经典ResNet结果不能复现?何恺明回应:它经受住了时间的考验

新智元报道
新智元报道
编辑:小芹
【新智元导读】ResNet原始结果无法复现?大神何恺明的经典之作受到了网友质疑,不过何恺明本人现身解答之后,让真理越辩越明。
大神何恺明受到了质疑。
今天,Reddit 上一位用户对何恺明的ResNet提出质疑,他认为:
何恺明 2015 年的原始残差网络的结果没有被复现,甚至何恺明本人也没有。
网友称,他没有发现任何一篇论文复现了原始 ResNet 网络的结果,或与原始残差网络论文的结果进行比较,并且所有的论文报告的数字都比原始论文的更差。
论文中报告的 top1 错误率的结果如下:
ResNet-50 @ 20.74
resnet - 101 @ 19.87
resnet - 152 @ 19.38
何恺明等人在2015年提出ResNet之后,ResNet很快成为计算机视觉最流行的架构之一,这篇论文已经被引用了超过20000次。

不过,网友称,DenseNet (https://arxiv.org/abs/1608.06993, 3000 + 引用) 和 Wide ResNets (https://arxiv.org/abs/1605.07146, ~1000 引用) 都没有使用这个结果。甚至在何恺明最近的一篇论文中,也没有使用这个结果。
按理说,何恺明这篇论文应该是这个领域被引用最多的论文之一,原始 ResNet 的结果真的没有被复现出来吗?在继续讨论之前,让我们先来回顾一下ResNet的思想,以及它之所以强大的原因。
重新审视 ResNet:计算机视觉最流行的架构之一
2015 年,ResNet 大大吸引了人们的眼球。实际上,早在 ILSVRC2012 分类竞赛中,AlexNet 取得胜利,深度残差网络(deep Residual Network)就成为过去几年中计算机视觉和深度学习领域最具突破性的工作。ResNet 使得训练深达数百甚至数千层的网络成为可能,而且性能仍然优异。
由于其表征能力强,ResNet 在图像分类任务之外的许多计算机视觉应用上也取得了巨大的性能提升,例如对象检测和人脸识别。
自 2015 年以来,许多研究对 ResNet 架构进行了调整和改进。其中最著名的一些 ResNet 变体包括:
何恺明等人提出的 ResNeXt
康奈尔大学、清华大学和 Facebook 联合提出的 DenseNet
谷歌 MobileNet
孙剑团队 ShuffleNet
颜水成团队的双通道网络 DPN
最近南开大学、牛津大学等提出的 Res2Net
……
那么 ResNet 的核心思想是什么呢?
根据泛逼近定理(universal approximation theorem),如果给定足够的容量,一个单层的前馈网络就足以表示任何函数。但是,这个层可能是非常大的,而且网络容易过拟合数据。因此,研究界有一个共同的趋势,就是网络架构需要更深。
从 AlexNet 的提出以来,state-of-the art 的 CNN 架构都是越来越深。虽然 AlexNet 只有 5 层卷积层,但后来的 VGG 网络和 GoogLeNet 分别有 19 层和 22 层。
但是,如果只是简单地将层堆叠在一起,增加网络的深度并不会起太大作用。这是由于难搞的梯度消失(vanishing gradient)问题,深层的网络很难训练。因为梯度反向传播到前一层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降。
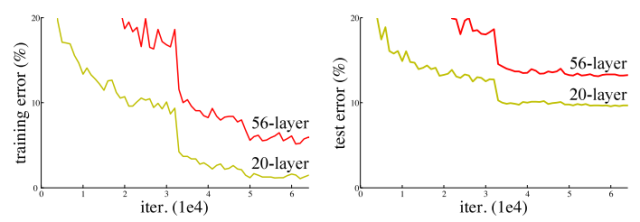
网络深度增加导致性能下降
在 ResNet 之前,已经出现好几种处理梯度消失问题的方法,例如,2015 年 C. Szegedy 等人提出的 GoogLeNet 在中间层增加一个辅助损失(auxiliary loss)作为额外的监督,但遗憾的是,没有一个方法能够真正解决这个问题。
ResNet 的核心思想是引入一个 “恒等捷径连接”(identity shortcut connection),直接跳过一层或多层,如下图所示:
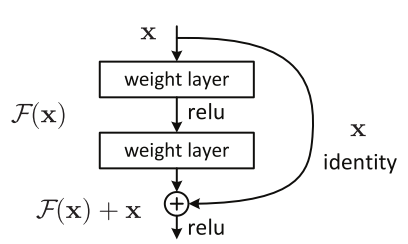
一个残差块
何恺明等人于 2015 年发表的论文《用于图像识别的深度残差学习》(Deep Residual Learning for Image Recognition)中,认为堆叠的层不应该降低网络的性能,因为我们可以简单地在当前网络上堆叠identity映射(层不处理任何事情),并且所得到的架构性能不变。这表明,较深的模型所产生的训练误差不应比较浅的模型的误差更高。作者假设让堆叠的层拟合一个残差映射(residual mapping)要比让它们直接拟合所需的底层映射更容易。上面的残差块(residual block)显然仍让它做到这点。
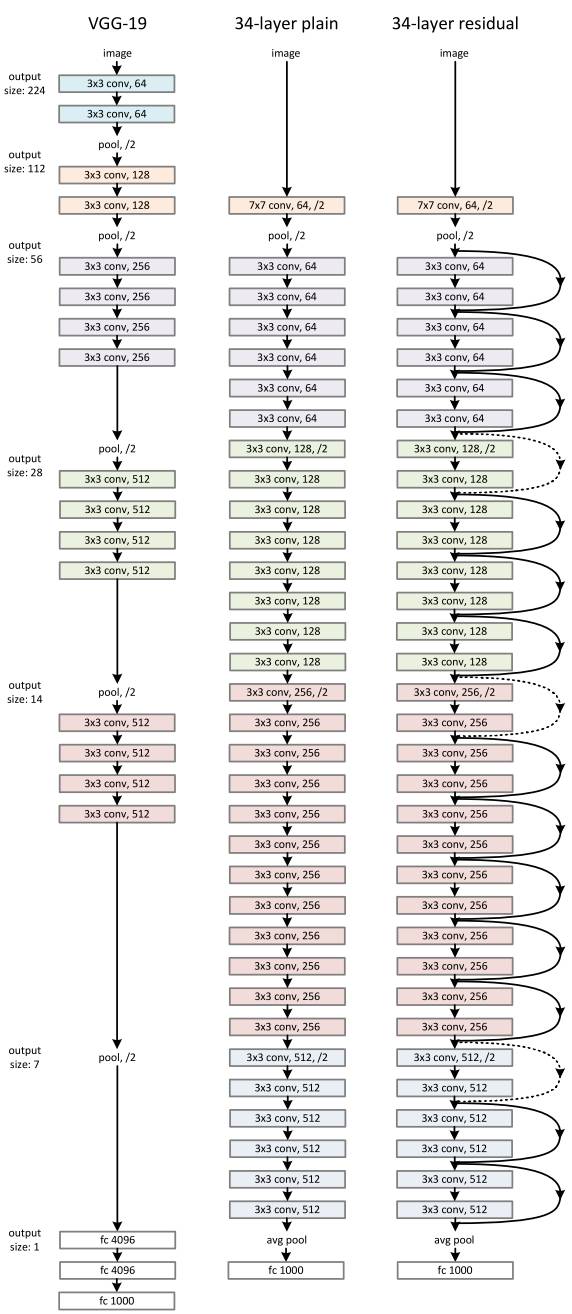
ResNet 的架构
那么这次质疑“不能复现”的结果是什么呢?讨论点集中在原始论文中的表3和表4:
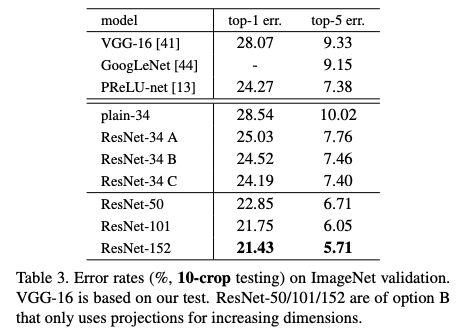
表3:ImageNet验证集上10-crop测试的错误率
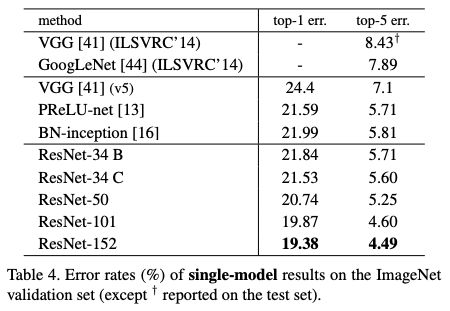
表4:ImageNet验证集上sigle-model的错误率结果
由于其结果优异,ResNet 迅速成为各种计算机视觉任务最流行的架构之一。
新智元昨天发表的文章《对 ResNet 本质的一些思考》,对 ResNet 做了较深入的探讨。作者表示:
不得不赞叹 Kaiming He 的天才,ResNet 这东西,描述起来固然简单,但是对它的理解每深一层,就会愈发发现它的精妙及优雅,从数学上解释起来非常简洁,非常令人信服,而且直切传统痛点。
ResNet 本质上就干了一件事:降低数据中信息的冗余度。
具体说来,就是对非冗余信息采用了线性激活(通过 skip connection 获得无冗余的 identity 部分),然后对冗余信息采用了非线性激活(通过 ReLU 对 identity 之外的其余部分进行信息提取 / 过滤,提取出的有用信息即是残差)。
其中,提取 identity 这一步,就是 ResNet 思想的核心。
再回到文章开头的讨论:原始 ResNet 的结果真的无法复现吗?
针对网友的质疑,不少人在帖子下回复,可以总结为两个方面:
ImageNet 有多种测试策略,后来的论文在复现ImageNet时采用的是当时流行的策略,而非 ResNet 原始论文的策略;
后来的论文在训练时采用了一些与原始论文不同的优化技巧,使得结果甚至比原始 ResNet 论文的结果更好
何恺明本人也第一时间作出回复:
ImageNet 上有几种测试策略:(i) single-scale, single-crop 测试; (ii) single-scale, multi-crop 或 fully-convolutional 测试;(iii) multi-scale, multi-crop 或 fully-convolutional 测试;(iv) 多个模型集成。
在这些设置下,这篇论文的 ResNet-50 模型的 top-1 错误率为:(i) 24.7% (1-crop,如我的 GitHub repo 所展示), (ii) 22.85% (10-crop,论文中的表 3),(iii) 20.74% (full -conv, multi-scale, 论文中的 Table 4)。论文中使用的 (ii) 和 (iii) 的描述见第 3.4 节。
当时是 2015 年,(ii) 和 (iii) 是最流行的评估设置。策略 (ii) 是 AlexNet 的默认值 (10-crop), (ii) 和 (iii) 是 OverFeat、VGG 和 GoogleNet 中常用的设置。Single-crop 测试在当时并不常用。
2015/2016 年后,Single-crop 测试开始流行。这在一定程度上是因为社区已经变成一个对网络精度的差异很感兴趣的环境 (因此 single-crop 足以提供这些差异)。
ResNet 是近年来被复现得最多的架构之一。在我的 GitHub repo 中发布的 ResNet-50 模型是第一次训练的 ResNet-50,尽管如此,它仍然十分强大,并且在今天的许多计算机视觉任务中仍然是预训练的骨干。我认为,ResNet 的可复现性经受住了时间的考验。
Reddit用户ajmooch指出:
你忘记了测试时数据增强 (test-time augmentation, TTA)。表 4 中的数字来自于不同 scales 的 multi-crop 的平均预测 (以计算时间为代价优化精度),而其他论文中的数字是 single-crop 的。
表 3 列出了 10-crop 测试的数据。表 4 的数字更好,所以它肯定不是 single crop 的数字。我的猜测是 n-crop,可能还包括其他增强,比如翻转图像。
这个帖子读起来有点像指责,我不喜欢。ResNet 因为在 ImageNet 测试集上表现出色而著名,而 ImageNet 测试集隐藏在服务器上,他们没有办法在那里处理这些数字。ResNet 是我能想到的被复现最多的架构之一。它显然是合理的。在开始批评别人之前,我们应该先了解我们在批评什么。
谷歌大脑工程师hardmaru也回复道:
在何恺明加入 FAIR 之前, FAIR Torch-7 团队独立复现了 ResNet:https://github.com/facebook/fb.resnet.torch
经过训练的 ResNet 18、34、50、101、152 和 200 模型,可供下载。我们包括了使用自定义数据集,对图像进行分类并获得模型的 top5 预测,以及使用预训练的模型提取图像特征的说明。
他们的结果如下表:
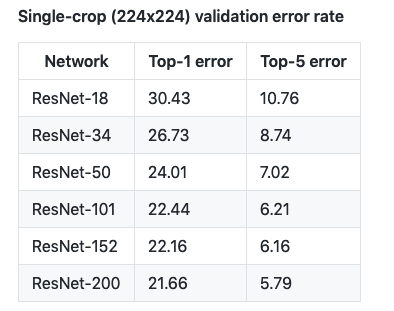
经过训练的模型比原始 ResNet 模型获得了更好的错误率。
但是,考虑到:
这个实现与 ResNet 论文在以下几个方面有所不同:
规模扩大 (Scale augmentation):我们使用了 GooLeNet 中的的规模和长宽比,而不是 ResNet 论文中的 scale augmentation。我们发现这样的验证错误更好。
颜色增强 (Color augmentation):除了在 ResNet 论文中使用的 AlexNet 风格的颜色增强外,我们还使用了 Andrew Howard 提出的的亮度失真 (photometric distortions)。
权重衰减 (Weight decay):我们将权重衰减应用于所有权重和偏差,而不仅仅是卷积层的权重。
Strided convolution:当使用瓶颈架构时,我们在 3x3 卷积中使用 stride 2,而不是在第一个 1x1 卷积。
何恺明的 GitHub 有 Caffe 模型训练的原始版本和更新版本的 resnet,而且报告的也不同:
(https://github.com/KaimingHe/deep-residual-networks/blob/master/README.md)

也许他的 GitHub 报告中的方法与论文不一致,但为了可重复性而不使用相同的方法也有点奇怪。
也许 arxiv 或 repo 应该使用一致的数字进行更新,或者更好的是,使用多次独立运行的平均值。
但是随着 SOTA 的改进和该领域的发展,其他人花费资源来产生旧的结果的动机就更少了。人们宁愿使用他们的资源来复现当前的 SOTA 或尝试其他新想法。
许多人引用它是因为它的概念本身,而不是为了报告排行榜分数。
【2019新智元 AI 技术峰会精彩回顾】
2019年3月27日,新智元再汇AI之力,在北京泰富酒店举办AI开年盛典——2019新智元AI技术峰会。峰会以“智能云•芯世界“为主题,聚焦智能云和AI芯片的发展,重塑未来AI世界格局。
同时,新智元在峰会现场权威发布若干AI白皮书,聚焦产业链的创新活跃,评述AI独角兽影响力,助力中国在世界级的AI竞争中实现超越。
嘉宾精彩演讲:








.png")