作者:Adrian Tam, Ray Hong, Jinghan Yu, Brendan Artley
主成分分析是一种无监督的机器学习技术。可能它最常见的用处就是数据的降维。主成分分析除了用于数据预处理,也可以用来可视化数据。一图胜万言。一旦数据可视化,在我们的机器学习模型中就可以更容易得到一些洞见并且决定下一步做什么。
在这篇教程中,你将发现如何使用PCA可视化数据,并且使用可视化来帮助确定用于降维的参数。
可视化是从数据中得到洞见的关键一步。我们可以通过可视化学习到一个模式是否可以被观察到,因此估计哪个机器学习模型是合适的。
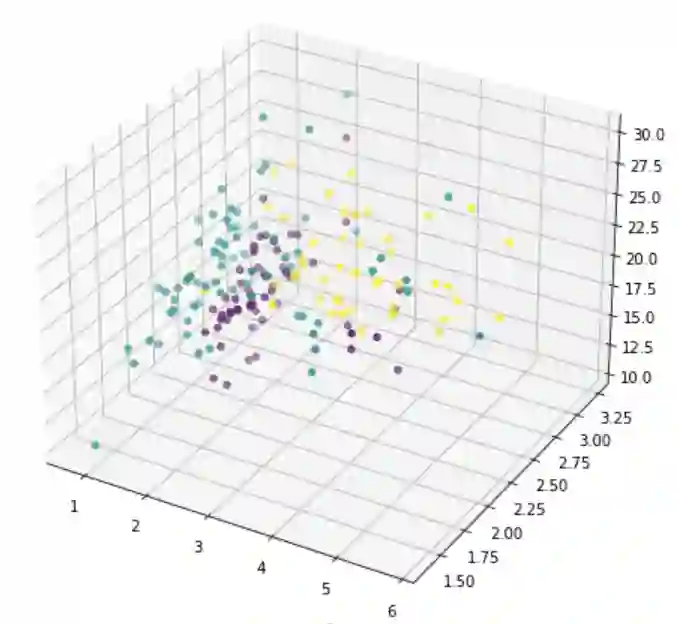
用二维数据描述事物是容易的。正常地,一个有x轴y轴的散点图就是二维的。用三维数据描述事物有一点挑战性但不是不可能的。例如,在matplotlib中可以绘制三维图。唯一的问题是在纸面或者屏幕上,我们每次只能从一个角度或者投影来看三维图。在matplotlib中,视图由仰角和方位角控制。用四维或者五维数据来描述事物是不可能的,因为我们生活在三维世界,并且不知道在这些高维度中数据看起来是什么样的。
这就是诸如PCA的数据降维技术发挥作用的地方。我们可以将数据维度降低到二维或者三维以便将其可视化。我们从一个例子开始。
我们使用红酒数据集,这个数据集是包括13个特征和3种类别的分类数据集(也就是说这个数据集是13维的)。这里有178个样本:
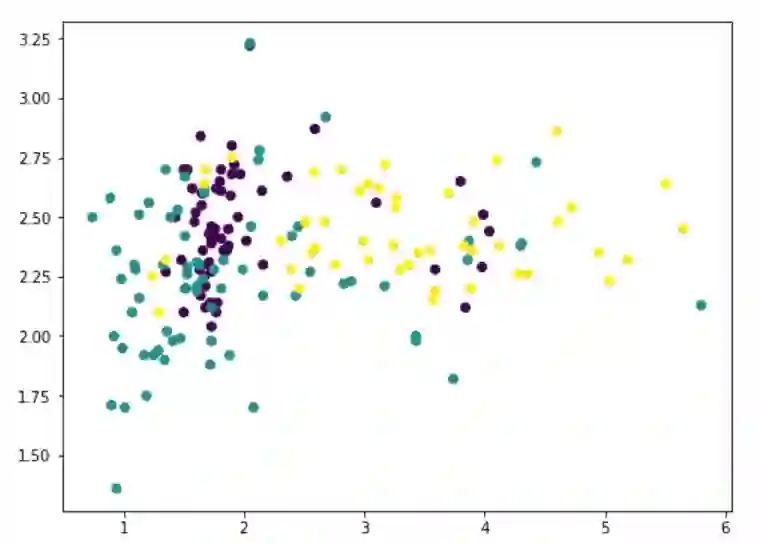
在13个特征中,我们可以使用matplotlib挑选任意两个(我们使用c 参数对不同的类进行颜色编码):
但是这并不能揭示数据到底是什么样,因为大量的特征没有被展示出来。我们现在转向PCA:
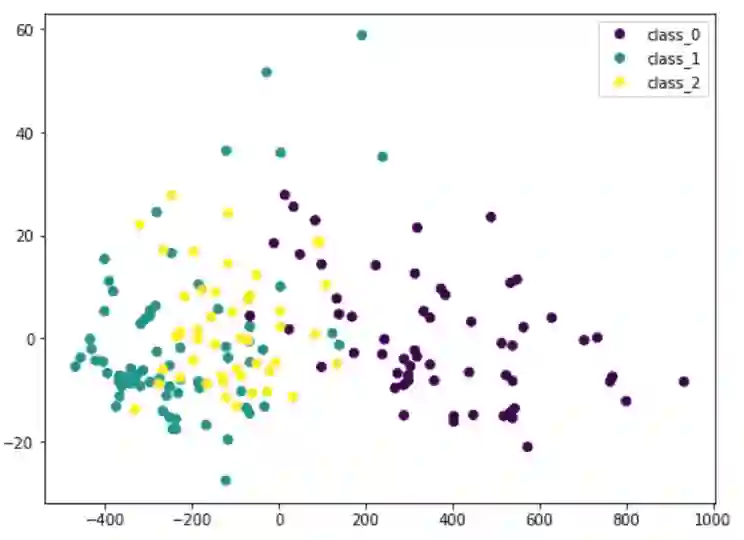
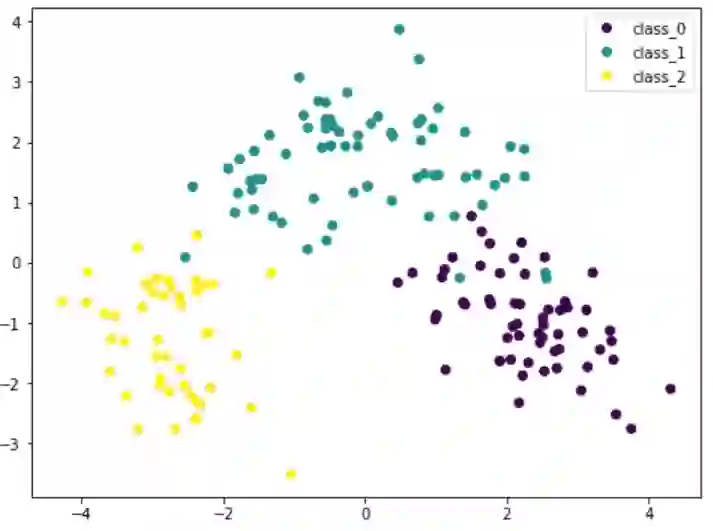
这里我们将输入数据的X通过PCA转换成Xt。我们只考虑包含最重要数据的两栏,并且将其画成二维图像。可以看到,紫色类是比较有特色的,但是和其他类存在一些重叠。 如果我们在 PCA 之前缩放数据的维度,结果会有所不同:
因为 PCA 对数据的尺寸很敏感,所以如果通过 StandardScaler 对每个特征进行归一化,我们可以看到更好的结果。这样的话,不同的种类会更有特色性。通过该图,我们可以确信诸如 SVM 之类的简单模型可以高精度地对该数据集进行分类。
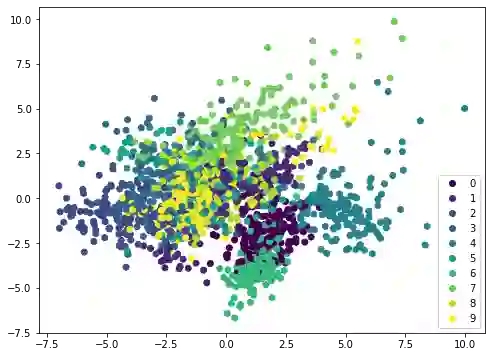
如果我们在不同的数据集(例如 MINST 手写数字)上应用相同的方法,散点图将不会显示出明显的边界,因此需要更复杂的模型(例如神经网络)进行分类:
PCA本质上是通过特征的线性组合将它们重新排列。因此,它被称为特征提取技术。PCA的一个特点是第一个主成分包含有关数据集的最多信息。第二个主成分比第三个主成分提供更多信息,依此类推。
为了阐述这个想法,我们可以从原始数据集中逐步删除主成分,然后观察数据集的样子。 让我们考虑一个特征较少的数据集,并在图中显示两个特征:
这是只有四个特征的 iris 数据集。这些特征具有可比的比例,因此我们可以跳过缩放器。对于一个具有4 个特征的数据,PCA 最多可以产生 4 个主成分:
例如,第一行是创建第一个主成分的第一个主轴。对于任何具有特征p=(a,b,c,d)的数据点p,因为主轴由向量v=(0.36,−0.08,0.86,0.36)表示,所以在主轴上此数据点的第一个主成分有值0.36×a–0.08×b+0.86×c+0.36×d。使用向量点乘,此值可以表示为:P⋅v。
因此,将数据集X作为一个150×4的矩阵(150个数据点,每个数据点有4个特征),我们就可以通过矩阵-向量乘法将每个数据点映射到该主轴上的值:X⋅v。
计算结果是长度为150的向量。此时,若我们从每个数据点中删除沿主轴向量的对应值,就是:X–(X⋅v)⋅vT。
其中,转置向量vT是行向量,X⋅v是列向量,乘积(X⋅v)⋅vT遵循矩阵-矩阵乘法法则。计算结果是一个150×4矩阵,与X维度相同。
如果我们绘制(X⋅v)⋅vT的前两个特征,它看起来是这样:
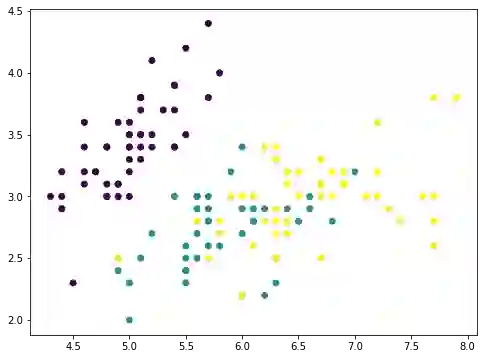
numpy 数组 Xmean的目的是将X的特征转换到以零为中心,这是 PCA必经的一步。然后通过矩阵-向量乘法计算出数组value 。数组value是映射在主轴上的每个数据点的大小。因此,如果我们将此值乘以主轴向量,得到一个数组pc1。从原始数据集X中删除它,得到一个新的数组 Xremove。在图中,我们观察到散点图上的点散落在一起,每个类的聚类都不如之前那么突出。这说明通过删除第一个主成分,我们删除了大量信息。如果我们再次重复相同的过程,这些数据点将进一步散落:
这张图里看起来像一条直线,但实际上不是。如果我们再重复一遍,所有点会散落成一条直线:
这些点都落在一条直线上,因为我们从数据中删除了三个主成分,而这些数据只有四个特征。因此,我们的数据矩阵变为秩为1的矩阵。你可以尝试重复此过程,结果将是所有点散落成为一个点。在我们删除主成分时,每个步骤中删除的信息量可以通过PCA中相应的解释方差比找到:
这里我们可以看到,第一个成分解释了92.5%的方差,第二个组件解释了5.3%的方差。如果我们去掉前两个主分量,剩余的方差只有2.2%,因此在视觉上,去掉两个分量后的图看起来像一条直线。实际上,当我们检查上面的图时,不仅可以看到点被破坏了,而且当我们删除成分时,x轴和y轴的范围也更小。
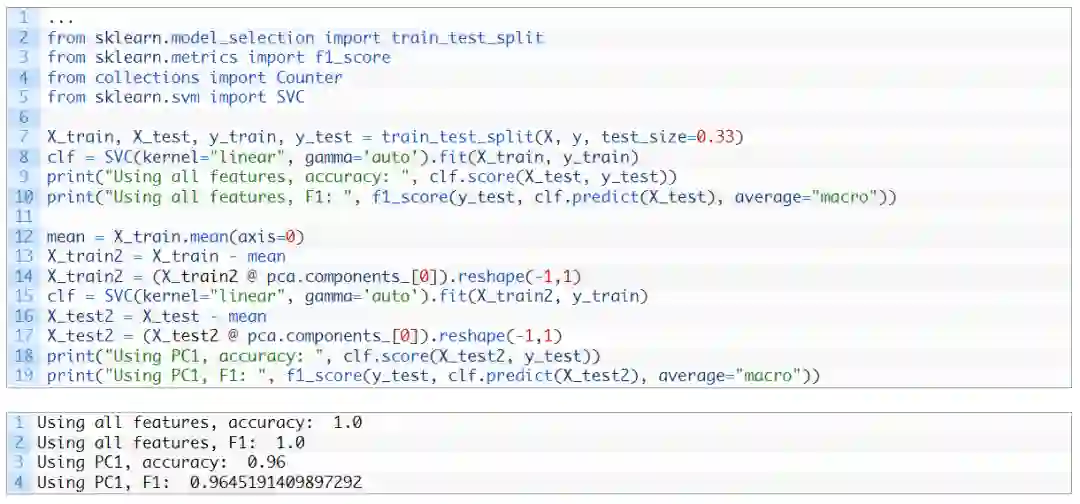
在机器学习方面,我们可以考虑在此数据集中仅使用一个特征进行分类,即第一个主成分。相比使用全部特征得到的原始准确度,此时获得的准确度有望不低于它原来的90%:
解释方差的另一个用途在于压缩。鉴于第一个主分量的解释方差很大,如果我们需要存储数据集,我们只能存储第一个主轴上的投影值(X⋅v)以及向量v的主轴。然后,我们可以通过乘以原始数据集来近似地重现它们:X≈(X⋅v)⋅vT。
通过这种方式,我们只需要存储每个数据点的一个值,而不是四个特征的四个值。如果我们将投影值存储在多个主轴上并将多个主成分相加,则近似值会更准确。
书籍
教程
-
如何在Python中从头开始计算主成分分析(PCA)
https://machinelearningmastery.com/calculate-principal-component-analysis-scratch-python/
https://machinelearningmastery.com/principal-components-analysis-for-dimensionality-reduction-in-python/
APIs
scikit-learn toy datasets
https://scikit-learn.org/stable/datasets/toy_dataset.html
scikit-learn iris dataset
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html
scikit-learn wine dataset
https://scikit- learn.org/stable/modules/generated/sklearn.datasets.load_wine.html
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.scatter.html
https://matplotlib.org/stable/tutorials/toolkits/mplot3d.html
在本教程中,你了解了如何使用主成分分析来可视化数据。
-
-
如何使用 PCA 维度中的图来帮助选择合适的机器学习模型
-
-