30s到5s!单张图片的无监督语义分割算法理解及原始代码改良
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
授权转载自知乎
https://zhuanlan.zhihu.com/p/68528056
用谷歌搜索 无监督语义分割 unsupervised segmentation,能搜索到的GitHub 代码中,星星比较多的,是下面的这个项目:
Unsupervised Image Segmentation by Backpropagation[1] - Asako Kanezaki 金崎朝子 (東京大学)
https://github.com/kanezaki/pytorch-unsupervised-segmentation
基于作者论文的算法,我成功复现作者算法,代码我也放在Github上
https://github.com/Yonv1943/Unsupervised-Segmentation/tree/master
我复现的代码可以用更短的运行时间(作者用30秒的图,我用5秒),取得相同分割效果。
能有这些提升,不是因为我代码写得多好,而是因为原作者没有实现好她的算法,如下图:
第一行是进行语义分割的输入图片;
第二行是作者放在GitHub上的展示图片;
第三行是我在本地电脑上运行作者源代码得到的结果;
第四行是我基于作者论文的算法,自己用PyTorch进行复现,原先作者使用的是随机颜色,为了美观,我随手计算相同语义标签的平均颜色作为涂色。

算法通过迭代,不断地给具有相似语义的像素分配相同的标签
从美学角度考虑,我从随机配色中选择了不让人感到难受的结果,在一个在线的免费gif生成网站 (https://ezgif.com)上生成gif:

Coral 珊瑚

Woof 哈士奇
下面开始正式介绍这个算法
0.目录
算法主体
算法理解
代码改进
优化效果
算法缺点
补充
回复问题
1. 算法主体
我个人认为原论文的算法写得不好看,我保持算法不变的情况下进行了修改,原文PDF在此[1] ,里面的 Algorithm 1。
——————————————————————————————————
算法:无监督图像分割 Unsupervised image segmentation
——————————————————————————————————
输入: 
输出:










其中,

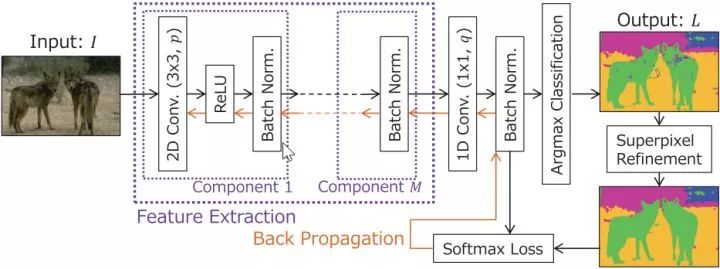
原作者竟把ReLU放在了BN前,把线性整流放在批归一化前面,会影响BN对方差的调整。有类似问题的地方我在复现时改掉。
其中,
skimage.segmentation
中的多个算法,如 原文作者使用的 slic算法[2],以及我推荐使用的felzenszwalb算法[3]。值得注意的是,作者的原始代码中,为slic算法选取了比较极端的参数,选取这个极端参数是有原因的:

在slic算法中,当分区数n_segments 越高,算法对输入图片的分块越多:
由于具有相同语义的像素通常存在于一张图片中的连续区域
从而推测:位置相近的像素,很大概率是属于相同语义
因此,我们在预分类中,为相邻的像素分配相同的语义标签
2. 算法理解:
先使用经典的机器学习算法,为输入图片进行『预分类』:调整算法参数,为语义信息明显相同的小区域分配相同的语义标签。由于具有相同语义的像素通常存在于一张图片中的连续区域,所以我们可以假设:颜色接近,纹理接近,且位置接近的像素,必定可以为其分配相同的语义标签。
然后使用深度学习结合自动编码器结构,对输入图片进行分类,分类的目标是:使输出的语义分割结果,尽可能地符合『预分类』的结果。训练到收敛。
最后,深度学习的语义分割结果,会在符合『预分类结果』基础上,将具备相同语义信息的小区块进行合并,得到大区块。
我的个人的理解是:深度学习(神经网络)在整个无监督语义分割任务中,承担的任务是:对经典机器学习无监督语义分割的细粒度预分类结果进行处理。并在迭代中,逐步对小区块进行合并,最后得到符合人类预期的语义分割结果。

橘猫,无监督语义分割迭代 第 1,2,4,8,16,32,64,128 次的结果
可以观察我前面放出的gif图片,我们可以看到:语义信息相近的小区块,会在迭代的前期得到合并;迭代后期,只剩下2~8个语义标签。此处蕴含着一种树状的分类方式(类似于物种进化树),这样的分类方式比较自然,比如各种不同类型的草,以及虎纹都被很好地区分开来,并且在迭代中优先合并了。
需要改进的地方,如:『虎而不橘』的虎尾、虎眼,在迭代中被错误地分到了和『草』一样的标签,这不是我们希望看到的结果。(我也想到了一些改进方法,在这里就不展开了)

作者的原始代码中,使用随机梯度下降法(SDG)对网络进行训练,并选择了0.1的学习率(默认值是0.001),使得前期的迭代中,算法对像素的合并非常快。
3. 代码改进(仅针对运行效率,使运行时间缩短,不改变主体算法)
重写了算法中的三个for循环,(注意我是根据算法重写,并不是修改)
修改了经典机器学习无监督图片分类的算法:使用felz算法替代slic算法。
修改了卷积网络:使用四层卷积,仿照SENet ,使用3x3与1x1交替,膨胀64 与压缩32
将SDG修改为 Hinton 的 RMSprop,迭代次数大大减少,最终效果精度下降(因此改进的方法依然使用SDG,但是处理大图的时候可自行选用 RMSprop)。
为何我推荐使用felz算法替代slic算法?
在预分类阶段,需要进行足够细粒度的分类,分出足够多的区域(保证该分类的地方被分类到,不该分类的地方,神经网络可以帮助它合并),才能使最终结果更准确。如果分出的类别过多,那么算法需要更多的迭代次数。
使用felz算法替代slic算法,是因为它可以在分出较少区域的情况下,命中更多的『正确边界』,并且felz分出的边界更加准确。无论是选用felz算法或是slic算法,在分出足够多的区域的情况下,对精度影响不大,但迭代次数却有很大不同。我们看图说话吧:

第一列使用了slic算法,分区数n_segments=1000,可以看到虽然分出了很多区域,但是老虎尾巴没有很好地与草丛分开。第二列使用的slic算法,分区数n_segments=100,没有命中我们想要得到的分类边界。
下面是适合了合适参数的预分类算法(对比felz与slic算法)
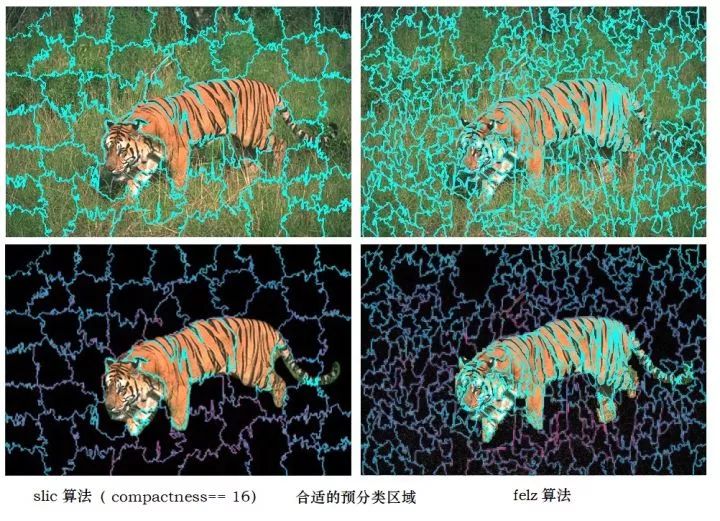
slic,边界条纹不够精细。而felz算法,它甚至连每一条虎纹都分出来了,这是我推荐这个算法的原因之一。
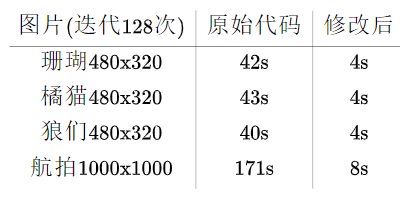
4. 优化结果(迭代128次,40秒→4秒)
由于修改后的代码,可以使用更少的迭代次数达到相同的效果,因此需要的时间比4秒更短。
测试用的图片
修改(魔改)后,不仅耗时缩短,图片分割质量也有所上升,下面是我随便从 法国自动化所的卫星图片数据集Inria Aerial Image[4] 里面的bellingham_x.tif 截取得到的图片 1000x1000,图中包括了 树林,草地,道路,建筑,以及右下角与能够cosplay草地的湖泊(偏绿色)。

对于这一张比较大的图片 1000x1000:
原始代码迭代了128次,耗时3分钟(没有将PyTorch初始化占据的15秒计入):
成功地把树林、道路分开
错误地把部分树林,草地,湖泊归为一类(桃红色)
错误地将建筑物与道路归为一类(淡紫色)
无法将草地与草地完成合并(浅蓝色与亮绿色)
我修改后的代码也迭代了128次,耗时8秒(PyTorch初始化占据了15秒):
成功地把湖泊与草地、树林分开(右下角青蓝色,浅绿色,深绿色)
成功地识别出右下角岸边的一条断断续续的小路(白色)
错误地把近岸的绿色水体与近岸树林合并为一类(深绿色)
错误地把道路分成两种类别(浅灰色,深灰色)
错误地把大部分建筑物与道路归为一类(浅灰色,深灰色)
5. 算法缺点(不够稳健,缺少限制)
首先,这个算法还不够稳健(robust),算法受参数影响大(包括梯度下降法的参数,与机器学习的预分类算法的参数),并且算法多次随机重启的结果会有不同。为了展示这个缺点,我制作了『橘猫望橘图』:( 问:这个方案能把老虎和橘子分开吗?答:有时候能,有时候不能,这个是该算法的缺点。)
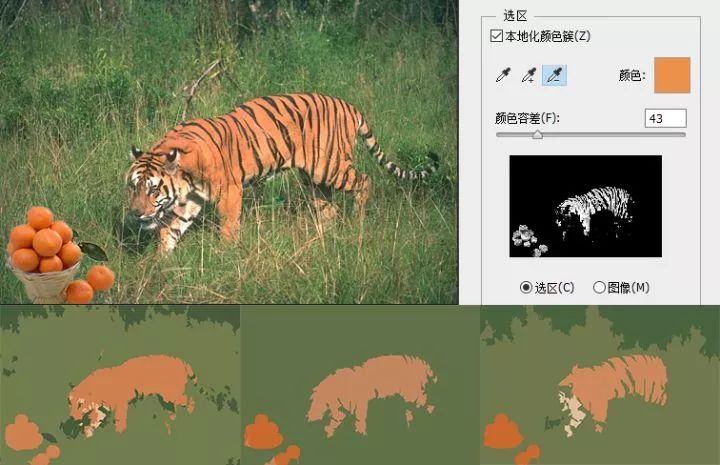
结果图中,橘猫颜色的橘色要比橘子浅,是因为橘猫在计算平均像素的时候,把黑色的条纹也纳入计算了,并非 橘猫橘 与 橘子橘 不同。我特地用了PS去证明两种橘色是相同的,结果图中,橘猫的平均颜色比橘子浅,是因为橘猫的平均颜色中包含了黑色的虎纹。深度学习能把橘子与橘猫区分开,很大的原因是卷积网络能比较好的感知纹理的不同,而不仅仅是依靠颜色去分类。
其次,算法还不够成熟,随着迭代,算法会逐步被合并各个分区。但是算法里却没有设定限制,去抑制神经网络对小区域的合并。
浅草,深草,枯草,,,,虎尾,虎眼,,虎纹,虎皮

深草,浅草,末端虎尾,,,虎皮(橘),虎皮(白)

深草,浅草(+虎的一部分),虎(的大部分)

作者自己的原始代码中,当语义分割的类别数量下降到 3或4类的时候,算法终止,如果去掉训练限制,则当全图都被分入同一个类别时,loss下降到0。原文设计的损失函数,无法对神经网络投机取巧地输出一张仅含有一个类别的结果进行限制。
这意味着训练这个网络的时候,有可能在随机重启的情况下,得到差异巨大的结果,我在运行原始代码的时候也发现了这个问题。由于没有对『一个类别』进行限制,因此这个神经网络的参数量要足够小(足够浅,足够窄),这样的设计太容易过拟合了(没有解决这个问题,模型改进会极度受限)。
(我也想到了一些改进方法,就是用普通机器学习语义分割算法,得到一些必定属于不同语义的标签,作为对『一个类别』进行的限制,在这里就不展开了)
6. 补充
felz算法与slic算法
性能提升与GPU
felz算法
Efficient Graph-Based Image Segmentation - Felzenszwalb (MIT)[3] 2004. 基于图形的语义分割。Gestalt movement(整体心理学/格式塔心理学)认为:人类根据事物的整体做出判断。而Felz 算法定义了一种使用了基于图像表示(graph-based representation) 界定两个区域边界的方法(define a predicate)。尽管这种方法会做出贪婪的决策,但它依然产生的是满足全局观点(global properties)的结果。
算法的时间复杂度是线性的,实际运行时速度快。(以前的方法对于实际应用来说都太慢了,毕竟是上世纪的算法 [5][6])
对于变化幅度小的图片(low-variability),它能把很好地处理细节。在变化幅度大的图片,也能忽略掉一些细节。某些经典聚类算法一样,felz算法也是基于对图片边缘的选择,每个像素都对应无向图上的一个节点。每条边的权重描述了节点两个像素之间不相似的程度。然而,与经典方法不同的是:这篇文章的算法可以根据相邻区域的变化程度(variability)调整分割标准。
翻译自felz论文的 介绍Intorduction 部分。
slic算法
SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. 2012. 略,作者论文算法描述中,与原始代码中的出现的 SuperPixel ,在此论文中也有出现。加粗吐槽,上面的felz算法是2004年的,slic算法是2012年,然而slic的标题中却有 State-of-the-Art? 没有做到全面超越的情况下还是不要这么说,欲戴王冠,必承其重。
性能提升与GPU
因为代码是单线程的,所以耗费在CPU上的时间越短,对GPU的利用率越高。因此,尽管我为了美观,计算所有类别中像素的平均颜色,耗时还是比原代码短。无论是从运行速度上,还是分割精度上,我认为算法还有很大的改进空间。
欢迎评论,有错指出,多多交流
6. 回复评论区的问题
@cm cm
问:这个设计是不分训练和推理的是吗?每次对一张图片的分割都会重新训练网络的权重?
答:“是的,训练的过程就是推理”。这个算法和风格迁移的初始版本一样,通过在单张图片上进行训练,得到最终结果。在李飞飞她们组的 real time style transfer[7] 出来之前,风格迁移的结果是“训练”出来的,训练得到的网络参数并不能保存下来继续在其他图片上使用。所以这个算法还不够成熟(我很想把它改成 real time的)。
@一秒一喵
认为:flez,然后用平均色给像素填色(并计算方差),然后Kmean(k=4),我感觉200毫秒就能搞定比这个展示的分割好很多的效果,还没用到神经网络。(感谢他的建议)... ... 我已经用flez加yuv空间的平均色加minibatchkmean做出150毫秒(cpu)和你差不多的结果了。虎皮没有任何问题, ... ... (详情见评论区)
答:在法国的机器学习库 sklearn 中,已经有类似的算法了,Region Adjacency Graph (RAG) and merges regions which are similar in color。后面使用flez算法加yuv空间的平均色加 mini-batch + K-mean的方案,我认为这样子做的确可行的,有机会我会试试的,但是前面基于相同颜色分类的算法,的确是毫秒级别的算法。不过这种前面提及的这种算法存在以下问题:
该算法对机器学习语义分割聚类的预分类的结果敏感,需要找到适合的预分类参数。
平均颜色的方法无法将「黑色的虎纹」与「橘色的虎皮合并」(见草丛橘猫图)
平均颜色会错误地将某些区域合并,这些区域明显不同却有相近的平均颜色。仅仅依靠颜色是不行的,还需要深度学习对纹理的感知。
与问题3相关的gif:下面将RAG算法中使用到的阈值从 4 逐步递增到 128,当阈值在32 的时候得到相对较好的结果。

使用slic算法(n_segments=2048, compactness=16, max_iter=8) # 分出更多区域

使用slic算法(n_segments=128, compactness=16, max_iter=8) # 分出合适区域
与问题1相关的图片:左图右图服从正态分布,均值128, 方差16,而右图的每一行使用了排序。从而得到服从相同分布 

另外,可以使用计算特征矩(测度 Moments[8])、SSIM等方法,将上面的两个区域区分开。但是这些方式要求被比较的两个对象必须拥有相同的区域形状(比如都是相同长宽的矩形,相同大小的圆形),并且每一此只能比较两个对象,因此算法中的比较部分,其复杂度必定超过 O(n*log(n))。
OpenCV
cv2.Moments 测度
中心距:
零阶矩,质量, 概率
一阶矩,质心, 方差
二阶矩,转动惯量, 偏斜度
三阶矩,平滑度 峰度
图形:
空间矩:mOO,面积,质量
中心矩:muOO,图像强度的最值方向,只具有平移不变性
中心归一化矩:nuOO
Hu不变矩,具有旋转,缩放和平移不变性
cv2.matchShape()
cv2.matchShapes(contour1, contour2, method, parameter) → retval
Structural Analysis and Shape Descriptors
method=CV_CONTOURS_MATCH_I1 倒数相减,绝对值求和
method=CV_CONTOURS_MATCH_I2 相减,绝对值求和
method=CV_CONTOURS_MATCH_I3 相减,归一化(第一个当分母),绝对值求和
参考
unsupervised image segmentation. ICASSP. 2018 https://kanezaki.github.io/pytorch-unsupervised-segmentation/ICASSP2018_kanezaki.pdf
机器学习 无监督语义分割 SLIC Superpixels Compared to State-of-the-art Superpixel Methods, TPAMI, May 2012. http://www.kev-smith.com/papers/SMITH_TPAMI12.pdf
机器学习 无监督语义分割 Efficient Graph-Based Image Segmentation. IJCV. 2004 http://people.cs.uchicago.edu/~pff/papers/seg-ijcv.pdf
法国自动化所 卫星图片数据集(其实是航拍的Aerial Image) https://project.inria.fr/aerialimagelabeling/
Conference on Computer Vision and Pattern Recognition. IEEE. 1997
Segmentation using Eigenvectors: A Unifying. ICCV. 1999.
Perceptual Losses for Real-Time Style Transfer and Super-Resolution. Johnson. ECCV. 2016 https://cs.stanford.edu/people/jcjohns/papers/eccv16/JohnsonECCV16.pdf
OpenCV cv2.Moments 测度 https://blog.csdn.net/qq_30815237/article/details/86925736
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




