讲堂| 童欣:数据驱动方法在图形学中的应用

你离成为人工智能专家,还有多远的距离?
近日,四位来自微软亚洲研究院的AI大咖在中国科技大学进行了一场以“开启智能计算的研究之门”为主题的前沿分享。这四位嘉宾分别是:
● 首席研究员刘铁岩——人工智能的挑战与机遇
● 资深研究员谢幸——用户画像、性格分析与聊天机器人
● 首席研究员童欣——数据驱动方法在图形学中的应用
● 首席研究员曾文军——当机器学习遇到大视频数据
上周,我们发布了刘铁岩博士的演讲——人工智能的挑战与机遇,和谢幸博士的演讲——用户画像、性格分析与聊天机器人 。
本周,我们会继续在本账号中发布另外两位研究员的演讲视频及精彩内容,希望这些关于前沿技术的思索能够开启属于你的智能计算研究之门,敬请期待!
第三位与大家分享的是童欣博士的演讲——数据驱动方法在图形学中的应用,全文如下(文字内容略有精简)。
今天报告的题目是数据驱动方法在图形学中的应用。
我所在的组叫做网络图形组,主要在做一些跟图形相关的东西。我们希望达到三个目标,以研发一些新的图形方面的解决方案。
第一,我们希望每一个人都可以很轻松地产生、分享和去享受这些三维的内容,比如像左边这个,是如何在Kinect上通过一些手势的模拟操作,来产生一个三维的Avatar,用户可以产生各种形象,还可以驱动它去做动画。

第二,人都生活在真实世界里,以前我们通过一个计算机屏幕和虚拟世界打交道,现在我们希望能够打破这个界限,通过一些新的设备和新的交互方式在真实世界和虚拟世界之间提供一个更自然的交互方式,比如HoloLens,通过手势等很自然地交互,它可以把虚拟的物体展示在一个真实世界里,和真实世界混合在一起。
第三,除了可视的世界之外,还有很多抽象的信息,我们希望能够把这些抽象的信息经过可视化技术展现出来,提供一个良好的可视与非可视信息之间的交互方式,帮助用户通过可视的方式快速理解抽象的信息,获得想要的信息。为了达到这个目标,我们也做了很多努力。
在图形学的方面,传统的手段是physical based approach(基于物理的方法)。因为真实世界都是靠物理规律来控制的,所以过去图形学方面无论是光影效果,还是动画的效果,甚至水的声音,都通过对物理规律的计算来进行模拟,从而达到相应的效果。
这个方法很好,因为物理规律都非常的简洁漂亮,所以模型算法很干净。但它的缺点就是,为了模拟这些丰富的细节,计算量往往非常大,需要很昂贵的计算成本。而当我们很关心物体的视觉效果时,就会关注很多视觉细节。于是科学家们就把目标转向了另外一种方法——data based approach(基于数据的方法)。
这种方法就是通过研发一些设备,然后直接将真实世界中想要的信息进行捕捉。所以人们研发了三维扫描仪,从真实世界中获取几何形状,还研发了光穹设备来捕捉物体在不同光照、不同视点下的材质外观。还有动作捕捉设备等被广泛用于影视制作中,以捕捉人或物体的动态。
基于数据的方法有很多的优点,因为所有的数据都是直接从真实世界中获取的,所以它包含了所有细节,质量非常好,而且计算非常的简单、快速。但是这个方法也有缺点,需要捕捉的很多数据的维度都非常高,所以需要非常昂贵的捕捉设备以及复杂的设置过程,很多时候捕捉数据需要一间专用的实验室,上百万美元的设备才可以完成。
由于数据维度高,因此经常一个很简单的现象,需要捕捉很巨量的数据才能描述。数据量非常大,又缺乏对数据的理解,当编辑这些数据的时候,人们发现非常困难。因为无法修改、编辑这些数据,艺术家就没有办法去使用,只能捕捉成什么样就是什么样,这是它的另一个缺点。
在过去几年中,针对以上两个方法的缺点人们又研究了新的方法——data driven approach(基于数据驱动的方法)。该方法还是需要捕捉一些数据,当我们捕捉完成,则利用数据本质所蕴含的特性——本征特性来重构整个函数,以保持它的特点。
这个方法的好处是:第一,稀疏数据的捕捉,使得数据非常的紧凑、数据量少。第二,由于捕捉到了数据的本征特征,所以在做重构的时候,所有的细节都被保留了下来,从而使得结果质量非常高。第三,因为知道数据的本征特征,所以数据之间是有联系的,人们可以很容易地对数据进行编辑,同时还保持它的本征特征,以达到合理的结果。
那么这种方法的缺点又是什么呢?它的缺点就是如何找到数据的本征特征,这是需要研究的一个很困难的问题。在过去的几年中,我们也做了很多探索和研究,慢慢地我们发现利用机器学习技术可能是一个很好的方法。
接下来,通过我们在传统计算机图形学里面的三个大领域中所做的一些研究工作来展示如何通过数据驱动的方法来处理图形学问题的,包括:几何造型、真实感绘制和计算机动画。
首先是,几何造型和几何处理。这里展示的一个工作是几何去噪或者网格去噪,这个目标很简单,比如,用一台三维扫描仪把一个真实的大卫雕像扫描到计算机里。但由于扫描仪精度没有很高或者光照环境没有很好,所以扫描出来会发现雕像的表面并不光滑,有很多的噪声。如果想把这些噪声去除,一般情况下会做一个过滤,但过滤之后不仅噪声去除了,而且雕像的几何特征也丢掉了。
我们希望在去除噪声的同时保留原本的几何特征,这是我们的目标。而在算法上,我们希望算法越自动越好,而且最好足够快,这样用户按一个按钮就做完了。但我们却发现这个问题十分困难,为什么?
第一个难题是问题本身是歧义的。从单个模型本身,恢复两个未知量:噪声和没有噪声的模型。第二个难题是,不同物体的几何特点也各不相同、千奇百怪,所以很难给它一个定义或者约束。最难的一个问题是,不同的扫描设备、不同的光照条件所产生的噪声很难用一个简单的噪声模型去描述。
针对这个问题目前有成百篇的论文在研究。做了这么久,大家还在做是为什么呢?因为当人们把算法用到实际数据中时,发现它的效果并不好,因为大家基于的很多假设和约束只适合一些特定的情况。而我们的想法是拟合一个映射关系。假设我们能获得一些扫描过的带噪声的数据,然后用一个更高精度的扫描仪去扫描一个更好的模型,通过手工做成它的ground truth数据,我们希望从这些成对的数据中直接学习从噪声模型到没有噪声的模型的一个映射。这样我们不需要对噪声和模型做太多的约束和假设。
在这个方法中,我们发现如果直接学习一个映射关系可能很难,但用一个在机器学习中很常见的级联学习的办法,先学一个映射关系,这个映射关系可能不能完全去除噪声,那么我们先把这个模型重构出来,可它还是有点噪声。我们再学习这个带有噪声的模型和最终模型之间的第二个映射关系——G2’,G2’得到以后,我们再学习G3’,通过级联的方式逐渐迈向真实的模型来获得最终的多步映射关系。
有了这个关系之后,当给定一个新的带有噪声的三维模型时,我们只要把学习到的映射关系直接进行使用就可以自动获得一个已经去噪的结果。这个方法用在实际的数据测试中,大家可以看到,左边是一个Kinnect捕捉到的深度数据,最右边是它的ground truth,我们的方法是倒数第二个,一起比较是看不出是什么噪声的。

我们还做了更多的测试,发现我们的方法确实在大量的我们测试过的所有数据上,无一例外地好于现有的所有方法。更好的一件事情是,当我们把我们方法的速度和已有的方法进行比较时,会发现我们方法的速度远远快于其他的。
这里面关键的是我们完全从一个全新的角度去看待这个问题,于是才获得了比以前的方法更好的一个效果。
再来看看我们如何把数据驱动的方法用于真实感绘制的。真实感绘制可以说是计算机图形学中一个最核心的问题。这个领域就是给定一个三维场景,假设知道场景里各物体的材质从而产生一个像照片一样真实的、栩栩如生的绘制结果。
在这里面最大的问题就是全局光照(global illumination),我们需要模拟光线在场景中反射、弹射多次造成的结果。
举个例子,在今天这个会场,我们只有有限的光源,大家看到之所以很亮,是因为光线从光源打出来之后,在地板和墙面上弹射了很多次,把周围所有的地方都照亮了,所以大家才能看到这样的效果。
当我们把一个戒指或者很闪亮的东西放到桌上的时候,桌子上的反光会形成一些很漂亮的光斑,我们叫做散焦(caustics)。假设有光从窗户里面照进来时,在图中柜子顶上会形成由于反光造成的一个阴影,我们叫做间接光照阴影(indirect shadow)。另外,如图,厨房里面装修了一些铝合金的东西,很闪亮,当把东西放在上面的时候,光线会在里面弹射多次之后形成一些光泽材质间的相互反射(glossy inter-reflections),它反射多次之后会形成一些模模糊糊的倒影,所有这些效果在全局光照中都是非常难模拟的。

在传统中,要计算任何一个效果都需要使用最好的CPU去算几分钟,甚至几个小时的时间。同时,为了制作实时的动态效果,还需要支持移动的光照和视点。我们的目标就是实现实时的动态的全局光照效果。
这个问题的难点是什么?在示意图中,我们看到当两条从光源出发的光线打在物体上,在场景中进行交互的时候,他们的路径非常不同,虽然初射时只有很小的角度差别,但弹射多次之后,最后的落脚点可能彻底不同了。
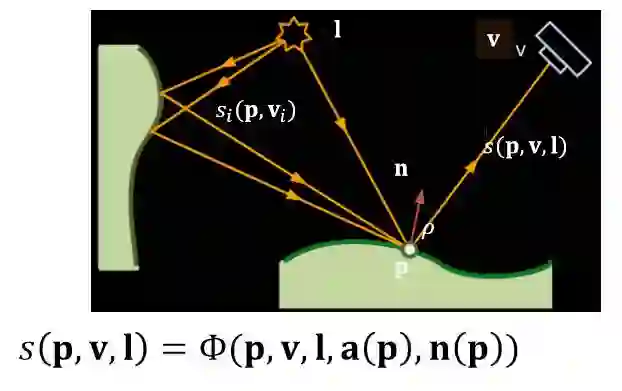
我们想做的一个方法是,不看物理原则,把绘制过程当作一个黑箱,做成从光照方向、视点方向、材质到最终图像的一个函数,然后看能不能学习这个函数,我们把这个函数叫做radiance regression fuction。这是我们第一次把绘制当作一个机器学习的方式来进行研究。给定一个场景,在场景中先绘制一些图片,利用这些图片学习我们定义的函数,等函数学习好了,当任意给出一个新的光照方向或者视线方向,该模型可以通过函数展示出物体在该光照或视线方向下的图像,可以想象这个函数就像一个画家一样。通过不断的临摹场景学会了场景在不同光照和视点下的图片。
为了建模这个函数并支持一个实时绘制的过程,我们选择了单层的神经网络。我们希望这个表达足够的简洁,越小越好,同时还希望这个计算能够做到实时。除此之外,我们发现场景还是很复杂,所以就把场景分成若干小块,每一小块再配一个神经网络。完成之后,我们发现我们第一次实现了实时的全局光照效果。我们绘制的这个卧室场景被很多离线的绘制程序设立为一个标杆。
我们所学习的这个映射不仅仅可以用来做绘制,在经过简单扩展后,我们也可以用它来学习做材质的编辑,比如前面的厨房场景,我们可以把后面的面板做到反光更强或者更弱一点,或者改变物体的颜色,人们可以实时地看到非常真实的光照效果。这个研究的应用对影视制作,装修设计等等都非常有用。
之后,我们还把这一技术用于实际拍摄的光照环境中,同样用神经网络的方法对简单的图像进行学习之后再做重新打光,可以叠加一个新的光照效果。
最后我们来看看,如何在计算机的动画中应用数据驱动的方法。下图是一个实时的3D面部追踪(facial tracking)。当捕捉到人面部动作的三维模型之后,我们就可以实时地把它使用到另外一个虚拟的角色上,让这个虚拟角色跟着人的动作来活动。
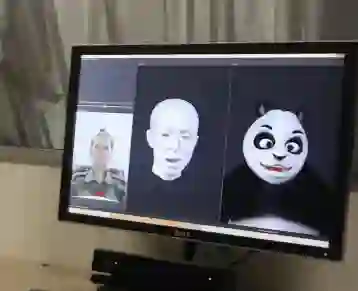
为了更好的实现这个效果,我们希望我们的算法或者系统有几个特性:
第一,我们希望这个系统是与用户无关的。也就是说任何一个新用户来使用这个系统,都可以立即实现,无需经过任何训练。
第二,我们希望这个系统能够鲁棒。比如,当用户把某个部位遮住时,系统还能够把三维的人脸和动作恢复出来。
最后,我们希望当只有用户的声音时,系统也能把人脸的动作,至少嘴部的动作可以恢复出来。

这个研究的难点是什么?有人说很简单,拿语音信号直接对应嘴部运动就可以了。但人的声音很有意思,不同人在发同一个音的时候,发出的声音信号可以看起来一点都不相似,这是第一个难点。第二个难点是,语言学家和声学学家研究发现人说话的时候有一个很重要的东西——协同发音(Co-articulation)。就是指当发同一个音的时候,根据前后音的不同,嘴的形状会完全不同。这就意味着光靠一个音是不行的,我们必须知道前后的词语和语句,才能决定嘴型。
第三个难点是,不同的人,人脸的形状是不一样的,所以嘴形的运动可能也不太一样。如果想做一个与用户无关的系统,那么如何有效地建造从语音到唇型的模型?
对此,我们的方法是借助三个模型。
第一,用实时的DNN模型来处理语音,从语音中抽取一个与用户无关的音频特征。
第二,是用多元线性面部模型(multi-linear face model),抽取一个与用户无关的表情特征。
基于这两者,我们希望最后来构建一个从语音到唇型变化关系的模型。有了这样的模型之后,新的用户来使用时,我们首先根据视频来恢复他人脸的三维形状,再根据他的音频来重建他的唇型。模型会按照重要程度和可信程度来进行叠加,之后生成最后的结果。使用我们的这个方法,也第一次做到当人的嘴巴被遮住时,我们同样可以恢复嘴部的运动,如果能从音频里再恢复一些情绪特征,模型甚至可以做一些表情来。
以上,我们讲了数据驱动的方法以及一些图形学的应用。但实际上这个领域的研究才刚刚开始,我们还面临着很多挑战。首先,如何产生高质量的数据还是一个很大的问题;第二,比如做绘制的时候,针对每一个场景,我们都需要训练一个神经网络模型,未来我们希望可以训练一个更通用的、与场景无关的模型。第三,在做造型或者生成图形应用时,如何把用户的意图通过学习的方法注入到系统里,让系统更加自动。我们也欢迎大家加入到研究中来,和我们一起努力达到我们的愿景!
谢谢大家!
你也许还想看:





