【学界】】NIPS 2018 | MIT新研究参透批归一化原理
选自arXiv
来源:机器之心
作者:Shibani Santurkar 等
参与:李诗萌、路
批归一化(BatchNorm)是一种广泛采用的技术,用于更快速、更稳定地训练深度神经网络(DNN)。尽管应用广泛,但我们并不了解 BatchNorm 有效的确切原因。很多人认为 BatchNorm 的成功与内部协方差偏移有关,但 MIT 的这项研究发现二者并无关系。研究者证明 BatchNorm 以一种基础的方式影响着网络的训练:它使相关优化问题的解空间更平滑了。这确保梯度更具预测性,从而允许使用更大范围的学习率,实现更快的网络收敛。该研究提供这些发现的经验性证明和理论依据。该论文已被 NIPS 2018 接收。
引言
在过去十年间,深度学习在计算机视觉、语音识别、机器翻译以及游戏等诸多困难任务中取得了令人瞩目的进展。这些进展依赖于硬件、数据集以及算法和架构技术等方面的重大突破。这些突破中最突出的例子是批归一化(BatchNorm)[10]。
BatchNorm 是一种通过稳定层输入的分布来改善神经网络训练的方法。它是通过引入额外的网络层来实现的,引入的层控制这些分布的前两个 moment(平均值和方差)。
BatchNorm 在实际应用中取得的成功无可争议。目前无论是研究领域(超过 6000 次引用)还是在现实世界的设置中,大多数深度学习模型都默认使用 BatchNorm。令人震惊的是,尽管它很突出,但我们对 BatchNorm 的原理仍然知之甚少。事实上,现在有一些工作提供了 BatchNorm 的替代方案 [1, 3, 13, 31],但它们都没能让我们更多地理解这个问题。(最近 [22] 也提出了类似观点。)
目前,对 BatchNorm 的成功和原始动机最为人所接受的解释与内部协方差偏移(ICS)相关。通俗而言,ICS 指之前层的更新对层输入分布造成的改变。据推测,这样的连续变化会对训练产生消极影响。BatchNorm 的目标是减少 ICS,从而弥补该负面影响。
虽然这种解释被广泛接受,但似乎也没什么具体的证据可以支持这一论断。尤其是,我们尚不了解 ICS 和训练性能之间的联系。本文的主要目标是解决所有这些不足之处,该研究也带来了一些惊人的发现。
本文的贡献。该研究的出发点是证明 BatchNorm 的性能增益和内部协方差偏移的减少之间没有任何联系,或者说这种联系非常脆弱。事实上,研究发现在某种意义上,BatchNorm 甚至可能不会减少内部协方差偏移。
之后研究者将注意力转向确定 BatchNorm 成功的原因上。具体而言,研究者证明 BatchNorm 以一种基础的方式影响着网络的训练:它使相关优化问题的解空间更平滑了。这确保梯度更具预测性,从而允许使用更大范围的学习率,实现更快的网络收敛。该研究提供这些发现的经验性证明和理论依据。该研究证明了,在自然条件下,有 BatchNorm 的模型改善了损失和梯度的 Lipschitzness(也称为 β 平滑)。
最后我们发现,这种平滑效果并不与 BatchNorm 唯一相关。其他一些自然归一化技术都有相似的效果(有时甚至更强)。即这些方法都提供了类似的训练性能提升。
我们认为,理解 BatchNorm 这样的基本技术的原理可以使我们更好地理解神经网络训练的潜在复杂性,并进一步促进算法的进步。
批归一化和内部协方差偏移
尽管 BatchNorm 在深度学习中具有基础性和广泛性,但我们对 BatchNorm 成功的原因还知之甚少 [22]。本研究的目的是解决这一问题。为此,我们先研究了 ICS 和 BatchNorm 之间的联系。具体而言,我们先在 CIFAR-10 [15] 上分别训练了带 BatchNorm 和不带 BatchNorm 的标准 VGG 架构。如我们所料,图 1(a)和(b)表明用 BatchNorm 训练的网络在优化和泛化性能上都取得了显著的改善。但图 1(c)则呈现出了令人惊讶的发现。在这张图中,我们通过绘制训练中随机输入的分布(按批次)可视化了 BatchNorm 可以在多大程度上稳定层输入的分布。令人惊讶的是,有和没有 BatchNorm 的网络的分布稳定性之间的差异(均值和方差的变化)微乎其微。这就提出了以下问题:
(1)BatchNorm 的效果是否和内部协方差偏移相关?
(2)BatchNorm 的层输入分布的稳定性是否可以有效减少 ICS?
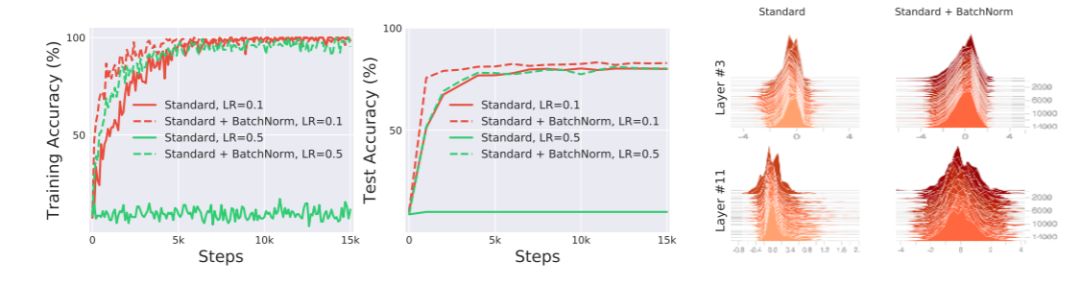
图 1:在 CIFAR-10 上训练带和不带 BatchNorm 的标准 VGG 网络,比较它们的(a)训练(优化)和(b)测试(泛化)性能(细节见附录 A)。有 BatchNorm 层的模型的训练速度是一致的。(c)尽管有 BatchNorm 的网络和没有 BatchNorm 的网络性能之间的差距很明显,但层输入分布的变化差异似乎不太明显。(我们在此采样了给定层的激活值,并在训练步骤中可视化了其分布。)
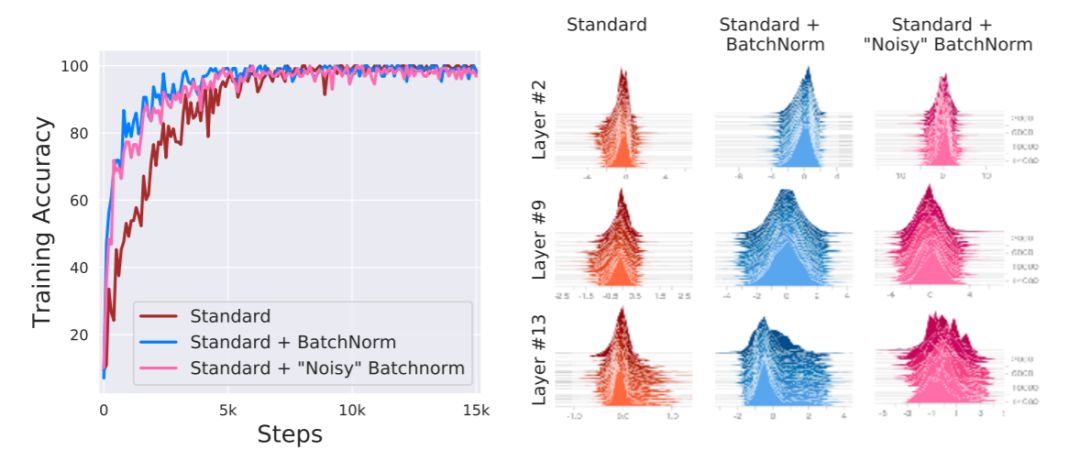
图 2:分布稳定性和 BatchNorm 性能之间的联系:我们比较了没有 BatchNorm 的 VGG 网络(Standard)、有 BatchNorm 的 VGG 网络(Standard+BatchNorm)和在 BatchNorm 层添加了显式「协方差偏移」的 VGG 网络(Standard+「Noisy」BatchNorm)。在最后一种情况中,我们通过添加独立于每个批归一化激活值的时变、非零均值和非单位方差噪声引入分布的不稳定性。尽管完全分布不稳定,但「Noisy」BatchNorm 模型的性能几乎与标准 BatchNorm 模型相当。我们采样了给定层的激活值并可视化了其分布(参见图 8)。
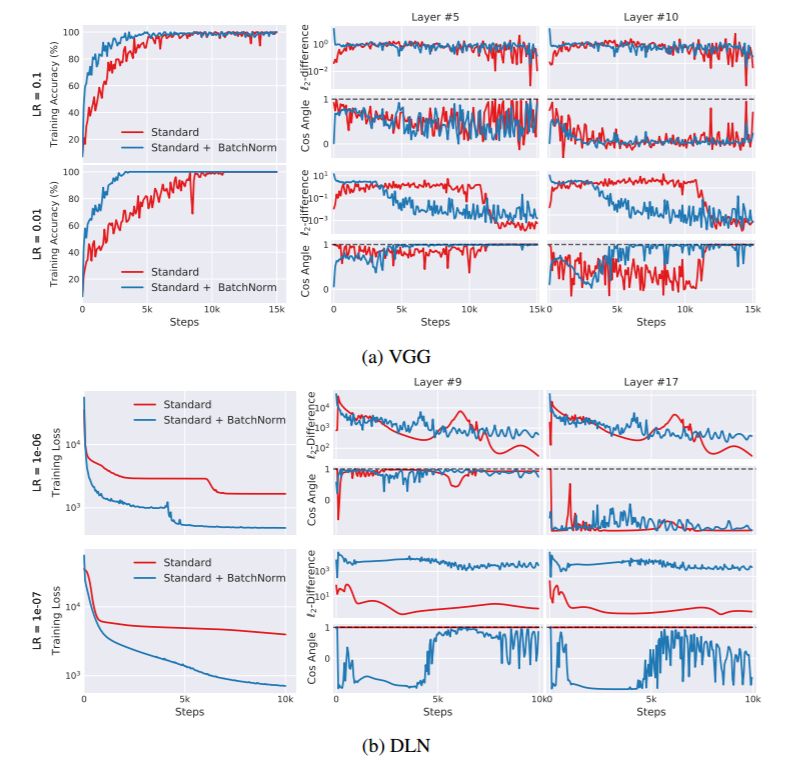
图 3:在有 BatchNorm 层和没有 BatchNorm 层的网络中测量 ICS。对于某一个层,我们测量之前层更新前后的梯度的余弦值(理想情况是 1)和 l_2 差异(理想情况是 0)。尽管从准确率和损失上讲有 BatchNorm 的模型表现更好,但有 BatchNorm 的模型和没有 BatchNorm 的模型的内部协方差偏移情况差不多,甚至更差。(在训练期间 BatchNorm 稳定得更快是参数收敛造成的。)
论文:How Does Batch Normalization Help Optimization?

论文链接:https://arxiv.org/pdf/1805.11604v3.pdf
摘要:批归一化(BatchNorm)是一种广泛采用的技术,用于更快速、更稳定地训练深度神经网络(DNN)。尽管应用广泛,但 BatchNorm 有效的确切原因我们尚不清楚。人们普遍认为,这种效果源于在训练过程中控制层输入分布的变化来减少所谓的「内部协方差偏移」。本文证明这种层输入分布稳定性与 BatchNorm 的成功几乎没有关系。相反,我们发现 BatchNorm 会对训练过程产生更重要的影响:它使优化解空间更加平滑了。这种平滑使梯度更具可预测性和稳定性,从而使训练过程更快。
BatchNorm 为什么有用?
BatchNorm 的平滑效果
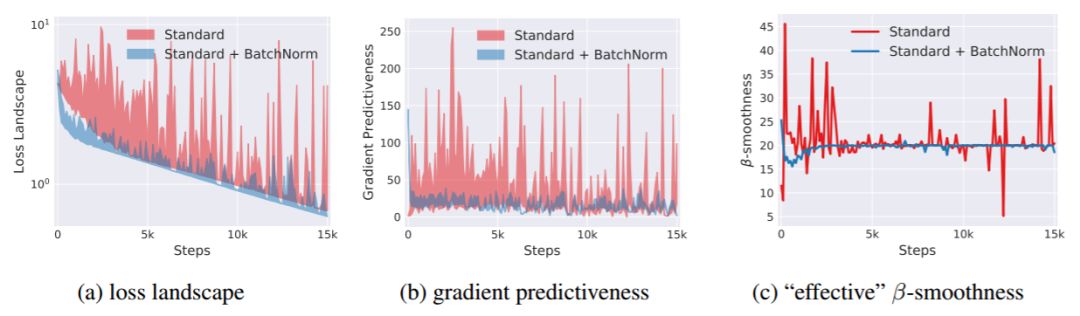
图 4:VGG 网络的优化解空间分析。在特定的训练步中,我们沿着梯度移动的方向测量损失的变化(阴影区域)(a)和梯度中 l2 的变化(b)。「effective」β 平滑 (c) 指的是梯度移动距离对应的最大(l_2 范数)差异。所有这些指标在有 BatchNorm 的网络中都有了明显的改善,这表示损失的解空间更加良好。
BatchNorm 是最好(唯一)的平滑解空间的方法吗?
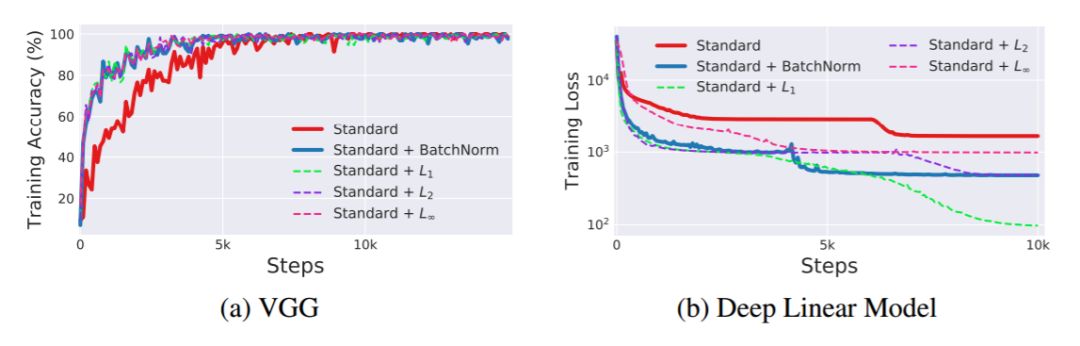
图 5:l_p 归一化技术的训练性能评估。对这两种神经网络而言,所有 l_p 归一化策略的性能都和 BatchNorm 相当,甚至比 BatchNorm 更好。这表明用 BatchNorm 获得的性能增益与分布稳定性(控制均值和方差)无关。
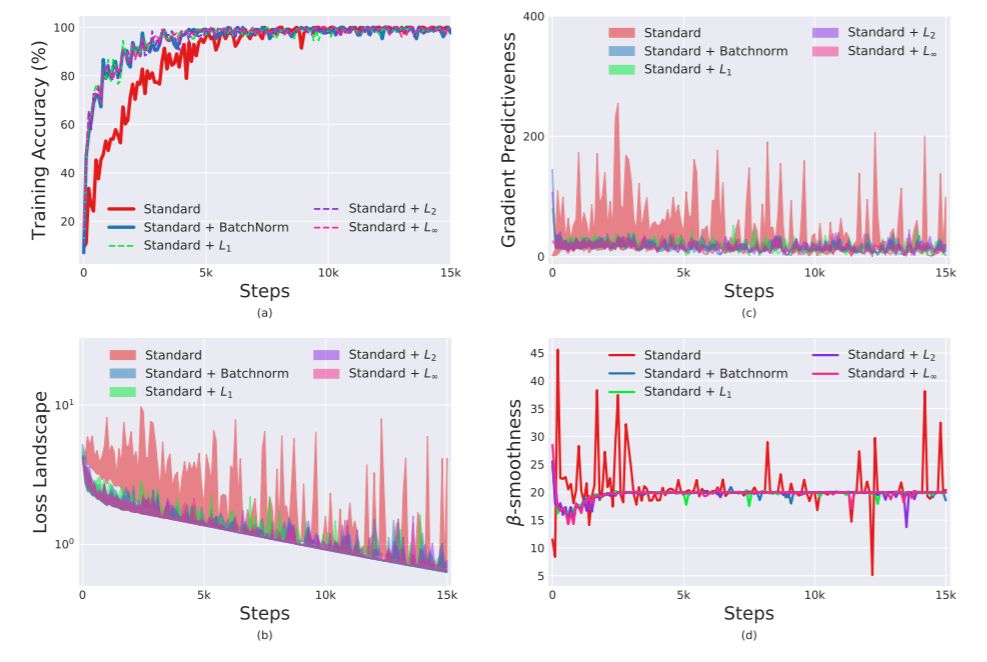
图 12:不同的 l_p 归一化策略训练的 VGG 网络的评估。

☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得


