论文浅尝 | 5 篇顶会论文带你了解知识图谱最新研究进展
本文转载自公众号:PaperWeekly。
精选 5 篇来自 ICLR 2019、WSDM 2019、EMNLP 2018、CIKM 2018和IJCAI 2018 的知识图谱相关工作,带你快速了解知识图谱领域最新研究进展。

■ 论文解读 | 张文,浙江大学在读博士,研究方向为知识图谱的表示学习,推理和可解释
本文是我们与苏黎世大学合作的工作,将发表于 WSDM 2019,这篇工作在知识图谱的表示学习中考虑了实体和关系的交叉交互,并且从预测准确性和可解释性两个方面评估了表示学习结果的好坏。
模型
给定知识图谱和一个要预测的三元组的头实体和关系,在预测尾实体的过程中,头实体和关系之间是有交叉交互的 crossover interaction,即关系决定了在预测的过程中哪些头实体的信息是有用的,而对预测有用的头实体的信息又决定了采用什么逻辑去推理出尾实体。
文中通过一个模拟的知识图谱进行了说明,如下图所示:
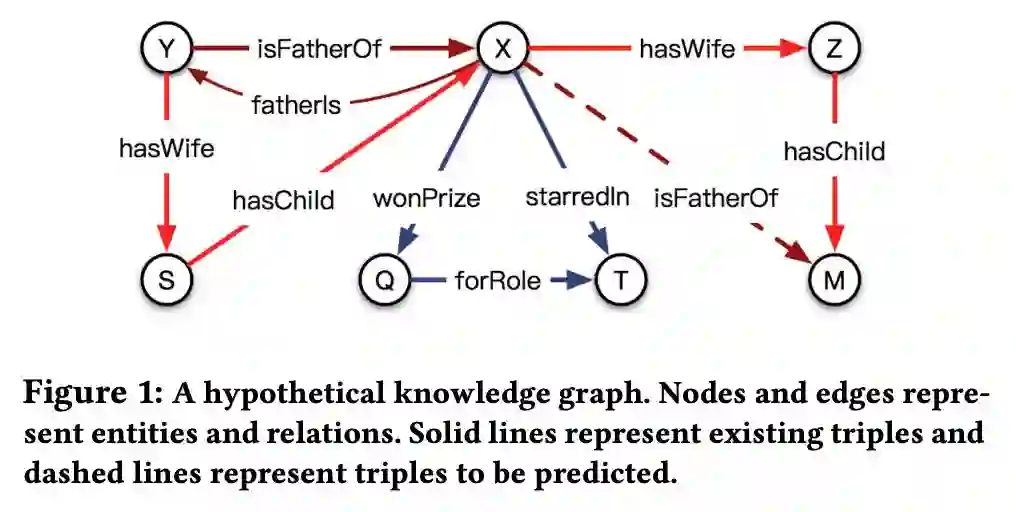
基于对头实体和关系之间交叉交互的观察,本文提出了一个新的知识图谱表示学习模型 CrossE。CrossE 除了学习实体和关系的向量表示,同时还学习了一个交互矩阵 C,C 与关系相关,并且用于生成实体和关系经过交互之后的向量表示,所以在 CrossE 中实体和关系不仅仅有通用向量表示,同时还有很多交互向量表示。
CrossE 核心想法如下图:
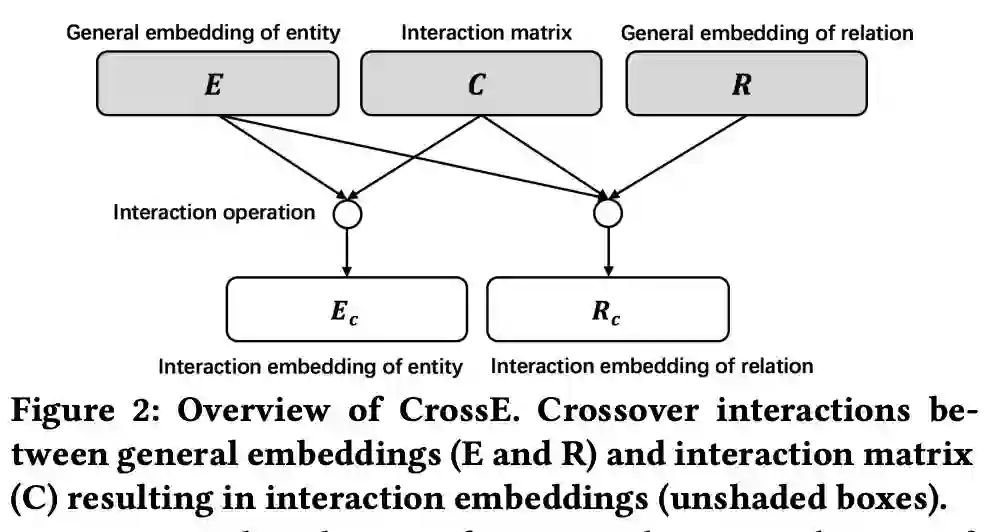
在 CrossE 中,头实体的向量首先和交互矩阵作用生成头实体的交互表示,然后头实体的交互表示和关系作用生成关系的交互表示,最后头实体的交互表示和关系的交互表示参与到具体的三元组计算过程。
对于一个三元组的计算过程展开如下:
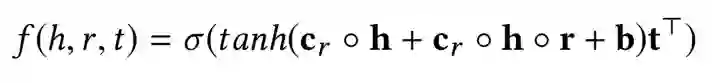
实验
实验中本文首先用链接预测的效果衡量了表示学习的效果,实验采用了三个数据集 WN18、FB15k 和 FB15k-237,实验结果如下:
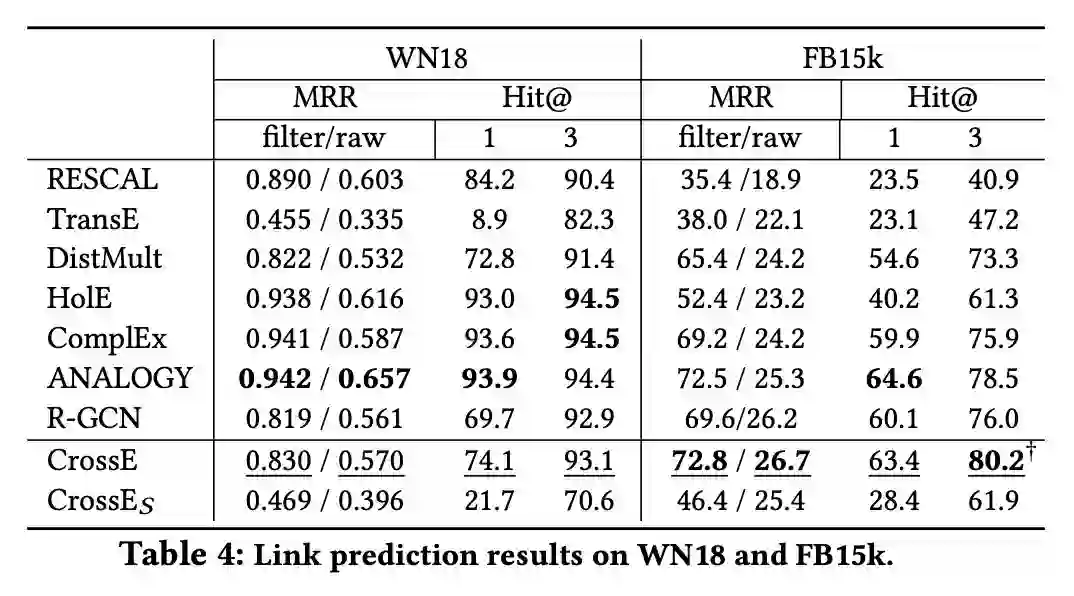
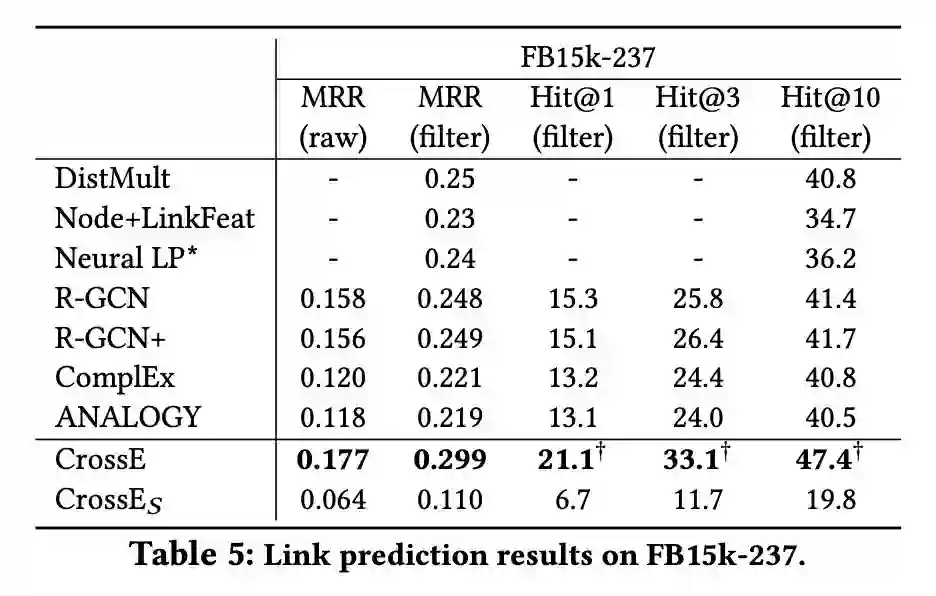
从实验结果中我们可以看出,CrossE 实现了较好的链接预测结果。我们去除 CrossE 中的头实体和关系的交叉交互,构造了模型 CrossES,CrossE 和 CrossES 的比较说明了交叉交互的有效性。
除了链接预测,我们还从一个新的角度评估了表示学习的效果,即可解释性。我们提出了一种基于相似结构通过知识图谱的表示学习结果生成预测结果解释的方法,并提出了两种衡量解释结果的指标,AvgSupport 和 Recall。
Recall 是指模型能给出解释的预测结果的占比,其介于 0 和 1 之间且值越大越好;AvgSupport 是模型能给出解释的预测结果的平均 support 个数,AvgSupport 是一个大于 0 的数且越大越好。可解释的评估结果如下:
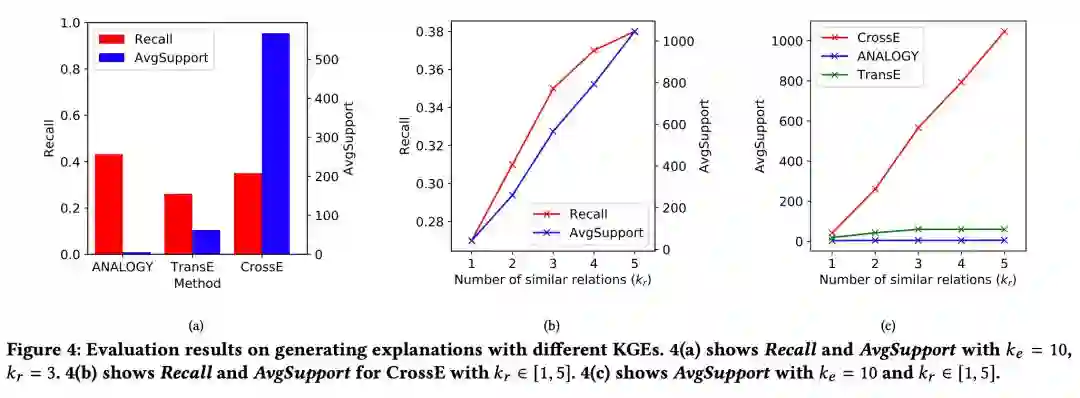
从实验结果中我们可以看出,整体来说 CrossE 能够更好地对预测结果生成解释。
链接预测和可解释的实验从两个不同的方面评估了知识图谱表示学习的效果,同时也说明了链接预测的准确性和可解释性没有必然联系,链接预测效果好的模型并不一定能够更好地提供解释,反之亦然。

■ 论文解读 | 王梁,浙江大学硕士,研究方向为知识图谱,自然语言处理
论文动机
传统的机器阅读理解的模型都是给定 context 和 question,找出最有可能回答该 question 的 answer,用概率表示为 p(a|q,c),这其实是一个判别模型。判别模型在大多数任务上可以取得比生成模型更好的准确率,但问题在于判别模型会利用一切能提升准确率的数据特征来做预测,这在机器阅读中会造成模型并未完全理解 question 和 context,而是利用训练集中的一些数据漏洞来预测。
如下图所示,模型只需要 question 中有下划线的词即可预测出正确答案,无须完全理解问题。

在 SQuAD 中另一个典型的情况是:问题的疑问词是 when 或者 who,而 context 中只有一个日期或者人名,这时模型只需要根据 question 的疑问词,context 中的日期或人名即可回答问题,不用完全理解 question 和 context。
模型
因此,本文的作者提出基于生成模型架构的机器阅读模型,其优化的目标是:给定 context,最大化 question 和 answer 的联合概率,用概率表示为 p(a,q|c)。该概率可以分解为 p(a|c)p(q|a,c)。对于这两部分,分别训练两个模型,最后在预测时,遍历所有候选的 answer 选出最大化联合概率 p(a,q|c) 的 answer 作为预测结果。
首先训练 p(a|c) 部分,即给定 context,选出最有可能出现的候选的 answer。根据 context 的不同,采用不同的方式。
1. 如果 context 是文档,例如 SQuAD 数据集,那么用 ELMo 得到 context 的表示后,该表示经过全连接层映射得到一个 score(记为),该 score 在和候选 answer 的长度指标 (),这两个 score 按如下公式得到每个候选 answer 的概率。
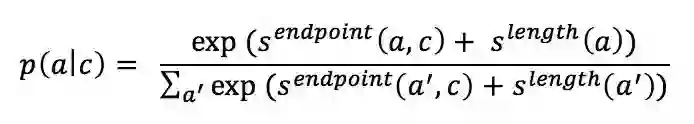
2. 如果 context 是图片,例如 CLEVR 数据集,那么在预训练的 RESNet 上 fine tuning 得到图片的表示,对所有候选 answer 分类得到每个 answer 出现的概率。
其次是 p(q|a,c) 部分,本文将其看做是文本生成问题,即采用 Encoder-Decoder 架构,根据 answer, context 的 encoding 结果,采用 decoder 生成 question。模型采用的 Decoder 的架构为:
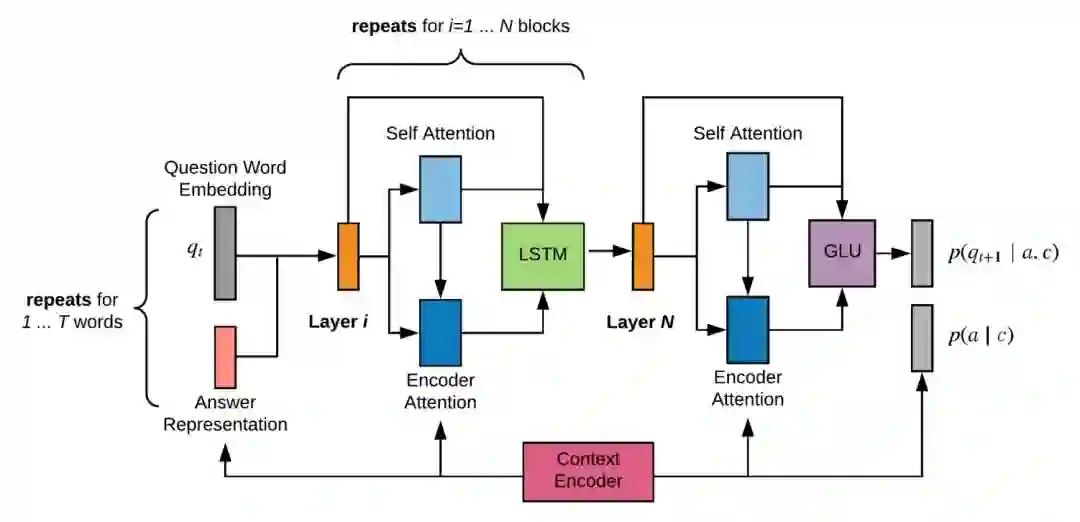
其主要包含一个循环 N 词的 decoder block,每个 block 内部 t 时刻生成的词的 embedding 会先经过 self-attention 和 attention 计算,得到的结果再经过一个 LSTM 单元,如此重复 N 次并最终依存 t+1 时刻的词。
为了解决稀疏词的问题,在预测每个词被生成的概率时采用了 character 级别的 embedding 和 pointer-generator 机制。
到这里模型已经介绍完毕。但是论文中提到了按照上述目标函数和模型结构训练完后,还有一个 fine-tuning 的步骤,这一步的目标是通过人为构造 question 和 answer 的负组合,来强化模型生成 question 时和 answer 的关联。
Fine-tuning 的目标函数是最小化如下式子:
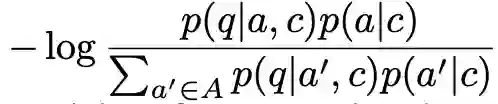
其中 A 是由 p(a|c) 选出的在当前 context 下最有可能的 top k 个候选 answer。
实验
模型的实验结果如下所示,在 SQuAD 和 CLEVR 上都取得了仅次于当前 state-of-the-art 的判别式机器阅读模型的效果:

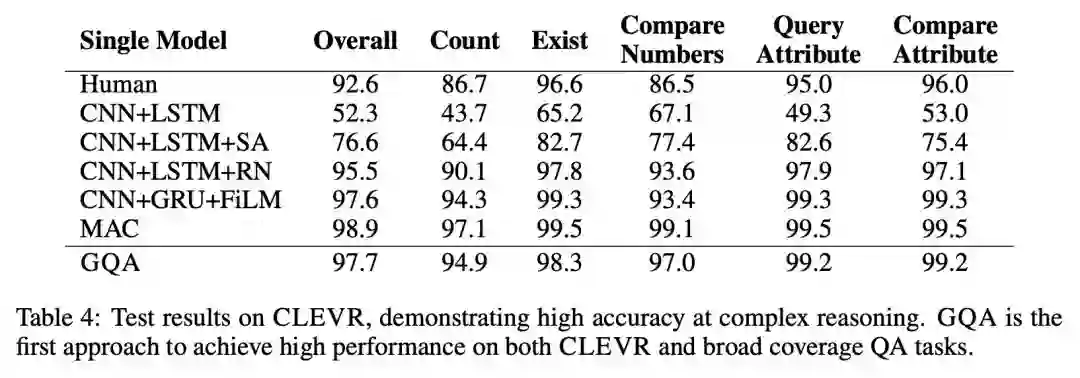
可以看到生成模型的效果要比效果最好的判别模型略差,但是本文的论点在于生成模型对 question 和 context 有更全面的理解,从而让模型有更好的泛化能力和应对对抗样本的能力。
为了验证模型的泛化能力,本文作者构建了一个 SQuAD 的子集,该子集中训练样本中的 context 都只包含一个日期,数字或者人名类实体,但是在测试样本中有多个。如果模型在训练时仅依赖 context 中特殊类型的实体作为答案的数据特征,那么在测试集上就会表现很差。
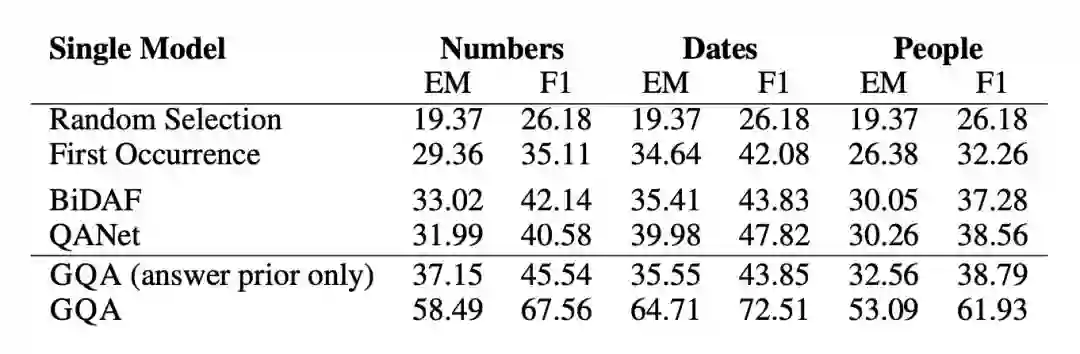
可以看到在该数据集上生成模型有很大的优势。

在包含对抗样本的数据集 Adversarial SQuAD 上的表现也好过判别模型。

■ 论文解读 | 张良,东南大学博士,研究方向为知识图谱,自然语言处理
知识图谱的表示学习最近几年被广泛研究,表示学习的结果对知识图谱补全和信息抽取都有很大帮助。本文提出了一种新的区分概念和实例的知识图谱表示学习方法,将上下位关系与普通的关系做了区分,可以很好的解决上下位关系的传递性问题,并且能够表示概念在空间中的层次与包含关系。
本文的主要贡献有三点:
1. 第一次提出并形式化了知识图谱嵌入过程中概念与实例区分的问题
2. 提出了一个新的嵌入模型 TransC 模型,该模型区分了概念与实例,并能处理 isA 关系的传递性;
3. 基于 YAGO 新建了一个用于评估的数据集。
论文动机
传统的表示学习方法没能区分概念(concept)和实例(instance)之间的区别,而是多数统一看作实体(entity),而概念显然和实例不是同一个层次的,统一的表示是有欠缺的。更重要的是,之前的方法多数无法解决上下位关系传递性的问题,这是不区分概念和实例表示的弊端。
本文创造性地将概念表示为空间中的一个球体,实例为空间中的点,通过点和球体的空间包含关系和球体间的包含关系来表示上下位关系,这种表示可以很自然地解决上下位关系传递性的问题。下图是一个区分了概念,实例的层次关系图。
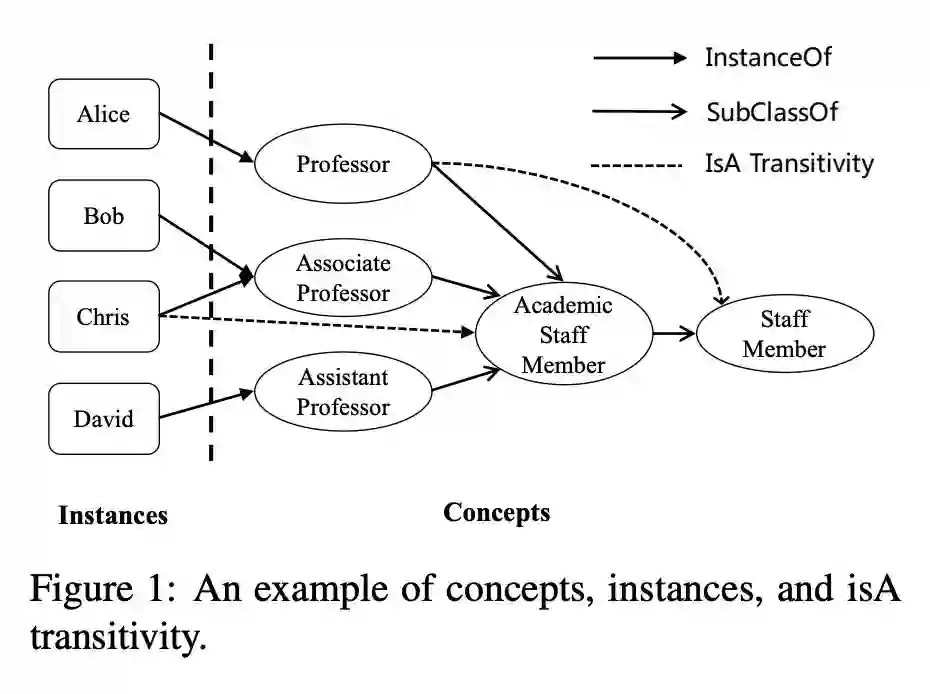
模型
通常在人们的脑海里,概念都是通过层级的方式组织起来的,而实例也应归属于与它们各自对应的概念。受此启发,本文提出了 TransC 模型来处理概念和实例区分的问题。
在 TransC 模型里,每一个概念都被表示成一个球体,而每一个实例都被表示到与对应概念相同的语义空间中。概念与实例以及概念与概念之间的相对位置分别通过 instanceOf 关系与 subClassOf 关系来刻画。
InstanceOf 关系用来表示某个实例是否在概念所表示的球体中,subClassOf 关系用来表示两个概念之间的相对位置,文中提出了四种可能的相对位置:
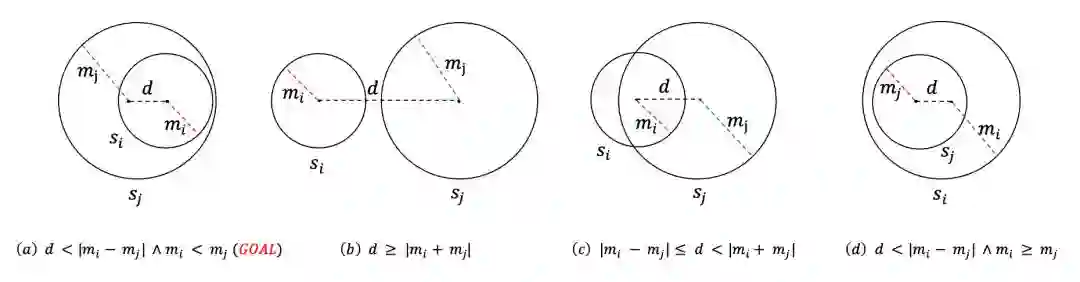
如上图所示,(a)、(b)、(c)、(d)分别表示两个概念所表示球体的相对位置,其中 m 为球体半径,d 为两个球体中心的距离,Si 与 Sj 分别表示概念 i 与概念 j 所表示成的球体。
对于 instanceOf 关系与 subClassOf 关系,文中有比较巧妙的设计以便保留 isA 关系的传递性,即 instanceOf-subClassOf 的传递性通过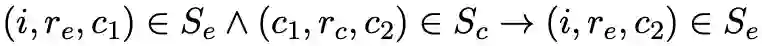
而 subClassOf-subClassOf 的传递性通过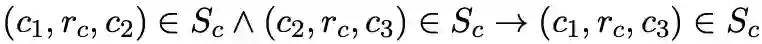
文中设计了不同的损失函数去度量 embedding 空间中的相对位置,然后用基于翻译的模型将概念,实例以及关系联合起来进行学习。在文中主要有三类 triple,所以分别定义了不同的损失函数。
InstanceOf Triple表示:对于一个给定的 instanceOf triple,如果它是正确的,那么 i 就应该被包含在概念 c 所表示的球体 s 里。而实际上,除了被包含以外,很显然还有一种相对位置就是实例 i 在球体 s(P,m)之外,损失函数设计为
SubClassOf Triple表示:对于一个给定的 subClassOf triple (c_i, r_c, c_j) ,首先定义两个球中心之间的距离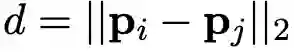
1. 按照图 1 中(b)表示的相对位置,两个球是分开的,损失函数表示为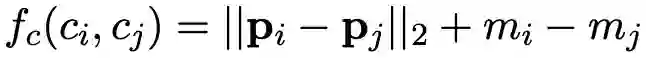
2. 两个球相交,如图 1 中(c)所示,损失函数表示为
3. 完全包含关系,如图 1 中(d)所示,损失函数表示为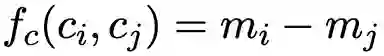
Relational Triple 表示:对于一个 relational triple (h, r, t),TransC 利用 TransE 模型的训练方式来得到实体和关系的向量,所以损失函数定义为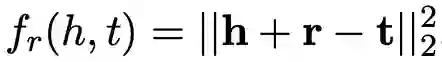
对于模型的训练,分别用 ξ 和 ξ' 来表示正确和错误的三元组,根据以上几类损失函数,可以对应得到以下几类损失:
对于 instanceOf triples,损失表示为:
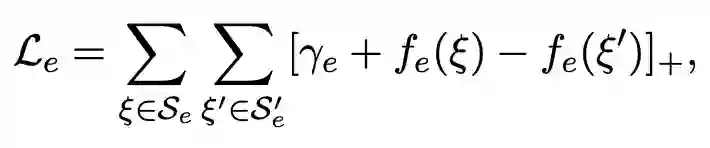
对于 subClassOf triples,损失表示为:
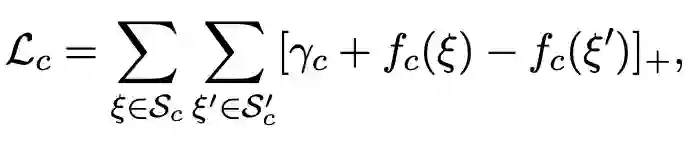
对于 relational triples,损失表示为:
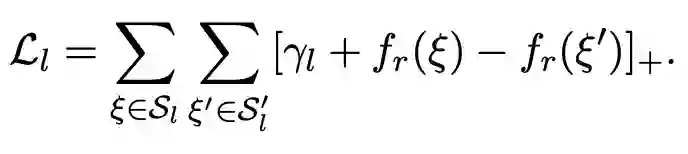
最后,模型的最终损失函数为以上几类损失的线性组合,即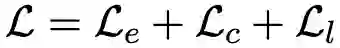
实验
以往的大多数模型都用 FB15K 和 WN18 来作为评估的数据集,但这两个数据集并不很适合文中的模型,而 YAGO 数据集不仅含了许多概念而且还有不少实例,所以作者构建了一个 YAGO 数据集的子集 YAGO39K 来用作试验评估。
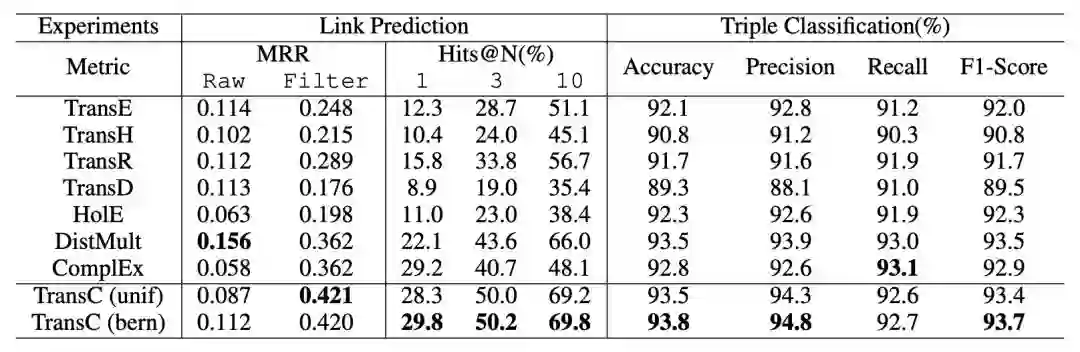
实验分别在链接预测,三元组分类以及 instanceOf 与 subClassOf 关系的三元组分类这几项任务上进行,实验结果如下:
链接预测与三元组分类结果:
instanceOf triple 分类结果:
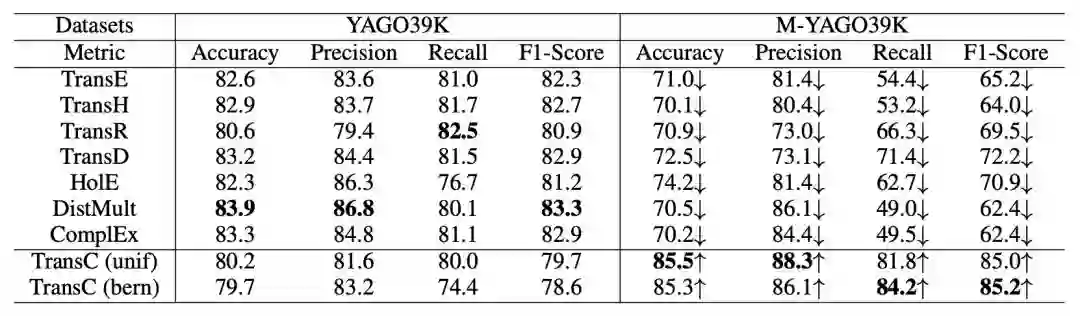
subClassOf triple 分类结果:
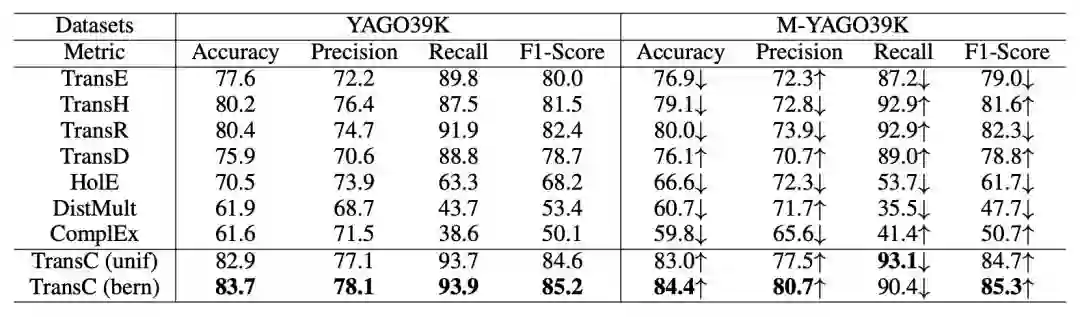
实验结果表明,TransC 模型在相关任务上与其它模型相比有较为显著的提升。
总结
本文从 Ontology 层面对知识表示学习进行了较为深入的研究,提出了新的知识图谱嵌入模型 TransC 模型,该模型将实例、概念以及关系嵌入到同一个空间中以便用来处理 isA 关系的传递性。
在实验部分,作者还创建了一个用来评估模型的新数据集 YAGO39K。实验结果表明 TransC 模型在大多数任务上要优于传统的翻译模型。
对于文中将概念表示成球体的想法似乎还可以继续探讨,作者将会继续寻找适合表示概念的方式。另外,每个概念在不同的三元组里可能会有不同的表示,如何进一步地将概念的多意性表达出来也是一个值得探究的方向。
在传统的知识工程领域,知识是通过 schema 组织起来的,有较强的逻辑性,但在语义计算层面相比向量来说没有优势,最近有不少将二者相结合的工作(给语义的向量计算披上逻辑的外衣)值得关注一下。

■ 解读 | 谭亦鸣,东南大学博士生,研究兴趣:知识问答,自然语言处理,机器翻译
本文是发表在 CIKM 2018 的短文,关注有时间信息的复杂知识库问答工作。文章提出使用 TimeML(一种时间相关的标注语言)对问题进行标注,在识别时间相关问题后,根据时间特征将复杂问题改写为多个时序相关的子问题,通过与现有的知识问答系统相关联,实现带有时间信息的复杂问答。
论文动机
与简单问题的处理方式不同,复杂问答一般会将原问题划分为多个子问题,而后合并问题答案。作者发现,复杂问题中一个需要解决的重要问题是时间信息的获取。以下面三个问题为例:
Q1: “Which teams did Neymar play for before joiningPSG?”
Q2: “Under which coaches did Neymar play inBarcelona?”
Q3: “After whom did Neymar’s sister choose her lastname?”
在 Q1 中,没有明确的日期或者时间被提到,我们可以识别“joining PSG”代表了一个事件,然后通过它转换为一个标准的时间信息。而句子中的“before”则提供了另一个时间相关的线索,但是类似于“before, after”这样的词并不总是在句子中承担这样的角色,比如 Q3 中的“after”。
在 Q2 中,我们看不到类似 Q1 的时间依赖表达,但是“Neymar play in Barcelona”中依然包含了时间信息。
因此可以发现,处理带有时序信息的复杂问题面对的第一个挑战就是:如何从问句中识别时间信息; 随之产生的第二个挑战则是:如何根据时间信息将问题分解为时序相关的子问题。
方法
本文方法的关键过程是:1)分解问题;2)重写子问题。
大体的目标如下:
还是以前面的问句为例,Q1: “Which teams did Neymar play for before joiningPSG” 改写得到子问题 Q2.1, Q2.2。
Q1.1: “Which teams did Neymar play for?”
Q1.2: “When did Neymar join PSG?”
而后在问答过程中,通过 Q2.1,从知识库中得到答案及时间范围,再与 Q2.2 得到的时间相匹配,从而找到 Q2 的答案。
为了达到上述目的,本文提出一种基于规则的四步框架:
识别包含时间信息的问题
分解问题并重写子问题
获取子问题答案
根据时间证据自合子问题答案
规则设计
本文构建的规则以 TimeML(一种标注语言)为理论基础,用于识别句子及文本中的时间信息。
标签提供了以下信息:
TIMEX3 tag,反映四类时间表达;
SIGNAL tag,反映时间表达标签之间的关系(用于切分子问题)。
规则定义
包含时间信息的问题:即出现了时间信息表达或时间信息关系的问句(标签能在问句中标出内容)。
时间关系:Allen (J. F.Allen. 1990. Maintaining knowledge about temporal intervals. In Readings inqualitative reasoning about physical systems. Elsevier) 定义了 13 种时间关系,EQUAL, BEFORE, MEETS, OVERLAPS, DURING, STARTS, FINISHES。

表 1 列举了子问题重写规则。回答子问题时,对于包含时间信息的子问题需要检索可能的时间范围。
实验
本文实验评估基于 TempQuestions benchmark,其中包含 1271 个时间相关问题,并使用三个目前最好的 KBQA 系统作为 baseline:AQQU, QUINT 和 Bao et al。在实验中,作者将框架与问答系统整合到一起,构成对比模型。

实验结果反映出添加框架的问答系统的提升主要表现为 F1 与准确率的上升。
总结
本文提出了一种基于时间信息标注的规则型时序复杂问答框架,主要以时间信息的规则标注概念为基础,将复杂问题的切分过程转换为序列标注问题,并对已有人工规则加以利用,构建时序信息间的关系。框架整体比较简明,从规则角度看,还需要做部分深入阅读方能较好理解该方法是否具有较好的泛化性。

■ 论文解读 | 花云程,东南大学博士,研究方向为知识图谱问答、自然语言处理
论文动机
在以前的工作中,对话生成的信息源是文本与对话记录。但是这样一来,如果遇到 OOV 的词,模型往往难以生成合适的、有信息量的回复,而会产生一些低质量的、模棱两可的回复,这种回复往往质量不高。
为了解决这个问题,有一些利用常识知识图谱生成对话的模型被陆续提出。当使用常识性知识图谱时,由于具备背景知识,模型更加可能理解用户的输入,这样就能生成更加合适的回复。但是,这些结合了文本、对话记录、常识知识图谱的方法,往往只使用了单一三元组,而忽略了一个子图的整体语义,会导致得到的信息不够丰富。
为了解决这些问题,文章提出了一种基于常识知识图谱的对话模型(commonsense knowledge aware conversational model,CCM)来理解对话,并且产生信息丰富且合适的回复。
本文提出的方法利用了大规模的常识性知识图谱。首先是理解用户请求,找到可能相关的知识图谱子图;再利用静态图注意力(static graphattention)机制,结合子图来理解用户请求;最后使用动态图注意力(dynamic graph attention)机制来读取子图,并产生合适的回复。
通过这样的方法,本文提出的模型可以生成合适的、有丰富信息的对话,提高对话系统的质量。
贡献
文章的贡献有:
1. 首次尝试使用大规模常识性知识图谱来处理对话生成问题;
2. 对知识图谱子图,提出了静态/动态图注意力机制来吸收常识知识,利于理解用户请求与生成对话;
3. 对比于其他系统,目前的模型生成的回复是最合适的、语法最正确的、信息最丰富的。
方法
1. Encoder-Decoder模型
经典的 Encoder-Decoder 模型是基于 sequence-to-sequence(seq2seq)的。encoder 模型将用户输入(user post)X=x_1 x_2…x_n 用隐状态 H=h_1 h_2…h_n 来表示。而 decoder 模型使用另一个 GRU 来循环生成每一个阶段的隐状态,即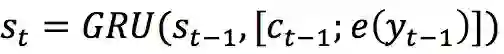
当 decoder 模型根据概率分布生成了输出状态后,可以由这个状态经过 softmax 操作得到最终的输出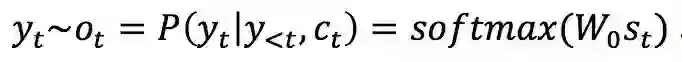
2. 模型框架
如下图 1 所示为本文提出的 CCM 模型框架。
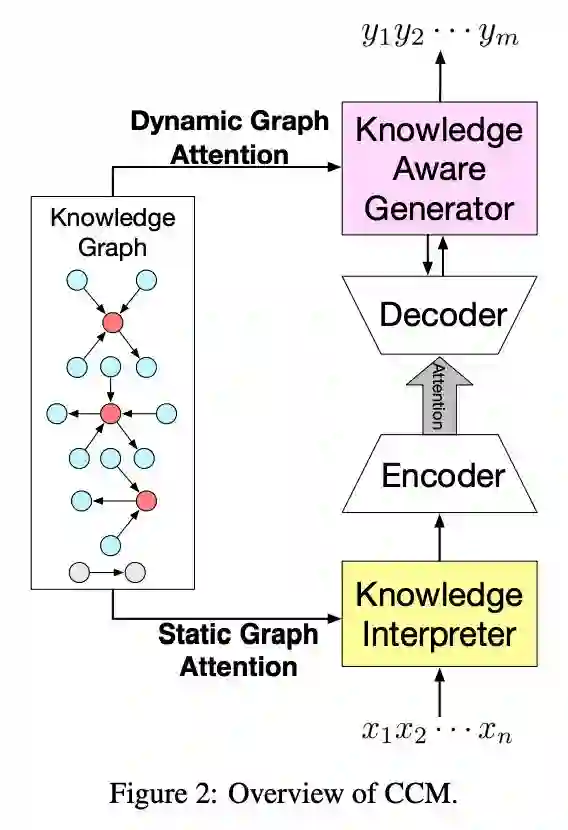
如图 1 所示,基于 n 个词输入,会输出 n 个词作为回复,模型的目的就是预估这么一个概率分布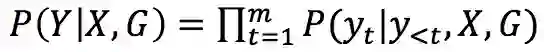
在信息读取时,根据每个输入的词 x,找到常识知识图谱中对应的子图(若没有对应的子图,则会生成一个特殊的图 Not_A_Fact),每个子图又包含若干三元组。
⒊ 知识编译模块
如图 2 所示,为如何利用图信息编译 post 的示意图。
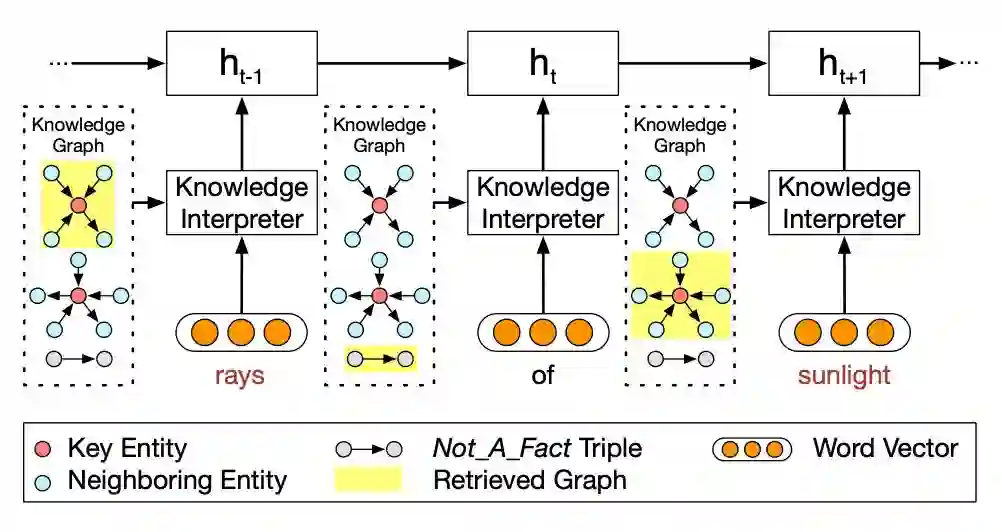
如图所示,当编译到“rays”时,会把这个词在知识图谱中相关的子图得到(图 2 最上的黄色高两部分),并生成子图的向量。每一个子图都包含了 key entity(即这里的 rays),以及这个“rays”的邻居实体和相连关系。
对于词“of”,由于无法找到对应的子图,所以就采用特殊子图 Not_A_Fact 来编译。之后,采用基于静态注意力机制,CCM 会将子图映射为向量,然后把词向量 w(x_t) 和 g_i 拼接为,并将这个替换传统 encoder-decoder 中的 e(x_t) 进行 GRU 计算。
对于静态图注意力机制,CCM 是将子图中所有的三元组都考虑进来,而不是只计算一个三元组,这也是该模型的一个创新点。
⒋ 知识生成模块
如下图 3 所示,为如何利用图信息生成回复的示意图。
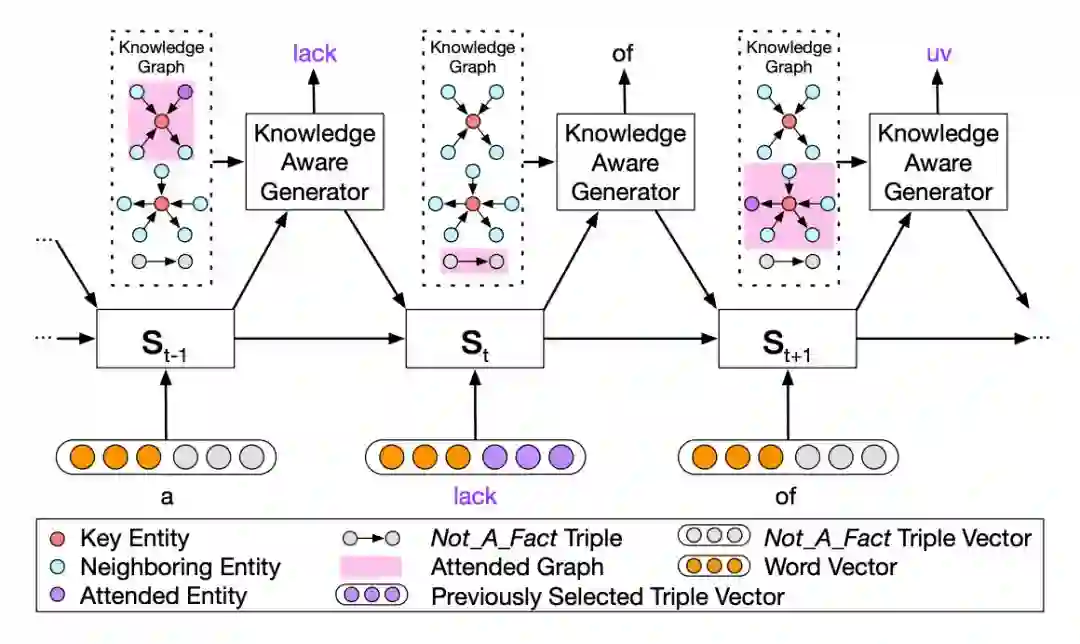
在生成时,不同于静态图注意力机制,模型会读取所有相关的子图,而不是当前词对应的子图,而在读取时,读取注意力最大的就是图中粉色高亮的部分。生成时,会根据计算结果,来选择是生成通用字(generic word)还是子图中的实体。
⒌ 损失函数
损失函数为预期输出与实际输出的交叉熵,除此之外,为了监控选择通用词还是实体的概率,又增加了一个交叉熵。
实验
实验相关细节
常识性知识图谱选用了 ConceptNet,对话数据集选用了 reddit 的一千万条数据集,如果一个 post-response 不能以一个三元组表示(一个实体出现于 post,另一个出现于 response),就将这个数据去除。
然后对剩下的对话数据,分为四类,一类是高频词,即每一个 post 的每一个词,都是最高频的 25% 的词;一类是中频词,即 25%-75% 的词;一类是低频词,即 75%-100% 的词;最后一类是 OOV 词,每一个 post 包含了 OOV 的词。
而基线系统选择了如下三个:只从对话数据中生成 response 的 seq2seq 模型、存储了以 TransE 形式表示知识图谱的 MemNet 模型、从三元组中 copy 一个词或生成通用词的 CopyNet 模型。
而选用 metric 的时候,采用了刻画回复内容是否语法正确且贴近主题的 perplexity,以及有多少个知识图谱实体被生成的 entity score。
实验结果
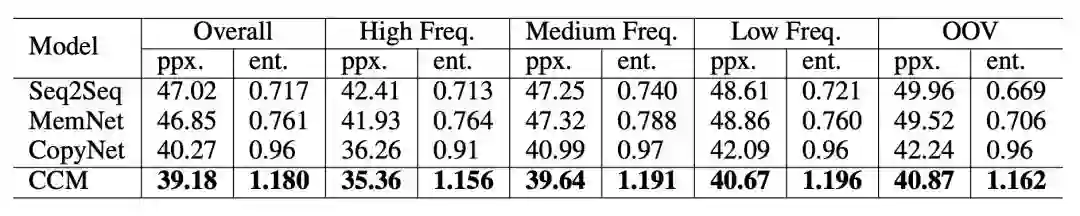
如下图 4 所示,为根据 perplexity 和 entity score 进行的性能比较,可见 CCM 的 perplexity 最低,且选取 entity 的数量最多。并且,在低频词时,选用的 entity 更多。这表示在训练时比较罕见的词(实体)会需要更多的背景知识来生成答复。
另外,作者还采用众包的方式,来人为审核 response 的质量,并采用了两种度量值 appropriateness(内容是否语法正确,是否与主题相关,是否有逻辑)与 informativeness(内容是否提供了 post 之外的新信息)。
如下图所示,为基于众包的性能比较结果。

从上图可见,CCM 对于三个基线系统来说,都有将近 60% 的回复是更优的。并且,在 OOV 的数据集上,CCM 比 seq2seq 高出很多,这是由于 CCM 对于这些低频词或未登录词,可以用知识图谱去补全,而 seq2seq 没有这样的知识来源。
如下图所示,当在 post 中遇到未登录词“breakable”时,seq2seq 和 MemNet 都只能输出一些通用的、模棱两可的、毫无信息量的回复。CopyNet 能够利用知识图谱输出一些东西,但是并不合适。而 CCM 却可以输出一个合理的回复。

总结
本文提出了一种结合知识图谱信息的 encoder-decoder 方法,引入静态/动态图注意力机制有效地改善了对话系统中 response 的质量。通过自动的和基于众包的形式进行性能对比,CCM 模型都是优于基线系统的。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




