基于强化学习的自动交易系统研究与发展综述
深度强化学习实验室报道
作者:梁天新
编辑:DeepRL
近年来,强化学习在电子游戏、棋类、决策控制领域取得了巨大进展,也带动着金融交易系统的迅速发展,金融交易问题已经成为强化学习领域的研究热点,特别是股票、外汇和期货等方面具有广泛的应用需求和学术研究意义。本文以金融领域常用的强化学习模型的发展为脉络,对交易系统、自适应算法、交易策略等方面的诸多研究成果进行了综述。最后讨论了强化学习在金融领域应用中存在的困难和挑战,并对今后强化学习交易系统发展趋势进行展望。
1. RRL在金融交易系统中的应用
Moody 等人将循环强化学习算法模型(Recurrent Reinforcement Learning,RRL)应用在单一股票和资产投资组合等领域,测试了日内外汇市场(USD / GBP)、标准普尔500(S&P 500 Index)、美国短期国债等金融资产。以收益率为输入,微分夏普比率为目标函数,在交易成本为5‰的情况下进行实验。RRL 策略获得的回报超过Q 学习(Q-Learning)策略和买入持有策略,并在交易次数上明显小于Q 学习策略。
在交易领域中,最终利润或者基于风险的收益,代表交易模型的回报。通过专家标签和分析一定长度金融时间序列做出交易决策,这种监督方式交易系统存在以下弊端:首先,金融交易获得的回报不是即时的,回报是交易中止时的总回报,这导致每一步决策的回报不明确。这正是强化学习中的临时信用分配和结构信用难题,即“系统获得的奖赏如何分配到每个操作上[5]”;其次,标签数据是基于已知的金融时间序列,忽略了不断变化的市场风格对输入变量有效性的影响,导致交易系统不能及时调整策略。最后,随着交易价格的变化,交易成本也在不断变化,无法实时调整交易成本的模型,即便是预测准确,依然会由于交易成本失控导致交易亏损。实践证明,监督学习方式在金融自动交易系统中应用效果并不理想。
相比监督式的交易系统,Moody 等人提出的RRL 算法是一种在线模式,可以找到随机动态规划问题的近似解[7]。RRL 不需要标记信息,通过行动得到的环境反馈来调整内部参数,增加未来回报的期望值。基于RRL 建立的交易系统通过循环算法解决优化时间信用分配问题和结构信用分配问题[5],RRL 获得的交易利润是路径依赖决策的结果,既包含基于时间的反向传播算法(Back Propagation Through Time,BPTT),也包含在线自适应算法(Adaptive Algorithm)。RRL 既可以应用在单一金融资产交易领域,也可以应用到投资组合管理领域。它在金融领域的应用如图1所示。
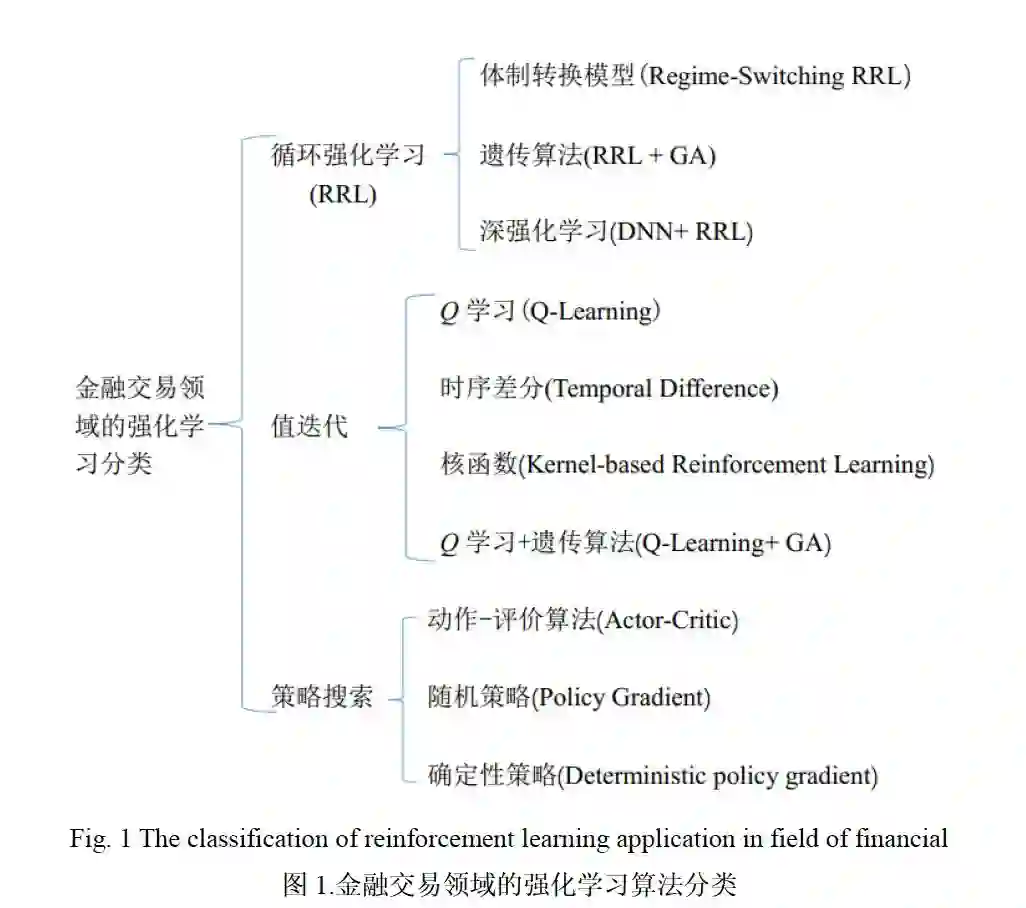
2. RRL模型
Moody 等人提出的RRL 模型把金融时间序列作为输入,以最大化微分夏普比率(Sharp Ratio)为目标函数,设计两类金融领域常见的操作:做空(short)、做多(long)。RRL将动作定义为,代表着在t 时刻的操作(空/多),RRL 单层神经网络的预测模型如公式(1.1)所示:
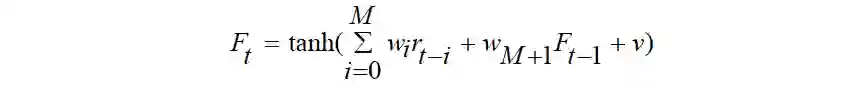
r_t代表收益率,有如下两种表示方法:
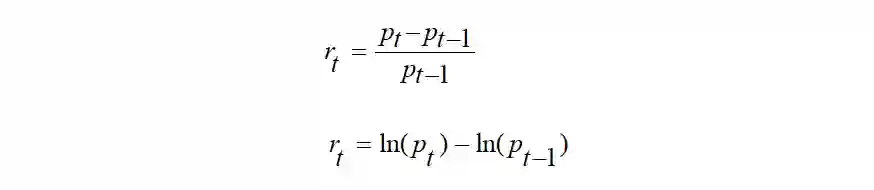
研究中常采用对数收益率,对数收益率比价格差值更容易体现价格的变动,也更容易计算夏普比率、最大回撤率(Max Drawdown) 等风险度量指标。当价格变化幅度
RRL 算法以最大化利润为目标,但通常不使用最高累计利润作为模型表现衡量指标,最高累计利润p_T ,表示为

3. RRL优化方式
RRL 的目标是通过梯度上升的方式在一个循环神经网络中优化权重w_t
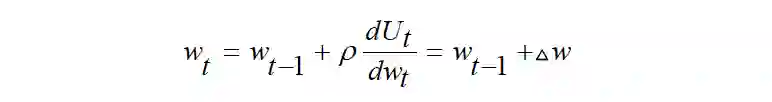

4. 基于RRL 自适应交易系统
自动交易系统架构
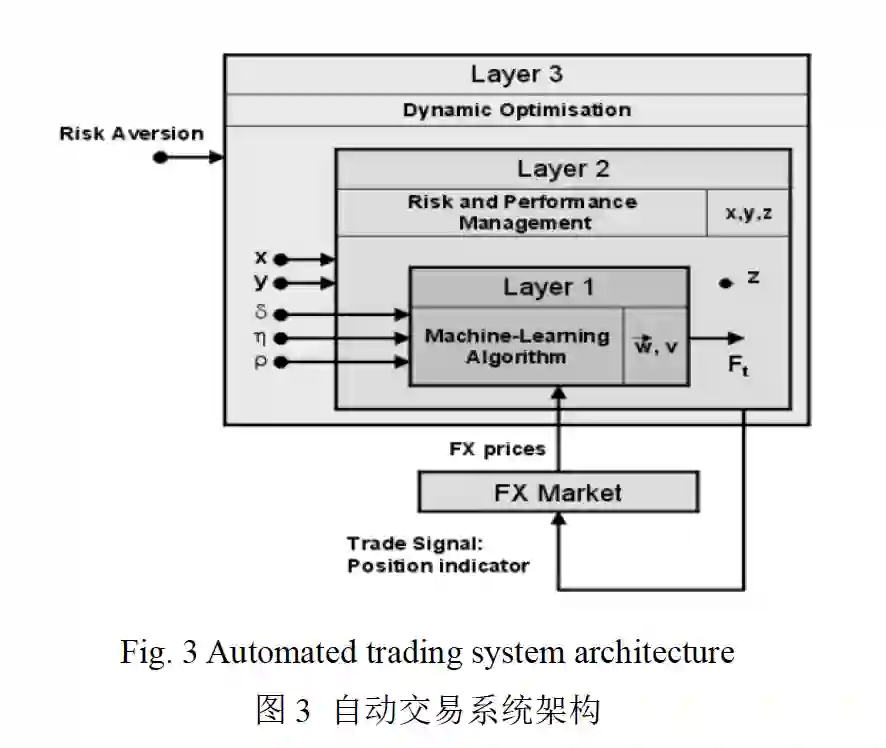
交易系统整体流程如下图所示:

5. 值函数与Q 学习的金融交易系统

6. 结论
本文认为上述研究中仍然存在着亟待解决的问题:
金融市场具有不稳定性,趋势实时变化。从历史的训练数据中学到的知识可能不会在后续测试数据中有良好的效果,这对强化学习模型的适应性提出了更高的要求,不同市场条件下如何选择合适的强化学习模型和深度学习模型仍然是一个悬而未决的问题。
构建基于强化学习的交易软件或系统,通常一种算法不能解决全部问题,针对不同的市场情况,需要设置不同的配置模块。风险层、策略轮动层、自适应层等层次结构的设计至今没有统一解决方案,业界仍然在探索中。
大部分强化学习模型系统都是专攻某一类金融交易,单纯的做多、做空或空仓观望等,投资组合方式也仅是对各类金融资产的权重进行重新分配。但是,如股票中性、期货中性等策略需要对多种资产同时进行复杂的多空对冲操作时,仍缺少充分的研究。
强化学习领域最近提出了确定性策略和蒙特卡罗树搜索结合的算法,并应用于围棋领域,获得了突破。如何将蒙特卡罗树搜索策略应用在交易系统中,值得深入研究。
更多内容请查看原paper《 基于强化学习的自动交易系统研究与发展》
http://www.jos.org.cn/jos/ch/reader/view_abstract.aspx?file_no=5689&flag=1
第37篇:从Paper到Coding, 一览DRL挑战34类游戏
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei的改进
第34篇:DeepMind-102页深度强化学习PPT(2019)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第9期论文:2019-12-4(3篇,1篇NIPS)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)

深度强化学习实验室
算法、框架、资料、前沿信息等
GitHub仓库
https://github.com/NeuronDance/DeepRL
欢迎Fork,Star,Pull Reques



