【人工智能】自然语言处理方法与应用、通俗理解生成对抗网络、十大深度学习技巧
自然语言处理方法与应用
AI科技评论

2018 中国人工智能大会(CCAI 2018)于 7 月 28 日-29 日于深圳召开。「过去未去,未来已来」,李德毅院士在 CCAI 2018 开幕式上对人工智能的发展寄予极高的期待,认为未来人工智能必将给人类带来全新的启迪。
CAAI 副理事长、中国科学院院士谭铁牛在开幕式致辞中同时强调,「理性、务实」是未来人工智能的重要路线。他也希望中国人工智能大会能给与会观众以充实的视听盛宴与丰富的心得体会。
在 2018 中国人工智能大会(CCAI 2018)首日下午的专题论坛上,苏州大学特聘教授、国家杰出青年科学基金获得者张民做了题为《自然语言处理方法与应用》的大会讲座。在这场长达两个小时的讲座上,张民教授围绕 AI、自然语言及 NLP,还有相应的方法、应用及展望,向与会观众分享了自然语言处理的相应研究。雷锋网 AI 科技评论整理了张民教授的讲座概要及部分精华内容,以飨读者。
一、AI、自然语言和自然语言处理
从农业社会、工业社会到信息社会,从数据到信息、到知识到智能的演变,代表了人类社会的巨大进步,展现了人类对于不同概念的诠释与理解的演变:
数据可以理解为人类对主观/客观世界事物的数量、属性、位置及其相互关系的抽象表示;信息是具有时效性的、有一定含义的、有逻辑的、经过加工处理的、对决策有价值的数据流,也就是加工后有逻辑的数据。而信息的丰富性决定了我们需要将它抽取、凝练为知识;但拥有用知识去解决问题的能力,才真正叫做智能。从历史的长河来看,人工智能的产业成熟曲线及人类的认识体系,是在经历「人类要毁灭」的恐慌(发现人工智能的能力超出想象)与大呼「骗子」的顿悟(发现人工智能的局限性)的反复中循环提升的。在张民教授来看,这两种极端的观点都只能部分代表人工智能的观点和看法,不应以偏概全。

人工智能的内涵和外延:
能够讲清楚什么是人工智能很重要。在张民教授的理解中,按照李德毅院士的观点,人工智能的外延包括机器人与智能系统。而内涵包括如下四个层面:
底层是脑认知基础,上层是以知识工程为核心的知识建模、获取和推理;
中间有两个同样重要的内容,一个是感知智能,即机器感知和模式识别;另一个是认知智能,也就是自然语言处理和理解。

人的进化与语言的关系
从感知、认知到进化,人为何能步入食物链的顶端?因为人类有语言,语言使人类区别于动物。语言的本质就是一套符号系统。从语言的种类来看,一个是动物语言,一个是人工语言,再者是自然语言。自然语言是人类最重要的工具,是人类进行沟通交流的各种表达符号。
那么自然语言处理的定义是什么?就是用计算机来处理人类的自然语言。
自然语言处理有三件重要的事:
1. 分析和理解;2. 生成和应用(互动过程);3. 动作(执行语言相对应的内容)。
为了更好地进行表示、推理和学习,自然语言处理涉及到了哪些方法?张民教授总结了如下内容:自然语言处理学科自身的算法和理论,规则方法,统计方法、机器学习方法及深度学习等多种方法。
机器能理解人类的自然语言吗?
从广义角度来说,真正的自然语言处理从 1950 年代的机器翻译研究开始。但语言存在高度歧义、高度结构化的特性。为何自然语言处理的难度如此大?张民教授认为包括如下因素:
功能:语言是对世界的认识和理解;
知识:涉及到语言学知识、外部知识、领域知识甚至是常识等多种综合知识。
特性:语言具备组合性、开放的、动态的、长期特性等多种特性。
语用性:张民教授着重强调了环境、上下文、信息、意图等各种因素对于理解语言的重要性和复杂性。
二、自然语言处理的方法
与人工智能一样,张民教授也将自然语言处理划分为外延和内涵两个部分。外延指的是自然语言处理的应用(下一部分会重点说明);内涵则涵盖三大内容,包括以自然语言分析(分析语言表达的结构和含义)、自然语言生成(从内部表示生成语言表达)和多语言处理等。
分词
分词的任务定义为:输入一个句子,输出一个词语序列的过程。如将「严守一把手机关了。」输出为「严守一/把/手机/关/了。」
目前的两种主流方法包括基于离散特征的 CRF 和 BILSTM-CRF。
挑战包括交叉歧义、新词识别、领域移植、多源异构数据融合及多粒度分词等。
命名实体
现在的主流方法包括:
1. 规则系统
2. 基于机器学习的学习系统
目前的挑战包括新领域旧实体类别识别、新实体类别识别等,解决办法包括利用构词知识、领域知识,使用强化学习、跨领域学习、半监督学习、众包、远程监督等机器学习方法。
句法分析
句法分析的任务定义为:输入一个句子的词语序列,输出为句子结构表示的过程。依存句法分析输出的是依存句法树,下面以依存句法分析为例。
目前采用的方法包括:
基于图的方法,即从图中搜索得到句法树,主要的任务在于确定每个依存弧的分值;
基于转移的方法:即通过一系列移进规约的动作得到句法树,主要任务在于基于当前状态,确定每个动作的分值。
现在的主流做法是在上述两者的基础上加入深度学习的方法。
语义分析
定义是将文本转换为可计算的知识表示。目前学术界语义表达方法包括:1)浅层语义分析;2)逻辑语义分析;3)抽象语义表示分析。
篇章分析
篇章的定义指的是一系列连续的语段或句子构成的语言整体单位,核心问题是篇章结构和篇章特征,其所基于的语言学基本理论包括中心理论、脉络理论、RST 等多种语言学基本理论。
基本结构分析
篇章结构指的是篇章内部关系的不同结构化表达形式,主要包括逻辑语言结构、指代结构、话题结构、功能结构、事件结构等范畴。
基本特征的研究
包括连接性、连贯性、意图、可接受性、信息性、情景性和跨篇章等七个基本特征。
自然语言生成
张民教授总结了在基于规则、基于知识的检索及基于深度学习等三种自然语言生成方法的优缺点对比及适用场景。
基于规则
它的一大优势在于具体领域的能做到精准回答;但相应地,在可移植性及可扩展性上则存在不足;适用的场景以个人助理为主,和任务驱动型的对话。
基于知识的检索
它的优点在于知识库易于扩充,答案没有语法错误;但对话连续性差,容易出现答非所问的情况;适用场景以问答系统、娱乐聊天为主。
基于深度学习
基于数据驱动的方法能够省去显示语言理解等过程,但需要大量语料支持;适用场景以虚拟影像、智能聊天机器人为主的有丰富领域语料的场景。
三、自然语言处理的应用
自然语言处理应用包括自然语言处理本身的直接应用和自然语言处理加行业的应用。直接应用包括,问答、对话、机器翻译、自动文摘、机器写作、阅读理解、信息抽取、情感分析等;同时,自然语言处理在各个行业中都有越来越广泛的应用,包括教育、医疗、司法、金融、旅游、国防、公共安全、科技、广告、文化、出版各行各业。
1. 情感和情绪分析
在业界研究和应用,情感一般包括正面、负面和中性,而情绪一般表现为喜、怒、哀、乐、惊、恐、思等。情绪和情感都是人对客观事物所持的态度体验,只是情绪更倾向于个体基本需求欲望上的态度体验,而情感则更倾向于社会需求欲望上的态度体验。情感和情绪分析包括问题驱动和模型驱动两个方面,在工业界和学术界都已经有着广泛的应用和研究。
2. 问答
智能问答主要有三方面的要求:一是理解人类语言的内涵;二是推敲知识获取的意图;三是挖掘精确贴切的知识。
相应地,问答系统需要解决三个问题:
1. 问题分类、分析和理解(一阶逻辑、二阶逻辑)
2. 答案的匹配、检索
3. 答案生成
问答的四个难点及解决方法
1)多源异构大数据背景下开放域问答的瓶颈。在效率与覆盖率的权衡下,数据大小与知识占比的关系是每个研究者需要考虑的问题;而结构化数据与非结构化数据的混杂,导致知识挖掘与存储存在相应的难点;此外,数据时效性的变化也给新旧知识的应用带来了挑战。
以往是用 IR 或 RC 的方法,但目前流行采用对检索所得的多个段落排序,也就是在 IR 和 RC 中加入了排序的操作,进而进行面向多段落的提取/生成答案。
2)深度语义理解的问答技术。以 Watson 为代表的系统采用的是抽取与置信度计算的方法;目前则是阅读理解抽取/生成式方法推动了技术发展。
3)知识库与知识图谱。以往的知识库存在可靠性、包容性低,存在通用性不高的问题,目前研究者们更多考虑用当下热门问题自动生成来实现知识图谱的自动更新和扩展。
4)多模态场景下的问答。问题的对象往往潜藏于多媒体,且答案的判断需要参考其它媒体的数据资源。目前出现了以语言处理 RNN 与图像处理的 CNN 的有机结合方法,实现跨媒体的特征共享、独立和抗依赖。
对话
根据应用场景的不同,可分为开放域及封闭域对话系统。高准确率的上下文篇章建模、对话状态转移模型和领域知识建模是目前对话亟待解决的问题。
知识图谱
包括知识建模、知识图谱构建、知识融合、知识推理计算以及知识赋能等主要任务。知识图谱构建是目前学术界和产业界研究热点,包括实体及其属性识别、事件抽取、实体事件关系抽取、概念实例化和规则学习等。
机器翻译
机器翻译目前已经取得较大进展,张民教授展望了未来机器翻译可以从如下领域做发展:
知识建模和翻译引擎,从词序列到语义到知识,利用知识图谱和各类知识(语言学知识、领域知识、常识知识等)进一步延伸机器翻译的边界;
研究新的翻译模型,从广度(篇章)和深度(深度理解)进一步推进机器翻译的理解能力。此外,还需要适应产业化的需求和国家战略需求。
四、AI 时代的自然语言处理
张民教授告诉雷锋网 (公众号:雷锋网) AI 科技评论,目前的自然语言处理发展处于历史上最好的时机。早在 90 年代,他们团队就尝试做过自然语言处理的商业化应用,但因为技术的局限性,最终并没能将商业模型成功落地。「早起的鸟儿有虫吃,但起得太早,天没有亮就饿死了。」张民教授的切身体会让他意识到,技术的进步,加上产业的需求和落地,让自然语言处理到了今天才迎来了新的春天。
同样地,张民教授在讲座中也提到了自然语言处理于 AI 时代的三个基本问题,一个是表示;一个是搜索、推理,还有一个是学习。
从底层来看,包括 NLP 词法、句法、语义到篇章的 NLP 基础研究和核心技术;
从应用研究来看,包括情感分析、信息抽取、对话系统、阅读理解、信息检索、问答系统、知识图谱、机器翻译等;
从上层来看,则是相应的平台、系统和应用。
以上这些也是张民教授团队研究工作的重点。
张民教授对 AI 科技评论表示,从数据、信息到知识和智能,未来的学科边界与知识智能结合会进一步融合,并在可解释性、小数据、知识赋能等亟待解决和探讨的问题上进一步延伸;与此同时,注重科学问题的凝练,定义学科研究规范和研究框架,重视产学研的结合与交融,这也是他寄予自然语言处理在 AI 时代这个「历史上发展的最好时期」的期待。
通俗理解生成对抗网络(GANs)
来源 | 我i智能,AI研习社
前言
GAN网络是近两年深度学习领域的新秀,火的不行,本文旨在浅显理解传统GAN,分享学习心得。现有GAN网络大多数代码实现使用Python、torch等语言,这里,后面用matlab搭建一个简单的GAN网络,便于理解GAN原理。
GAN的鼻祖之作是2014年NIPS一篇文章:
Generative Adversarial Net
(https://arxiv.org/abs/1406.2661),
可以细细品味。
分享一个目前各类GAN的一个论文整理集合
https://deephunt.in/the-gan-zoo-79597dc8c347
再分享一个目前各类GAN的一个代码整理集合
https://github.com/zhangqianhui/AdversarialNetsPapers
▌开始
我们知道GAN的思想是是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我两的总空间是一定的,这就是二人博弈,但是呢总利益是一定的。
引申到GAN里面就是可以看成,GAN中有两个这样的博弈者,一个人名字是生成模型(G),另一个人名字是判别模型(D)。他们各自有各自的功能。
相同点是:
这两个模型都可以看成是一个黑匣子,接受输入然后有一个输出,类似一个函数,一个输入输出映射。
不同点是:
生成模型功能:比作是一个样本生成器,输入一个噪声/样本,然后把它包装成一个逼真的样本,也就是输出。
判别模型:比作一个二分类器(如同0-1分类器),来判断输入的样本是真是假。(就是输出值大于0.5还是小于0.5)
直接上一张个人觉得解释的好的图说明:

在之前,我们首先明白在使用GAN的时候的2个问题
我们有什么?
比如上面的这个图,我们有的只是真实采集而来的人脸样本数据集,仅此而已,而且很关键的一点是我们连人脸数据集的类标签都没有,也就是我们不知道那个人脸对应的是谁。
我们要得到什么?
至于要得到什么,不同的任务得到的东西不一样,我们只说最原始的GAN目的,那就是我们想通过输入一个噪声,模拟得到一个人脸图像,这个图像可以非常逼真以至于以假乱真。
好了再来理解下GAN的两个模型要做什么。
首先判别模型,就是图中右半部分的网络,直观来看就是一个简单的神经网络结构,输入就是一副图像,输出就是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假),真假也不过是人们定义的概率而已。
其次是生成模型,生成模型要做什么呢,同样也可以看成是一个神经网络模型,输入是一组随机数Z,输出是一个图像,不再是一个数值而已。从图中可以看到,会存在两个数据集,一个是真实数据集,这好说,另一个是假的数据集,那这个数据集就是有生成网络造出来的数据集。好了根据这个图我们再来理解一下GAN的目标是要干什么:
判别网络的目的:就是能判别出来属于的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到什么程度呢,你判别网络没法判断我是真样本还是假样本。
有了这个理解我们再来看看为什么叫做对抗网络了。判别网络说,我很强,来一个样本我就知道它是来自真样本集还是假样本集。生成网络就不服了,说我也很强,我生成一个假样本,虽然我生成网络知道是假的,但是你判别网络不知道呀,我包装的非常逼真,以至于判别网络无法判断真假,那么用输出数值来解释就是,生成网络生成的假样本进去了判别网络以后,判别网络给出的结果是一个接近0.5的值,极限情况就是0.5,也就是说判别不出来了,这就是纳什平衡了。
由这个分析可以发现,生成网络与判别网络的目的正好是相反的,一个说我能判别的好,一个说我让你判别不好。所以叫做对抗,叫做博弈。那么最后的结果到底是谁赢呢?这就要归结到设计者,也就是我们希望谁赢了。作为设计者的我们,我们的目的是要得到以假乱真的样本,那么很自然的我们希望生成样本赢了,也就是希望生成样本很真,判别网络能力不足以区分真假样本位置。
▌再理解
知道了GAN大概的目的与设计思路,那么一个很自然的问题来了就是我们该如何用数学方法解决这么一个对抗问题。这就涉及到如何训练这样一个生成对抗网络模型了,还是先上一个图,用图来解释最直接:

需要注意的是生成模型与对抗模型可以说是完全独立的两个模型,好比就是完全独立的两个神经网络模型,他们之间没有什么联系。
好了那么训练这样的两个模型的大方法就是:单独交替迭代训练。
什么意思?因为是2个网络,不好一起训练,所以才去交替迭代训练,我们一一来看。
假设现在生成网络模型已经有了(当然可能不是最好的生成网络),那么给一堆随机数组,就会得到一堆假的样本集(因为不是最终的生成模型,那么现在生成网络可能就处于劣势,导致生成的样本就不咋地,可能很容易就被判别网络判别出来了说这货是假冒的),但是先不管这个,假设我们现在有了这样的假样本集,真样本集一直都有,现在我们人为的定义真假样本集的标签,因为我们希望真样本集的输出尽可能为1,假样本集为0,很明显这里我们就已经默认真样本集所有的类标签都为1,而假样本集的所有类标签都为0.
有人会说,在真样本集里面的人脸中,可能张三人脸和李四人脸不一样呀,对于这个问题我们需要理解的是,我们现在的任务是什么,我们是想分样本真假,而不是分真样本中那个是张三label、那个是李四label。况且我们也知道,原始真样本的label我们是不知道的。回过头来,我们现在有了真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0),这样单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送到神经网络模型中训练就完事了。假设训练完了,下面我们来看生成网络。
对于生成网络,想想我们的目的,是生成尽可能逼真的样本。那么原始的生成网络生成的样本你怎么知道它真不真呢?就是送到判别网络中,所以在训练生成网络的时候,我们需要联合判别网络一起才能达到训练的目的。什么意思?就是如果我们单单只用生成网络,那么想想我们怎么去训练?误差来源在哪里?细想一下没有,但是如果我们把刚才的判别网络串接在生成网络的后面,这样我们就知道真假了,也就有了误差了。所以对于生成网络的训练其实是对生成-判别网络串接的训练,就像图中显示的那样。好了那么现在来分析一下样本,原始的噪声数组Z我们有,也就是生成了假样本我们有,此时很关键的一点来了,我们要把这些假样本的标签都设置为1,也就是认为这些假样本在生成网络训练的时候是真样本。
那么为什么要这样呢?我们想想,是不是这样才能起到迷惑判别器的目的,也才能使得生成的假样本逐渐逼近为正样本。好了,重新顺一下思路,现在对于生成网络的训练,我们有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),是不是就可以训练了?有人会问,这样只有一类样本,训练啥呀?谁说一类样本就不能训练了?只要有误差就行。还有人说,你这样一训练,判别网络的网络参数不是也跟着变吗?没错,这很关键,所以在训练这个串接的网络的时候,一个很重要的操作就是不要判别网络的参数发生变化,也就是不让它参数发生更新,只是把误差一直传,传到生成网络那块后更新生成网络的参数。这样就完成了生成网络的训练了。
在完成生成网络训练好,那么我们是不是可以根据目前新的生成网络再对先前的那些噪声Z生成新的假样本了,没错,并且训练后的假样本应该是更真了才对。然后又有了新的真假样本集(其实是新的假样本集),这样又可以重复上述过程了。我们把这个过程称作为单独交替训练。我们可以实现定义一个迭代次数,交替迭代到一定次数后停止即可。这个时候我们再去看一看噪声Z生成的假样本会发现,原来它已经很真了。
看完了这个过程是不是感觉GAN的设计真的很巧妙,个人觉得最值得称赞的地方可能在于这种假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。
▌进一步
文字的描述相信已经让大多数的人知道了这个过程,下面我们来看看原文中几个重要的数学公式描述,首先我们直接上原始论文中的目标公式吧:
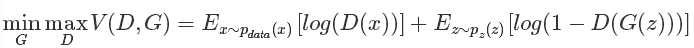
上述这个公式说白了就是一个最大最小优化问题,其实对应的也就是上述的两个优化过程。有人说如果不看别的,能达看到这个公式就拍案叫绝的地步,那就是机器学习的顶级专家,哈哈,真是前路漫漫。同时也说明这个简单的公式意义重大。
这个公式既然是最大最小的优化,那就不是一步完成的,其实对比我们的分析过程也是这样的,这里现优化D,然后在取优化G,本质上是两个优化问题,把拆解就如同下面两个公式:
优化D:
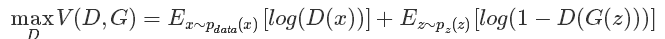
优化G:
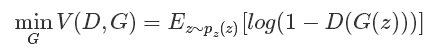
可以看到,优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好嘛。对于假样本,需要优化是的其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是呢第一项是越大,第二项是越小,这不矛盾了,所以呢把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。 那么同样在优化G的时候,这个时候没有真样本什么事,所以把第一项直接却掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成了最开始的那个最大最小目标函数了。
所以回过头来我们来看这个最大最小目标函数,里面包含了判别模型的优化,包含了生成模型的以假乱真的优化,完美的阐释了这样一个优美的理论。
▌再进一步
有人说GAN强大之处在于可以自动的学习原始真实样本集的数据分布,不管这个分布多么的复杂,只要训练的足够好就可以学出来。针对这一点,感觉有必要好好理解一下为什么别人会这么说。
我们知道,传统的机器学习方法,我们一般都会定义一个什么模型让数据去学习。比如说假设我们知道原始数据属于高斯分布呀,只是不知道高斯分布的参数,这个时候我们定义高斯分布,然后利用数据去学习高斯分布的参数得到我们最终的模型。再比如说我们定义一个分类器,比如SVM,然后强行让数据进行东变西变,进行各种高维映射,最后可以变成一个简单的分布,SVM可以很轻易的进行二分类分开,其实SVM已经放松了这种映射关系了,但是也是给了一个模型,这个模型就是核映射(什么径向基函数等等),说白了其实也好像是你事先知道让数据该怎么映射一样,只是核映射的参数可以学习罢了。
所有的这些方法都在直接或者间接的告诉数据你该怎么映射一样,只是不同的映射方法能力不一样。那么我们再来看看GAN,生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律了,有了这个规律,想生成人脸还不容易。然而这个规律我们开始知道吗?显然不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。
再拿原论文中的一张图来解释:
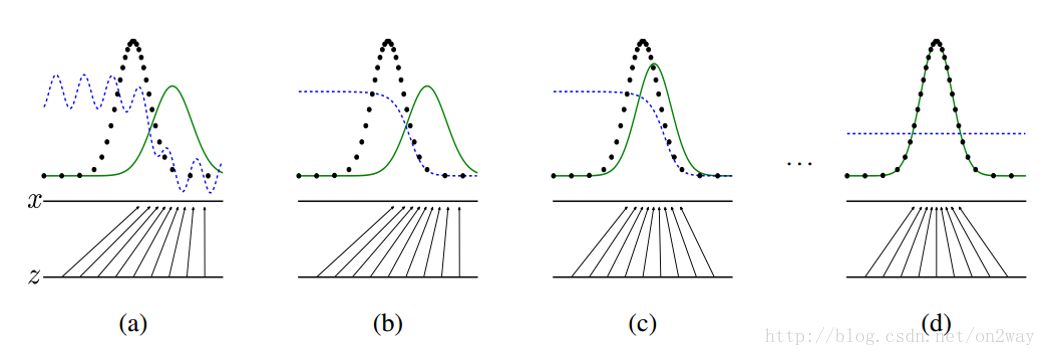
这张图表明的是GAN的生成网络如何一步步从均匀分布学习到正太分布的。原始数据x服从正太分布,这个过程你也没告诉生成网络说你得用正太分布来学习,但是生成网络学习到了。假设你改一下x的分布,不管什么分布,生成网络可能也能学到。这就是GAN可以自动学习真实数据的分布的强大之处。
还有人说GAN强大之处在于可以自动的定义潜在损失函数。 什么意思呢,这应该说的是判别网络可以自动学习到一个好的判别方法,其实就是等效的理解为可以学习到好的损失函数,来比较好或者不好的判别出来结果。虽然大的loss函数还是我们人为定义的,基本上对于多数GAN也都这么定义就可以了,但是判别网络潜在学习到的损失函数隐藏在网络之中,不同的问题这个函数就不一样,所以说可以自动学习这个潜在的损失函数。
▌开始做小实验
本节主要实验一下如何通过随机数组生成mnist图像。mnist手写体数据库应该都熟悉的。这里简单的使用matlab来实现,方便看到整个实现过程。这里用到了一个工具箱 DeepLearnToolbox,关于该工具箱的一些其他使用说明:
DeepLearnToolbox
https://github.com/rasmusbergpalm/DeepLearnToolbox
其他使用说明
https://blog.csdn.net/dark_scope/article/details/9447967
网络结构很简单,就定义成下面这样子:
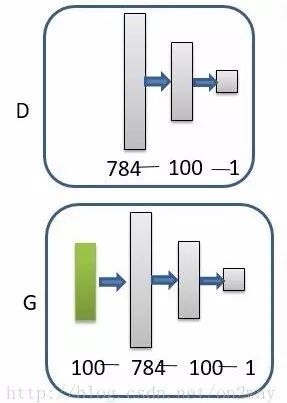
将上述工具箱添加到路径,然后运行下面代码:
clc
clear
%% 构造真实训练样本 60000个样本 1*784维(28*28展开)
load mnist_uint8;
train_x = double(train_x(1:60000,:)) / 255;
% 真实样本认为为标签 [1 0]; 生成样本为[0 1];
train_y = double(ones(size(train_x,1),1));
% normalize
train_x = mapminmax(train_x, 0, 1);
rand('state',0)
%% 构造模拟训练样本 60000个样本 1*100维
test_x = normrnd(0,1,[60000,100]); % 0-255的整数
test_x = mapminmax(test_x, 0, 1);
test_y = double(zeros(size(test_x,1),1));
test_y_rel = double(ones(size(test_x,1),1));
%%
nn_G_t = nnsetup([100 784]);
nn_G_t.activation_function = 'sigm';
nn_G_t.output = 'sigm';
nn_D = nnsetup([784 100 1]);
nn_D.weightPenaltyL2 = 1e-4; % L2 weight decay
nn_D.dropoutFraction = 0.5; % Dropout fraction
nn_D.learningRate = 0.01; % Sigm require a lower learning rate
nn_D.activation_function = 'sigm';
nn_D.output = 'sigm';
% nn_D.weightPenaltyL2 = 1e-4; % L2 weight decay
nn_G = nnsetup([100 784 100 1]);
nn_G.weightPenaltyL2 = 1e-4; % L2 weight decay
nn_G.dropoutFraction = 0.5; % Dropout fraction
nn_G.learningRate = 0.01; % Sigm require a lower learning rate
nn_G.activation_function = 'sigm';
nn_G.output = 'sigm';
% nn_G.weightPenaltyL2 = 1e-4; % L2 weight decay
opts.numepochs = 1; % Number of full sweeps through data
opts.batchsize = 100; % Take a mean gradient step over this many samples
%%
num = 1000;
tic
for each = 1:1500
%----------计算G的输出:假样本-------------------
for i = 1:length(nn_G_t.W) %共享网络参数
nn_G_t.W{i} = nn_G.W{i};
end
G_output = nn_G_out(nn_G_t, test_x);
%-----------训练D------------------------------
index = randperm(60000);
train_data_D = [train_x(index(1:num),:);G_output(index(1:num),:)];
train_y_D = [train_y(index(1:num),:);test_y(index(1:num),:)];
nn_D = nntrain(nn_D, train_data_D, train_y_D, opts);%训练D
%-----------训练G-------------------------------
for i = 1:length(nn_D.W) %共享训练的D的网络参数
nn_G.W{length(nn_G.W)-i+1} = nn_D.W{length(nn_D.W)-i+1};
end
%训练G:此时假样本标签为1,认为是真样本
nn_G = nntrain(nn_G, test_x(index(1:num),:), test_y_rel(index(1:num),:), opts);
end
toc
for i = 1:length(nn_G_t.W)
nn_G_t.W{i} = nn_G.W{i};
end
fin_output = nn_G_out(nn_G_t, test_x);
函数nn_G_out为:
function output = nn_G_out(nn, x)
nn.testing = 1;
nn = nnff(nn, x, zeros(size(x,1), nn.size(end)));
nn.testing = 0;
output = nn.a{end};
end
看一下这个及其简单的函数,其实最值得注意的就是中间那个交替训练的过程,这里我分了三步列出来:
重新计算假样本(假样本每次是需要更新的,产生越来越像的样本)
训练D网络,一个二分类的神经网络;
训练G网络,一个串联起来的长网络,也是一个二分类的神经网络(不过只有假样本来训练),同时D部分参数在下一次的时候不能变了。
就这样调一调参数,最终输出在fin_output里面,多运行几次显示不同运行次数下的结果:
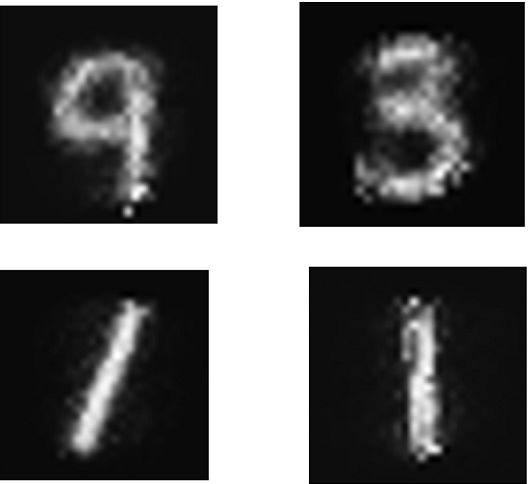
可以看到的是结果还是有点像模像样的。
▌实验总结
运行上述简单的网络我发现几个问题:
网络存在着不收敛问题;网络不稳定;网络难训练;读过原论文其实作者也提到过这些问题,包括GAN刚出来的时候,很多人也在致力于解决这些问题,当你实验自己碰到的时候,还是很有意思的。那么这些问题怎么体现的呢,举个例子,可能某一次你会发现训练的误差很小,在下一代训练时,马上又出现极限性的上升的很厉害,过几代又发现训练误差很小,震荡太严重。
其次网络需要调才能出像样的结果。交替迭代次数的不同结果也不一样。比如每一代训练中,D网络训练2回,G网络训练一回,结果就不一样。
这是简单的无条件GAN,所以每一代训练完后,只能出现一个结果,那就是0-9中的某一个数。要想在一代训练中出现好几种结果,就需要使用到条件GAN了。
▌再提升一下
图像生成
这里尝试给「图像生成」一个大致定义:图像生成的目的是,学习一个生成模型,能够将来自于输入分布的一幅图像或变量转变成为一幅输出图像。这里,我们不仅要求「输入」满足一个输入分布,同样,我们还要求「输出」满足一个预期的期望分布。通过定义不同的输入分布和期望分布,就对应着不同的图像生成问题。

一开始,最标准的 GAN 的假设是,输入要服从随机噪声分布,期望分布是所有的真实图像。这个问题一开始定义得太大,所以虽然 GAN 在2014年就出现了,在2014年到2016年这段时间其实发展得并不快。
后来大家就去思考,输入的分布也可以不是随机分布,于是大家开始根据各种实际问题的需要来定义自己需要的输入分布和期望分布。比如,输入分布可以是来自于所有斑马的一幅图像,输出分布是所有正常马的图像,这样系统要学习的其实是这两种图像之间的映射(mapping)。

同样,如果我们输入的是一个低分辨率图像,输出的是一个高分辨率图像,那么希望系统学习到的是低分辨率和高分辨率之间的映射。去区块(deblocking),输入的是 JPEG 压缩图像,输出的是真实高清图像,我们也是希望学到两者之间的映射。人脸领域也是一样,比如我们做的超分辨和性别转换。输入是男性图像,输出是女性图像,学习二者之间的映射。

另外一个有意思的是图像文本描述的自动生成(Image captioning),输入的是图像,输出的是句子。大家以前就认为,这是一个一对一的映射,其实不是。它实际上是一对多的映射。不同的人来描述一幅图,就会产生不同的语句。所以如果用 GAN 来做这件事情,应该是很有趣的,今年有几篇投 ICCV 的文章做的就是这方面的工作。

关于GAN的三个问题
第一,度量复杂分布之间差异性。我们希望输出分布达到期望分布,那么我们需要找两个分布之间差异的度量方式,这是我认为在 GAN 里面需要研究的第一个关键性问题。
第二,如何设计生成器。如果我们想要学习映射,就需要一个生成器,那么就要对它的训练、可学习性进行设计。这是 GAN 里面另一个可以研究的角度。
第三,连接输入和输出。如下图右边性别转换的例子,输入是一张男性图像,输出是一张女性图像。显然我们需要的并不是从输入到任意一幅女性人脸图像的映射,二是要求输出的女性图像要跟输入的男性图像尽可能像,这个转换才是有意义的。所以,这就是 GAN 里面另外一个重要的研究方向,就是如何将输入和输出连接起来。

下面针对这三个问题,进行详细的讲解。
如何度量两个分布之间的差异性
GAN 使用了一个分类器来度量输出分布和期望分布的差异性。实际上,Torralba和Efros在 2011 年的时候也考虑过用一个分类器来分析两个分布之间差异,这也是当时做 domain adaption 的学者喜欢引用的一篇论文。他们设计了一个实验,给你三张图像,让你猜是来自 12 个数据集(包括 ImageNet、COCO和PASCAL VOC等)中的那一个。如果是随机猜的话,显然猜中的概率是 1/12。但是人猜中的准确度往往能达到 30% 左右,说明不同数据集刻画的分布是不一致的。这里人其实可视为一个分类器,通过判断样本来自于那个数据集来分析两个分布之间差异。
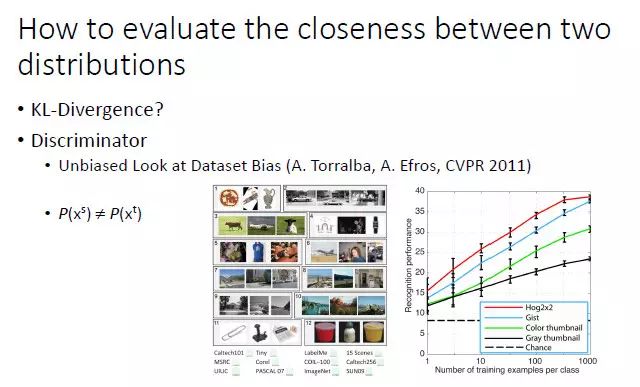
虽然 NIPS 2014 年的这篇 GAN 论文没有引用 Torralba 的工作,其实它也是采用了一个判别器来度量两个分布的差异化程度。基本的过程是,固定生成器,得到一个最好的判别器,再固定判别器,学到一个最好的生成器。但是其中有一个最令人担心的问题,那就是如果我们学到的是一个很复杂的分布,就会出现模式崩溃(Mode Collapse)的问题,即无法学习复杂分布的全局,只能学习其中的一部分。

对此,最早的解决方案,是调整生成器(G)和判别器(D)的优化次序,但这也不是一个终极方案。从去年开始大家开始关注要去找到一个终极解决方案。
那之前,大家怎么去解决这个问题呢?使用的是原来机器学习里常用的方法:最大化均值差异(Maximum Mean Discrepancy,MMD)。
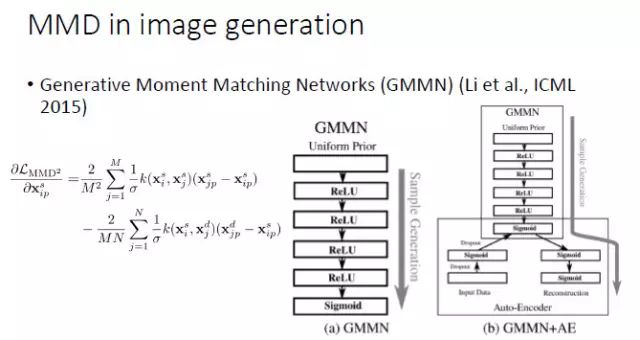
如果两个分布相同的话,那么两个分布的数学期望显然也应该相同;然而,如果两个分布的数学期望相同,并不能保证两个分布相同。因而,我们需要更好地建立「分布相同」和「期望相同」之间的连接关系。幸运的是,我们可以对来自于两个分布的变量施加同样的非线性变换。如果对于所有的非线性变换下两个分布的数学期望均相同(即:两个分布的期望的最大差别为0),在统计学意义上就可以保证两个分布是相同的。不幸的是,这种方法需要我们遍历所有的非线性变换,从实践的角度似乎任由一定难度。一开始,在机器学习领域,大家倾向于用线性 kernel或Gaussian RBF kernel 来进行非线性变换,后来开始采用 multi-kernel。从去年开始,大家开始用 CNN 来近似所有的非线性变换,在 MMD 框架下进行图像生成。首先,固定生成器并最大化 MMD,然后固定判别器里 MMD 的 f,然后通过最小化 MMD 来更新生成器。
最常用的一种方法,就是拿 MMD 来代替判别器,去学习一个 CNN,这是 ICML 2015 的一篇文章中尝试的方法,我们自己也在这个基础上做了一些工作。
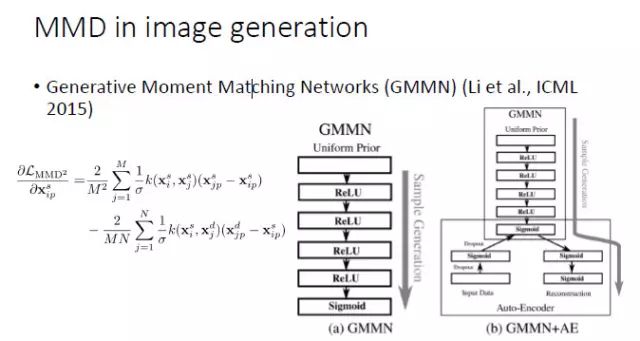
但实际上,如果直接拿 MMD 去替换生成器,虽然有一定效果,但不是特别成功。所以,从 NIPS 2016 开始,就出现了一个 Improved GAN,这个工作虽然没有引用 MMD 的论文,但实际上在更新判别器的同时也最小化了 MMD。等到了 Wasserstein GAN 的时候,它就明确解释了与 MMD 之间的联系,虽然论文里写的是一个「减」的关系,但我们看它的代码,它也是要加上一个范数的,因为只是让两个分布的期望最大化或最小化都不能保证分布的差异化程度最小。
然后,最近 ICLR 2017 的一篇论文也明确指出要用 MMD 来作为 GAN 网络的停止条件和学习效果的评价手段。

如何设计一个生成器
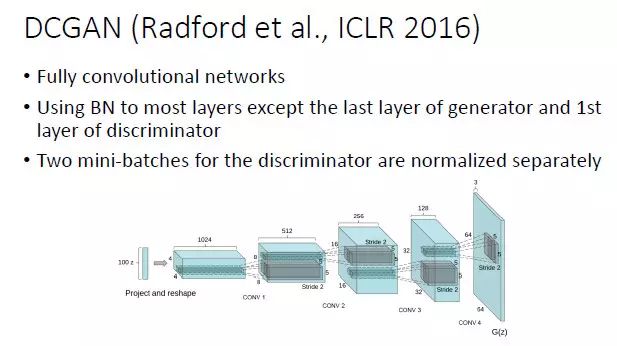
这个部分相对来说就比较容易一些。早期的时候,GAN 的一个最大的进步就是 DCGAN,用于图像生成时,比较合适的选择就是用全卷积网络加上 batch normalizaiton。
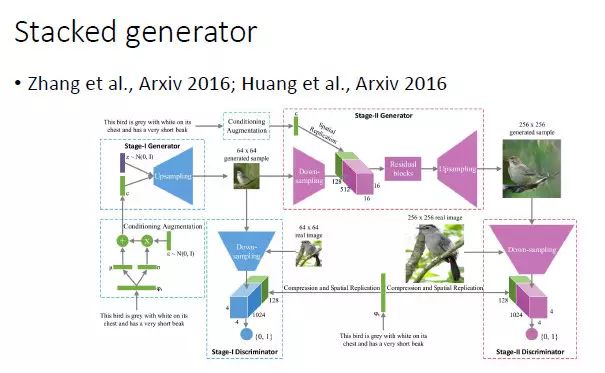
对于复杂的图像生成,可以使用分阶段的方式。比如,第一步可以生成小图,然后由小图生成大图。沿着这个方向,香港中文大学王晓刚老师和康奈尔大学 John Hopcroft 都做了一些工作。
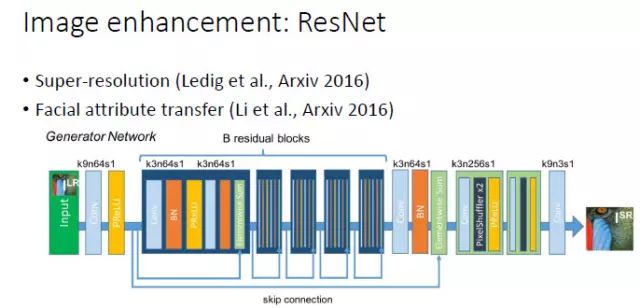
对于图像增强(image enhancement)相关的一些任务,包括超分辨率和人脸属性转换(Face Attribute Transfer),目前在有监督时表现最好网络是 ResNet ,所以我们在这些任务中实用GAN时一般也会采用 ResNet 结构。
同样,对于图像转换(image translation),基本上用的是 U-Net 结构。我们在做基于引导图像的人脸填充(guided face completion)时也采用了 U-Net 结构。
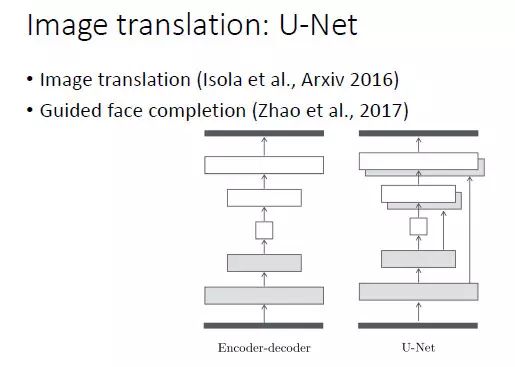
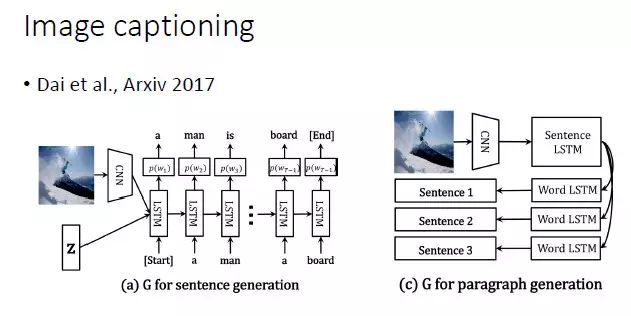
对于图像文本描述的自动生成,显然应该采用 CNN+RNN 这样的网络结构。总而言之,一个比较好的建议就是根据任务的特点和前任的经验来设计生成器网络。
如何连接输入和输出
如何通过连接输入和输出的方式来改善 GAN 的可学习性,这个问题是从 NIPS 2016 开始得到了较多的关注,同时这也是我自己非常感兴趣的一个方向。比较早的一个工作就是 InfoGAN,其特点就是输入包括两个部分:C(隐变量)和 Z(噪声)。InfoGAN 生成图像之后,不仅要求生成图像和真实图像难以区分,还要求能够从生成图像中预测出 C,这样就为输入和输出建立起了一个联系。

另外针对一些任务,比如超分辨,可以用 Perceptual loss 的方式来建立输入和输出的联系。
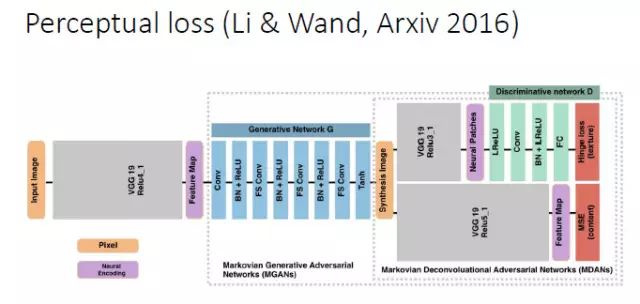
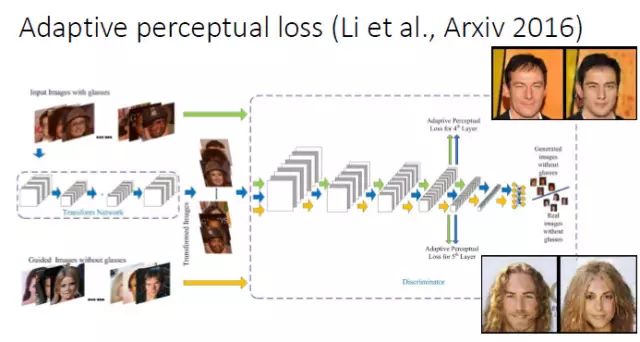
我们在做人脸属性转换时发现,现有的 Perceptual loss 往往是定义在一个现有的网络基础上的,我们就想能不能把 Perceptual loss 网络和判别器结合起来,所以就提出了一个 Adaptive perceptual loss。结果表明Adaptive perceptual loss能够具有更好的自适应性,能够更好地建立输入和输出的联系和显著改善生成图片的视觉效果。
当输入和输出都是已知时(比如图像超分辨和图像转换),要用什么方式来连接输入和输出呢?以前是用 Perceptual loss 来连,现在更好的方式是用 Conditional GAN。假设有一个 Positive Pair(输入和groundtruth图像)和 Negative Pair(输入和生成图像),那么判别器就不是在两幅图像之间做判别,而是在两个「Pair」之间做判别。这样的话,输入就很自然地引入到了判别器中。

在此基础上,我们还考虑了当有一些额外的 Guidance 时,如何来更好地建立输入和输出的联系。
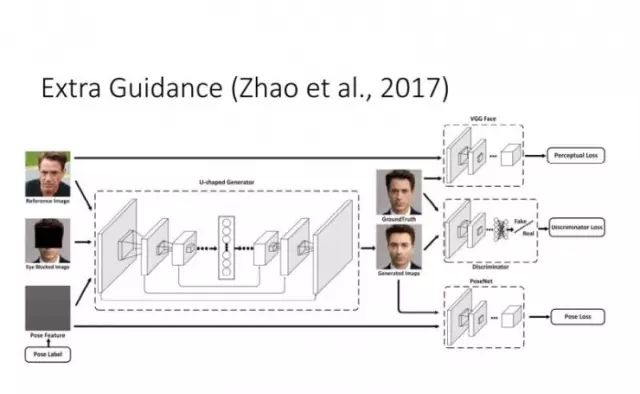
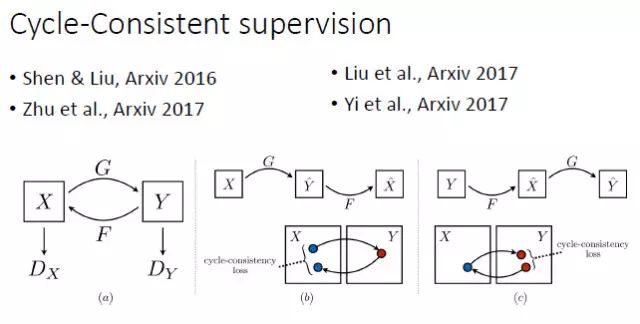
上面提到,在有监督的情况下 Conditional GAN 是一个比较好的选择。但如果在 unpair 的情况下做图像转换,要如何建立输入和输出的联系?谭平老师他们组和Efros组今年就做了这方面的工作,其实去年投 CVPR2017 的一篇论文也做了类似的工作。我们知道,由于是unpair的,原则上训练阶段输入和输出不能直接建立联系。这时他们采用的是一种 Cycle-Consistent 的方式。从 X 可以预测和生成 Y,再从 Y 重新生成 X',那么由 Y 生成的 X' 就能跟输入的 X 建立联系。这样的话,我们实际上相当于隐式地建立了从 X 到 Y 的联系。
总结
现在的GAN已经到了五花八门的时候了,各种GAN应用也很多,理解底层原理再慢慢往上层扩展。GAN还是一个很厉害的东西,它使得现有问题从有监督学习慢慢过渡到无监督学习,而无监督学习才是自然界中普遍存在的,因为很多时候没有办法拿到监督信息的。要不Yann Lecun赞叹GAN是机器学习近十年来最有意思的想法。点击文末阅读原文
原文地址:
https://blog.csdn.net/on2way/article/details/72773771
称霸Kaggle的十大深度学习技巧
作者 Samuel Lynn-Evans
王小新 编译自 FloydHub Blog
量子位 出品 | 公众号 QbitAI
在各种Kaggle竞赛的排行榜上,都有不少刚刚进入深度学习领域的程序员,其中大部分有一个共同点:
都上过Fast.ai的课程。
这些免费、重实战的课程非常鼓励学生去参加Kaggle竞赛,检验自己的能力。当然,也向学生们传授了不少称霸Kaggle的深度学习技巧。
是什么秘诀让新手们在短期内快速掌握并能构建最先进的DL算法?一位名叫塞缪尔(Samuel Lynn-Evans)的法国学员总结了十条经验。

他这篇文章发表在FloydHub官方博客上,因为除了来自Fast.ai的技巧之外,他还用了FloydHub的免设置深度学习GPU云平台。
接下来,我们看看他从fast.ai学来的十大技艺:
1. 使用Fast.ai库
这一条最为简单直接。
from fast.ai import *
Fast.ai库是一个新手友好型的深度学习工具箱,而且是目前复现最新算法的首要之选。
每当Fast.ai团队及AI研究者发现一篇有趣论文时,会在各种数据集上进行测试,并确定合适的调优方法。他们会把效果较好的模型实现加入到这个函数库中,用户可以快速载入这些模型。
于是,Fast.ai库成了一个功能强大的工具箱,能够快速载入一些当前最新的算法实现,如带重启的随机梯度下降算法、差分学习率和测试时增强等等,这里不逐一提及了。
下面会分别介绍这些技术,并展示如何使用Fast.ai库来快速使用它们。
这个函数库是基于PyTorch构建,构建模型时可以流畅地使用。
Fast.ai库地址:
https://github.com/fastai/fastai
2. 使用多个而不是单一学习率
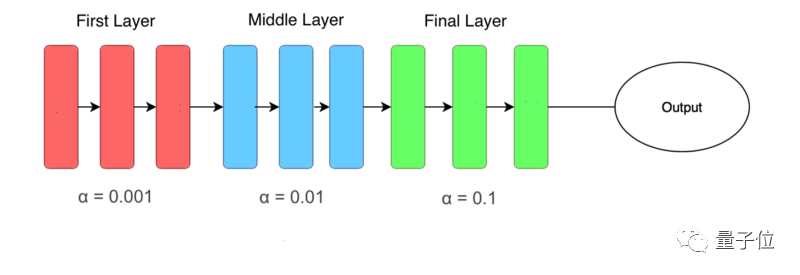
差分学习率(Differential Learning rates)意味着在训练时变换网络层比提高网络深度更重要。
基于已有模型来训练深度学习网络,这是一种被验证过很可靠的方法,可以在计算机视觉任务中得到更好的效果。
大部分已有网络(如Resnet、VGG和Inception等)都是在ImageNet数据集训练的,因此我们要根据所用数据集与ImageNet图像的相似性,来适当改变网络权重。
在修改这些权重时,我们通常要对模型的最后几层进行修改,因为这些层被用于检测基本特征(如边缘和轮廓),不同数据集有着不同基本特征。
首先,要使用Fast.ai库来获得预训练的模型,代码如下:
from fastai.conv_learner import *
# import library for creating learning object for convolutional #networks
model = VVG16()
# assign model to resnet, vgg, or even your own custom model
PATH = './folder_containing_images'
data = ImageClassifierData.from_paths(PATH)
# create fast ai data object, in this method we use from_paths where
# inside PATH each image class is separated into different folders
learn = ConvLearner.pretrained(model, data, precompute=True)
# create a learn object to quickly utilise state of the art
# techniques from the fast ai library创建学习对象之后(learn object),通过快速冻结前面网络层并微调后面网络层来解决问题:
learn.freeze()
# freeze layers up to the last one, so weights will not be updated.
learning_rate = 0.1
learn.fit(learning_rate, epochs=3)
# train only the last layer for a few epochs当后面网络层产生了良好效果,我们会应用差分学习率来改变前面网络层。在实际中,一般将学习率的缩小倍数设置为10倍:
learn.unfreeze()
# set requires_grads to be True for all layers, so they can be updated
learning_rate = [0.001, 0.01, 0.1]
# learning rate is set so that deepest third of layers have a rate of 0.001, # middle layers have a rate of 0.01, and final layers 0.1.
learn.fit(learning_rate, epochs=3)
# train model for three epoch with using differential learning rates3. 如何找到合适的学习率
学习率是神经网络训练中最重要的超参数,没有之一,但之前在实际应用中很难为神经网络选择最佳的学习率。
Leslie Smith的一篇周期性学习率论文发现了答案,这是一个相对不知名的发现,直到它被Fast.ai课程推广后才逐渐被广泛使用。
这篇论文是:
Cyclical Learning Rates for Training Neural Networks
https://arxiv.org/abs/1506.01186
在这种方法中,我们尝试使用较低学习率来训练神经网络,但是在每个批次中以指数形式增加,相应代码如下:
learn.lr_find()
# run on learn object where learning rate is increased exponentially
learn.sched.plot_lr()
# plot graph of learning rate against iterations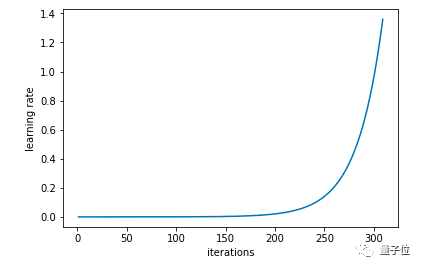
△ 每次迭代后学习率以指数形式增长
同时,记录每个学习率对应的Loss值,然后画出学习率和Loss值的关系图:
learn.sched.plot()
# plots the loss against the learning rate
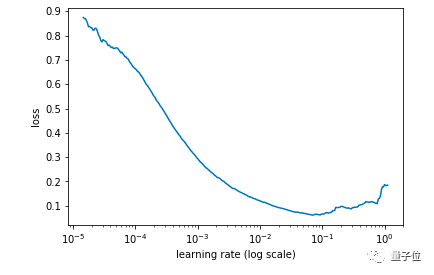
△ 找出Loss值在下降但仍未稳定的点
通过找出学习率最高且Loss值仍在下降的值来确定最佳学习率。在上述情况中,该值将为0.01。
4. 余弦退火
在采用批次随机梯度下降算法时,神经网络应该越来越接近Loss值的全局最小值。当它逐渐接近这个最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近这一点。
余弦退火(Cosine annealing)利用余弦函数来降低学习率,进而解决这个问题,如下图所示:
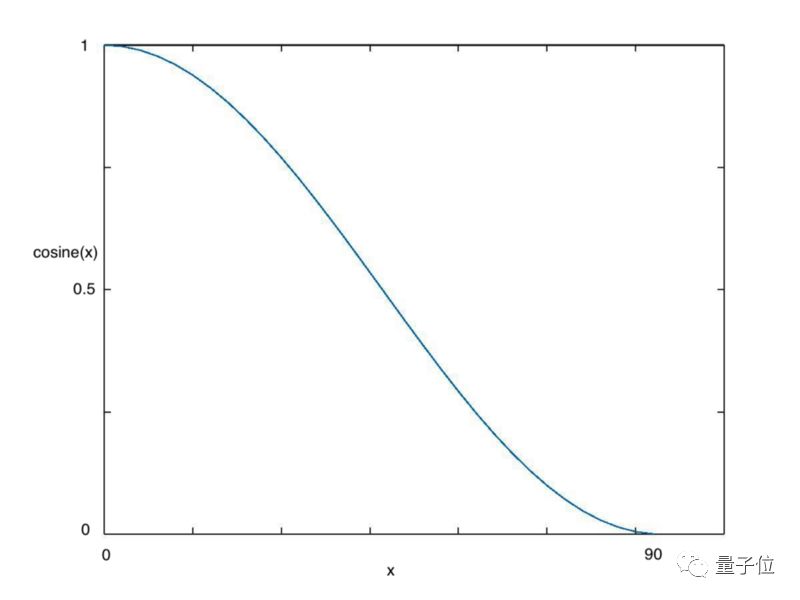
△ 余弦值随着x增大而减小
从上图可以看出,随着x的增加,余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
learn.fit(0.1, 1)
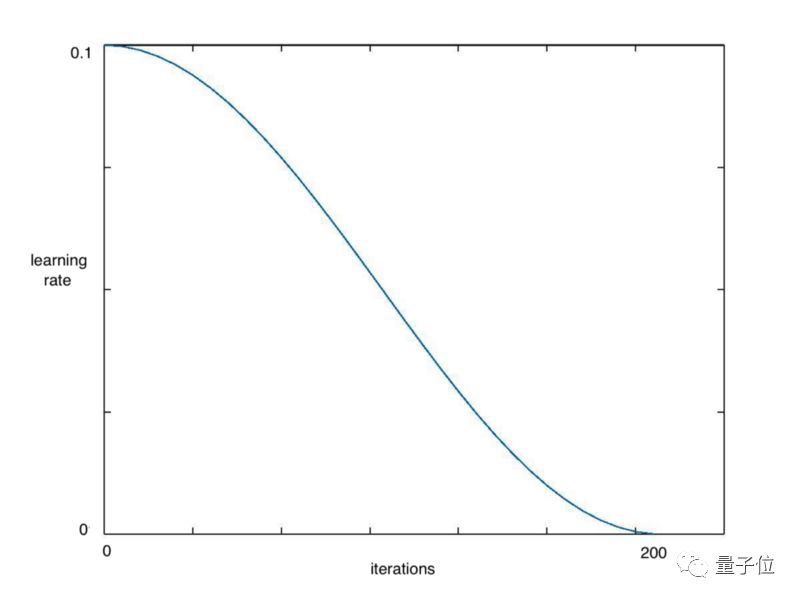
# Calling learn fit automatically takes advantage of cosine annealing我们可以用Fast.ai库中的learn.fit()函数,来快速实现这个算法,在整个周期中不断降低学习率,如下图所示:
△ 在一个需要200次迭代的周期中学习率不断降低
同时,在这种方法基础上,我们可以进一步引入重启机制。
5. 带重启的SGD算法
在训练时,梯度下降算法可能陷入局部最小值,而不是全局最小值。
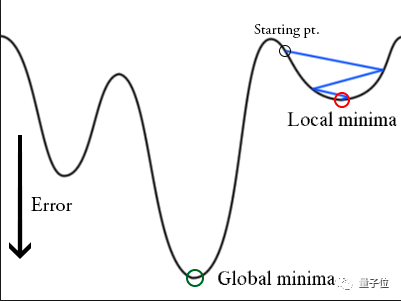
△ 陷入局部最小值的梯度下降算法
梯度下降算法可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。这种方式称为带重启的随机梯度下降方法(stochastic gradient descent with restarts, SGDR),这个方法在Loshchilov和Hutter的ICLR论文中展示出了很好的效果。
这篇论文是:
SGDR: Stochastic Gradient Descent with Warm Restarts
https://arxiv.org/abs/1608.03983
用Fast.ai库可以快速导入SGDR算法。当调用learn.fit(learning_rate, epochs)函数时,学习率在每个周期开始时重置为参数输入时的初始值,然后像上面余弦退火部分描述的那样,逐渐减小。
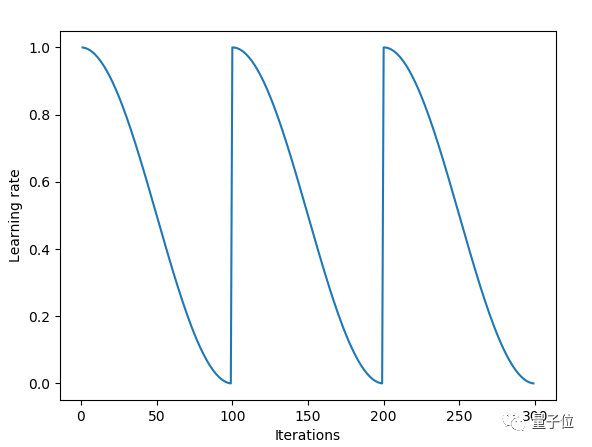
每当学习率下降到最小点,在上图中为每100次迭代,我们称为一个循环。
cycle_len = 1
# decide how many epochs it takes for the learning rate to fall to
# its minimum point. In this case, 1 epoch
cycle_mult=2
# at the end of each cycle, multiply the cycle_len value by 2
learn.fit(0.1, 3, cycle_len=2, cycle_mult=2)
# in this case there will be three restarts. The first time with
# cycle_len of 1, so it will take 1 epoch to complete the cycle.
# cycle_mult=2 so the next cycle with have a length of two epochs,
# and the next four.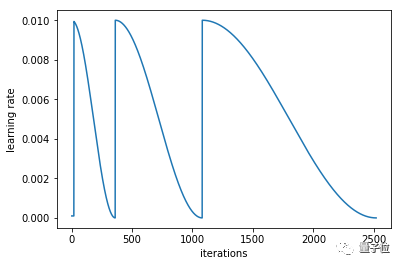
△ 每个循环所包含的周期都是上一个循环的2倍
利用这些参数,和使用差分学习率,这些技巧是Fast.ai用户在图像分类问题上取得良好效果的关键。
Fast.ai论坛有个帖子专门讨论Cycle_mult和cycle_len函数,地址在这里:
http://forums.fast.ai/t/understanding-cycle-len-and-cycle-mult/9413/8
更多关于学习率的详细内容可参考这个Fast.ai课程:
http://course.fast.ai/lessons/lesson2.html
6. 人格化你的激活函数
Softmax只喜欢选择一样东西;
Sigmoid想知道你在[-1, 1]区间上的位置,并不关心你超出这些值后的增加量;
Relu是一名俱乐部保镖,要将负数拒之门外。
……
以这种思路对待激活函数,看起来很愚蠢,但是安排一个角色后能确保把他们用到正确任务中。
正如fast.ai创始人Jeremy Howard指出,不少学术论文中也把Softmax函数用在多分类问题中。在DL学习过程中,我也看到它在论文和博客中多次使用不当。
7. 迁移学习在NLP问题中非常有效
正如预训练好的模型在计算机视觉任务中很有效一样,已有研究表明,自然语言处理(NLP)模型也可以从这种方法中受益。
在Fast.ai第4课中,Jeremy Howard用迁移学习方法建立了一个模型,来判断IMDB上的电影评论是积极的还是消极的。
这种方法的效果立竿见影,他所达到的准确率超过了Salesforce论文中展示的所有先前模型:
https://einstein.ai/research/learned-in-translation-contextualized-word-vectors。
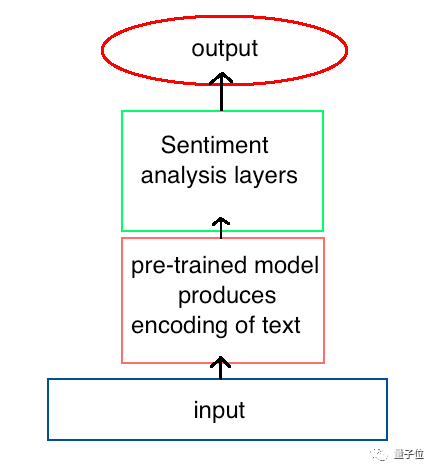
△ 预先存在的架构提供了最先进的NLP性能
这个模型的关键在于先训练模型来获得对语言的一些理解,然后再使用这种预训练好的模型作为新模型的一部分来分析情绪。
为了创建第一个模型,我们训练了一个循环神经网络(RNN)来预测文本序列中的下个单词,这称为语言建模。当训练后网络的准确率达到一定值,它对每个单词的编码模式就会传递给用于情感分析的新模型。
在上面的例子中,我们看到这个语言模型与另一个模型集成后用于情感分析,但是这种方法可以应用到其他任何NLP任务中,包括翻译和数据提取。
而且,计算机视觉中的一些技巧,也同样适用于此,如上面提到的冻结网络层和使用差分学习率,在这里也能取得更好的效果。
这种方法在NLP任务上的使用涉及很多细节,这里就不贴出代码了,可访问相应课程和代码。
课程:
http://course.fast.ai/lessons/lesson4.html
代码:
https://github.com/fastai/fastai/blob/master/courses/dl1/lesson4-imdb.ipynb
8. 深度学习在处理结构化数据上的优势
Fast.ai课程中展示了深度学习在处理结构化数据上的突出表现,且无需借助特征工程以及领域内的特定知识。
这个库充分利用了PyTorch中embedding函数,允许将分类变量快速转换为嵌入矩阵。
他们展示出的技术比较简单直接,只需将分类变量转换为数字,然后为每个值分配嵌入向量:
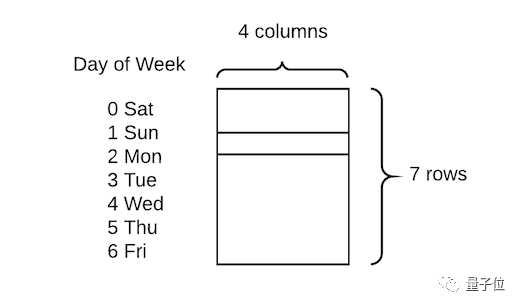
△ 一周中的每一天都嵌入了四个值
在这类任务上,传统做法是创建虚拟变量,即进行一次热编码。与之相比,这种方式的优点是用四个数值代替一个数值来描述每一天,因此可获得更高的数据维度和更丰富的关系。
这种方法在Rossman Kaggle比赛中获得第三名,惜败于两位利用专业知识来创建许多额外特征的领域专家。
相关课程:
http://course.fast.ai/lessons/lesson4.html
代码:
https://github.com/fastai/fastai/blob/master/courses/dl1/lesson3-rossman.ipynb
这种用深度学习来减少对特征工程依赖的思路,也被Pinterest证实过。他也提到过,他们正努力通过深度学习模型,期望用更少的工作量来获得更好的效果。
9. 更多内置函数:Dropout层、尺寸设置、TTA
4月30日,Fast.ai团队在斯坦福大学举办的DAWNBench竞赛中,赢得了基于Imagenet和CIFAR10的分类任务。在Jeremy的夺冠总结中,他将这次成功归功于fast.ai库中的一些额外函数。
其中之一是Dropout层,由Geoffrey Hinton两年前在一篇开创性的论文中提出。它最初很受欢迎,但在最近的计算机视觉论文中似乎有所忽略。这篇论文是:
Dropout: A Simple Way to Prevent Neural Networks from Overfitting:
https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
然而,PyTorch库使它的实现变得很简单,用Fast.ai库加载它就更容易了。

△ 空格表示Dropout函数的作用点
Dropout函数能减弱过拟合效应,因此要在CIFAR-10这样一个相对较小的数据集上取胜,这点很重要。在创建learn对象时,Fast.ai库会自动加入dropout函数,同时可使用ps变量来修改参数,如下所示:
learn = ConvLearner.pretrained(model, data, ps=0.5, precompute=True)
# creates a dropout of 0.5 (i.e. half the activations) on test dataset.
# This is automatically turned off for the validation set有一种很简单有效的方法,经常用来处理过拟合效应和提高准确性,它就是训练小尺寸图像,然后增大尺寸并再次训练相同模型。
# create a data object with images of sz * sz pixels
def get_data(sz):
tmfs = tfms_from_model(model, sz)
# tells what size images should be, additional transformations such
# image flips and zooms can easily be added here too
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
# creates fastai data object of create size
return data
learn.set_data(get_data(299))
# changes the data in the learn object to be images of size 299
# without changing the model.
learn.fit(0.1, 3)
# train for a few epochs on larger versions of images, avoiding overfitting还有一种先进技巧,可将准确率提高若干个百分点,它就是测试时增强(test time augmentation, TTA)。这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数,可调用learn.TTA()来使用该算法。
preds, target = learn.TTA()
这种技术很有效,因为原始图像显示的区域可能会缺少一些重要特征,在模型中输入图像的多个版本并取平均值,能解决上述问题。
10. 创新力很关键

在DAWNBench比赛中,Fast.ai团队提出的模型不仅速度最快,而且计算成本低。要明白,要构建成功的DL应用,不只是一个利用大量GPU资源的计算任务,而应该是一个需要创造力、直觉和创新力的问题。
本文中讨论的一些突破,包括Dropout层、余弦退火和带重启的SGD方法等,实际上是研究者针对一些问题想到的不同解决方式。与简单地增大训练数据集相比,能更好地提升准确率。
硅谷的很多大公司有大量GPU资源,但是,不要认为他们的先进效果遥不可及,你也能靠创新力提出一些新思路,来挑战效果排行榜。
事实上,有时计算力的局限也是一种机会,因为需求是创新的动力源泉。
关于作者
Samuel Lynn-Evans过去10年一直在教授生命科学课程,注意到机器学习在科学研究中的巨大潜力后,他开始在巴黎42学校学习人工智能,想将NLP技术应用到生物学和医学问题中。
原文:
https://blog.floydhub.com/ten-techniques-from-fast-ai/

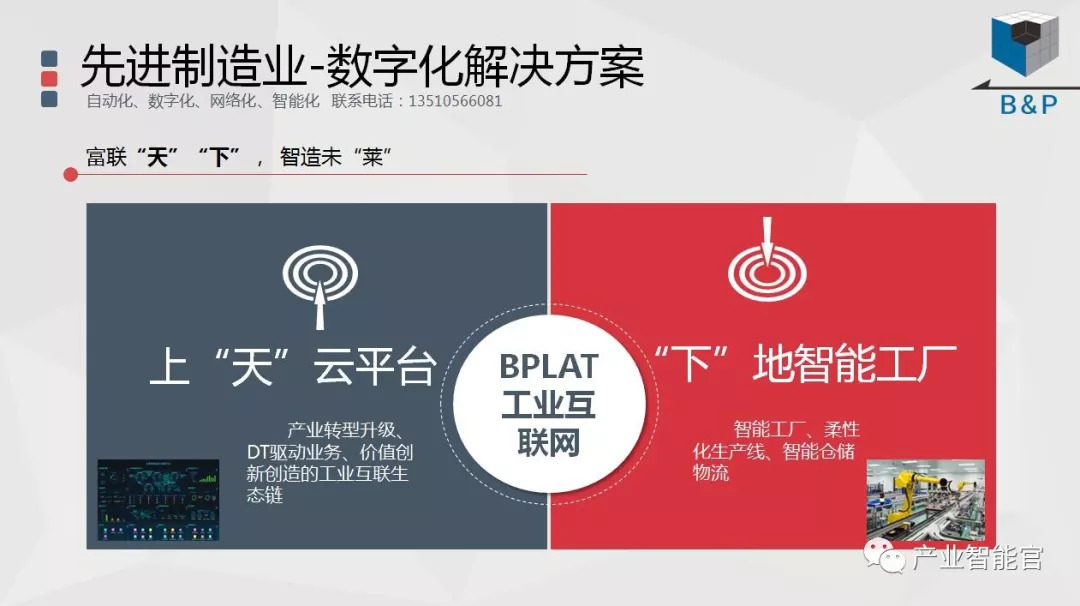
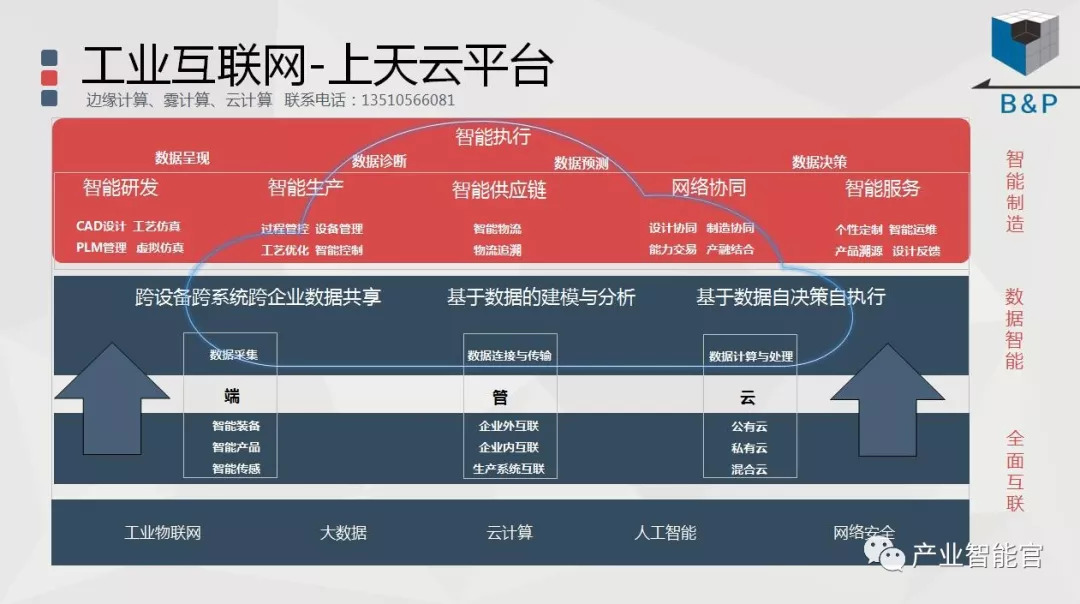
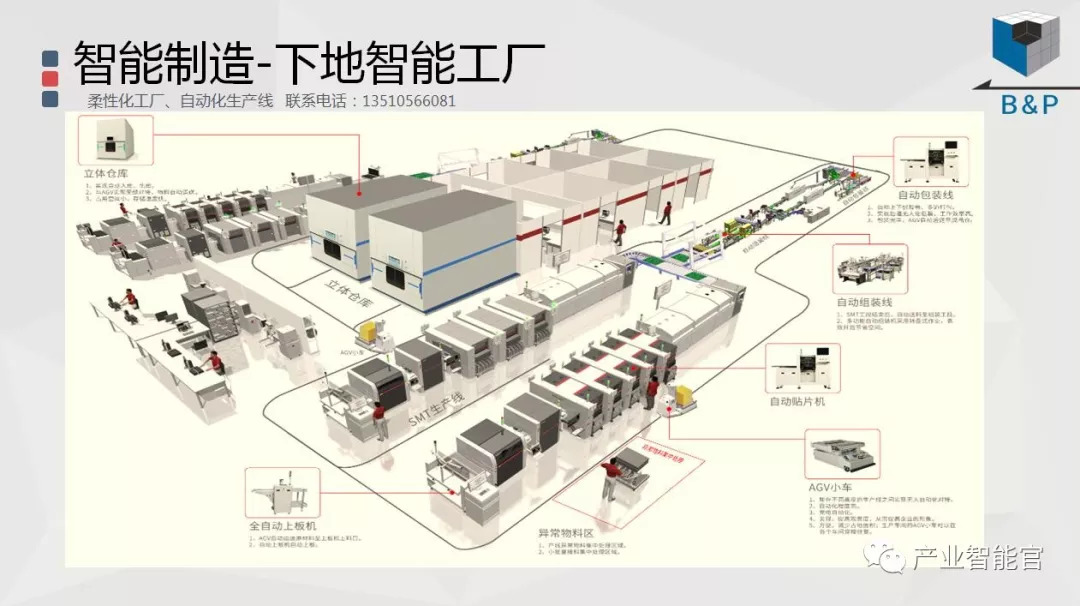
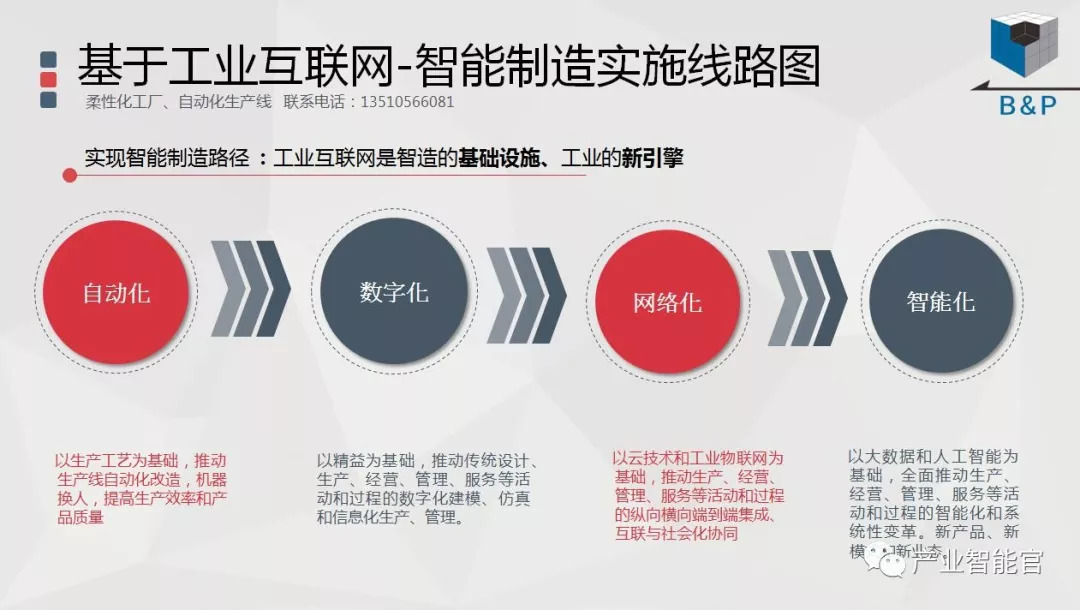

工业互联网
产业智能官 AI-CPS
通过工业互联网操作系统(云计算+大数据+物联网+区块链+人工智能),在场景中构建:状态感知-实时分析-自主决策-精准执行-学习提升的机器智能和认知系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。涉权烦请联系协商解决。联系、投稿邮箱:erp_vip@hotmail.com




