语义分割江湖的那些事儿——从旷视说起
今天的主题是Face++ Detection组近两年持续在做的Semantic Segmentation相关工作,代表性成果主要有:
GCN (CVPR2017)
DFN (CVPR2018)
BiSeNet (ECCV2018)。
我们先来看一段演示 Demo:
回顾
介绍算法之前,我们先简单回顾一下语义分割(semantic segmentation)的历史。众所周知,计算机视觉有三大核心任务——分类、检测、分割,三者号称是深度学习炼丹师的“三大浪漫”。分类针对整张图片,检测针对图片的局部,语义分割则如图1所示,旨在给输入图片上的每个像素赋予一个正确的语义标签。

图 1:PASCAL VOC 2012图片示例
传统的分割算法我们先按下不表。时间拨回到2015年,语义分割江湖之中,FCN横空出世,自此DL/NN方法席卷了整个语义分割领域。短短几年,各个Benchmark的state-of-the-art不断刷新,成果喜人。
FCN前期阶段,研究重点主要是解决“网络逐渐衰减的特征尺寸和需要原图尺寸的预测之间的矛盾”,换言之,就是如何解决网络不断downsample造成的信息损失;期间百家争鸣,百花齐放,涌现了希望保存或者恢复信息的unpool、deconv等方法,也出现了进行结构预测的各种花式CRF方法。
“大道之争”之中,碰撞出了两个最重要的设计:U-shape Structure和Dilation Conv,据此形成当下语义分割领域网络设计最常见的两大派系:
U-shape 联盟以RefineNet、GCN、DFN等算法为代表;
Dilation联盟以PSPNet、Deeplab系列方法为代表;
随着Base Model性能不断提升,语义分割任务的主要矛盾也逐渐渐演变为“如何更有效地利用context”;这中间又是一番腥风血雨,我们今天介绍的3位主角也在其中贡献了一份力量。
介绍
语义分割任务同时需要Spatial Context和Spatial Detail 。今天我们介绍的三种算法都将从这两方面分别提出各自对应的解决方案。整体对比如下:

Global Convolutional Network
第一位主角是CVPR2017算法Global Convolutional Network(GCN),江湖人送外号“Large Kernel”。论文Arxiv链接请见:arxiv.org/abs/1703.0271。
1、Motivation
GCN主要将Semantic Segmentation分解为:Classification和Localization两个问题。但是,这两个任务本质对特征的需求是矛盾的,Classification需要特征对多种Transformation具有不变性,而 Localization需要对Transformation比较敏感。但是,普通的Segmentation Model大多针对Localization Issue设计,正如图2(b)所示,而这不利于Classification。
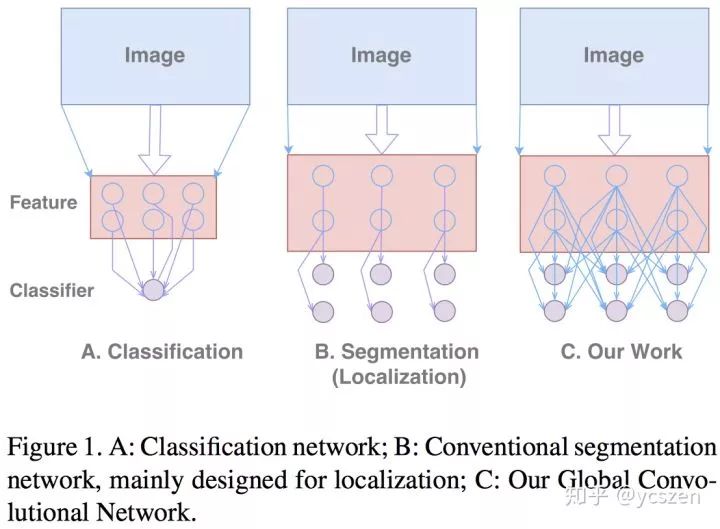
图 2
所以,为了兼顾这两个Task,本文提出了两个Principle:
从Localization来看,我们需要全卷积网络,而且不能有全连接或者全局池化等操作丢失位置信息。
从Classification来看,我们需要让Per-pixel Classifier或者Feature Map上每个点的连接更稠密一些,也就需要更大的Kernel Size,如图2(c)所示。
2、网络结构
根据这两条Principle,本文提出了Global Convolutional Network(GCN)。如图3所示,这个方法整体结构正是背景介绍中提到的U-shape结构,其核心模块主要包括:GCN和BR。
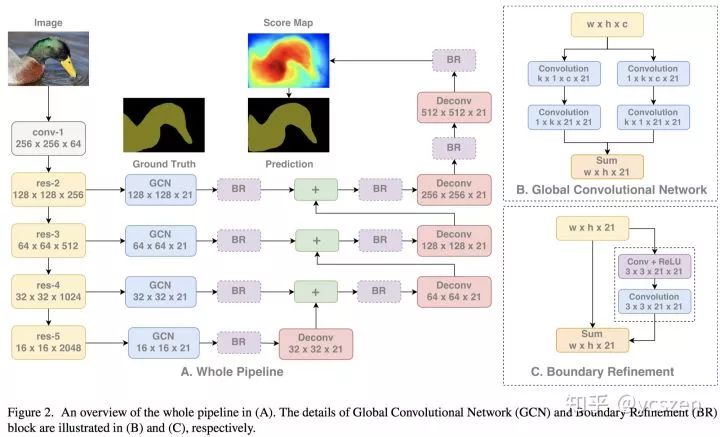
图 3:网络结构
此处主要介绍GCN设计。正如图3(b)所示,它采用了较大Kernel Size的卷积核,来同时解决上述的两个Issue;然后根据矩阵分解,利用1x k + k x 1和k x 1 + 1 x k的卷积来替代原来的k x k大核卷积。相对于原本的大核卷积,该设计能明显降低参数量和计算量。图4可视化了Large Kernel Conv和普通Conv网络有效感受野的对比。

图 4
可以看到,Large Kernel Conv 的有效感受野显著增大。
3、实验
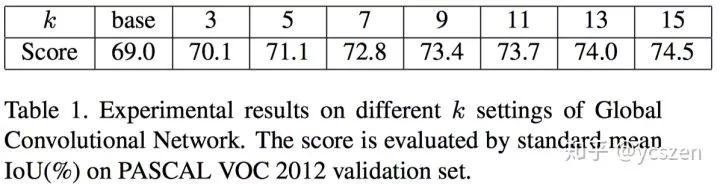
文中为了验证Large Kernel Conv的有效性,对比了不同Size的 Kernel,可以看到Kernel Size=15时比 Base Network整整高了5.5% mean IoU.
此外,文中还对Large Kernel Conv进行了一系列讨论。
GCN的有效是否得益于更多的参数?
在GCN中,随着Kernel Size的增加,网络参数也随之增长,那么网络性能的提升是否得益于使用了更多的参数?为了证明提升来自于设计的有效性而不是增加了复杂度,文中设计了不同Kernel Size的GCN和普通Conv的对比实验。
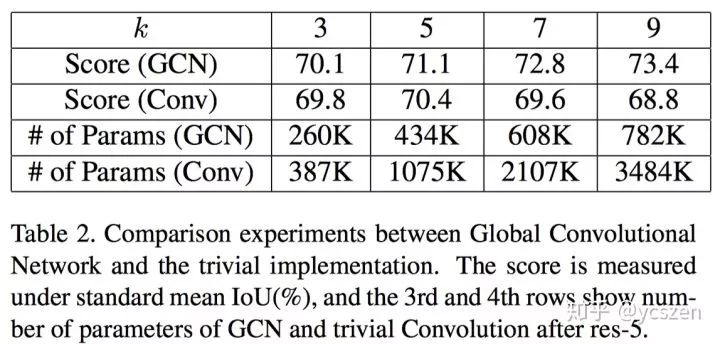
通过实验结果可知,随着Kernel Size的增加,普通Conv的参数量远大于GCN,但是GCN的性能却持续地优于普通Conv。
GCN使用Large Kernel Size增大了感受野,是否可以通过堆叠多个Small Kernel Size的 Conv来替代?
文章为此设计了实验对比两者的结果。
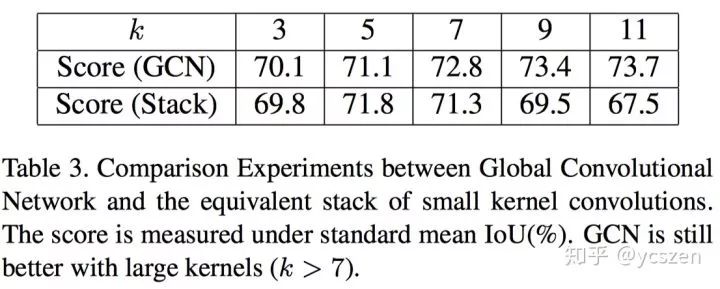
可以看到GCN依然优于普通Conv的堆叠,尤其是在较大Kernel Size的情况下。笔者认为这是一个很有价值的实验,可以启发我们去思考关于网络感受野的问题。我们以往认为,通过堆叠多个小核Conv可以达到和大核Conv一样的感受野,同时计算量还更少。最常见的应用比如VGG-Net。但是,实际上并非如此。
随着网络深度的提升,理论上网络的感受野大多可以直接覆盖全图,但是实际有效感受野却远小于此。笔者的理解是对同一个Feature Map进行卷积,边缘区域进行计算的次数会小于中心区域,所以随着Conv的不断堆叠,实际上会导致边缘感受野的衰减,即有效感受野会远小于理论感受野。
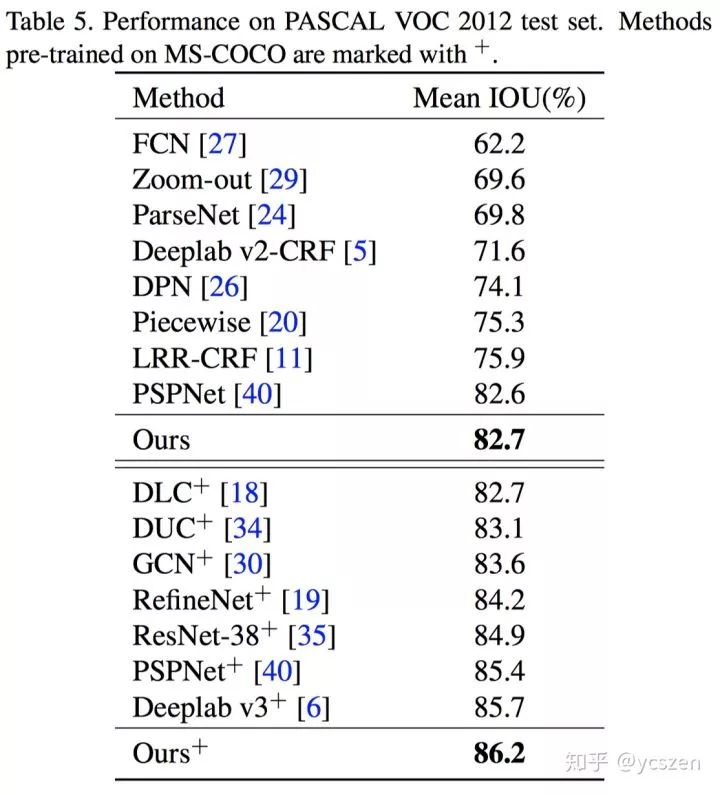
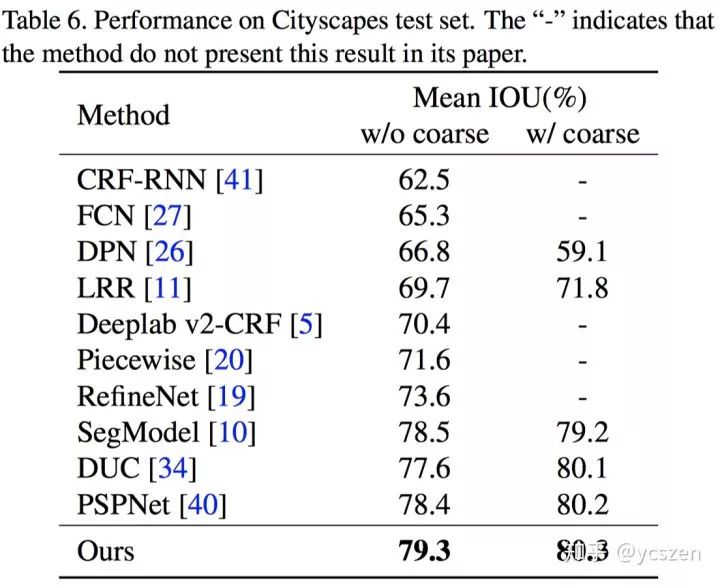
最后文中给出了在PASCAL VOC 2012和Cityscapes上完整的Training Strategy,这在当时还是很良心的,之前的一些Paper对此都语焉不详。具体详细的Training过程请参考原文。
最终GCN在PASCAL VOC 2012和Cityscapes上都取得了不错的结果。
4、PASCAL VOC 2012
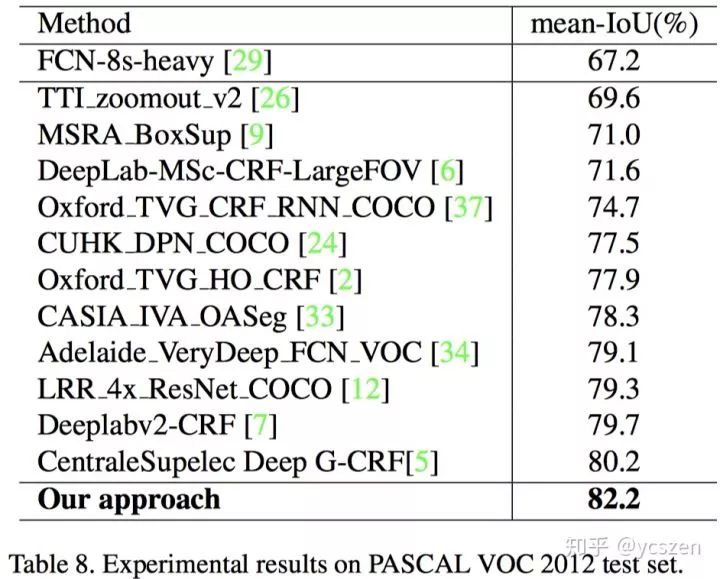
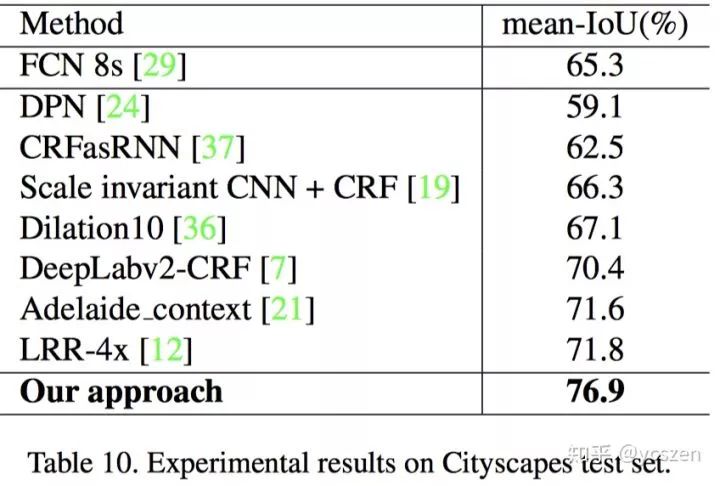
5、Cityscapes
Discriminative Feature Network
接下来出场的是CVPR2018算法Discriminative Feature Network(DFN)。论文Arxiv链接请见:arxiv.org/abs/1804.0933。详细解读请见:CVPR 2018 | 旷视科技Face++提出用于语义分割的判别特征网络DFN(https://zhuanlan.zhihu.com/p/36540674)。
1、Motivation
本文总结了现有语义分割方法仍然有待解决的两类Challenge(如图5所示):
Intra-class Inconsistency(具有相同的语义标签,不同的表观特征的区域)
Inter-class Indistinction(具有不同的语义标签,相似的表观特征的区域)
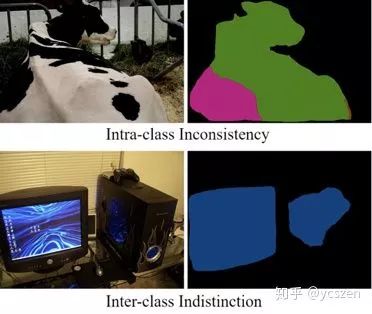
图 5
所以,本文从宏观角度出发重新思考语义分割任务,提出应该将同一类的 Pixel考虑成一个整体,也就需要增强类内一致性,增大类间区分性。总结而言,我们需要更具有判别力的特征。
2、网络结构
本文提出的DFN主要包括两部分:Smooth Network 和 Border Network,如图6所示。
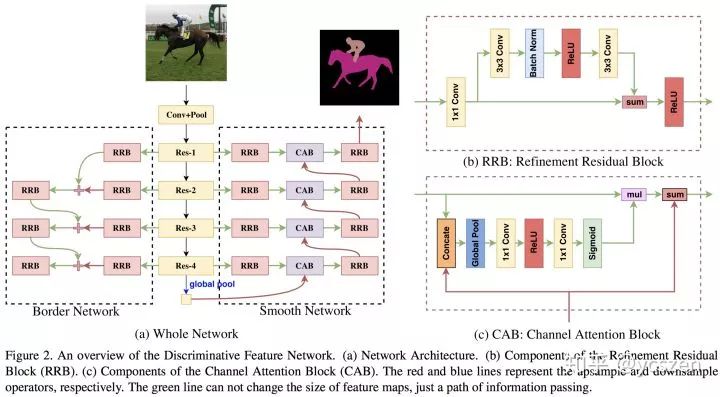
图 6
Smooth Network主要解决类内不一致性问题。文中认为类内不一致性问题主要来自Context的缺乏。进而,我们需要引入Multi-scale Context和Global Context;但是,不同Stage的特征虽然带来了Multi-scale Context,与此同时也带来了不同的判别能力;因此,我们需要对这些具有不同判别力的特征进行筛选,这就诞生了其中核心的设计——Channel Attention Block(CAB)。
CAB利用相邻Stage的特征计算Channel Attention然后对Low-stage的特征进行筛选,如图7所示。因为文中认为,High-stage的特征语义信息更强,更具有判别力。
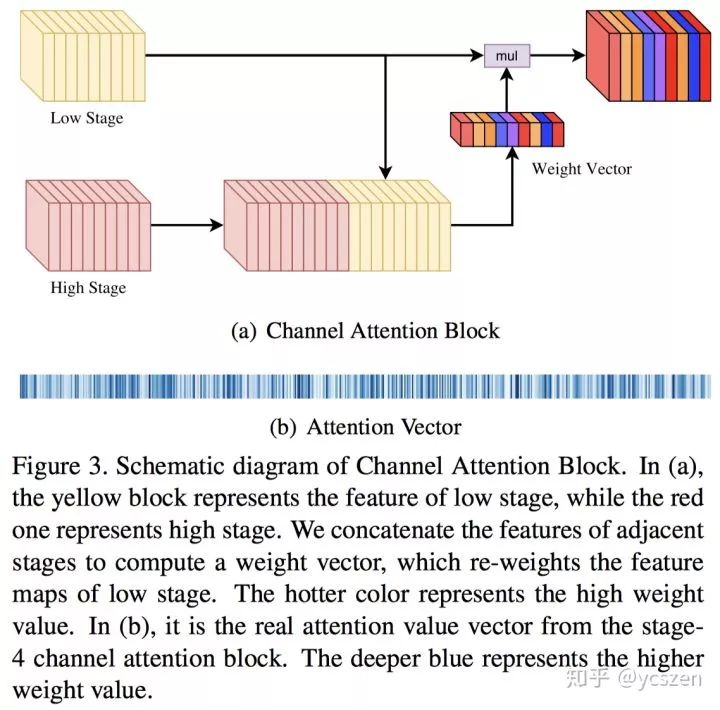
图 7
此外,本文首次在U-shape结构中采用Global Average Pooling,这个设计非常有效。ParseNet首次在语义分割中使用Global Average Pooling提取Global Context,而之后的PSPNet,Deeplab V3 将其在Dilation阵营发扬光大。而本文将其应用U-shape的High-stage,并命名为“V-shape”。我们尝试将其迁移到 Detection中的FPN结构,结果证明同样有效。
Border Network主要解决类间低区分性的问题。文中认为具有相似表观特征的不同区域很容易被网络混淆,尤其是相邻之时。所以,需要增大特征之间的区分性。为此文章显式地引入了Semantic Boundary来引导特征学习。因为Low-stage主要关注一些细节边缘区域,而随着语义的增强,High-stage的特征才是更多关注语义边界,所以 Border Network采用了“反 U-shape”结构。
3、实验
文中进行了丰富的消融实验和可视化分析。
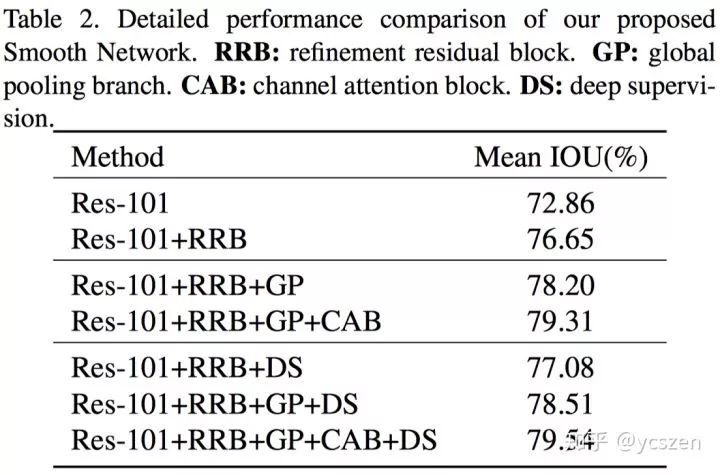
首先是对Smooth Network各部分的消融实验分析。可以看到Smooth Network非常有效,在PASCAL VOC 2012 Validation Set上可以达到Single Scale 79.54% mean IoU。
而通过可视化输出,可以看到Smooth Network确实可以将类内区域变得更加一致,如图8所示。

图 8
同时,文中还对Smooth Network 和 Border Network进行了消融实验分析。

通过可视化Border Network的输出,可以看到Border Network确实可以很好地关注到Semantic Boundary区域,如图9所示。

图 9
最终,DFN在PASCAL VOC 2012和Cityscapes上性能都达到了当时的state-of-the-art。
BiSeNet
最后出场的主角是ECCV 2018算法Bilateral Segmentation Network(BiSeNet)。前面两个算法主要关注Accuracy,探索mean IoU的极限;而BiSeNet关注于做出一个既快又好的实时语义分割算法。最终该算法在Cityscapes上能取得68.4% mean IoU 105 FPS (NVIDIA Titan XP)的好成绩。当然,我们希望这篇工作能抛砖引玉,尝试探讨到底什么架构才更适合Segmentation任务,什么框架才能很好地同时获得充足的Context和丰富的空间信息?论文Arxiv链接请见:arxiv.org/abs/1808.0089。
详细解读请见:ECCV 2018 | 旷视科技提出双向网络BiSeNet:实现实时语义分割(https://zhuanlan.zhihu.com/p/41475332)。
1、Motivation
本文对之前的实时性语义分割算法进行了总结,发现当前主要有三种加速方法:
通过Crop或者Resize限制输入图片进而减少计算量;
减少网络通道数,尤其是Early Stage;
还有像ENet类似的方法直接丢掉最后一个Stage,如图10(a)所示。
这些提速的方法会丢失很多Spatial Details或者牺牲Spatial Capacity,从而导致精度大幅下降。为了弥补空间信息的丢失,有些算法会采用U-shape的方式恢复空间信息。但是,U-shape会降低速度,同时很多丢失的信息并不能简单地通过融合浅层特征来恢复,如图10(b)所示。
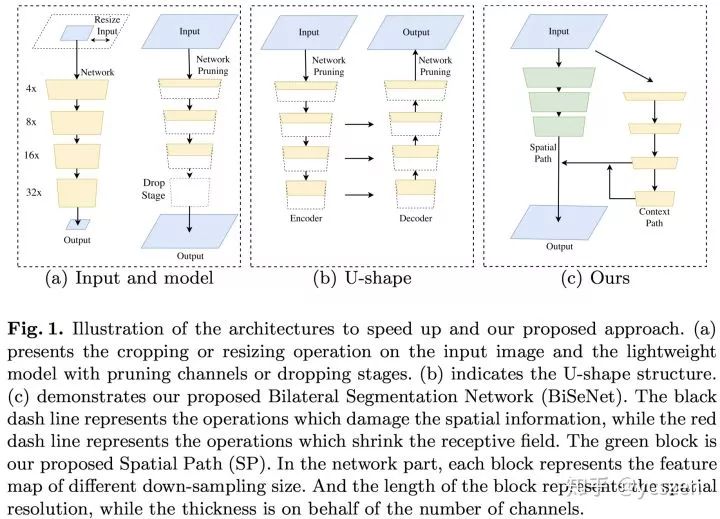
总结而言,实时性语义分割算法中,加速的同时也需要重视空间信息。基于这些观察,本文提出了一种新的解决方案Bilateral Segmentation Network(BiSeNet)。
2、网络结构
BiSeNet区别于U-shape和Dilation结构,尝试一种新的方法同时保持Spatial Context和Spatial Detail 。所以,我们设计了Spatial Path和Context Path两部分。顾名思义,Spatial Path使用较多的Channel、较浅的网络来保留丰富的空间信息生成高分辨率特征;Context Path使用较少的Channel、较深的网络快速downsample来获取充足的Context。基于这两路网络的输出,文中还设计了一个Feature Fusion Module(FFM)来融合两种特征,如图11所示。
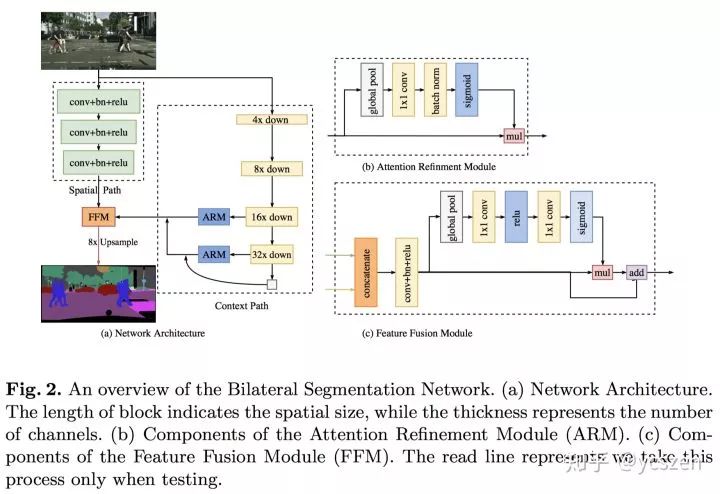
图 11
Spatial Path只包含三个stride = 2 的Conv+BN+Relu,输出特征图的尺寸为原图的1/8。为了访存比考虑,此处并没有设计 Residual结构。
Context Path可以替换成任意的轻量网络,比如Xception,ShuffleNet系列,MobileNet系列。本文主要采用Xception39和ResNet-18进行实验。可以看到,为了准确率考虑,Context Path这边使用了类似U-shape结构的设计。不过,不同于普通的U-shape,此处只结合了最后两个Stage,这样设计的原因主要是考虑速度。此外,和DFN类似,Context Path依然在最后使用了Global Average Pooling来直接获取Global Context。
最后,文章中提到因为两路网络关注的信息不同,属于Different Level的特征,所以文中设计了一个FFM结构来有效融合两路特征。
3、实验
本文从精度和速度两个维度,进行了丰富的分析实验。
首先文中分析了Context Path这边使用不同变体的U-shape结构的速度和精度的对比。
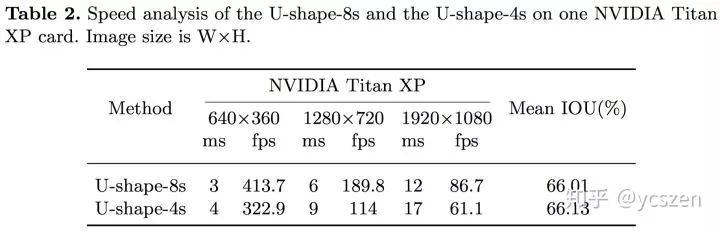
此处,U-shape-8s就是文中所展示的结构,U-shape-4s则是普通的U-shape设计,即融合了更多stage特征。可以看到,U-shape-4s的速度会明显慢于U-shape-8s.
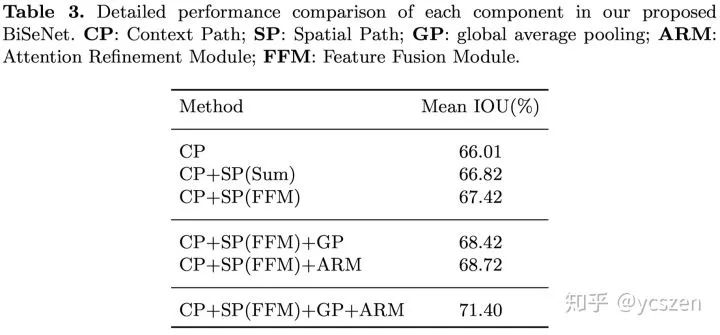
文中还对BiSeNet的各个部分进行了消融分析实验。
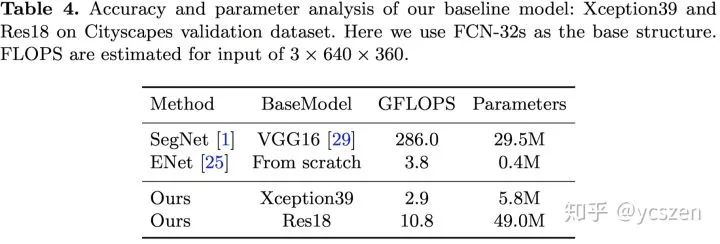
文中还给出了BiSeNet的GFLOPS、参数量等信息,以及在不同硬件平台不同分辨率下的速度对比。
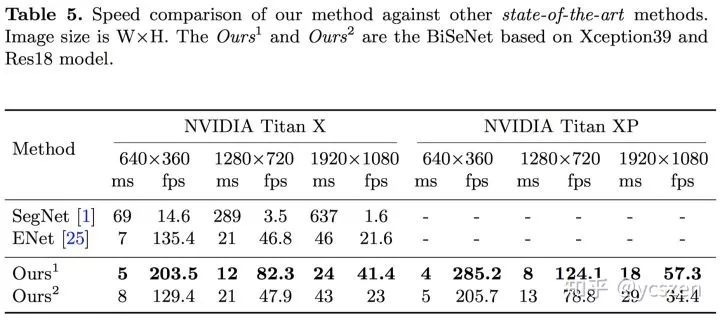
文中给出了BiSeNet分别与实时性算法和非实时性算法比较的结果。
与实时性算法比较:
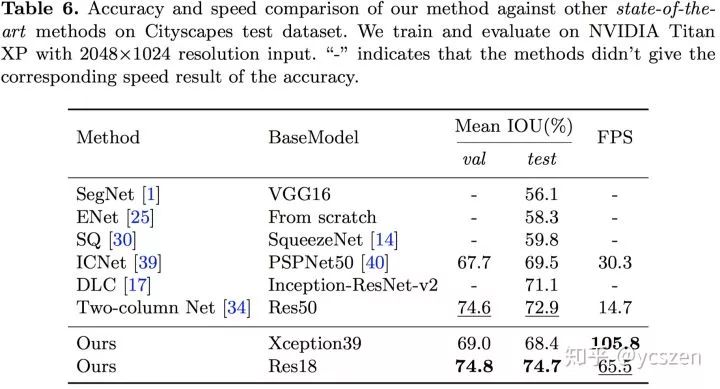
虽然BiSeNet是实时性算法,但是它的精度甚至比一些非实时性算法还高。
与非实时性算法比较:
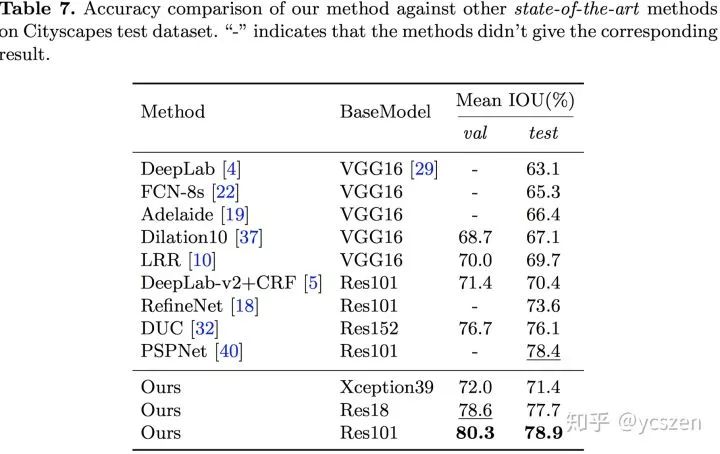
可以看到,BiSeNet是一种很有效的设计。当替换上大模型之后,精度甚至高于 PSPNet等算法。另外,需要注意的是,为了和非实时性算法进行比较,在关注精度这部分实验BiSeNet使用的不同于关注速度部分的Setting,具体细节详见论文。
BiSeNet算法对实时性语义分割算法提出了新的思考,在提升速度的同时也需要关注空间信息。同时,该设计也是一次对Segmentation Backbone的思考,希望设计一个对 Segmentation任务友好的框架,当然现在还存在许多需要改进的地方。此外,该方法不仅仅可应用于实时性语义分割算法,也可应用于其他领域,尤其是在对Spatial Detail和Context同时有需求的情况下。据笔者了解,已有研究将其应用于Potrait Segmentation.
重要的事情
我们的DFN和BiSeNet均已开源,后续将有更多的语义分割算法复现开源出来,欢迎大家Star和Contribute:
https://github.com/ycszen/TorchSeg
欢迎各位同学加入旷视科技Face++ Detection Team,简历可以投递给 Detection组负责人俞刚 (yugang@megvii.com)
Reference
[1] Peng, C., Zhang, X., Yu, G., Luo, G., & Sun, J. (2017). Large kernel matters—improve semantic segmentation by global convolutional network. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on(pp. 1743-1751). IEEE.
[2] Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., & Sang, N. (2018). Learning a Discriminative Feature Network for Semantic Segmentation.arXiv preprint arXiv:1804.09337.
[3] Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., & Sang, N. (2018, September). Bisenet: Bilateral segmentation network for real-time semantic segmentation. InEuropean Conference on Computer Vision(pp. 334-349). Springer, Cham.
[4] Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 3431-3440).
[5] Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention(pp. 234-241). Springer, Cham.
解读者介绍
余昌黔,华中科技大学自动化系在读博士,旷视科技研究院算法实习生,语义分割算法DFN、BiSeNet第一作者,研究方向涵盖语义分割、全景分割、快速分割、视频分割等,并在上述方向有着长期深入的研究;2018年,参加计算机视觉顶会ECCV挑战赛 COCO+Mapillary,分获全景分割(Panoptic Segmentation)两项冠军,并受邀作现场口头报告。
个人网页:http://changqianyu.me/
@ 知乎Face++ Detection组专栏
版权声明
本文版权归《知乎Face++ Detection组专栏》,转载请自行联系。


点击下方阅读原文了解课程详情
历史文章推荐:
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
SFFAI分享 | 曹杰:Rotating is Believing
SFFAI分享 | 黄怀波 :自省变分自编码器理论及其在图像生成上的应用
AI综述专栏 | 深度神经网络加速与压缩
SFFAI分享 | 田正坤 :Seq2Seq模型在语音识别中的应用
SFFAI 分享 | 王克欣 : 详解记忆增强神经网络
SFFAI报告 | 常建龙 :深度卷积网络中的卷积算子研究进展
点击下方阅读原文了解课程详情↓↓
若您觉得此篇推文不错,麻烦点点好看↓↓