时间信息编码为机器学习模型特征的三种方法(附链接)

大数据文摘授权转载自数据派THU
作者:Eryk Lewinson
翻译:张睿毅
校对:张睿毅
设置与数据
在本文中,我们主要使用非常知名的Python包,以及依赖于一个相对不为人知的scikit-lego包,这是一个包含许多有用功能的库,这些功能正在扩展scikit-learn的功能。我们导入所需的库,如下所示:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom datetime import datefrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import FunctionTransformerfrom sklearn.metrics import mean_absolute_errorfrom sklego.preprocessing import RepeatingBasisFunction
day_nr – 表示时间流逝的数字索引
day_of_year – 一年中的第一天
# 避免重复np.random.seed(42)# 生成日期的数据格式range_of_dates = pd.date_range(start="2017-01-01",End="2020-12-30")X = pd.DataFrame(index=range_of_dates)# 创建日期数据的序列X["day_nr"] = range(len(X))X["day_of_year"] = X.index.day_of_year# 生成目标成分signal_1 = 3 + 4 * np.sin(X["day_nr"] / 365 * 2 * np.pi)signal_2 = 3 * np.sin(X["day_nr"] / 365 * 4 * np.pi + 365/2)noise = np.random.normal(0, 0.85, len(X))# 合并获取目标序列y = signal_1 + signal_2 + noise# 画图y.plot(figsize=(16,4), title="Generated time series");
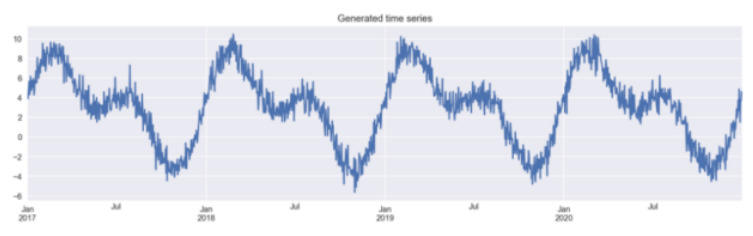
results_df = y.to_frame()results_df.columns = ["actuals "]
创建与时间相关的要素
TRAIN_END = 3 * 365方法1:虚拟变量
X_1 = pd.DataFrame(data=pd.get_dummies(X.index.month, drop_first=True, prefix="month"))
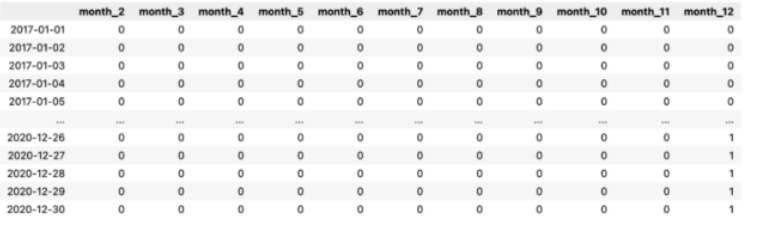
表 1:带有月份假人的数据帧。
model_1 = LinearRegression().fit(X_1.iloc[:TRAIN_END], y.iloc[:TRAIN_END])results_df["模型_1"] = model_1.predict(X_1)results_df[["actuals","model_1"]].plot(figsize=(16,4),title="用月虚拟变量拟合")plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
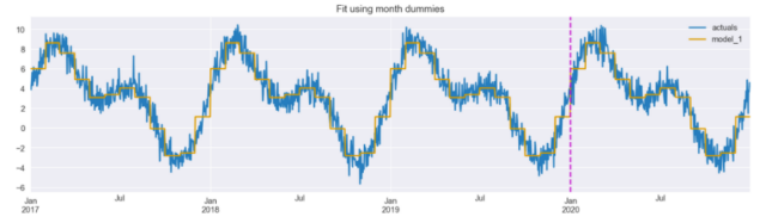
图 2:使用月份假人进行拟合。垂直线将训练集和测试集分开。
方法#2:具有正弦/余弦变换的循环编码
def sin_transformer(period):return FunctionTransformer(lambda x: np.sin(x / period * 2 * np.pi))def cos_transformer(period):return FunctionTransformer(lambda x: np.cos(x / period * 2 * np.pi))
X_2 = X.copy()X_2["月"] = X_2.index.monthX_2["月_sin"] = sin_transformer(12).fit_transform(X_2)[" 月"]X_2["月_cos"] = cos_transformer(12).fit_transform(X_2)[" 月"]X_2["日_sin"] = sin_transformer(365).fit_transform(X_2)["每年的日"]X_2["日_cos"] = cos_transformer(365).fit_transform(X_2)[" 每年的日"]fig, ax = plt.subplots(2, 1, sharex=True, figsize=(16,8))X_2[["月_sin", "月_cos"]].plot(ax=ax[0])X_2[["日_sin", "日_cos"]].plot(ax=ax[1])plt.suptitle("用正余弦变换循环编码");
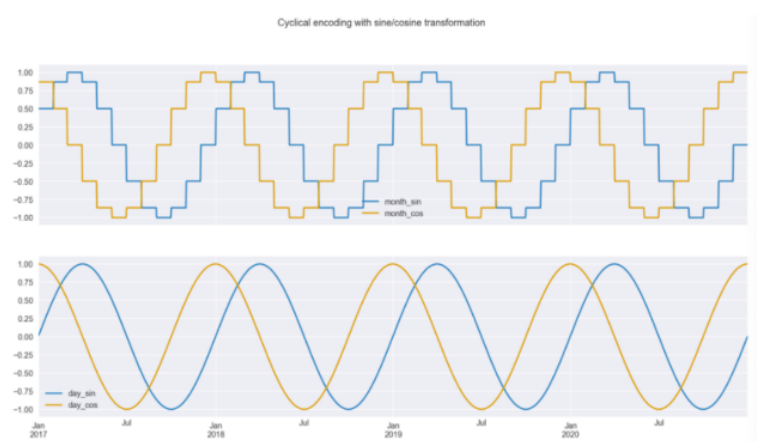
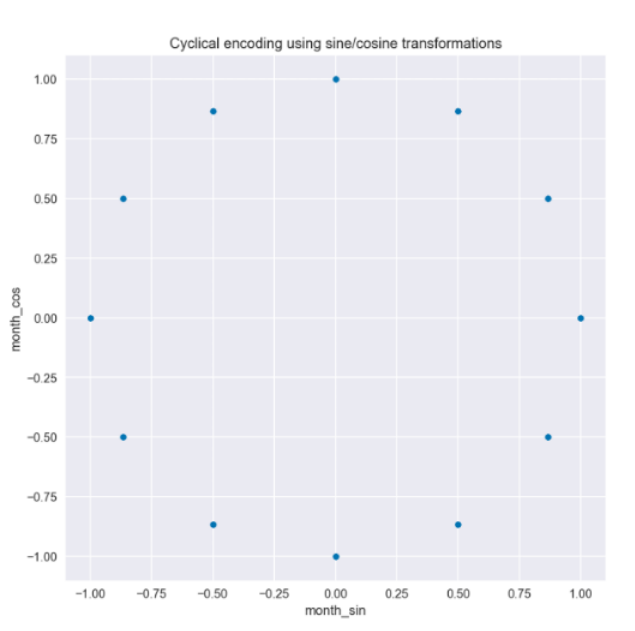
X_2_daily = X_2[["day_sin", "day_cos"]]model_2 = LinearRegression().fit(X_2_daily.iloc[:TRAIN_END],y.iloc[:TRAIN_END])results_df["model_2"] = model_2.predict(X_2_daily)results_df[["actuals", "model_2"]].plot(figsize=(16,4), title="使用正弦/余弦特征拟合")plt.axvline(date(2020, 1, 1), c="m", linestyle="--");
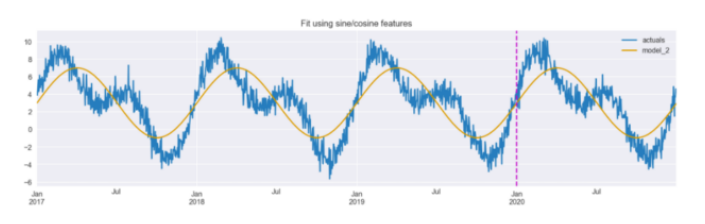
图 5:使用正弦/余弦变换拟合。垂直线将训练集和测试集分开。
图 5 显示,该模型能够拾取数据的总体趋势,识别具有较高和较低的周期。但是,预测的幅度似乎不太准确,乍一看,这种拟合似乎比使用第一种方法,虚拟变量,实现的拟合更差(图 2)。
在我们讨论第三种特征工程技术之前,值得一提的是,这种方法存在一个严重的缺点,尤其会在使用基于树的模型时,缺点很明显。最初设计,基于树的模型就是基于当时的单个特征进行拆分。正如我们之前提到的,正弦/余弦特征应该同时考虑,以便正确识别一段时间内的时间点。
方法#3:径向基函数
最后一种方法使用径向基函数。我们不会详细介绍它们的实际情况,但您可以在此处阅读有关该主题的更多信息。从本质上讲,我们再次希望解决第一种方法遇到的问题,即我们的时间特征具有连续性。
我们使用方便的scikit-lego库,它提供了RepeatmentBasisFunction类,并指定了以下参数:
我们要创建的基函数的数量(我们选择:12个)。
用于为 径向基函数(RBF)编制索引的列。我们这里采用的列是,该观测值来自一年中的哪一天。
输入范围 – 我们这里,范围是从1到365。
如何处理数据帧的其余列,我们将使用这些数据帧来拟合估计器。"drop"将仅保留创建的 RBF 功能,"passthrough "将保留旧功能和新功能。
rbf = RepeatingBasisFunction(n_periods=12,column="day_of_year",input_range=(1,365),remainder="drop")rbf.fit(X)X_3 = pd.DataFrame(index=X.index,data=rbf.transform(X))=True, figsize=(14, 8),sharex=True, title="Radial Basis Functions",legend=False);
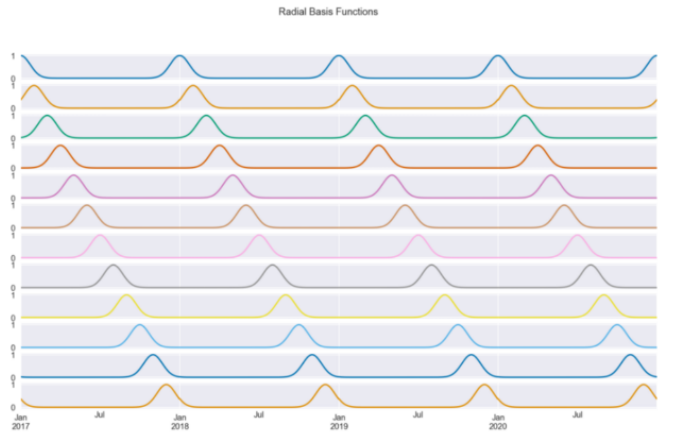
model_3 = LinearRegression().fit(X_3.iloc[:TRAIN_END], y.iloc[:TRAIN_END])results_df["model_3"] = model_3.predict(X_3)results_df[["actuals", "model_3"]].plot(figsize=(16,4), title="使用RBF特征拟合")plt.axvline(date(2020, 1, 1), c="m", linestyle="--");

径向基函数的数目,
钟形曲线的形状 – 可以使用 RepeatingBasis 函数的宽度参数对其进行修改。
最终比较
results_df.plot(title="对比不同时间特征的拟合",figsize=(16,4), color = ["c", "k", "b", "r"])plt.axvline(date(2020, 1, 1), c="m", linestyle="--");

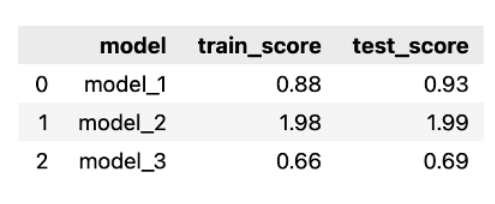
score_list = []for fit_col in ["model_1", "model_2", "model_3"]:scores = {"model": fit_col,"train_score": mean_absolute_error(results_df.iloc[:TRAIN_END]["actuals"],results_df.iloc[:TRAIN_END][fit_col]),"test_score": mean_absolute_error(results_df.iloc[TRAIN_END:]["actuals"],results_df.iloc[TRAIN_END:][fit_col])}score_list.append(scores)scores_df = pd.DataFrame(score_list)scores_df
总结
我们展示了三种将时间相关信息编码为机器学习模型特征的方法。
除了最流行的虚拟编码之外,还有一些方法更适合编码时间的循环性质。
使用这些方法时,时间间隔的粒度对于新创建的要素的形状非常重要。
使用径向基函数,我们可以决定要使用的函数的数量,以及钟形曲线的宽度。
引用:
[1] 时间相关的特征工程
https://scikit-learn.org/stable/auto_examples/applications/plot_cyclical_feature_engineering.html
[2] 预处理
https://scikit-lego.readthedocs.io/en/latest/preprocessing.html
[3] 时间/日期因素





