【致敬ImageNet】ResNet 6大变体:何恺明,孙剑,颜水成引领计算机视觉这两年
【新智元招聘】AI 盛夏,星舰启航。《新一代人工智能发展规划》发布之际,新智元也正式入驻融科资讯中心 B 座,整装待发。天时地利,星辰大海,我们召唤你——新船员的加入!COO、总编、主笔、内容运营、客户总监、客户经理、视觉总监(兼职) 7 大职位招聘全新启动。点击文末 阅读原文 查看详情。
简历投递:jobs@aiera.com.cn HR 微信:Dr-wly
1 新智元报道
作者:Vincent Fung,文强
编译:刘小芹
【新智元导读】2015 年,152 层深的 ResNet 横空出世,不仅取得当年ImageNet竞赛冠军,相关论文在CVPR 2016斩获最佳论文奖。ResNet成为视觉乃至整个 AI 界的一个经典。自那以后,ResNet 得到许多调整和改进,2017 年,基于 ResNet 的双通道网络 DPN 再夺ImageNet冠军,并将 200 层 ResNet 的计算量降低了 57%。本文从 ResNet 的背景知识讲起,梳理 Wide Residual Network(WRN)、ResNeXt、MobileNet 等 ResNet 变体,纵览计算机视觉在这两年的飞速发展,向最后一届 ImageNet 竞赛致敬。

2015 年,ResNet 大大吸引了人们的眼球。实际上,早在 ILSVRC2012 分类竞赛中,AlexNet 取得了胜利,深度残差网络(deep Residual Network)[2]就成为过去几年中计算机视觉和深度学习领域最具突破性的工作。ResNet 使得训练深达数百甚至数千层的网络成为可能,而且性能仍然优异。
由于其表征能力强,ResNet 在图像分类任务之外的许多计算机视觉应用上也取得了巨大的性能提升,例如对象检测和人脸识别。
自 2015 年以后,许多研究对 ResNet 架构进行了调整和改进。在这里,我们先为那些不熟悉 ResNet 的人提供一些背景知识;接下来,梳理关于 ResNet 架构的不同变体及相关论文,包括何恺明等人提出的 ResNeXt、康奈尔大学、清华大学和 Facebook 联合提出的 DenseNet、谷歌 MobileNet、孙剑团队 ShuffleNet,以及最近获得 2017 ImageNet 冠军的颜水成团队的双通道网络 DPN。
根据泛逼近定理(universal approximation theorem),如果给定足够的容量,一个单层的前馈网络就足以表示任何函数。但是,这个层可能是非常大的,而且网络容易过拟合数据。因此,研究界有一个共同的趋势,就是网络架构需要更深。
从 AlexNet 的提出以来,state-of-the art 的 CNN 架构都是越来越深。虽然 AlexNet 只有5层卷积层,但后来的 VGG 网络[3]和 GoogLeNet(也作 Inception_v1)[4]分别有19层和22层。
但是,如果只是简单地将层堆叠在一起,增加网络的深度并不会起太大作用。这是由于难搞的梯度消失(vanishing gradient)问题,深层的网络很难训练。因为梯度反向传播到前一层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降。
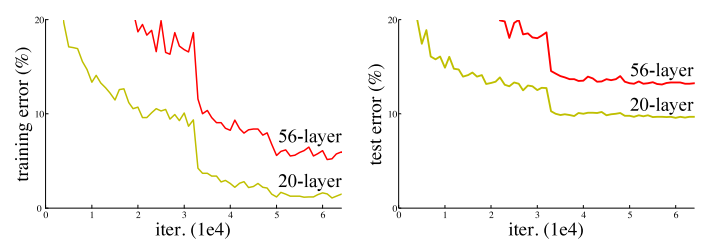
网络深度增加导致性能下降
在 ResNet 之前,已经出现好几种处理梯度消失问题的方法,例如,2015年 C. Szegedy 等人提出的 GoogLeNet [4]在中间层增加一个辅助损失(auxiliary loss)作为额外的监督,但遗憾的是,没有一个方法能够真正解决这个问题。
ResNet 的核心思想是引入一个“身份捷径连接”(identity shortcut connection),直接跳过一层或多层,如下图所示:
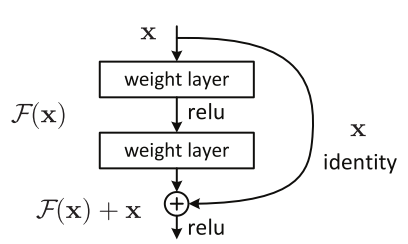
一个残差块
何恺明等人于 2015 年发表的论文《用于图像识别的深度残差学习》(Deep Residual Learning for Image Recognition)[2]中,认为堆叠的层不应该降低网络的性能,因为我们可以简单地在当前网络上堆叠身份映射(层不处理任何事情),并且所得到的架构性能不变。这表明,较深的模型所产生的训练误差不应比较浅的模型的误差更高。作者假设让堆叠的层拟合一个残差映射(residual mapping)要比让它们直接拟合所需的底层映射更容易。上面的残差块(residual block)显然仍让它做到这点。
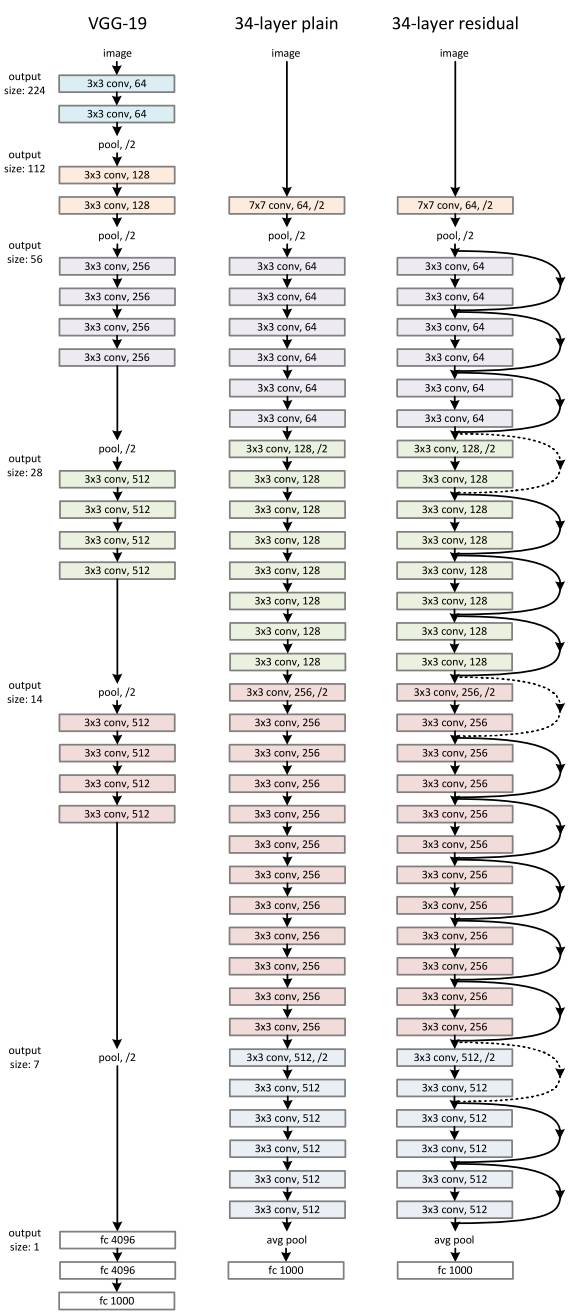
ResNet 的架构
实际上,ResNet 并不是第一个利用 shortcut connection 的方法,R. Srivastava 等人提出的 Highway Network [5]也引入了门控短路连接(gated shortcut connections)。这些参数化的门控制允许多少信息流过短路通道(shortcut)。类似的想法可以在长短期记忆网络(LSTM)[6]单元中找到,其中存在一个参数化的“遗忘门”(forget gate),它控制让多少信息传送到下一个时间步长。因此,ResNet 可以被认为是 Highway Networks 的一种特殊情况。
然而,实验表明,Highway Network 的性能不如 ResNet,因为 Highway Network 的解决方案空间包含 ResNet,它至少应该表现得跟 ResNet 一样好才对,这就显得有点奇怪。这表明,保持这些“gradient highways”的干净相比追求更大的解决方案空间更为重要。
按照这种直觉,前述《用于图像识别的深度残差学习》[2]的作者改进了残差块,并提出一个残差预激活变体[7],其中梯度可以畅通无阻地通过 shortcut 连接到任何其他先前的层。实际上,这一研究表明,使用原始的残差块,训练一个 1202 层的 ResNet 比 110 层的 ResNet 性能更差。
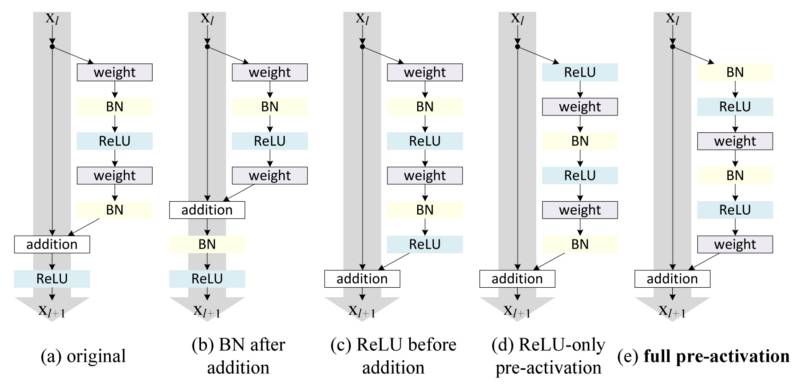
残差块的变体
Identity Mappings in Deep Residual Networks [7]的作者通过试验证明,他们现在可以训练一个 1001 层的深度 ResNet,以超越它的较浅的变体。由于其结果优异,ResNet 迅速成为各种计算机视觉任务最流行的架构之一。
随着 ResNet 在研究界越来越受欢迎,它的架构得到越来越多的研究。
Wide Residual Network(WRN) 由 Sergey Zagoruyko 和 Nikos Komodakis 提出。虽然网络不断向更深层发展,但有时候为了少量的精度增加需要将网络层数翻倍,这样减少了特征的重用,也降低训练速度。因此,作者从“宽度”的角度入手,提出了 WRN,16 层的 WRN 性能就比之前的 ResNet 效果要好。
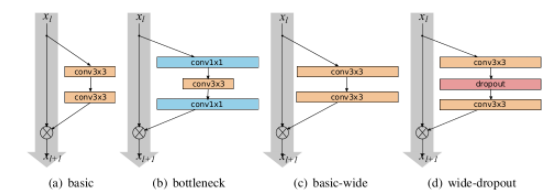
上图中 a,b 是何恺明等人提出的两种方法,b 计算更节省,但是 WDN 的作者想看宽度的影响,所以采用了 a。作者提出增加 residual block 的 3 种简单途径:
1. 更多卷积层
2. 加宽(more feature planes)
3. 增加卷积层的滤波器大小(filter sizes)
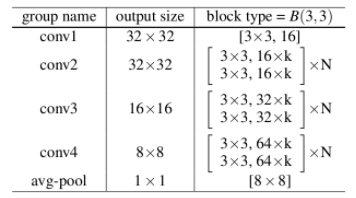
WRN 结构如上,作者表示,小的滤波器更加高效,所以不准备使用超过 3x3 的卷积核,提出了宽度放大倍数 k 和卷积层数 l。
作者发现,参数随着深度的增加呈线性增长,但随着宽度却是平方长大。虽然参数会增多,但卷积运算更适合 GPU。参数的增多需要使用正则化(regularization)减少过拟合,何恺明等人使用了 batch normalization,但由于这种方法需要heavy augmentation,于是作者使用了 dropout。
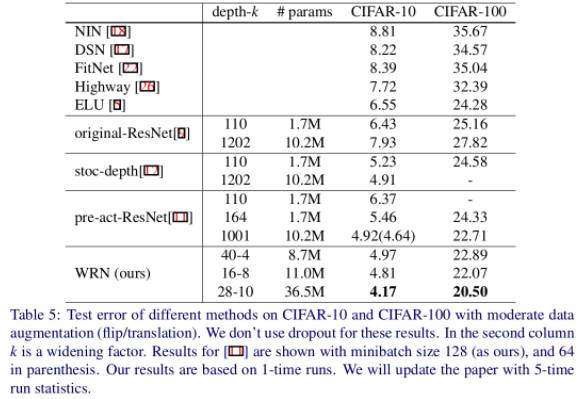
WRN 40-4 与 ResNet-1001 结果相似,参数数量相似,但是前者训练快 8 倍。作者总结认为:
1. 宽度的增加提高了性能
2. 增加深度和宽度都有好处,直到参数太大,正则化不够
3. 相同参数时,宽度比深度好训练
2017 年 2 月,已经加入 Facebook 的何恺明和 S. Xie 等人在《残差变换聚合深度网络》(Aggregated Residual Transformations for Deep Neural Networks)[8]中提出一个名为 ResNeXt 的残差网络变体,它的构建块如下所示:
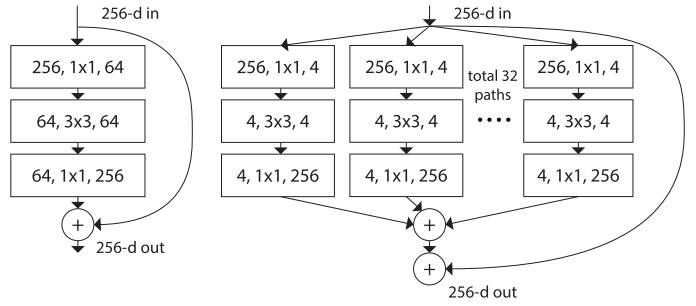
左:[2]的构建块;右:ResNeXt 的一个构建块,基数=32
这个可能看起来很眼熟,因为它与 GoogLeNet [4]的 Inception 模块非常类似。它们都遵循“拆分-转换-合并“的范式,区别只在于 ResNeXt 这个变体中,不同路径的输出通过将相加在一起来合并,而在 GoogLeNet [4]中不同路径的输出是深度连结的。另一个区别是,GoogLeNet [4]中,每个路径彼此不同(1x1, 3x3 和 5x5 卷积),而在 ResNeXt 架构中,所有路径共享相同的拓扑。
ResNeXt 的作者引入了一个被称为“基数”(cardinality)的超参数——即独立路径的数量,以提供一种新方式来调整模型容量。实验表明,通过增加“基数”提高准确度相比让网络加深或扩大来提高准确度更有效。作者表示,基数是衡量神经网络在深度(depth)和宽度(width)之外的另一个重要因素。作者还指出,与 Inception 相比,这种新的架构更容易适应新的数据集/任务,因为它有一个简单的范式,而且需要微调的超参数只有一个,而 Inception 有许多超参数(如每个路径的卷积层核的大小)需要微调。
这一新的构建块有如下三种对等形式:
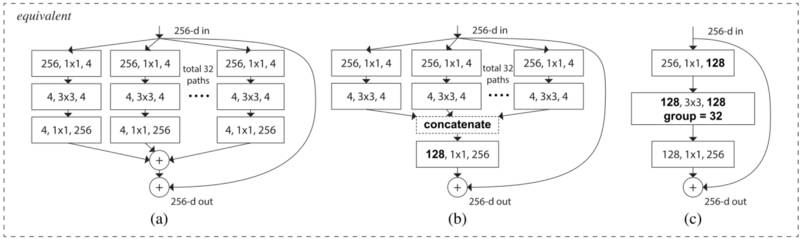
在实践中,“分割-变换-合并”通常是通过逐点分组卷积层来完成的,它将输入分成一些特征映射组,并分别执行卷积,其输出被深度级联然后馈送到 1x1 卷积层。
在 ImageNet-1K 数据集上,作者表明,即使在保持复杂性的限制条件下,增加基数也能够提高分类精度。此外,当增加容量时,增加基数比更深或更宽更有效。ResNeXt 在 2016 年的 ImageNet 竞赛中获得了第二名。
也是在 2016 年,康奈尔大学的 Gao Huang 和清华大学的 Zhuang Liu 等人在论文 Densely Connected Convolutional Networks [9]中,提出一种称为 DenseNet 的新架构。不同于 ResNet 将输出与输入相加,形成一个残差结构,DenseNet 将输出与输入相并联,实现每一层都能直接得到之前所有层的输出。
DenseNet 进一步利用 shortcut 连接的好处——将所有层都直接连接在一起。在这个新架构中,每层的输入由所有前面的层的特征映射(feature maps)组成,其输出传递给每个后续的层。特征映射与 depth-concatenation 聚合。
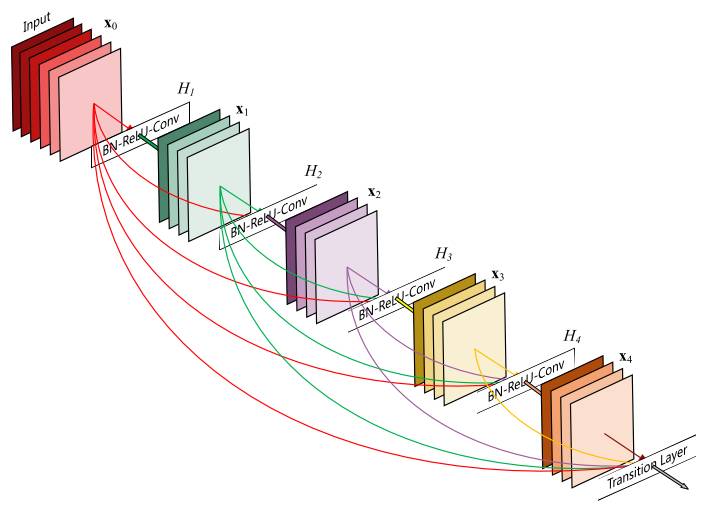
ResNet 将输出与输入相加,形成一个残差结构;而 DenseNet 却是将输出与输入相并联,实现每一层都能直接得到之前所有层的输出。
Aggregated Residual Transformations for Deep Neural Networks [8]的作者除了应对梯度消失问题外,还认为这种架构可以鼓励特征重新利用,从而使得网络具有高度的参数效率。一个简单的解释是,在 Deep Residual Learning for Image Recognition [2]和 Identity Mappings in Deep Residual Networks [7]中,Identity Mapping 的输出被添加到下一个块,如果两个层的特征映射具有非常不同的分布,这可能会阻碍信息流。因此,级联特征映射可以保留所有特征映射并增加输出的方差,从而鼓励特征重新利用。

遵循这个范式,我们知道第 l 层将具有 k *(l-1)+ k_0 个输入特征映射,其中 k_0 是输入图像中的通道数。作者使用一个名为增长率(k)的超参数来防止网络的生长过宽,以及使用一个 1x1 的卷积瓶颈层来减少昂贵的 3x3 卷积之前的特征映射数量。整体结构如下表所示:
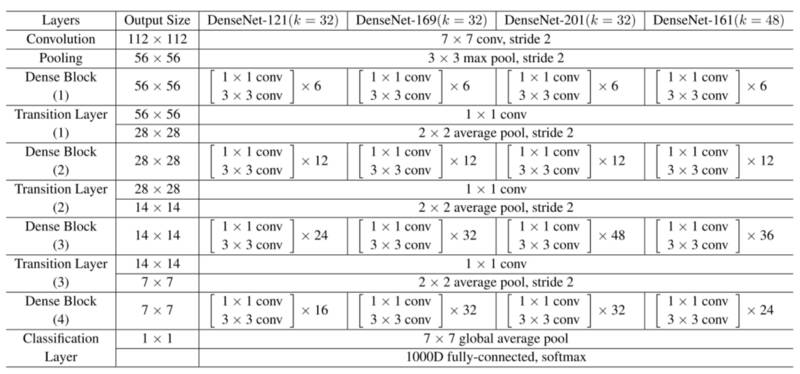
DenseNet的架构
说道 ResNet(ResNeXt)的变体,还有一个模型不得不提,那就是谷歌的 MobileNet,这是一种用于移动和嵌入式设备的视觉应用高效模型,在同样的效果下,计算量可以压缩至1/30。
MobileNet 基于一个流线型的架构,该架构使用 depthwise separable convolution 来构建轻量级的深度神经网络。作者引入了两个简单的全局超参数,有效权衡延迟和准确度。这些超参数能让模型搭建者根据问题的限制为其应用选择适当规模的模型。
新智元此前专门采访了 MobileNet 的其中一位作者,谷歌 G-RMI 团队的朱梦龙。
朱梦龙介绍:“MobileNet 一个很大的亮点是对 depthwise 卷积的大规模使用。将一个二维的 depthwise 卷积和 1x1 的映射卷积组合起来可以很好的逼近普通的三维卷积。对于常用的 3x3 三维卷积来说,利用 depthwise 和 1x1 映射来取代可以将计算量压缩8-9倍,所用到的参数量也大大减少,但仍然保持相类似的精确度。这样的想法来自于矩阵分解,一般如果一个矩阵是 low rank(低秩)的话,可以有很多办法将其分解成为两个或者多个矩阵。另外一个启发是大部分的计算会产生于早期的卷积层,所以 MobileNet 较早的采用 stride 2 而大大减少了计算量。MobileNet 在 ImageNet 分类的任务上能达到类似 VGG 的效果,但是参数和计算量都少了都超过一个数量级(约1/30)。”
【相关新智元报道】
旷视(Face++)孙剑等人的研究团队最近发表了《ShuffleNet:一种极高效的移动端卷积神经网络》一文,作者针对移动端低功耗设备提出了一种更为高效的卷积模型结构,在大幅降低模型计算复杂度的同时仍然保持了较高的识别精度,并在多个性能指标上均显著超过了同类方法。
受 ResNeXt 的启发,作者提出使用分组逐点卷积(group pointwise convolution)来代替原来的结构。通过将卷积运算的输入限制在每个组内,模型的计算量取得了显著的下降。然而这样做也带来了明显的问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换。这将可能影响到模型的表示能力和识别精度。
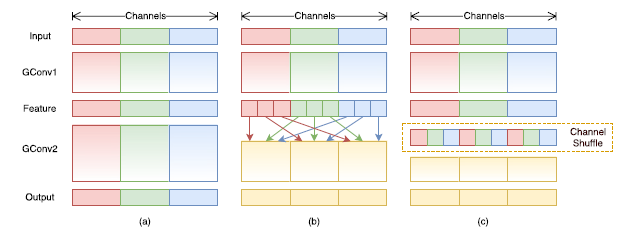
图 1 逐点卷积与通道重排操作
因此,在使用分组逐点卷积的同时,需要引入组间信息交换的机制。也就是说,对于第二层卷积而言,每个卷积核需要同时接收各组的特征作为输入,如图 1(b)所示。作者指出,通过引入“通道重排”(channel shuffle,见图 1(c))可以很方便地实现这一机制;并且由于通道重排操作是可导的,因此可以嵌在网络结构中实现端到端的学习。
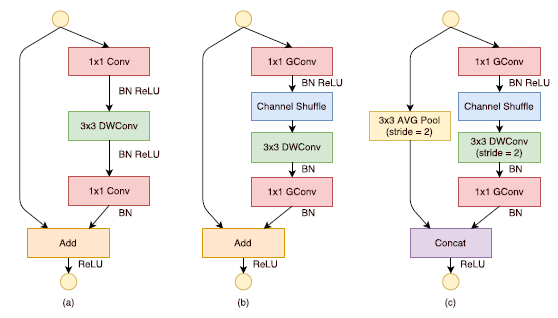
基于分组逐点卷积和通道重排操作,作者提出了全新的ShuffleNet结构单元,如图2所示。该结构继承了“残差网络”(ResNet)[3]的设计思想,在此基础上做出了一系列改进来提升模型的效率:首先,使用逐通道卷积替换原有的3x3卷积,降低卷积操作抽取空间特征的复杂度,如图2(a)所示;接着,将原先结构中前后两个1x1逐点卷积分组化,并在两层之间添加通道重排操作,进一步降低卷积运算的跨通道计算量。最终的结构单元如图2(b)所示。类似地,文中还提出了另一种结构单元(图2(c)),专门用于特征图的降采样。
借助ShuffleNet结构单元,作者构建了完整的ShuffeNet网络模型。它主要由16个ShuffleNet结构单元堆叠而成,分属网络的三个阶段,每经过一个阶段特征图的空间尺寸减半,而通道数翻倍。整个模型的总计算量约为140MFLOPs。通过简单地将各层通道数进行放缩,可以得到其他任意复杂度的模型。
另外可以发现,当卷积运算的分组数越多,模型的计算量就越低;这就意味着当总计算量一定时,较大的分组数可以允许较多的通道数,作者认为这将有利于网络编码更多的信息,提升模型的识别能力。
作者使用一样的整体网络布局,在保持计算复杂度的同时将 ShuffleNet 结构单元分别替换为 VGG-like、ResNet、Xception-like 和 ResNeXt 中的结构单元,使用完全一样训练方法。表2中的结果显示在不同的计算复杂度下,ShuffleNet 始终大大优于其他网络。
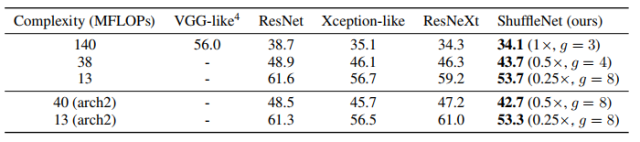
表2 和其他网络结构的分类错误率对比(百分制)
新加坡国立大学与奇虎 AI 研究院合作,指出 ResNet 是 DenseNet 的一种特例,并提出了一类新的网络拓补结构:双通道网络(Dual Path Network)。在 ImageNet-1k 分类任务中:该网络不仅提高了准确率,还将200 层 ResNet 的计算量降低了 57%,将最好的 ResNeXt (64x4d) 的计算量降低了25%;131 层的 DPN 成为新的最佳单模型,并在实测中提速约 300%。
作者发现,Residual Networks 其实是 DenseNet 在跨层参数共享时候的特例。于是,他们结合残差网络和 DenseNet 两者的优点,提出了一类全新的双通道网络结构:Dual Path Network(DPNs)。
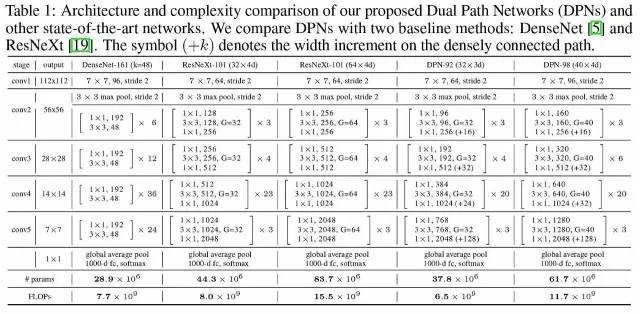
DPN 具体网络结构
其核心思想是,将残差通道和 densely connected path 相融合,实现优缺互补,其重点不在于细节部分是如何设定的。
作者分别在“图像分类”,“物体检测”和“物体分割”三大任务上对 DPN 进行了验证。在 ImageNet 1000 类分类任务中的性能如表 2 所示:
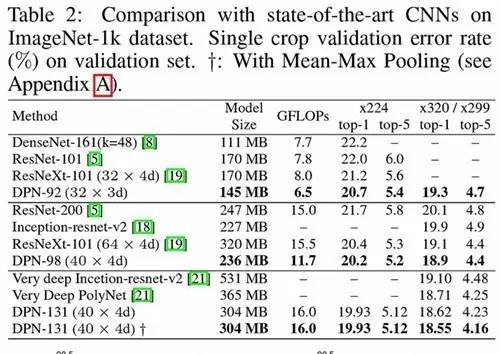
在实测中: DPN-98 也显著提高了训练速度,降低内存占用,并保持更高的准确率。在 ImageNet-1k 分类任务中:该网络不仅提高了准确率,还将200 层 ResNet 的计算量降低了 57%,将最好的 ResNeXt (64x4d) 的计算量降低了25%;131 层的 DPN 成为新的最佳单模型,并在实测中提速约 300%。
就在这周,ImageNet 官方网站公布了 2017 年ImageNet Large Scale Visual Recognition Challenge 2017 (ILSVRC2017) 的比赛结果,在目标定位任务中,新加坡国立大学与奇虎360 合作提出的 DPN 双通道网络 + 基本聚合获得第一,定位错误率为 0.062263。
我们重新回顾了 ResNet 的架构,简要介绍了其最近取得的成功背后的原因。我们还介绍了一些 ResNet 的有趣变体。短短两年,2017 年 ImageNet 竞赛冠军架构——基于 ResNet 的双通道网络 DPN 将 200 层 ResNet 的计算量降低了 57%。
计算机视觉在这两年取得了突飞猛进的发展,回顾 ResNet、WRN、ResNeXt、MobleNet、ShuffleNet 和最新的 DPN,我们在这里向最后一届 ImageNet 竞赛致敬,并期待未来更多更好的轻量级视觉模型。同时,让我们向视觉理解进军。

ILSVRC,再见!
本文中的所有图片均来自参考文献中列出的论文。
References:
[1]. A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems,pages1097–1105,2012.
[2]. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[3]. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556,2014.
[4]. C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 1–9,2015.
[5]. R. Srivastava, K. Greff and J. Schmidhuber. Training Very Deep Networks. arXiv preprint arXiv:1507.06228v2,2015.
[6]. S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, Nov. 1997.
[7]. K. He, X. Zhang, S. Ren, and J. Sun. Identity Mappings in Deep Residual Networks. arXiv preprint arXiv:1603.05027v3,2016.
[8]. S. Xie, R. Girshick, P. Dollar, Z. Tu and K. He. Aggregated Residual Transformations for Deep Neural Networks. arXiv preprint arXiv:1611.05431v1,2016.
[9]. G. Huang, Z. Liu, K. Q. Weinberger and L. Maaten. Densely Connected Convolutional Networks. arXiv:1608.06993v3,2016.
[10]. G. Huang, Y. Sun, Z. Liu, D. Sedra and K. Q. Weinberger. Deep Networks with Stochastic Depth. arXiv:1603.09382v3,2016.
[11]. N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever and R. Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. The Journal of Machine Learning Research 15(1) (2014) 1929–1958.
[12]. A. Veit, M. Wilber and S. Belongie. Residual Networks Behave Like Ensembles of Relatively Shallow Networks. arXiv:1605.06431v2,2016.
本文部分内容来自:https://medium.com/towards-data-science/an-overview-of-resnet-and-its-variants-5281e2f56035 作者:Vincent Fung
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~



