵是在观测到额外信息 X 的情况下,仅利用函数族 V 中的函数,去预测 Y 可以取到的期望下最小的负对数似然(negative log-likelihood)。同理定义 V-熵,也就是没有观测到额外信息(用 ∅ 表示)的情况下,利用 V 中的函数去预测 Y 可以取到的期望下最小的负对数似然。
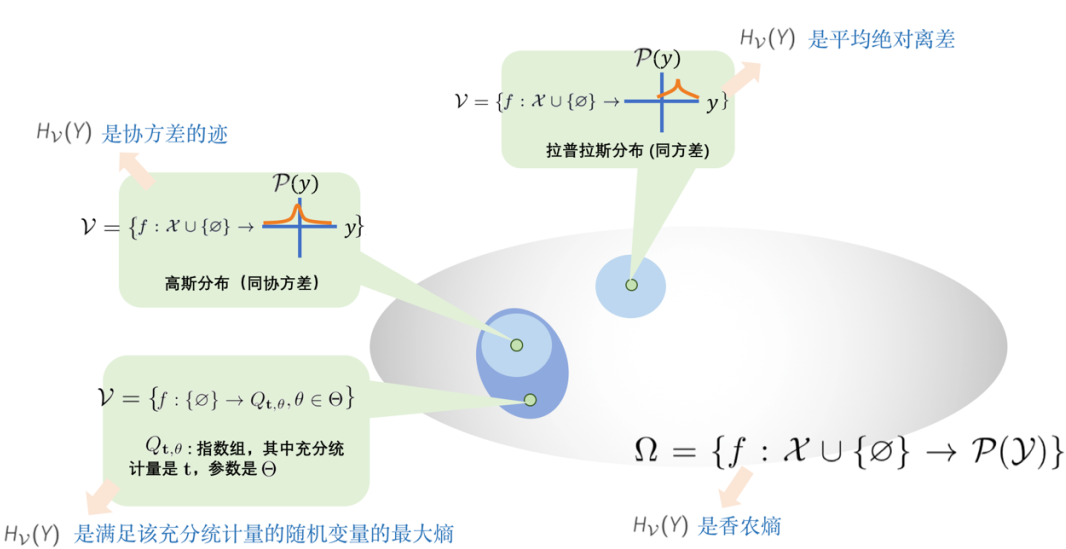
下面我们展示,通过取不同的函数族 V,许多对不确定性的度量 (如方差、平均绝对离差、熵)是 V-熵的特例:
接着类似于香农互信息的定义,我们利用 V-熵来定义 V-信息:
定义(V-信息):X, Y 是两个取值在 X, Y 的随机变量,V ⊆ Ω 是一个预测族,则 V-信息的定义为:
即从 X 到 Y 的 V-信息是 Y 的 V-熵在有考虑额外信息 X 的情况下的减少量。我们也证明了决定系数、香农互信息均为 V-信息在取不同函数族 V 下的特例。我们还证明了 V-信息的一些性质,比如单调性(取更大的函数族 V,V-信息也随之增大),非负性与独立性(X, Y 独立则 V-信息为0)。
此外我们展示,通过显示地考虑计算约束,在 V-信息的框架下,计算可以增加 V-信息,即增加对观测者而言的有用信息:
同时,注意到 V-信息是非对称的,它可以很自然地用到一些因果发现或者密码学(如 one-way function)的场景中。
不同于香农互信息,在对函数族 V 的一些假设下,本文证明了 V-信息在有限样本上的估计误差是有 PAC 界的:
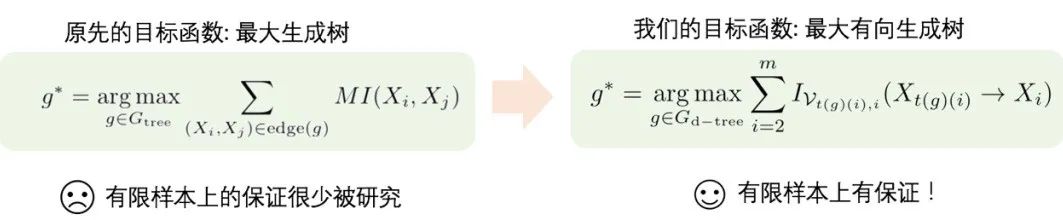
这个 PAC 界启发我们将 V-信息用于一些使用香农互信息的结构学习的算法中。我们发现这些之前在有限样本上没有保证的算法,迁移到 V-信息下就有了保证。比如 Chow-Liu 算法就是一例:
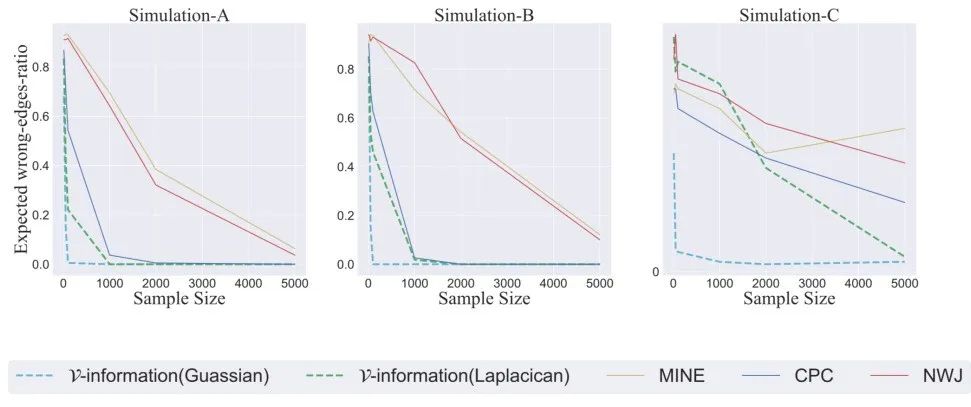
本文通过实验验证了新的基于 V-信息的算法构建 Chow-Liu Tree 的效果,优于利用现存最好的互信息估计量的 Chow-Liu 算法。
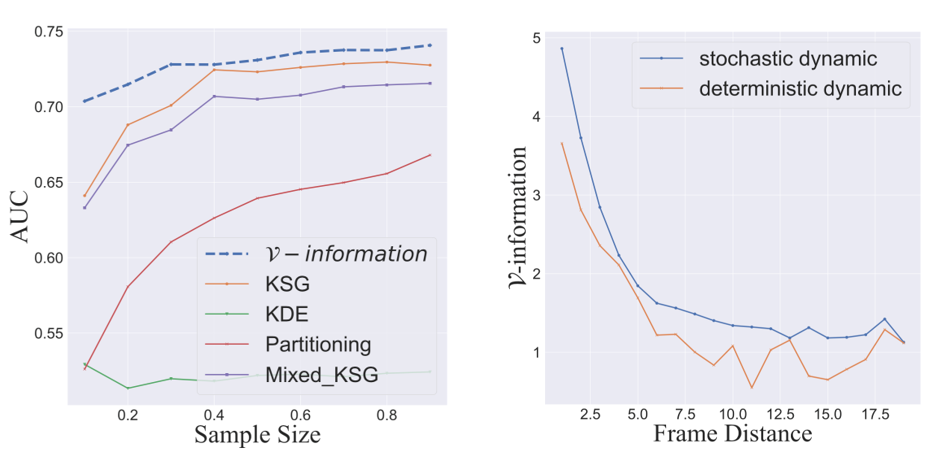
我们也将 V-信息用到了其他结构学习的任务中,如基因网络重建(下左图)和因果推断(下右图)。
注意到与一些非参数化的估计量(如 KSG, Partitioning 等)相比,我们的方法在低维基因网络的重建中取得了更好的效果。同时我们的方法在因果推断的实验中正确地重建了时序序列。在确定性的时序轨迹 (deterministic dynamics)下,香农互信息是无法重建时序序列的。
最后,我们将 V-信息应用到公平表示(fairness)上。若VA, VB 是两个不同的函数族,我们发现实现 VA-信息最小化的公平表示不一定能泛化到 VB-信息最小化。这一发现挑战了许多现有文献的结果。
本文提出并探索了一种新的信息框架 V-信息。V-信息包含了许多现有的概念,并且有许多机器学习领域喜欢的性质,比如对信息处理不等式的违背与非对称性。V-信息可以被有保证地估计好,且在结构学习中有着优异的表现。