神经图灵机深度讲解:从图灵机基本概念到可微分神经计算机
选自Talla Blog
作者:Daniel Shank
机器之心编译
参与:马亚雄、吴攀
本文作者为 Talla 公司的高级数据科学家 Daniel Shank。他最近在旧金山举办的机器学习会议上发表了关于神经图灵机的报告。以下是报告视频和讲稿。

嗨,大家好,我是 Talla 公司的高级数据科学家 Daniel Shank,今天我要谈谈一个新的振奋人心的机器学习架构,它被称为神经图灵机(Neutral Turing Machine/NTM)。

首先,我要对这个架构做一个总体的概述,即这个架构是什么?然后我会开始讨论为何说这个架构是重要的,以及它是如何与未来的机器学习相关的,再然后,我会谈为什么我们不能马上在每个地方用到这些东西。例如,假如它非常有作用,那为何我们不将它立即用在产品中。最后我会讨论最近发表在 Nature 上的神经图灵机(Neutral Machine)的论文以及它后续的架构,并且我会展示对这个模型的一些有趣的扩展。

为什么我们要关心神经图灵机?为了解释神经图灵机为何如此重要,我们必须实实在在解释一下普通的图灵机(Turing machine)是什么。

图灵机就是一种简单的计算机模型。正如现代计算机一样,其思想中也包含了一个外部存储器和某种处理器。本质上,图灵机包含上面写有指令的磁带和能够沿着磁带读取的设备。根据从磁带上读取到的指令,计算机能够决定在磁带上不同的方向上移动以写入或者擦除新符号等等。
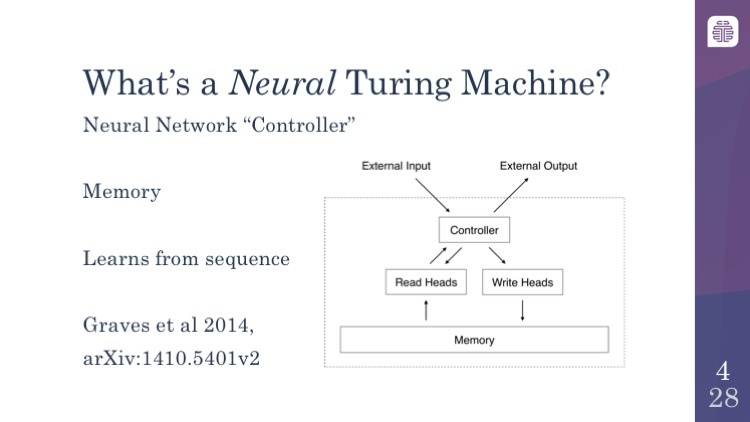
那什么又是神经图灵机(Neural Turing Machine)呢?简而言之,神经图灵机就是一种神经网络,但是它从图灵机中获得灵感来尝试执行一些计算机可以解决得很好而机器学习模型并不能很好地解决的任务。本质上,它包括一个神经网络控制器(controller)、读取磁带设备的模拟器或处理器,如果你愿意的话,还可以加上外部存储或记忆(memory)。它在所有读取到的输入上都是持续的。就像长短期记忆(LSTM)网络或者其他相关的模型一样,它是一个循环神经网络(recurrent neural network)。这意味着,像我们大多数人熟悉的一样,它读取类似变量的输入,但是,神经图灵机和图灵机也有不同之处:除了有一个记忆/内存之外,神经图灵机也可以接受一连串连续的输入并提供输出。

这里的关键思想是神经图灵机基本上就是可微分的图灵机,这是很重要的,因为我们每天在计算机上做的算法和事情对计算机来说是非常困难的,原因是计算机的计算是绝对的。要么是 0 要么是 1。计算机在「非此即彼」的逻辑或者整数中运作。然而大多数的神经网络和机器学习实际上不是这样的。它们使用实数。它们使用更加平滑的曲线,使得它们更加容易训练,这意味着,在看到它们的输出时,你可以轻易地通过输出追踪回去调整参数以得到希望的输出。当计算机 CPU 尽是诸如异或门(XOR)和与门(AND)等跳变函数时,这是非常难以实现的。神经图灵机采用了基本的图灵机中的所有功能找到了平滑的模拟函数。因此,比如在磁带上,神经图灵机可以决定稍微向左或者向右移动,而不是单纯的向左或者向右,这可以让你完成一些了不起的事情。

在神经图灵机能够执行的事情中,我们有一些激动人心的例子,当然也有一些不那么令人激动的......

但是缺点是它只能够学习简单的算法。例如接受输入并复制它。这看起来是极其平常的,但是对当前的神经网络来说,这实际上是一件非常困难的事情,因为神经网络需要学习出一个算法才能把这个工作做得足够好。神经图灵机能够接受输入和输出,并且学习得到能够从输入映射到输出的算法。这确实相当令人兴奋,因为这本质上是在尝试着取代程序员。虽然我们还未实现,但是这的确很酷。这意味着一旦习得了算法,它们可以接受输入并且外推到基于该算法的任何变量输出。接下来你会立即明白这为什么很酷。因为它们还非常擅长语言建模(language modeling)。如果你不知道什么是语言建模,你可以思考一下自动完成(autocomplete)。语言建模就是猜测一个单词在句子或者文档语境中的意思。神经图灵机也能够在 Facebook 的 bAbI 数据集上表现得很有前景,bAbI 数据集是被设计用来鼓励研究者们提升神经网络的通用认知推理能力的。

在复制/重复任务上的泛化
这是一个神经图灵机执行复制/重复任务的例子。它已经学会了接受相对短的序列,并重复几次。正如你可以在上图看到的一样,开始的时候它犯错。但是最终看起来相当好,图中上边的是目标,下边的是输出。
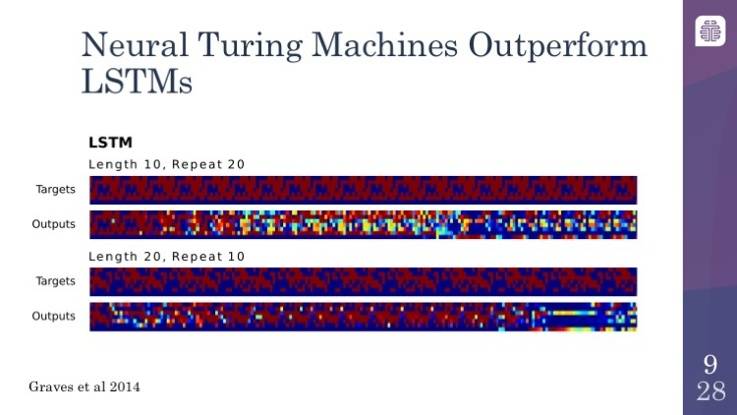
神经图灵机的表现超越了长短时记忆网络
相反,你拿这个例子与长短时记忆网络(LSTM)相比,LSTM 实际上是一种非常强大的神经网络模型。它们会很快就倾向于崩溃。出现这种情况的原因是,LSTM 确实是在学习一些东西,但是它们并不是在学习算法。LSTM 试图一次解决整个问题,所以它们意识不到前两次所做的事情就是它们之后应该做的。
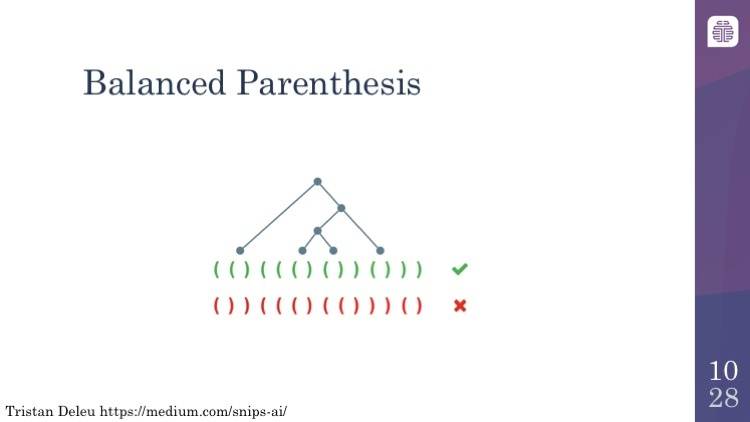
平衡括号表达式
在神经图灵机可以做到的事中,一个有趣的例子是它们可以识别平衡的括号。这个是特别有趣的,因为这涉及到的使用了栈(stack)的算法,所以本质上你可以随着左括号的进入去跟踪它们,然后尝试去匹配与之对应的右括号。这件事神经网络可以做,但是会以更加统计的方式完成,而神经图灵机实际上可以像人类程序员一样去完成这个任务。

好了,现在我们谈一下 bAbI 数据集以及为什么我们如此关注它。bAbI 数据集本质上是一系列后面带有问题的故事,而且所有的问题都被设计成需要某种形式的推理能力才能回答。我这里有一个简单的例子——使用位置来进行推理。这里的关键点是,如果你问某人在哪里,实际上问的是他们最后去了哪里。这看起来非常明显,当涉及到人物捡起东西或者行走时,这个问题实际上会变得有些复杂。故事也会涉及到关于物体相对尺寸的实际推理。基本上,这件事情背后的基本理念永远是,一个在所有这种任务中表现良好的系统,接近一个更加通用的知识推理系统。
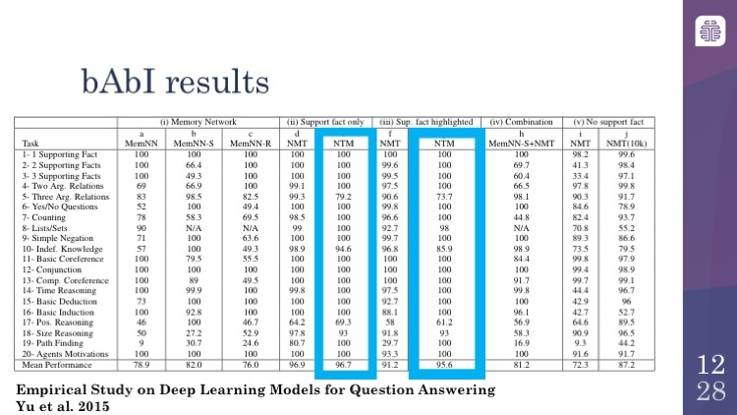
bAbI 数据集上的结果
这里仅仅是一些基于 bAbI 数据集的结果。注意,实际上 bAbI 数据集是训练集。就像我之前给你展示的,给定其中的每一个故事,你会看到的是,训练集实际上提供了一个提示,这涉及到实际故事中的什么内容对回答问题是重要的。事实证明,导致这个问题非常困难的原因,不仅是你必须做出逻辑推理,你还必须意识到什么东西是相关的。你会看到,这两者之间是存在竞争的。bAbI 数据集的许多子任务或者子部分都达到了超过 95% 的准确率,这作为系统通过给定领域的基准测试。

挑战和建议
神经图灵机可以做这些炫酷的事情:它们可以学会算法,它们可以理解一个小故事的意思,但是为什么我们不能一直用这些东西呢?嗯,它们的结构是如此地有趣,但也伴随着一些问题。

问题:
架构依赖;
大量的参数;
并不能从 GPU 加速中受益;
难以训练
首先,一旦你指定了一般的架构,在实现它的时候仍然需要做出很多决策。例如,对于每一个给定的输入或输出单元,在给定的时间步长下你能够读取或者写入多少向量?这些都很重要,它不仅仅是提高你的识别准确率的问题。如果你不能正确地做到这些,那它很有可能永远都得不到一个合理的结果。参数的数量是极其大的,这会让你的 RAM 压力很大。这是机器学习中的一个重要部分,它们并不会受益于 GPU 加速,虽然正如我们所见,GPU 加速是机器学习中的重要一部分。原因是这是序列式的,很难并行化,因为它们当下所做的都是基于之前的输入。很难将这些部分分解成容易的并行计算。它是很难训练的,这一点和我刚才提到的所有问题都有所不同。

难以训练:
数值不稳定性;
很难使用记忆(memory);
需要很好的优化;
实际中很难使用
它们往往具有很强的数值不稳定性。部分原因是实际中给它们设计的任务。因为它们是在学习算法,所以它们往往不会犯小错误,它们倾向于犯大错误。如果你在算法中犯了一个错误,那么所有的输出结果都会是不正确的。这意味着,当你训练它们的时候,它们总是很难找到需要的算法。如果喂给大量的数据,给予足够的时间,大多数神经网络都会得到一些结果。而神经图灵机经常会卡住。大家知道,它们经常一遍又一遍地一味地产生那些经常重复的值。这是因为使用记忆是很困难的。他们不仅必须学会记住以后解决问题所需要的东西,还必须记住不要意外地忘记它,这一层要求额外地增加了复杂性。因此,为了解决这个问题,你最终会用一些循环神经网络通用的巧妙的优化方法。但是为了让这些方法起作用,你需要想尽一切办法。所有的这些问题都让神经图灵机很难用在日常应用中。

有很多应对数学不稳定性的方法。非常通用的一个方法就是梯度裁剪(gradient clipping),尤其是在使用 LSTM 的时候。梯度裁剪的本质就是,无论我们怎么认为一个坏的结果由初始参数导致的,我们都要限制一下其改变的程度。这可以帮助我们避免在任何时候当我们得到坏结果的时候就去擦除一切参数。当机器犯错时,我们不能完全丢掉已经学到的东西。

损失裁剪本质上是梯度裁剪的扩展。相同的基本思想就是,神经图灵机会非常远离它们的目标。就像损失函数的总值一样,给我们能够改变的参数总和设置一个上限。我们经常结合这两种方法。基本上,我们需要把很多有效果的更改绑定到一个有不同含义的参数上面。

好了,实际上另一个有趣的方向是 Graves 的 RMSprop。RMSprop 实际上是常见的反向传播算法的一个扩展,这个大家可能比较熟悉。反向传播是如今训练所有的神经网络的关键。RMSprop 是一个用来平滑梯度的系统。所以,在有序的数据点中,本质上你所做的就是对任何给定参数的效果取一个平均值。Graves 的 RMSprop 实际上是这个方法的一个变体。它本质上是做一个运行估计的方差,而非仅仅取一个平均值。它标准化并且保证损失的极值在实际中不会衰减太多,或者不会把参数减小那么多。这是一个非常聪明的方法,它也非常有趣,因为为了解决这个问题,人们不得不通读 Alex Graves 的一些论文。如果你仅仅实现普通的 RMSprop,它往往效果不佳。所幸,还有一些可以替代的优化方法。

说实在的,尽管为了找出哪一个方法能够帮助你,你常常必须尝试多个算法,但是 Adam 优化器确实是一个常用的优化方法,并且它还支持了如今的大多数机器学习框架。像 Graves 的 RMSprop 方法一样,它基本上也是平滑梯度。这个方法有些复杂,所以我不会在这里讨论它是如何起作用的。但是一般而言,它确实是一个不错的备选方法。

另一件值得注意的事就是值的初始化,尤其是记忆。一些人确实利用了由快速训练神经图灵机所带来的记忆偏差。但是一般来说,这实际上是他们的架构有问题的特点。因为初始记忆会让以后的计算产生很大的偏差,所以如果你以一组坏的参数开始的话,它可以彻底毁掉整个模型。就像很多其他这种技术一样,它们有助于提升通用神经网络的性能。但是在这种情况下,如果你做得不正确,它很可能不会收敛,你将不会得到一个合理的结果,所以为了合理地优化,你必须频繁地尝试不同的参数值作为初始点。

另外一个方法,也是比较有趣的,那就是 curriculum learning,就是在开始的时候喂一些简单的数据。你从序列开始,让它学习复制一些东西到某一长度,比如说 5。当它可以把这个做得很好时,你再将长度增加到 10,然后再某一点,你达到了新的长度,比如说 20,然后在某一点你相当自信你可以将模型泛化,就像我们之前看到的,将复制序列的长度增大到 100 或者更大。

现在我要继续讨论最近的扩展。非常令人兴奋,如果我没有记错的话,它是在几个星期之前出现在 Nature 上的。它以一些有趣的方式扩展了神经图灵机,并且帮助解决了一些问题。

可微分神经计算机(参见机器之心文章《DeepMind 深度解读 Nature 论文:可微神经计算机》)或者最近的一些模型本质上就是经过一些修改的神经图灵机。从某种程度来说,它们放弃了基于索引移动的寻址方式。我之前一直在讲沿着记忆或者磁带的移动。它们不再这样做;它们尝试基于它们看到的东西直接在记忆中搜索给定的向量。它们还有分配记忆和释放记忆的能力,如果你曾经使用过某种低水平的编程语言的话,你就会理解这个。以同样的方式,很难跟踪记忆区域中的内容,所以你不会在编程中犯错误,这样很容易将记忆中的某个区域标记为禁止访问,因此你不会在以后意外地删除它们,这有助于优化。它们也有那种将序列输入序列进行本地记忆地能力。当神经图灵机学习复制的时候,它们学习将所有地输入按顺序写进记忆,并回到记忆地开头将它们读出来这个过程。在这种情况下,从某种程度来说它们拥有了某种形式的时间记忆(temporal memory),在瞬时记忆中它们可以回想起它们所做的上一件事,上一件事的上一件事,以此类推,这意味着它们可以遍历由它们需要做的事组成地一个链表。
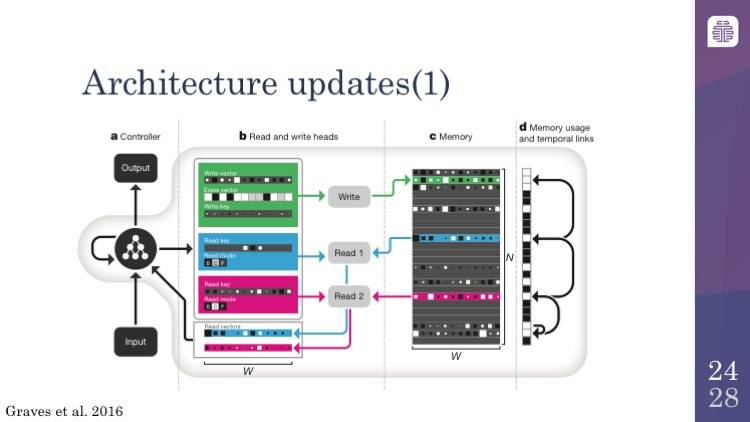
这是可微分神经计算机体系结构的总结。你们看到的左边的图表代表的是输入和输出变量的长度,然后读头和写头允许计算机在记忆区进行存取。这里你可以看到它一次读入整个向量并在第 6 区域写入。就像我之前描述过的,记忆区域在右边有一个附加的暂时链接。如果你追踪这些箭头,你会看到实际上这些箭头就是模型能够回想并重复它最近的输入和输出的方式。

这里我们看到的图片展示的是可微分计算机也在执行复制的任务。你看到的绿色的方块是它写入记忆中的东西,紫色的方块是它从记忆中读出来的内容。通常,当你给它输入一些序列的时候,如果你沿着左边看的话,你所看到的正在发生的事是计算机正在释放某些区域的记忆,因为它需要写入东西,所以这是在分配记忆,底部的方块显示了这个活动。然后,当写入完成之后,输出。然后,它就会说,「做好了,我们可以重新分配这块记忆了」。你就会得到这种交替的模式,「我需要这块记忆。好了,我做好了。我需要这块记忆......」可微分神经计算机确实学会了做这件事,这使事情变得更加容易,让这些事情变得更加有趣。
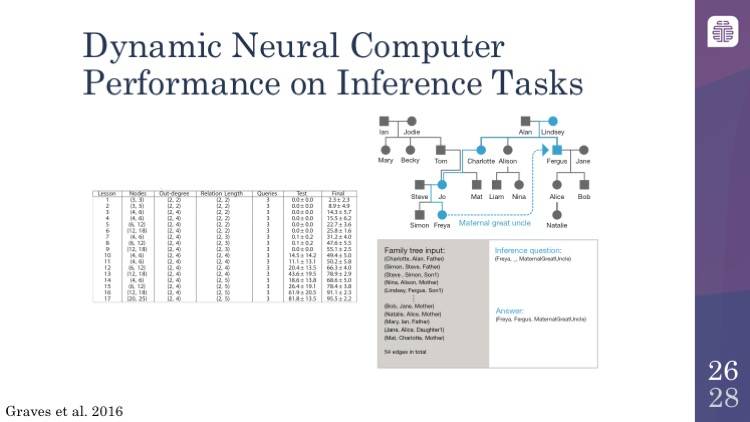
动态神经计算机在推理任务上的性能
我从为见过的让计算机之间显得有些不同的例子就是它们能够做这种逻辑推理的事情,虽然是结合了某种模糊的推理。你在这里看到的是一个家族树(family tree),用这个家族树去训练模型,本质上,「Mary 是 Jodie 的女儿」,或者「Simon 是 Steve 的儿子」。那么,你问计算机:「Freya 和 Fergus 是什么关系?」或者「Freya 和 Fergus 是什么关系?」答案是舅舅,所以它们确实是能够回答这个问题的。如果你去读这篇论文的话,你会发现一些有趣的例子,例如学会找最短路径,横穿伦敦地铁系统的图结构以及类似的东西,这些都是有趣的。我这里没有相关的幻灯片,但是如果你对它很感兴趣,强烈建议你读一下 Nature 上的这篇文章,链接如下:http://www.nature.com/nature/journal/v538/n7626/abs/nature20101.html
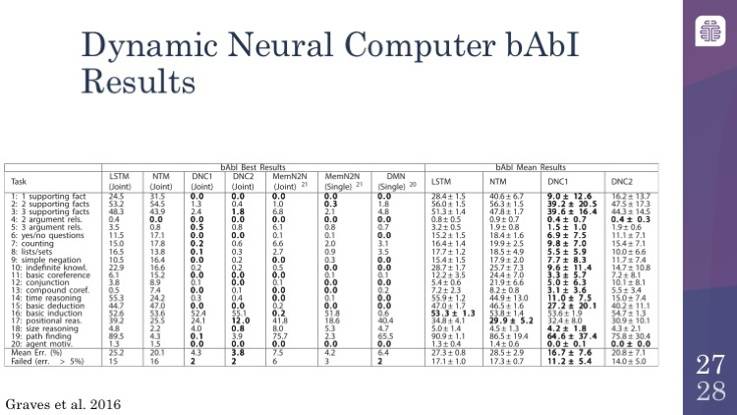
动态神经计算机在 bAbI 数据集上也有良好的表现。bAbI 数据集在过去一年左右有了很大的进步。实际上你会看到,除了少数几个之外,大多数先进的模型都已经通过了 bAbI 数据集,而且做得相当好。你会看到,动态神经计算机(DNC)只在两个领域没有通过,其他的都通过了,而且还和可以 Facebook 的模型相媲美,Facebook 的模型被设计得非常好,因为这些数据集就是它们自己的数据集。这非常令人兴奋,你可以说,只剩下不多的几个领域需要攻克了,这是将神经网络的学习任务向前推进的一大步,而之前我们是没有能力去触及这些任务的。

谢谢大家。这里有一些参考资料;我推荐 Theano、Lasagne 和 Go 的实现。我要推荐列表上的最后一篇文章,这是一种使用更少的内存使这些东西工作的方式,越来越接近在实际产品中应用神经图灵机的要求。

原文链接:http://blog.talla.com/neural-turing-machines-perils-and-promise
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




