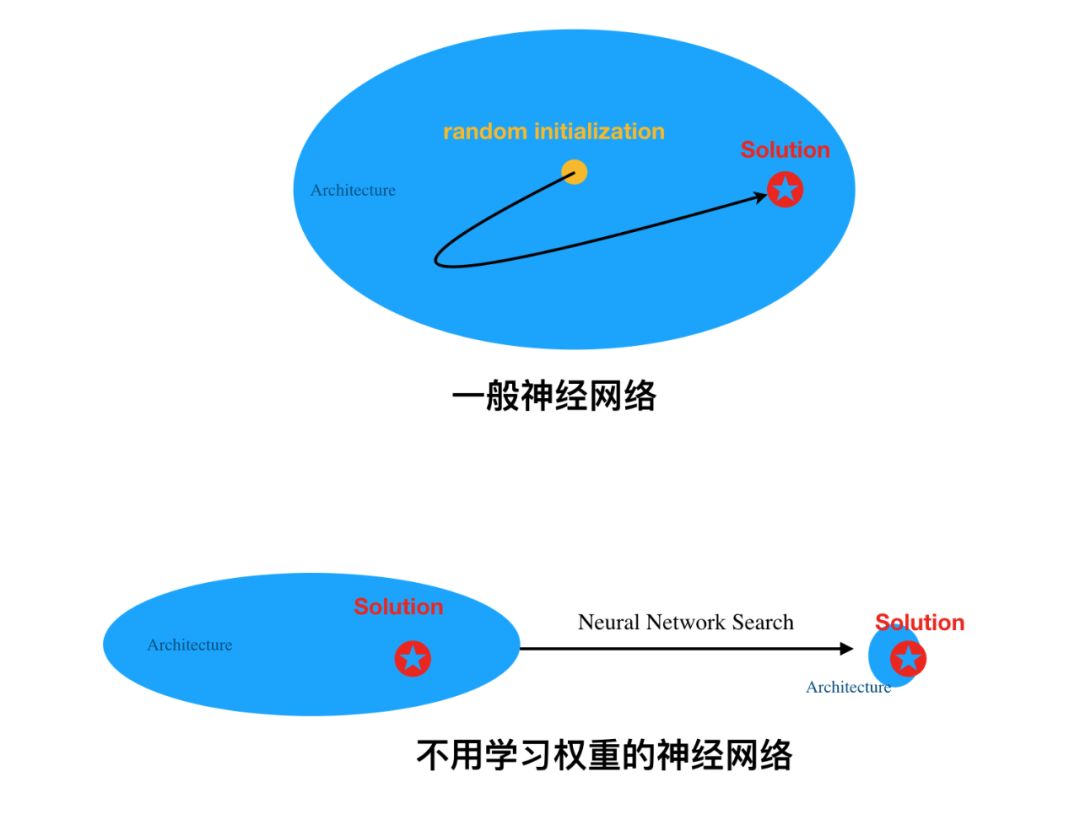
剪枝与学习权重同等重要,Lottery Ticket Hypothesis第一次被理论证明
参与:思
Pruning is All You Need,只要对随机初始化的神经网络做个好剪枝,不怎么训练也能有个好效果。



对于任意深度 l 的神经网络(ReLU 激活函数),它都可以通过搜索深度为 2l 、宽度足够的随机网络,并找到一个 weight-subnetwork 来逼近它。
对于两层神经网络(一个隐藏层),研究者证明它有一个能媲美的 neuron-subnetwork。
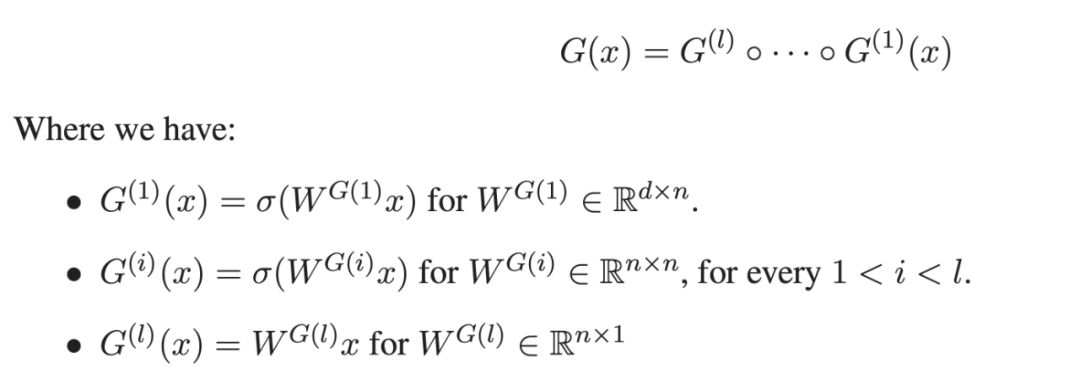

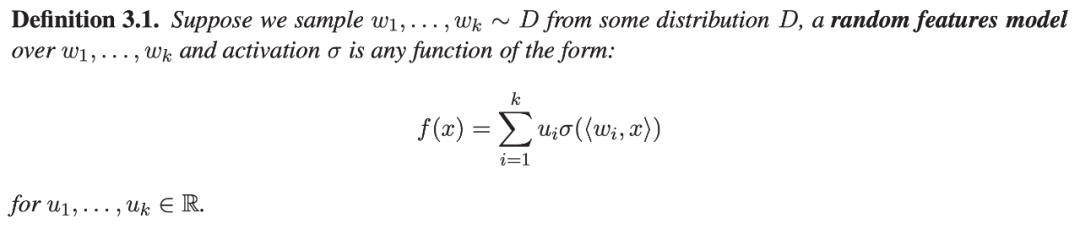
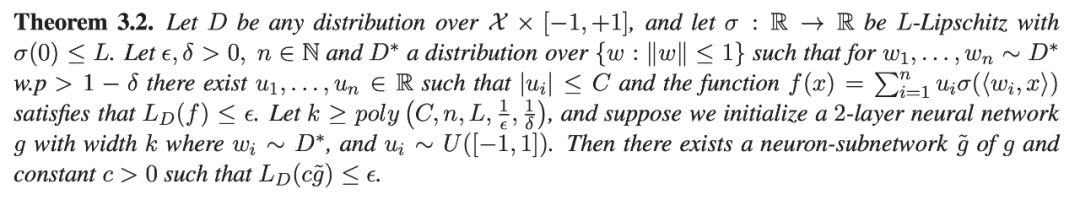
登录查看更多
相关内容

专知会员服务
19+阅读 · 2020年6月29日
专知会员服务
148+阅读 · 2019年12月28日
Arxiv
4+阅读 · 2018年9月23日


相关VIP内容
专知会员服务
19+阅读 · 2020年6月29日
专知会员服务
148+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年9月23日