[强化学习入门]Exploration or Exploitation
点击蓝字关注这个神奇的公众号~
“生存还是死亡,这是一个问题”,在强化学习中,Exploration or Exploitation?it's a problem. 我觉得这两个英文单词来概括强化学习,非常的贴切。强化学习经常被用于例如自动驾驶或是Alphago这样的场景,因为这种场景需要算法根据行为产生的反馈,做出一连串的判断。
Exploration:当我们对这个世界一无所知的时候,探索是唯一了解它的途径。在强化学习的一系列判断中,最初一定是处于信息空白区的,需要大胆的去Exploration,才能够获取更多信息。
Exploitation:经过了一定的Exploration之后,当我们对于这个世界有了一定了解,那么就是开始Exploitation的时候,去根据世界带给我们的反馈,给出最智能的回应。
“The world come with indetermination, but end with intelligence”
-鲁迅 haven't say
下面举一个例子:

如果老鼠走到骷髅头就会,想吃到更多的奶酪,它该怎么走。这里利用强化学习的Q-table方法,去预测每一次老鼠移动所能得到的反馈。
首先画一个Q-table:
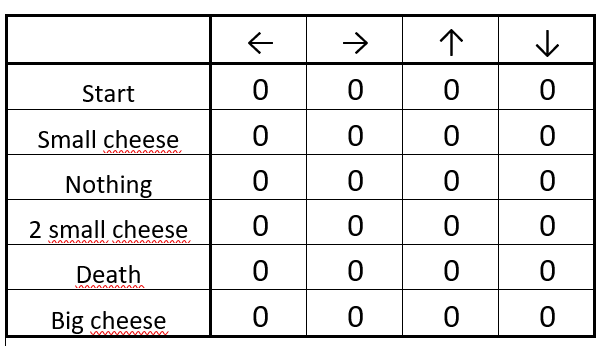
每一行代表上图的一个方格,每一列是一旦发生相应移动所能产生的结果,最初我们对这些一无所知,所以只能从“start”处开始探索,这里面涉及一个公式叫bellman公式,可以计算每一次行为产生的期望分,s为现在的状态status,a为action:
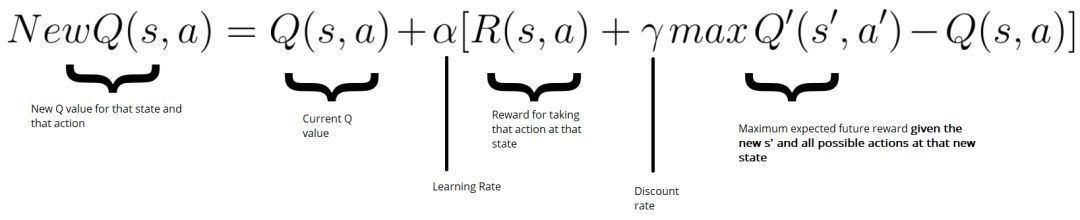
假设第一步是从start处向右走,
* NewQ(s,a)=NewQ(start,right)
* Q(start,right)=0,因为当前是0
* a可以自定义,设为0.9
* R(start,right)为发生这个移动能得到的好处,会吃一个奶酪,所以 R(start,right)=1
* Q‘(s',a')是一旦到了右边这一格,再继续向下、向左、向右得到的最大好处,从图片分析,最多是不死,所以是0
于是算下来NewQ(s,a)=0.1
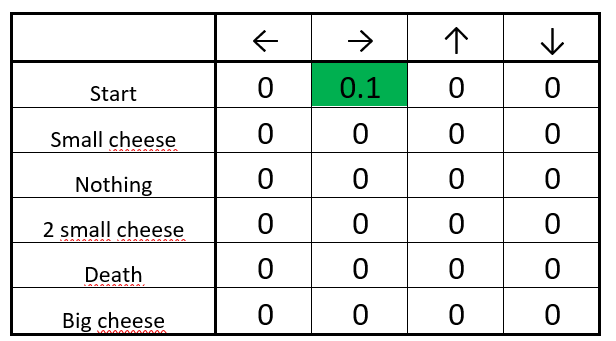
继续移动,直到算出所有行为的一个可能值,填满上面的表格,那么我们每一次做判断都取值做大的action,最终就可以吃最多的奶酪。
不知道大家看懂这个逻辑没有~
(本文参考于https://medium.com/m/global-identity?redirectUrl=https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe,认真拜读后的读后感,感谢这个世界有这么多爱分享的人让我们的黑夜不寂寞

你可以选择关注我
也可以不关注

微信号:凡人机器学习
长按二维码关注