专访 | 监管机器翻译质量?且看阿里如何搭建翻译质量评估模型
机器之心原创
作者:思源
随着机器翻译在真实场景中的应用越来越多,翻译质量评估模型也受到很大的关注。近日,阿里巴巴达摩院机器智能技术实验室的陈博兴博士向机器之心介绍了机器翻译质量评估竞赛与模型,他们凭借着 Feature Extractor-Quality Estimator 框架与完全注意力机制等方法在国际机器翻译大会 WMT 组织的质量评估竞赛上取得了优异的成绩。
阿里机器翻译团队在本次比赛中,参加了英语到德语和德语到英语两个语向的句子级别和词级别的七项质量评估任务,收获了六项世界冠军。其中,德语到英语的统计机器翻译评估任务中(German-English SMT),句子级别和词级别的预测任务分别取得第一名;英语到德语的统计机器翻译评估任务中 (English-German SMT),句子级别取得第一名,词级别的词预测和漏词预测分别取得第一名。同时,英语到德语的神经网络机器翻译评估任务中 (English-German NMT),词级别的词预测取得第一名。
对于翻译质量评测方法来说,可能读者最熟悉的就是 BLEU 值,它的核心思想即机器翻译的译文越接近人类专业译文,那么翻译的效果就越好。所以从本质上来说,BLEU 值仅仅只是在计算机翻译文与参考译文之间的相似性。此外,虽然 BLEU 值计算非常迅速,但它仅考虑词语层级的统计相似性,常忽略了语义和语法等特征。且其它如常用词、译文长度、同义词等很多情况都会影响到 BLEU 值的评判,因此它其实只能评估机器翻译模型与参考译文之间的大致相似度。
计算 BLEU 值最重要的是提供参考译文,参考译文质量越高,对于同一句原文的参考译文越多,翻译模型的度量就越准确。但很多情况下高质量参考译文很难获得,或者成本非常高,而且更多的实际运用场景中,用户输入的原文是无法及时提供参考译文的,这种情况下就需要一种没有参考译文也能评估翻译效果的方法。
Machine Translation Quality Estimation 就是这样一个由 WMT 发起的机器翻译质量评估比赛,它要求在不提供参考译文的情况下,根据原文和机器翻译译文评估译文质量的好坏。
除了竞赛,不需要参考译文的评估方法在实际中有非常广泛的应用,陈博兴表示这种自动评估方法可以评估译文的质量,用于判断译文是否可以直接发表,是否可以让读者理解,是否需要后续人工编辑,并辅助译员翻译。如果质量太差,那么这一句话就需要重新翻译且不适合做人工编辑,如果只需要少量改动,那就比较适合做人工编辑。甚至对于词语级别的译文评估方法,它能告诉我们到底哪一个词需要改进。此外,限制质量较差的机器翻译的译文输出、评估机器翻译模型效果等都需要这种不需要参考译文的评估方法。
翻译质量评估
翻译质量评估任务一般可分为两种,即句子级的评估和单词级的评估,阿里机器翻译团队这次参与的竞赛同样也分为这两种任务。其中句子级的质量评估需要使用回归模型给译文句子的整体水平打分,而单词级的任务需要分类模型标注每一个词到底翻译得好不好。完成这两种评估任务的方法也有许多,但总体上都是通过抽取原文与译文的特征,并计算它们之间的匹配程度。
以前常见的研究是使用手动抽取的质量评估特征,并馈送到回归或分类模型以得出译文的分数或类别。这些质量评估一般包括长度特征、语言特征和主题模型等特征,它们可能还会通过主成分分析和高斯过程等方法进行选择。
而自深度学习变得流行以来,很多研究者尝试使用深度神经网络自动抽取质量评估特征并完成评分。Kreutzer 等人首先在 2015 年提出基于窗口的 FNN 架构,它以窗口的方式抽取语义特征。在基于窗口的方法中,给定目标词,我们从原语和目标语的对应位置中获取双语窗口,其中目标语窗口的中心词就是该目标词,而原语窗口的中心词即目标词对应的原语词。所有双语窗口下的词将会以 one-hot 编码的方式馈送到输入层,并进一步计算出当前窗口的双语匹配程度。
Patel 等人随后在 2016 年提出基于循环神经网络架构的质量评估模型,在该模型中,他们将单词级的质量评估模型视为序列标注任务,且同样采用了基于双语上下文窗口的方法。其中上下文窗口的所有词需要作为输入,并借助循环神经网络建模它们之间的依赖性关系,并最后输出标注序列以判断每个单词是不是翻译正确。
随后很多研究者开始使用卷积神经网络、双向 LSTM 网络和注意力机制等深度学习方法,Martins 等人在 2017 年结合神经网络模型与富特征线性模型在质量评估模型上获得了非常好的效果。但阿里采用的模型并不基于上下文窗口,他们参考了最近提出的自注意力机制和 Transfomer 机器翻译的模型框架,在前人研究的基础上提出了一种名为『Bilingual Expert』model (『双语专家』模型) 作为特征抽取器,联合基于神经网络的译文质量评估框架。后面我们将从这两方面重点关注这一框架,并探讨阿里达摩院对它们的优化。
特征抽取模型
特征抽取即从原文与译文语句中抽取足够的信息或特征,并用来进一步计算译文效果到底好不好。因此特征抽取是翻译评估模型的核心,特征的好坏直接影响了翻译评估的准确度。不过在理解特征抽取以前,我们先要了解整个『Bilingual Expert』based Feature Extractor + Quality Estimator 框架,这样才能知道为什么能通过神经网络抽取原文和译文的语言特征。
『Bilingual Expert』based Feature Extractor + Quality Estimator 由特征抽取模型和译文评估模型组成,因为这两个模型解决的是两个任务,所以它们能使用两种数据集进行训练。特征抽取模型在输入原句序列和目标句序列的条件下抽取质量评估特征,这一部分的训练需要使用一般的双语平行数据集。而特征抽取模型抽取的特征可继续用于评估翻译效果,这一部分需要使用质量评估(QE)数据集,该数据集不仅包括原句与译文句,同时还包括了标注的翻译质量。
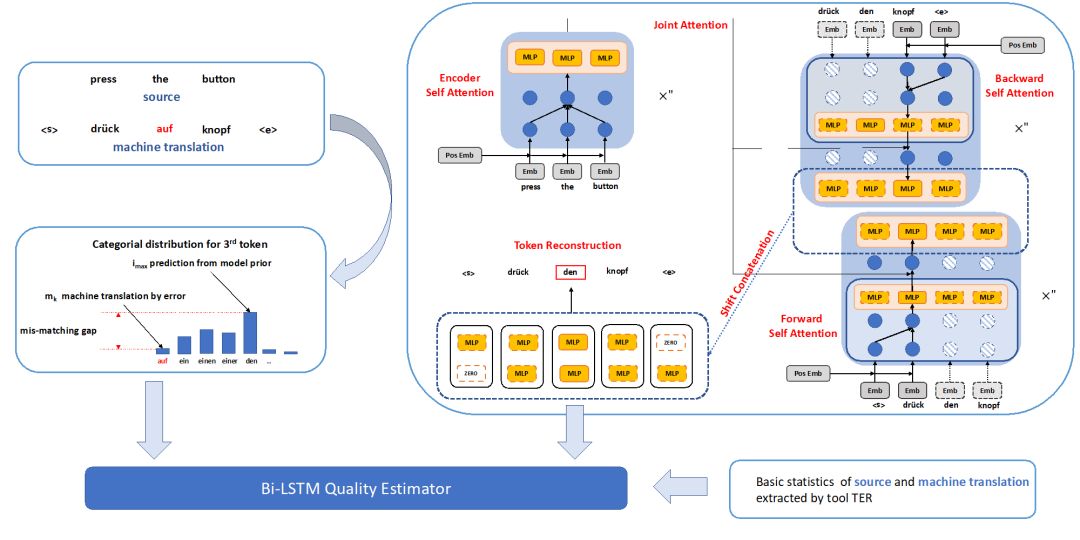
阿里达摩院在这次竞赛中采用的结构,特征抽取模型与评估模型使用 Transformer 与双向 LSTM 的框架进行修正。
对于特征抽取,『Bilingual Expert』(图上右上框)模型构建了一种条件语言模型。简单而言,在给定原语句子所有词和目标语句除当前词以外的上下文,模型希望能使用这些词的信息预测出当前词。这一过程潜在的假设即条件语言模型与质量评估模型高度相关,它能传递有用的信息来执行质量评估任务。陈博兴表示,我们可以直观地理解为,如果译文的质量非常高,那么这种基于条件语言模型的词预测模型能基于原句子和目标句子的上下文准确预测出当前词。相反如果译文质量不高,那么模型很难基于上下文准确地预测出当前词。
给定原语句子和目标语句子的上下文,并预测目标语句子的当前词可以表述为如下方程式,阿里机器翻译团队使用了在《Attention is all you need》中提出的 Transformer 建模这一方程。

之所以将传统的双向 LSTM 模型替换为最近比较流行的 Transformer,陈博兴表示:「LSTM 是以递归方式进行的,适合序列建模任务,需要逐步递归才能获取全局信息。这就导致了计算过程很难并行,计算效率较低。因此我们采用了完全基于注意力机制的结构来处理序列模型的相关问题,这样不仅能挖掘序列内部的隐藏关系,同时还能提高并行效率。」
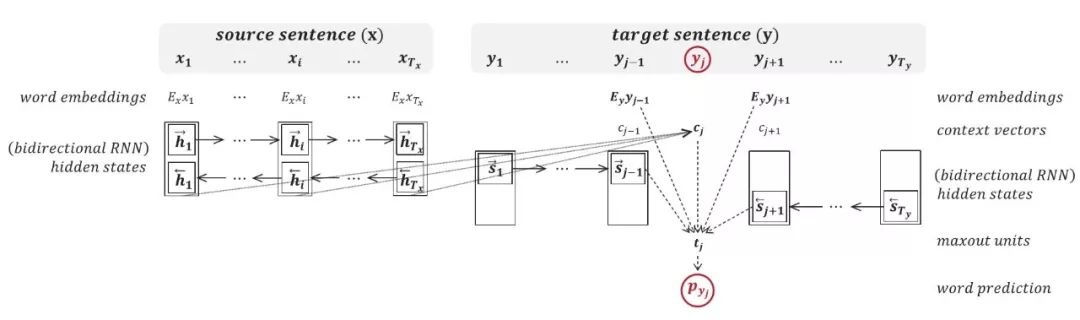
尽管使用 Transformer 构建词预测模型有更多的优势,但从 LSTM 出发能更好地理解词预测模型的过程。下图所示为基于 LSTM 的词预测模型,它期望能准确预测目标语句子中的第 j 个词。
如下对于原语句子 x,模型首先将每一个词都表征为词嵌入向量,然后再馈送到正向和反向两条 LSTM,每一个时间步需要同时结合正向和反向 LSTM 的隐藏状态并作为最终的输出。对于目标语句子 y,在第 j 个词之前的序列使用正向 LSTM 建模,而第 j 个词之后的序列使用反向的 LSTM 建模。最后在预测第 j 个词时,需要使用原语句子 x 的上下文向量 c_j(由注意力机制得出)、目标语前一个词及前面序列的语义信息、目标语后一个词及后面序列的语义信息。
阿里机器翻译团队采用 Transformer 的架构进行建模,该架构不仅在原文和译文端之间进行注意力机制的计算,同时原文和译文内部也引入自注意力的机制,使得两端深层的语义信息能够很好得被学习到。除此以外,『Multi-Head』注意力机制的结构能够使网络中每一层对不同位置的计算是并行的,大大提高了学习效率。陈博兴表示,在对原文进行编码的过程中,编码器由相同的两个模块构成,每一个模块都有两个子层级。其中第一个子层级是 Multi-Head 自注意机制,第二个子层级采用了全连接网络,其主要作用在于注意子层级的特征。同时,每一个子层级都会添加残差连接和层级归一化。
在对目标端解码的过程中,阿里机器翻译团队创新地进行了基于 Multi-head Attention 的双向解码。陈博兴表示,每个方向的解码器也由相同的两个模块堆叠而成。与编码器区别的是,每一个解码器模块都有三个子层组成。第一个和第三个子层分别与编码器的 Multi-Head 自注意力层和全连接层相同,而第二个子层采用了 Multi-Head Attention 机制,使用编码器的输出作为 Key 和 Value,使用解码模块第一个子层的输出作为 Query。与编码器类似的是,每一个子层同样会加上残差连接与层级归一化模块。该思想可以理解构造了一个双向的 Transformer,而其真正作用不是翻译系统中的解码器,而更像一个编码器或者特征表示器。

上图所示为 Transformer 原论文中介绍的网络架构,阿里机器翻译团队将其采用为『双语专家』条件语言模型的基础网络。Transformer 编码器的 Inputs 为原语句子序列 x,解码器输入的 Outputs 为目标语正向和逆向两个序列。此外,解码器中 Softmax 输出的概率表示目标端当前词预测。在阿里采用的架构中,编码器和解码器的层数都等于 2,即图中的 N=2。
每一次在预测目标语的当前词时,Transformer 需要使用正向与反向两部分信息。陈博兴表示若当前预测目标语的第 j 个词,对于正向序列而言,模型需要使用目标端第 j-1 个词的前向深层语义特征向量和第 j-1 个词的词向量。而对于反向序列而言,模型需要使用目标端第 j+1 个词的反向深层语义特征向量与第 j+1 个词的词向量。
总体而言,在阿里的模型中,利用预先训练的专家模型,先抽取基于模型隐层的一些 high level 表示信息,以及该词的前后词的词向量,最后再通过一个全连接层做一次线性变换。除此之外,阿里还构造了 mis-matching features。如下图所示,当某个翻译结果错误单词不多的时候,预训练模型会给出正确的单词预测分布,这和翻译结果激活的单词会存在一个 gap。这个 gap 是一个非常重要的特征,阿里机器翻译团队的实验显示就算只用这个特征去做下一步预测,也可以得到很好的结果。详细内容可以参考阿里机器翻译团队的论文:“Bilingual Expert” Can Find Translation Errors [1]。
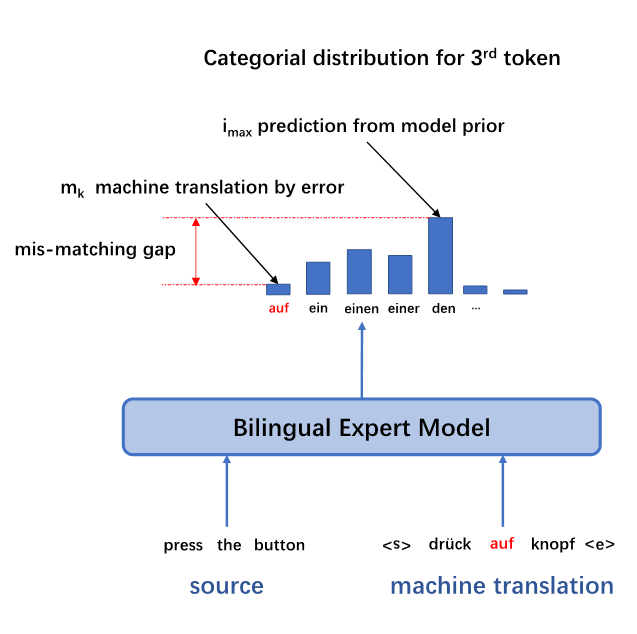
其实阿里机器翻译团队采用的这种双向解码机制有非常优秀的属性,它相当于迁移了一部分语言的知识。最近很多研究者都提倡以语言模型作为预训练基础模型将语言知识迁移到不同的 NLP 任务,阿里采用的这个结构正好体现了这种想法。在预测第 j 个词时,j+1 和 j-1 两个深层语义特征向量都相当于使用预训练的语言模型抽取语言特征,而那两个词的词嵌入向量则保留了原始信息。
除了需要预测最可能的当前词,更重要的是需要通过质量评估特征向量为后续运算迁移足够的语言知识。因此阿里的模型从词预测模型中抽取了两种质量评估特征,除了深层语义特征外,考虑到目标端词预测的概率能表示当前词出现的可能性,还额外抽取了如下的 mis-matching 特征:
1. 深层语义特征:
正向深层语义特征向量
反向深层语义特征向量
前一个词的词向量
后一个词的词向量
2. Mis-matching 特征:
目标端强制解码为当前词的概率信息
概率最高词语的概率信息
强制解码为当前词与解码为概率最高词的概率信息差异
当前词与预测词是否一致
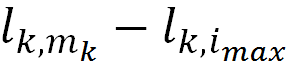
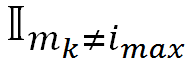
其中正向和反向深层语义特征都从 Transformer 的解码器中抽出,正向语义特征 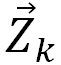
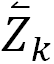
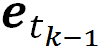
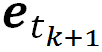
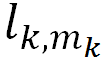
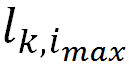
质量评估模型
在抽取了质量评估特征后,它们可以与人工抽取的特征一起作为质量评估模型或 Quality Estimator 的输入来计算译文质量。不过既然基于条件语言模型的特征抽取模型和质量评估模型有紧密的联系,那么为什么不能将这两个模型联合在一起实现端到端的训练呢?陈博兴表示如果做端到端的训练,很多人工添加的特征是无法使用的。此外,特征抽取模型广泛使用的平行语料与质量评估模型使用的 QE 数据集有比较大的不匹配性,联合训练可能会产生较差的性能。这一点也非常直观,平行语料只包含正确的目标语句子,而 QE 数据集同时包含正确与不正确的目标语句子。
正因为特征抽取模型和质量评估模型虽然高度相关,但还是两个独立的模型,所以我们能额外手动提取一些特征来提升模型效果。这些基础特征包括句长、标点符号数量、句子语言模型分数等,因此除了第一阶段提取的特征外,阿里还额外融合了 17 个人工提取的特征,与之前隐层合并结果再次合并作为预测条件。
若将所有特征向量都拼接在一起,且每一个特征向量视为一个时间步,那么我们就能以如下方式利用从原文与译文中抽取的语义信息。
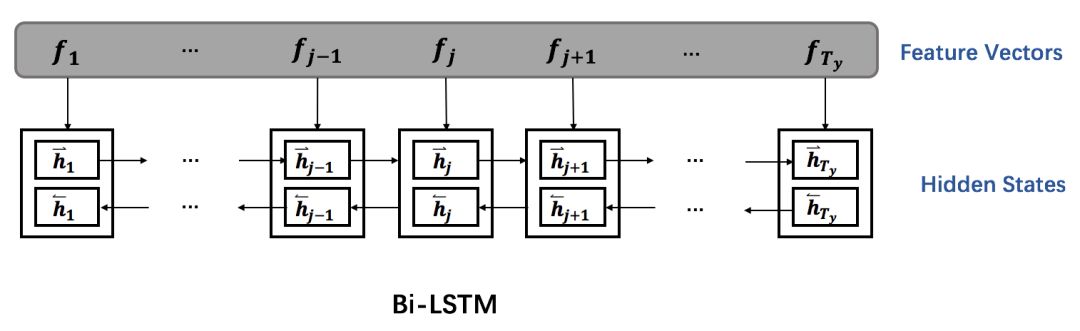
阿里机器翻译团队采用的质量评估模型就是基于双向 LSTM,模型预测的目标即句子层面的翻译质量和单词层面的翻译对错。其实这两个任务除了评估阶段采用的架构不一样,其它如特征抽取等过程都是一样的。在句子层面中,biLSTM 编码的前向的最后一个时间步与后向的最后一个时间步的隐藏特征联合计算一个实数值以表示翻译质量,而在词语层面的评估任务中,biLSTM 编码对应的 目标端词的每一个时间步的前后向量隐藏特征联合计算一个值以将它们分类为 OK 或 BAD。
数据与应用
整个翻译评估系统需要使用两种数据,即词预测模型所使用的平行数据集和评估模型所使用的 QE 数据集。其中平行数据集可以在广泛的领域收集,我们的目的是训练一个能抽取语言语义信息的模型,这很类似于预训练一个强大的语言模型。
而 WMT 组委会提供的 QE 训练数据只有 1 至 3 万,这对于训练一个强大的鲁棒性翻译质量评估模型是远远不够的。陈博兴表示阿里机器翻译团队在英德和德英语向上分别构造 了 30 万左右的 QE 训练伪数据。这部分数据与真实 QE 数据合并训练完质量评估基线模型后,会再使用真实的 QE 数据微调模型,即使用一个在大的数据集上预训练好的模型在真实场景数据上微调。
阿里机器翻译团队参考了一些 WMT Automatic Post-Editing (APE)任务的方法。采用了一种 round-trip translation 的技术。先从大量单语数据中筛选出领域相关的单语,作为人工后编辑译文 PE;同时用双语语料训练两个 MT 系统(例如,如果要做英语到德语的翻译质量评估,需要训练德语到英语和英语到德语的机器翻译系统)。将筛选的领域单语先通过一个 MT 系统生成原文 SRC;SRC 再通过另一个 MT 系统生成译文 MT。这样两次调取 MT 结果的方法,生成了一批原文,译文和人工后编辑译文组合的 APE 数据,称为 APE 训练伪数据。然后他们通过 TER 工具生成了对应的 HTER 分数和词标注,构造出了 QE 伪数据。为了更好地模拟真实数据,他们根据真实 QE 数据的 HTER 分布,从构造的伪数据中随机挑选出 30 万。这些伪数据先与真实的 QE 数据一起训练一个 Quality Estimator 的基础 Baseline 模型,再单独用真实的 QE 数据 fine tune 模型。
最后,开发这样一个翻译质量评估系统肯定是需要投入应用的。陈博兴表示翻译质量评估模型可以应用在很多业务上,例如它可以判断翻译系统给出的结果是不是足够优秀,能不能直接展示给用户。如果质量不行的话,译文就可能需要人工校对。这对阿里的商品翻译是非常重要的,因为如果产品品牌、买卖价格、产品描述等机器翻译出现了误差,那么很容易引起业务上的纠纷。
此外,由于 BLEU 值只能评估有参考译文的翻译结构,这种翻译质量评估系统能更广泛地辅助机器翻译或人工翻译。陈博兴表示该系统还可以更直接地评估数据,因为网上收集或购买的数据可能并不能保证质量,所以该系统可以充当过滤作用而确定能投入训练的高质量双语数据集。总而言之,阿里在利用高质量双语数据集与 QE 数据集训练质量评估模型后,它反过来可以评估其它双语数据,并将优秀的数据投入翻译模型的训练与质量评估系统的训练。

除了在 WMT 翻译质量评估上获得的荣誉,此前阿里达摩院机器智能自然语言智能团队还在 2017 年美国标准计量局英文实体识别,2018 年机器阅读理解首次超出人类回答精准率,2018 年 WMT 国际机器翻译大赛等技术大赛上获得十余个冠军。并以「让商业没有语言障碍」为理念,推动学术与工业界的融合创新。
参考文献:
“Bilingual Expert” Can Find Translation Errors, https://arxiv.org/pdf/1807.09433.pdf
Predictor-estimator: Neural quality estimation based on target word prediction for machine translation, Hyun Kim, Hun-Young Jung et al.
Attention is all you need, https://arxiv.org/abs/1706.03762
Semi-supervised sequence tagging with bidirectional language models, https://arxiv.org/abs/1705.00108
Log-linear combinations of monolingual and bilingual neural machine translation models for automatic post-editing, https://arxiv.org/abs/1605.04800
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

