达摩院基于元学习的对话系统

作者:戴音培, 黎航宇, 李永彬, 孙健
出品:阿里达摩院Conversational AI团队
导读:随着科技的不断进步发展,智能对话系统因其巨大的潜力和商业价值将会成为下一代人机交互的风口,不少公司都纷纷开始研究人机对话系统,希望人与机器之间能够通过自然对话进行交互。笔者所在的达摩院 Conversational AI团队(即云小蜜团队),早在三年前就研发打造了面向开发者的智能对话开发平台 Dialog Studio,并将我们的技术通过阿里云智能客服的产品矩阵,赋能各行各业和政府机构进行智能服务的全方位升级。目前Dialog Studio平台已经在阿里云智能客服(政务12345热线、中移动10086、金融、医疗等)、钉钉(通过钉钉官方智能工作助理服务几百万企业)、集团内(淘宝优酷等十几个BU)、淘宝天猫商家以及Lazada东南亚6国得到了大规模应用。
常见的智能对话系统有:问答型、聊天型、任务型等。其中任务型对话在实际应用中,尤其是在我们的ToB 场景最为普遍。因为该系统不仅可以回答用户问题,同时还能主动发问,引导会话的有效进行,通过多轮对话完成某个特定的任务。例如在一个浙江省信访的外呼场景中,一个典型的对话如下:
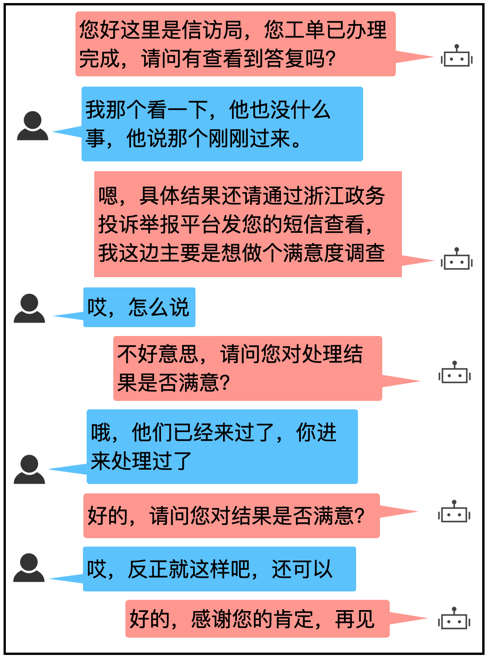
可以看到,在该对话中,机器人需要先表明自己的来意,根据用户的不同的回答情况进行多轮的对话,收集好自己需要的满意度信息并结束对话。
目前常见的任务型对话系统的架构有两种,一种是模块化的,另一种是端到端式的(如下图所示):

尽管模块化的对话系统由于每个部分独立优化,具有更强的可控性,但是端到端的对话系统可以直接利用对话日志进行训练,不需要人工设计特定的语义标签,因此更具备可扩展性,在一些复杂度中低的对话场景中能够快速训练部署使用。有关模块化和端到端对话模型的详细介绍和前沿进展可参考《小蜜团队万字长文:对话管理模型最新研究进展》一文。
2. 端到端对话模型及其挑战
一般来说,端到端对话模型可分为检索式和生成式,检索式模型就是给定对话历史从预定义回复候选集合中选出最佳回复作为当前系统输出,生成式模型则是给定对话历史直接生成回复。两种方式都可以通过和用户多轮交互完成最终的对话任务。
由于回复更加可控,目前我们在 Dialog Studio 上实现的是检索式端到端的对话模型,并且在政务、疫情等业务中都落地应用。上述的浙江省信访的例子就是我们实现的对话模型所产生的对话,因为没有复杂的知识推理、语义解析等,此类场景是端到端对话系统特别适用的场景。
然而,尽管端到端对话模型简单易用,但是在实际应用中仍然面临着两大常见问题:
① 数据量少:端到端模型一般需要大量的训练数据,且场景越复杂,需求越大。在 Dialog Studio 中的ToB 的业务,不少新场景一开始是没有可用的高质量对话日志,比如我们在政务12345 场景 和 114 移车场景上积累了大量的对话,可当我们做省信访外呼场景时,一开始只有极少的对话可以使用。因此如何利用已有场景的丰富数据训练好一个端到端模型,使其可以快速迁移到缺少数据的新场景上是一个很大的挑战。

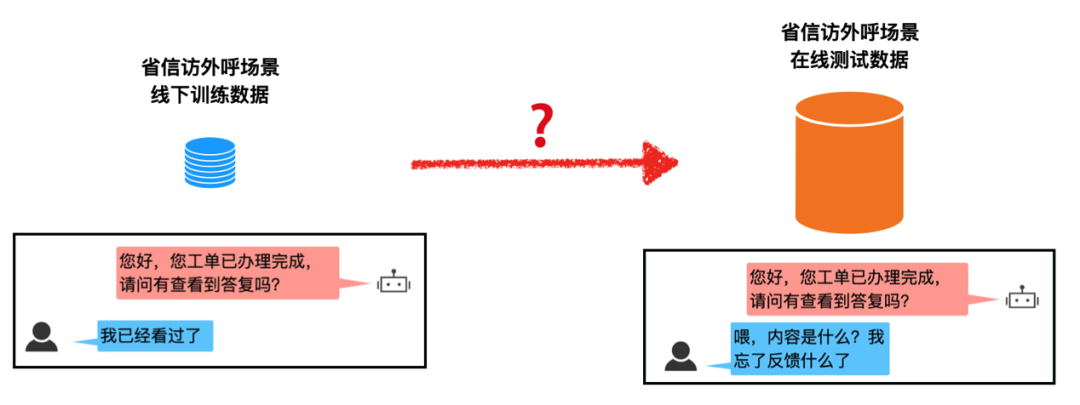
② 鲁棒性差:有限的离线训练数据和真实的在线测试数据之间存在数据分布的差异性,会导致系统在线表现不佳和离线测试效果不匹配的情况。这种差异性主要来自于未见的用户行为(例如:新槽值、新意图、复杂句等),这类问题统称为 out-of-script 问题,可以用来验证对话模型的鲁棒性。例如下图中,训练数据中从未出现过“喂,内容是什么?我忘了反馈什么了” 类似的用户语句,一旦真实上线,模型很容易预测出错误的结果,从而影响用户体验。尤其是当数据量少的时候,模型对于在线数据的鲁棒预测会进一步下降。因此如何解决线上线下数据不匹配,提高端到端对话模型的鲁棒性是另一大挑战。
在阿里云智能客服的诸多业务中,不少场景都存在训练数据稀少的问题,而客户又需要我们的对话系统能够达到可直接上线的标准。因此综合来看,我们希望提出一种新的端到端对话系统以及对应的优化方法,能够兼具备面对新场景的快速适应性(fast adaptability)和稳健的在线表现 (reliable performance),能够在低训练资源下依旧能够保证较好的线上效果。
02
技术方案
通过前期调研我们发现,应对数据少的问题的常用方法有元学习、数据增强等,而应对训练和测试对话数据不一致的问题的常用方法有人机协同[1]、在线学习[2]等。最终我们选择将元学习(meta-learning)方法和人机协同(human-machine collaboration)方法结合,提出了元对话系统(Meta-Dialog System, MDS):利用元学习,系统能够在少量训练数据上进行快速学习,解决数据少的难题;利用人机协作,模型可以在对话中请求人工客服帮助,以保证系统达到可接受的线上水平,提高系统的鲁棒性。相关成果已经发表至 ACL2020 [3]。
1. 模型结构
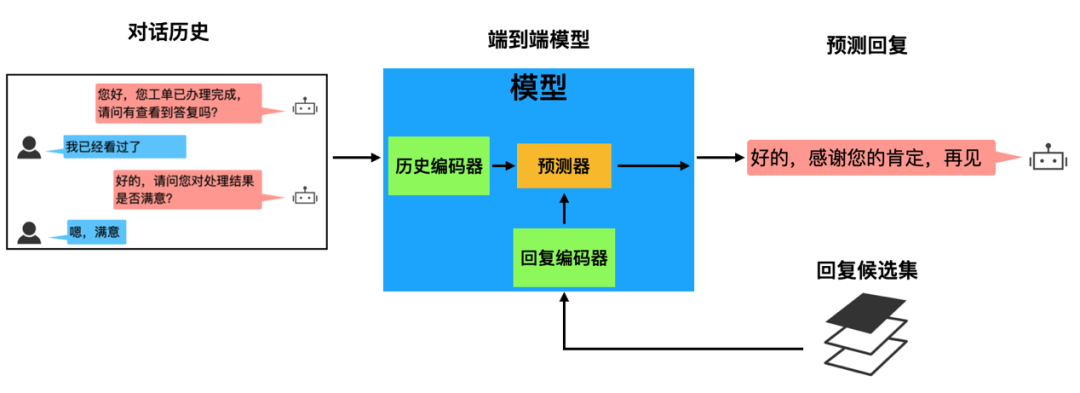
我们采用检索式端到端对话模型[4],该对话任务是一个分类任务,即给定预定义的回复候选集,基于对话历史选择正确回复。如下图所示,一般该模型一共包含三个部分:
历史编码器(History encoder),对整个对话历史进行编码提取对话状态向量,常见模型可以使用 MemN2N,Hierarical RNN,BERT 等 ;
回复编码器 (Response encoder),对每个回复进行编码提取句向量;
预测器,根据对话状态向量和回复句向量判断出正确的回复,通常就是计算余弦相似度给出。
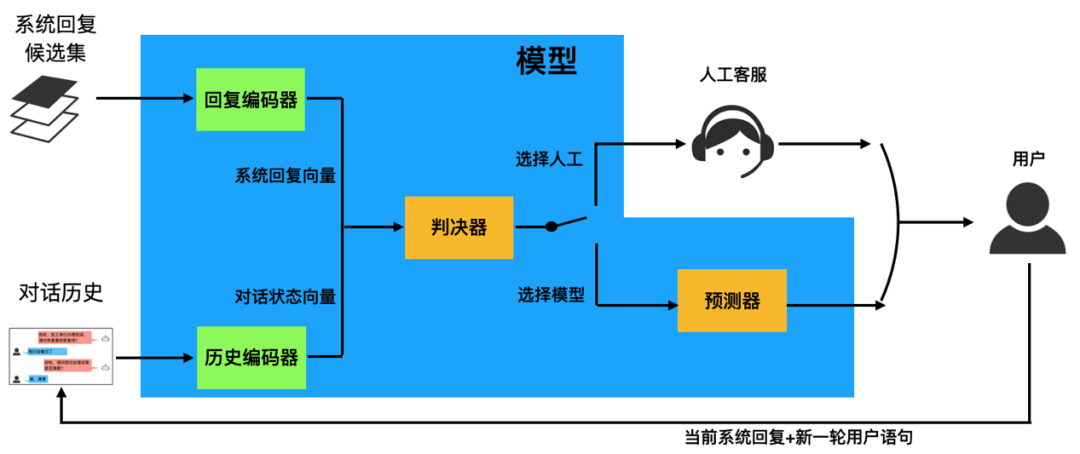
而在人机协同的框架下[1],为了能够做到智能高效地转人工,端到端对话模型还会多出一个判决器模块,专门用于判定当前对话是否转人工,如果转人工则交给人工客服解答,否则模型自己给出答案。如下图所示:
2. 优化方案
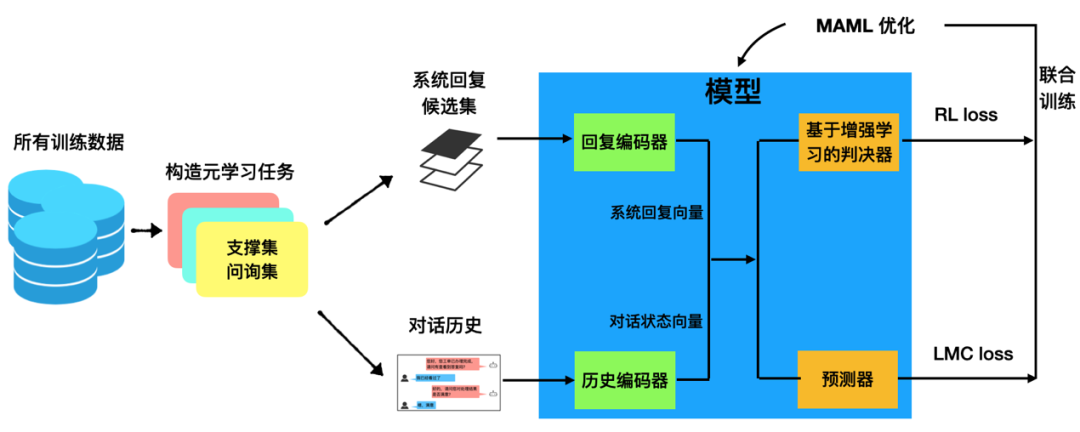
在ACL2020论文中,为了和文献 [1, 4] 一致,对于历史编码器我们仍然采用经典的 MemN2N 模型,对于回复编码器我们使用了一个简单的词向量相加的句向量。模型预测器的部分,我们选择了能够学习出更有鉴别性的特征的large margin cosine loss [7] 作为损失函数 Llmc 。针对请求人工的判决器,我们提出通过计算判决器预测的正负样本的 F1 score作为 reward 函数,使用增强学习来进行优化 Lrl 。最终,我们利用MAML对 Llmc+Lrl 进行联合优化。
MAML 是元学习中的一类方法,它具备模型普适性,通过在meta tasks上进行预训练,能够帮助模型找到一组最合适的参数,使其快速适应新任务。例如下图[9]给出了一个 MAML 和MLE 训练对比示意图,每个圆圈都是看做一个场景,实心的是训练用的源场景,空心的是测试用的目标场景,使用 MLE 预训练会导致模型的参数过拟合到源场景上,而MAML预训练则能够找到更好的参数初始化,使得快速迁移到新场景上去:
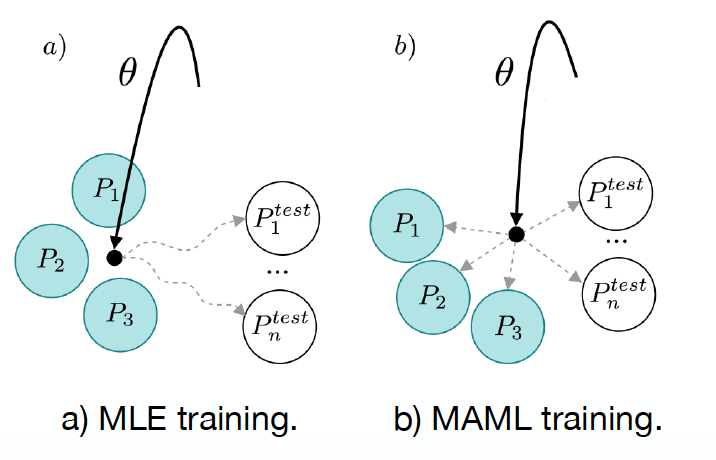
正是因为这样的特性,我们选择 MAML 来进行联合优化,帮助预测器和判决器一起快速适应新场景。
在 MAML 训练中,首先需要构造元任务 (meta-task),步骤如下:
采样 K 个对话场景 (每个场景对应一个对话任务)
每个对话任务,采样 N 个对话数据作为支撑集(support set),N 个数据作为问询集(query set)
然后根据以下算法流程进行优化:

03
模型结果
为了验证模型在新场景的迁移能力,我们需要多场景的端到端对话数据集,在评价时,依次选取一个场景作为目标场景,剩余的作为训练场景。利用 MAML 预训练模型完毕之后,再在目标场景上进行小样本的迁移实验。最终结果是每个场景取平均得到。我们既需要在学术数据集上实验,也需要在实际业务中落地,以此验证算法的可行性。
1. Extended-bAbI数据集结果
学术数据集我们选择了extended-bAbI,它是 bAbI 数据集的扩展版,包含了场景有餐馆、机票、酒店、电影、音乐、旅游、天气等 7 个场景,每个场景的训练集/开发集/测试集为 1500/500/1000 个完整对话,评价指标是回复选择的准确率。我们将 MDS、MDSmle(将MAML优化改成 MLE 优化)、Mem+C [1] 这三个模型进行对比如下:
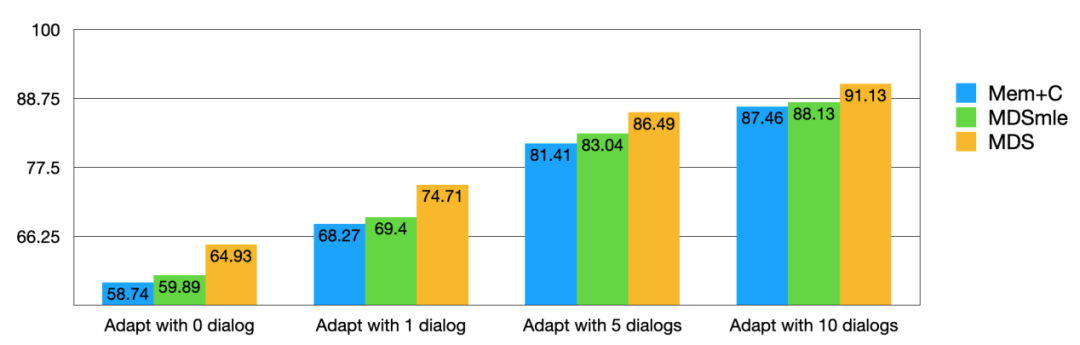
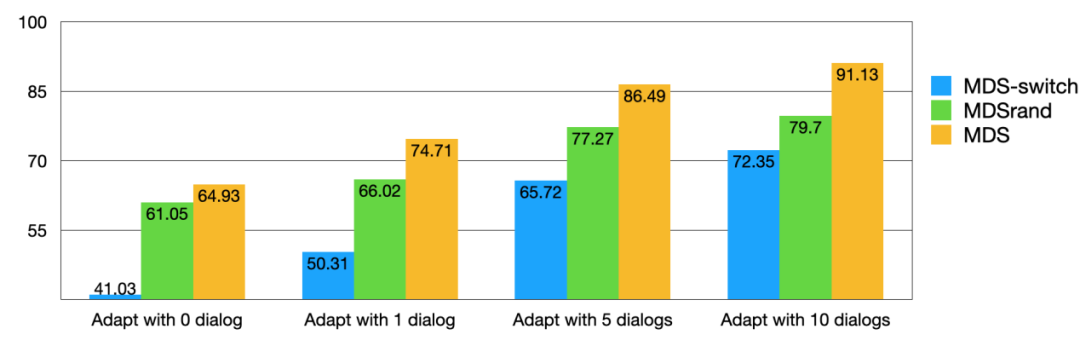
平均在新场景中,使用 0, 1, 5, 10 组完整对话 session 数据上,MDS 模型的表现都是最好的。证明了我们小样本下端到端模型的效果。同时我们也做了一下 ablation study,发现去掉判决器 (MDS-switch) 和随机转人工 (MDSrand) 的模型都很差,证明了我们的转人工判决器真的能够在联合优化中学出识别 out-of-script 的对话数据的能力,提升模型的鲁棒性。
2. 业务落地
我们的端到端对话模型 MDS 目前已经在Dialog Studio平台上政务12345的多个场景中落地,对话的完成率平均能有5-10% 的提升。通常我们遇到的实际业务的流程schema是一个较为复杂的图状结构,下图是一个简化的示意图:
这种图结构流程(我们称为 TaskFLow)在 Dialog Studio 里能够通过图形化拖拽的方式非常方便地进行配置使用。详见《一个中心+三大原则 -- 小蜜这样做智能对话开发平台》。
实际场景往往一开始时是零对话数据,尽管 MDS 模型能够进行冷启动,有比一般模型更好的效果,但是并不一定能够百分百达到上线准入要求。为了更好地利用我们模型的迁移能力,我们通过以下两步来预训练对话模型:
我们设计了一个基于TaskFLow 的对话模拟器,能够低成本快速地模拟出大量模拟对话数据。该对话模拟器利用生成模型生成对话数据,并能够通过线上回流的无标日志进行模拟器的自增强优化。
当一个新场景的模拟数据模拟完毕后,我们把新场景的模拟数据和各个已有相似场景的真实数据一起作为源场景进行 MAML 优化,然后迁移到新场景的真实数据中去。

下图是我们模型在某地市12345热线场景的一个实验结果:
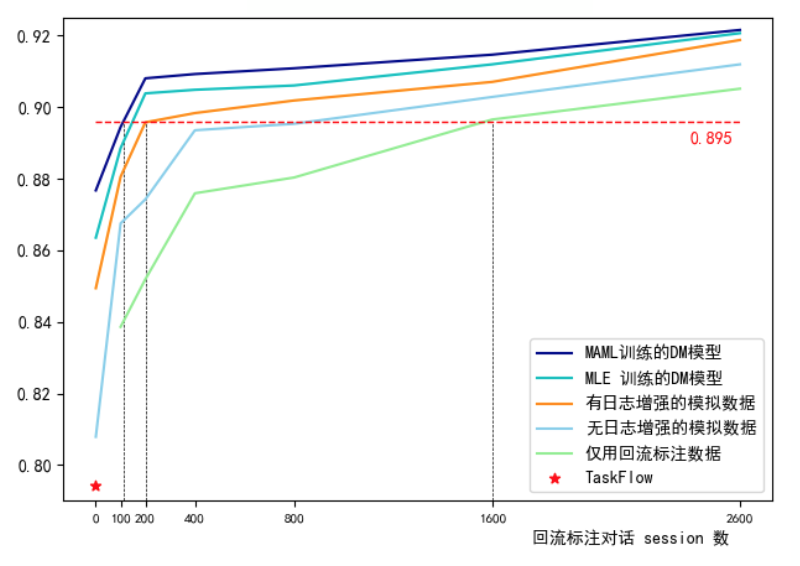
横轴是adaptation时使用的标注对话数据量,纵轴是回复准确率。可以看到,如果直接使用 TaskFlow,整个对话系统的准确率仅在 79% 左右。但是用上MDS 模型进行数据迁移和MAML 优化之后,我们可以得到最上面那条曲线,冷启动效果从 79% 提升至88% 左右,并在不同 adaptation对话数据下都能有着持续最好的表现。
04
总结展望
本文主要介绍了如何结合元学习方法提高对话模型在新场景上的快速适应能力和预测效果,解决小样本下的端到端对话模型训练问题。我们的元学习对话系统(Meta-Dialog system,MDS),不仅在学术数据集上进行了实验,还在阿里云智能客服的多个真实场景中落地。结果表明,利用 MAML 可以很好地帮助模型的判决器和预测器一起找到合适的初始化参数,以更快地迁移到新场景中。
最后感谢所有耐心看完这篇文章的读者。智能对话系统是个极具前景和挑战性的方法。达摩院 Conversational AI团队将不断地探索推进在这个领域的技术进步和落地,敬请期待我们后续的工作!
05
参考文献
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“元学习对话” 可以获取《达摩院基于元学习的对话系统》专知下载链接索引






