一周论文 | 论文盘点:检索式问答系统的语义匹配模型(神经网络篇)
slvher:助理来也后端 / 算法工程师 ,目前研发方向为多轮对话系统。
问答系统可以基于规则实现,可以基于检索实现,还可以通过对 query 进行解析或语义编码来生成候选回复(如通过解析 query 并查询知识库后生成,或通过 SMT 模型生成,或通过 encoder-decoder 框架生成,有些 QA 场景可能还需要逻辑推理才能生成回复)。
具体到检索式问答系统,其典型场景是:1)候选集先离线建好索引;2)在线服务收到 query 后,初步召回一批候选回复;3)matching 和 ranking 模型对候选列表做 rerank 并返回 topK。
备注:
1)matching 模型负责对 (query, reply) pair 做特征匹配,其输出的 matching score 通常会作为 ranking 模型的一维特征;
2)ranking 模型负责具体的 reranking 工作,其输入是候选回复对应的特征向量,根据实际需求构造不同类型(如:pointwise, pairwise, listwise)的损失函数,其输出的 ranking score 是候选回复的最终排序依据。各种 learning2rank 模型通常就是在 ranking 阶段起作用;
3)有些检索系统可能不会明确区分 matching 和 ranking 这两个过程。
再具体到短文本场景下的检索式问答系统,由于分词后 term 数量少,导致只基于 term 本身或其 bow 向量进行匹配的检索策略无法令人满意(term 稀疏且表达方式各异导致匹配效果不佳,也没有利用 term 背后的语义)。出于语义特征补充的需求,隐语义模型(如:LSA, PLAS, LDA)得到了普遍关注。再到近几年,利用神经网络(尤其是深度学习)模型对文本做语义表示(semantic representation)后进行语义匹配的方法开始被提出并应用于检索式问答系统。
下面进入正题,盘点一些基于神经网络模型实现语义匹配的典型工作。希望能够抛砖引玉,如有遗漏或错误,欢迎补充或指出。
1. Po-Sen Huang, et al., 2013, Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
这篇文章出自 UIUC 和 Microsoft Research,针对搜索引擎 query/document 之间的语义匹配问题 ,提出了基于 MLP 对 query 和 document 做深度语义表示的模型(Deep Structured SemanticModels, DSSM),结构如下图所示。
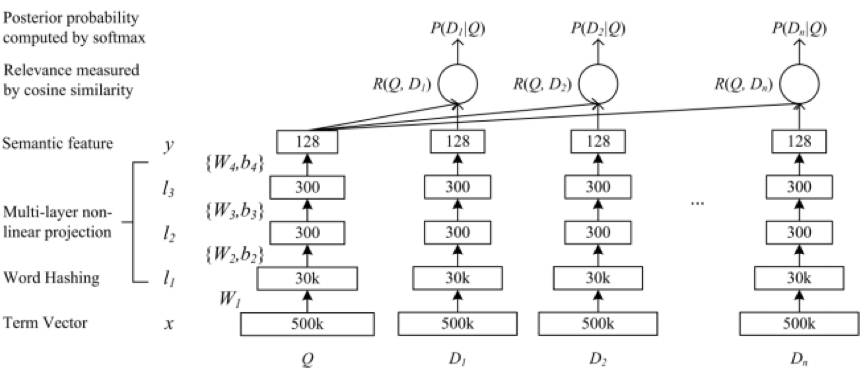
DSSM 模型原理简述如下:
先把 query 和 document 转换成 BOW 向量形式,然后通过 word hashing 变换做降维得到相对低维的向量(备注:除了降维,word hashing 还可以很大程度上解决单词形态和 OOV 对匹配效果的影响),喂给 MLP 网络,输出层对应的低维向量就是 query 和 document 的语义向量(假定为 Q 和 D)。计算 (D, Q) 的 cosinesimilarity 后,用 softmax 做归一化得到的概率值是整个模型的最终输出,该值作为监督信号进行有监督训练。
通过挖掘搜索点击日志构造 query 和对应的正负 document 样本(实验实际使用的是 document 的 title),输入 DSSM 模型进行训练。文中与 TF-IDF、BM25、WTM、LSA、PLSA 等模型进行了对比实验,NDCG@N 指标表明,DSSM 模型在语义匹配方面效果提升明显,当时达到了 SOTA 的水平。
2. Yelong Shen, et al, 2014, A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
这篇文章出自 Microsoft Research,是对上述 DSSM 模型的改进工作。在 DSSM 模型中,输入层是文本的 bag-of-words 向量,丢失词序特征,无法捕捉前后词的上下文信息。基于此,本文提出一种基于卷积的隐语义模型(convolutional latent semantic model, CLSM),结构如下图所示。
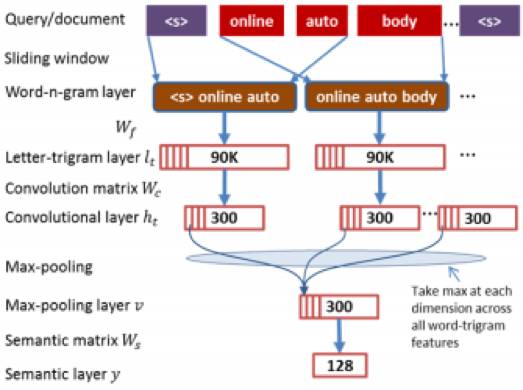
CLSM 模型原理简述如下:
先用滑窗构造出 query 或 document 的一系列 n-gram terms(图中是 trigram),然后通过 word hashing 变换将 word trigram terms 表示成对应的 letter-trigram 向量形式(主要目的是降维),接着对每个 letter-trigram 向量做卷积,由此得到「Word-n-gram-Level Contextual Features」,接着借助 max pooling 层得到「Sentence-Level Semantic Features」,最后对 max pooling 的输出做 tanh 变换,得到一个固定维度的向量作为文本的隐语义向量。Query 和 document 借助 CLSM 模型得到各自的语义向量后,构造损失函数做监督训练。训练样本同样是通过挖掘搜索点击日志来生成。
文中与 BM25、PLSA、LDA、DSSM 等模型进行了对比实验,NDCG@N 指标表明,CLSM 模型在语义匹配上达到了新的 SOTA 水平。文中的实验和结果分析详细且清晰,很赞的工作。
3. Zhengdong Lu & Hang Li, 2013, A Deep Architecture for Matching Short Texts
这篇文章出自华为诺亚方舟实验室,针对短文本匹配问题,提出一个被称为 DeepMatch 的神经网络语义匹配模型。该模型的提出基于文本匹配过程的两个直觉:1)Localness,也即,两个语义相关的文本应该存在词级别的共现模式(co-ouccurence pattern of words);2)Hierarchy,也即,共现模式可能在不同的词抽象层次中出现。
模型实现时,并不是直接统计两段短文本是否有共现词,而是先用 (Q, A) 语料训练 LDA 主题模型,得到其 topic words,这些主题词被用来检测两个文本是否有共现词,例如,若文本 X 和文本 Y 都可以归类到某些主题词,则意味着它们可能存在语义相关性。而词抽象层次则体现在,每次指定不同的 topic 个数,训练一个 LDA 模型,最终会得到几个不同分辨率的主题模型,高分辨率模型的 topic words 通常更具体,低分辨率模型的 topic words 则相对抽象。在高分辨率层级无共现关系的文本,可能会在低分辨率层级存在更抽象的语义关联。不难看到,借助主题模型反映词的共现关系,可以避免短文本词稀疏带来的问题,且能得到出不同的抽象层级,是本文的创新点。
文中提出的 DeepMatch 模型结构如下图所示:
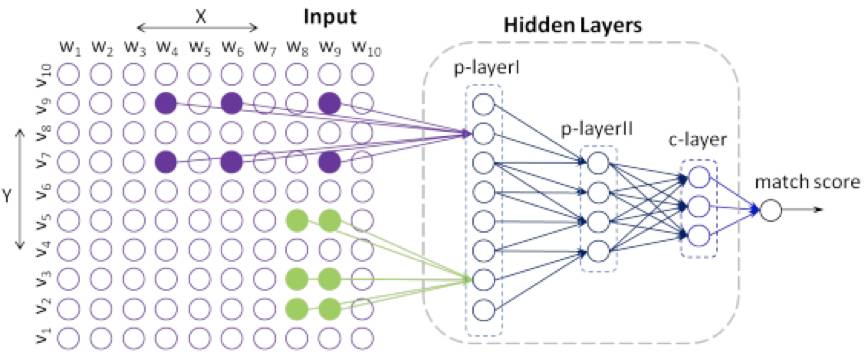
上图比较抽象,但限于篇幅,这里不详细解释。提供几点说明,相信对理解模型细节有帮助。
1)不同抽象层级的 topic words 可以构造出一系列 patches,两个文本 X, Y 在某 patch 上的共现关系构成那个抽象层次的 local decision。
2)上图左侧 Input 部分,不同的颜色代表不同的 topic 抽象层级,这一点要注意,否则很容易被图中的 "偷懒" 画法搞晕。
总之,最终的 matching score 可以构成监督信号来训练模型。文中在给定领域的 QA 语料和新浪微博语料上的实验都表明,与 PLS、SIAMESE NETWORK 等模型相比,DeepMatch 模型在文本语义匹配上,达到了 SOTA 的效果。
PS: 个人感觉 DeepMatch 在构造神经网络结构时略 tricky,不够简洁。
4. Zongcheng Ji, et al., 2014, An Information Retrieval Approach to Short Text Conversation
这篇文章出自华为诺亚方舟实验室,针对的问题是基于检索的短文本对话,但也可以看做是基于检索的问答系统。主要思路是,从不同角度构造 matching 特征,作为 ranking 模型的特征输入。构造的特征包括:1)Query-ResponseSimilarity;2)Query-Post Similarity;3)Query-Response Matching in Latent Space;4)Translation-based Language Model;5)Deep MatchingModel;6)Topic-Word Model;7)其它匹配特征。
文中的实验对比了不同的 matching features 组合对应的 ranking 效果,且对每个 matching 特征的作用做了分析,比较有参考价值。
5. Baotian Hu, et al., 2015, Convolutional Neural Network Architectures for Matching Natural Language Sentences
这篇文章出自华为诺亚方舟实验室,采用 CNN 模型来解决语义匹配问题,文中提出 2 种网络架构,分别为 ARC-I 和 ARC-II,如下图所示:
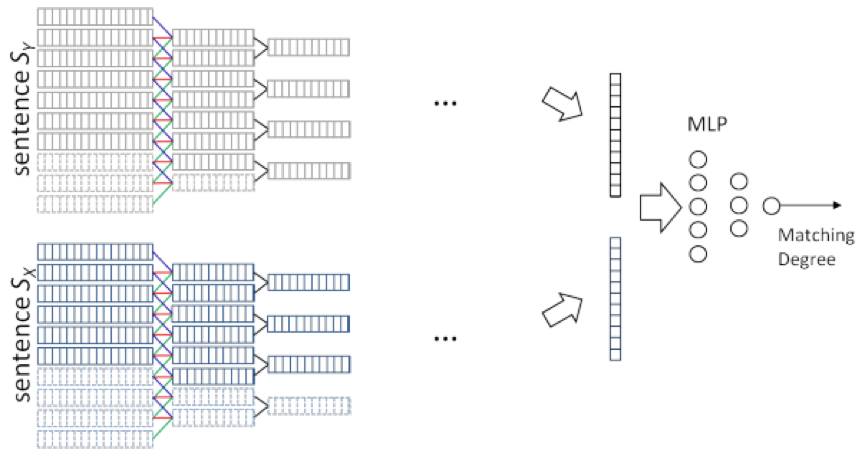
上图所示的 ARC-I 比较直观,待匹配文本 X 和 Y 经过多次一维卷积和 MAX 池化,得到的固定维度向量被当做文本的隐语义向量,这两个向量继续输入到符合 Siamese 网络架构的 MLP 层,最终得到文本的相似度分数。需要说明的是,MAX POOLING 层在由同一个卷积核得到的 feature maps 之间进行两两 MAX 池化操作,起到进一步降维的作用。
作者认为 ARC-I 的监督信号在最后的输出层才出现,在这之前,X 和 Y 的隐语义向量相互独立生成,可能会丢失语义相关信息,于是提出 ARC-II 架构。
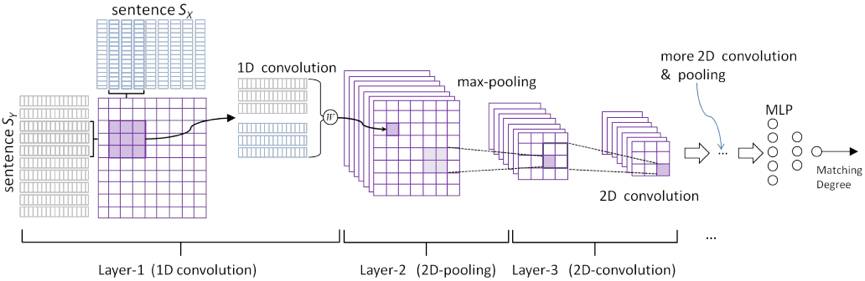
上图所示的 ARC-II 在第 1 层卷积后就把文本 X 和 Y 做了融合,具体的融合方式是,分别对 X 和 Y 做 1D 卷积,然后针对两者卷积得到的 feature maps,构造其所有可能的组合(在两个方向上拼接对应的 feature map),这样就构造出一个 2D 的 feature map,然后对其做 2D MAX POOLING,多次 2D 卷积和池化操作后,输出固定维度的向量,接着输入 MLP 层,最终得到文本相似度分数。
文中的实验结果表明,与 DeepMatch、WordEmbed(即直接累加 word vector 得到 sentence vector)、SENNA+MLP 等模型相比,ARC-I 和 ARC-II 都明显提升了文本语义匹配效果,其中 ARC-II 又明显优于 ARC-I。文中的实验还表明,WordEmbed 作为一种简单的处理方法,通常也能得到不错的匹配效果。
6. Lei Yu, et al., 2014, Deep Learning for Answer Sentence Selection
这篇文章出自 University of Oxford 和 DeepMind,提出基于 unigram 和 bigram 的语义匹配模型,其中,unigram 模型通过累加句中所有词(去掉停用词)的 word vector,然后求均值得到句子的语义向量;bigram 模型则先构造句子的 word embedding 矩阵,接着用 bigram 窗口对输入矩阵做 1D 卷积,然后做 average 池化,用 n 个 bigram 卷积核对输入矩阵分别做「1D 卷积 + average 池化」后,会得到一个 n 维向量,作为文本的语义向量。文中提出的基于 CNN 的文本语义表示模型如下图所示。
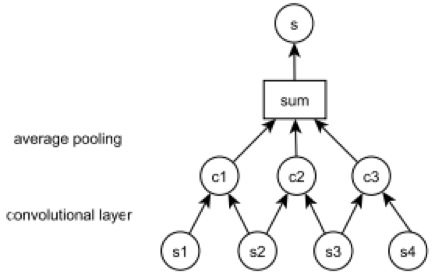
对 (question,answer) 文本分别用上述 bigram 模型生成语义向量后,计算其语义相似度并用 sigmoid 变换成 0~1 的概率值作为最终的 matching score。该 score 可作为监督信号训练模型。
文中用 TREC QA 数据集测试了提出的 2 个模型,实验结果的 MAP 和 MRR 指标表明,unigram 和 bigram 模型都有不错的语义匹配效果,其中 bigram 模型要优于 unigram 模型。特别地,在语义向量基础上融入 idf-weighted word co-occurence count 特征后,语义匹配效果会得到明显提升。文中还将提出的 unigram 和 bigram 模型与几个已有模型进行了效果对比,结果表明在同样的数据集上,融入共现词特征的 bigram 模型达到了 SOTA 的效果。
7. Aliaksei Severyn, et al., 2015, Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks
这篇文章出自 University of Trento (in Italy),是在上述第 6 篇 Paper 基础上做的改进工作,也是用 CNN 模型对文本进行语义表示。与第 6 篇文章提出的 unigram 和 bigram 模型相比,本文的改进点包括:1)使用 n-gram 窗口,可以捕捉更长的上下文语义;2)将 query 和 document 的语义向量及其相似度拼接成新的特征向量输入 MLP 层进行 learning to rank;3)可以在 learng2rank 模型的输入向量中方便地融入外部特征;4)支持 end-to-end 的 matching + ranking 任务。模型结构如下图所示。
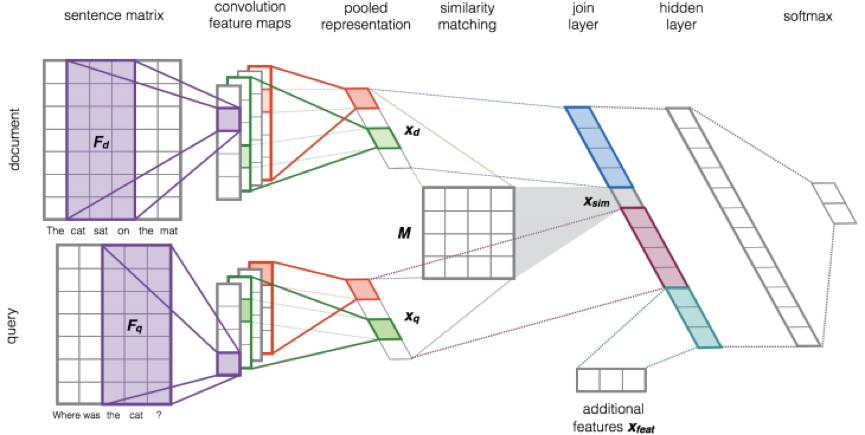
上述模型的逻辑很直观:先分别对 query 和 document 做 wide 1D 卷积和 MAX 池化,得到文本的语义向量,接着通过 M 矩阵变换得到语义向量的相似度,然后把 query 语义向量、query&document 的语义相似度、document 语义向量、外部特征拼接成 n 维向量,输入一个非线性变换隐层,最终用 softmax 做概率归一化。用 softmax 的输出作为监督信号,采用 cross-entropy 作为损失函数进行模型训练。
文中使用 TREC QA 数据集进行了实验,并与第 6 篇 Paper 的模型做了对比,结果表明,本文的模型在 MAP 和 MRR 指标上效果提升显著,达到了新的 SOTA 效果。此外,为测试模型的 reranking 效果,文中还用 TREC Microblog 数据集做了另一组实验,结果表明本文模型比已有模型有明显效果提升。
8. Ryan Lowe, et al., 2016, The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems
这篇文章出自 McGill 和 Montreal 两所大学,针对基于检索的多轮对话问题,提出了 dual-encoder 模型对 context 和 response 进行语义表示,该思路也可用于检索式问答系统。Dual-encoder 模型结构如下图所示。
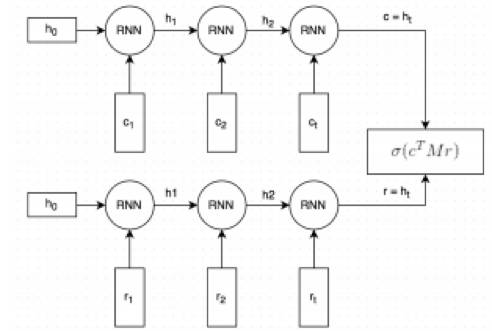
该模型思路直观:通过对偶的 RNN 模型分别把 context 和 response 编码成语义向量,然后通过 M 矩阵变换计算语义相似度,相似度得分作为监督信号在标注数据集上训练模型。
文中在 Ubuntu 对话语料库上的实验结果表明,dual-encoder 模型在捕捉文本语义相似度上的效果相当不错。
总结
从上面 8 篇论文可知,与关键词匹配(如 TF-IDF 和 BM25)和浅层语义匹配(如隐语义模型,词向量直接累加构造的句向量)相比,基于深度学习的文本语义匹配模型在问答系统的匹配效果上有明显提升。

关于 PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






