从 Linux 源码看 socket 的 close
(点击上方公众号,可快速关注)
作者:无毁的湖光-Al
my.oschina.net/alchemystar/blog/1821680
笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情。上篇博客讲了socket的阻塞和非阻塞,这篇就开始谈一谈socket的close(以tcp为例且基于linux-2.6.24内核版本)
TCP关闭状态转移图
众所周知,TCP的close过程是四次挥手,状态机的变迁也逃不出TCP状态转移图,如下图所示:
tcp的关闭主要分主动关闭、被动关闭以及同时关闭(特殊情况,不做描述)

主动关闭
close(fd)的过程
以C语言为例,在我们关闭socket的时候,会使用close(fd)函数:
int socket_fd;
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
...
// 此处通过文件描述符关闭对应的socket
close(socket_fd)
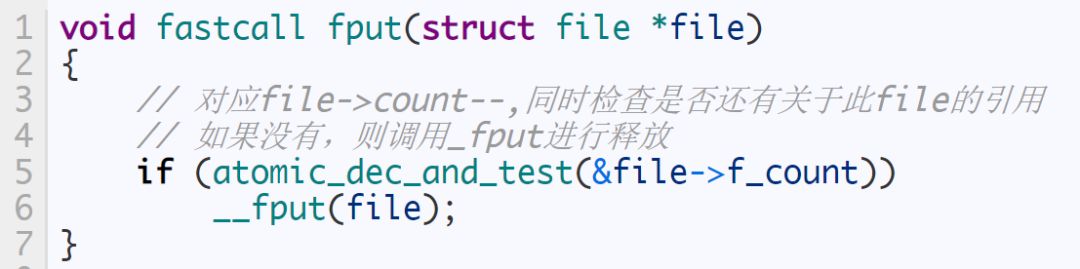
asmlinkage long sys_close(unsigned int fd)
{
// 清除(close_on_exec即退出进程时)的位图标记
FD_CLR(fd, fdt->close_on_exec);
// 释放文件描述符
// 将fdt->open_fds即打开的fd位图中对应的位清除
// 再将fd挂入下一个可使用的fd以便复用
__put_unused_fd(files, fd);
// 调用file_pointer的close方法真正清除
retval = filp_close(filp, files);
}

同一个file(socket)有多个引用的情况很常见,例如下面的例子:
所以在多进程的socket服务器编写过程中,父进程也需要close(fd)一次,以免socket无法最终关闭

然后就是_fput函数了:

由于我们讨论的是socket的close,所以,我们现在探查下file->f_op->release在socket情况下的实现:
f_op->release的赋值
我们跟踪创建socket的代码,即

static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
......
// 我们在这里只考虑sock_close
.release = sock_close,
......
};


即(在这里我们仅考虑tcp,即sk_prot=tcp_prot):

关于fd与socket的关系如下图所示:
上图中红色线标注的是close(fd)的调用链

tcp_close

四次挥手
现在就是我们的四次挥手环节了,其中上半段的两次挥手下图所示:
首先,在tcp_close_state(sk)中已经将状态设置为fin_wait1,并调用tcp_send_fin

void tcp_send_fin(struct sock *sk)
{
......
// 这边设置flags为ack和fin
TCP_SKB_CB(skb)->flags = (TCPCB_FLAG_ACK | TCPCB_FLAG_FIN);
......
// 发送fin包,同时关闭nagle
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_OFF);
}
net.ipv4.tcp_fin_timeout
/sbin/sysctl -w net.ipv4.tcp_fin_timeout=30
如下图所示:
有这样一步的原因是防止对端由于种种原因始终没有发送fin,防止一直处于FIN_WAIT2状态。

接着在FIN_WAIT2状态等待对端的FIN,完成后面两次挥手:
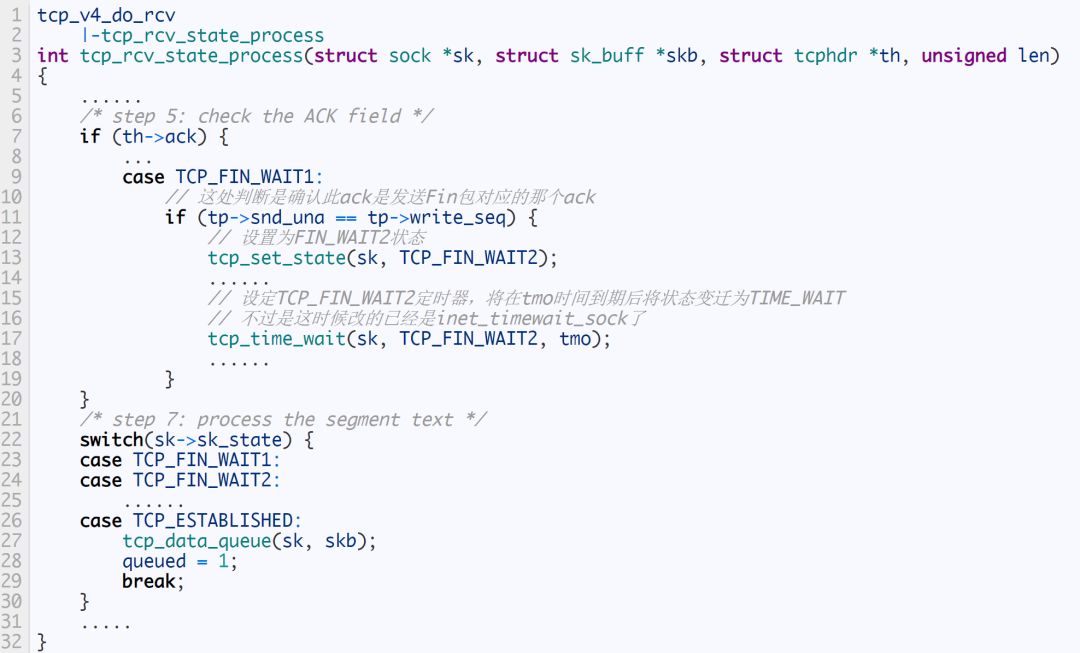
由Step1和Step2将状态置为了FIN_WAIT_2,然后接收到对端发送的FIN之后,将会将状态设置为time_wait,如下代码所示:


void tcp_time_wait(struct sock *sk, int state, int timeo)
{
// 建立inet_timewait_sock
tw = inet_twsk_alloc(sk, state);
// 放到bucket的具体位置等待定时器删除
inet_twsk_schedule(tw, &tcp_death_row, time,TCP_TIMEWAIT_LEN);
// 设置sk状态为TCP_CLOSE,然后回收sk资源
tcp_done(sk);
}
具体的定时器操作函数为inet_twdr_twcal_tick,这边就不做描述了
被动关闭
close_wait
在tcp的socket时候,如果是established状态,接收到了对端的FIN,则是被动关闭状态,会进入close_wait状态,如下图Step1所示:
具体代码如下所示:



这边有意思的点是,收到对端的fin之后并不会立即发送ack告知对端收到了,而是等有数据携带一块发送,或者等携带重传定时器到期后发送ack。
如果对端关闭了,应用端在read的时候得到的返回值是0,此时就应该手动调用close去关闭连接
if(recv(sockfd, buf, MAXLINE,0) == 0){
close(sockfd)
}
我们看下recv是怎么处理fin包,从而返回0的,上一篇博客可知,recv最后调用tcp_rcvmsg,由于比较复杂,我们分两段来看:
tcp_recvmsg第一段


我们看下tcp_recmsg的第二段:

由上面代码可知,一旦当前skb读完了而且携带有fin标识,则不管有没有读到用户期望的字节数量都会返回已读到的字节数。下一次再读取的时候则在刚才描述的tcp_rcvmsg上半段直接不读取任何数据再跳转到found_fin_ok并返回0。这样应用就能感知到对端已经关闭了。 如下图所示:

last_ack
应用层在发现对端关闭之后已经是close_wait状态,这时候再调用close的话,会将状态改为last_ack状态,并发送本端的fin,如下代码所示:


上述代码就是被动关闭端的后两次挥手了,如下图所示:

出现大量close_wait的情况
linux中出现大量close_wait的情况一般是应用在检测到对端fin时没有及时close当前连接。有一种可能如下图所示:
当出现这种情况,通常是minIdle之类参数的配置不对(如果连接池有定时收缩连接功能的话)。给连接池加上心跳也可以解决这种问题。

如果应用close的时间过晚,对端已经将连接给销毁。则应用发送给fin给对端,对端会由于找不到对应的连接而发送一个RST(Reset)报文。
操作系统何时回收close_wait
如果应用迟迟没有调用close_wait,那么操作系统有没有一个回收机制呢,答案是有的。 tcp本身有一个包活(keep alive)定时器,在(keep alive)定时器超时之后,会强行将此连接关闭。可以设置tcp keep alive的时间
/etc/sysctl.conf
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 7200
默认值如上面所示,设置的很大,7200s后超时,如果想快速回收close_wait可以设置小一点。但最终解决方案还是得从应用程序着手。
关于tcp keepalive包活定时器可见笔者另一篇博客:
https://my.oschina.net/alchemystar/blog/833981
进程关闭时清理socket资源
进程在退出时候(无论kill,kill -9 或是正常退出)都会关闭当前进程中所有的fd(文件描述符)

这样我们又回到了博客伊始的filp_close函数,对每一个是socket的fd发送send_fin
Java GC时清理socket资源
Java的socket最终关联到AbstractPlainSocketImpl,且其重写了object的finalize方法
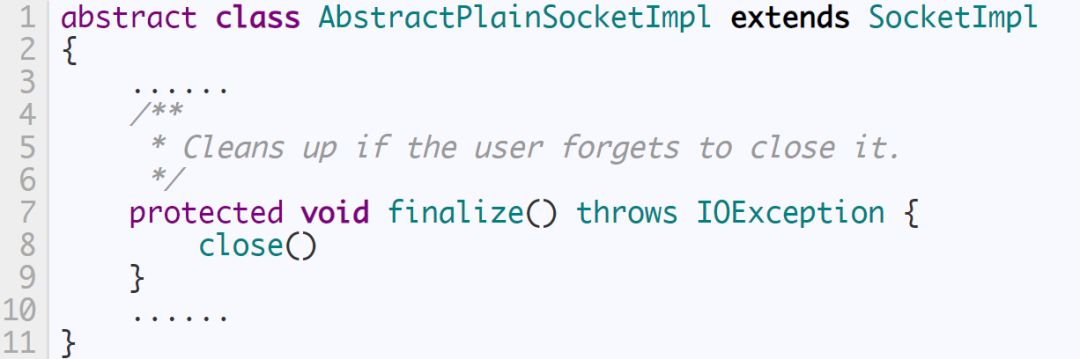
所以Java会在GC时刻会关闭没有被引用的socket,但是切记不要寄希望于Java的GC,因为GC时刻并不是以未引用的socket数量来判断的,所以有可能泄露了一堆socket,但仍旧没有触发GC。
总结
linux内核源代码博大精深,阅读其代码很费周折。之前读《TCP/IP详解卷二》的时候由于有先辈引导和梳理,所以看书中所使用的BSD源码并不觉得十分费劲。直到现在自己带着问题独立看linux源码的时候,尽管有之前的基础,仍旧被其中的各种细节所迷惑。希望笔者这篇文章能帮助到阅读linux网络协议栈代码的人。
【关于投稿】
如果大家有原创好文投稿,请直接给公号发送留言。
① 留言格式:
【投稿】+《 文章标题》+ 文章链接
② 示例:
【投稿】《不要自称是程序员,我十多年的 IT 职场总结》:http://blog.jobbole.com/94148/
③ 最后请附上您的个人简介哈~
看完本文有收获?请分享给更多人
关注「Linux 爱好者」,提升Linux技能






