AI 实践者需要掌握的10大深度学习方法:反向传播、迁移学习、梯度下降……
点击上方“公众号”可以订阅哦!
【导读】本文总结了10个强大的深度学习方法,包括反向传播、随机梯度下降、学习率衰减、Dropout、最大池化、批量归一化、长短时记忆、Skip-gram、连续词袋、迁移学习等,这是AI工程师可以应用于他们的机器学习问题的。
过去10年,人们对机器学习的兴趣激增。几乎每天,你都可以在各种各样的计算机科学课程、行业会议、华尔街日报等等看到有关机器学习的讨论。在所有关于机器学习的讨论中,许多人把机器学习能做的事情和他们希望机器学习做的事情混为一谈。从根本上讲,机器学习是使用算法从原始数据中提取信息,并在某种类型的模型中表示这些信息。我们使用这个模型来推断还没有建模的其他数据。
神经网络是机器学习的一种模型,它们至少有50年历史了。神经网络的基本单元是节点(node),基本上是受哺乳动物大脑中的生物神经元启发。神经元之间的连接也以生物的大脑为模型,这些连接随着时间的推移而发展的方式是为“训练”。
在20世纪80年代中期和90年代初期,许多重要的架构进步都是在神经网络进行的。然而,为了得到好的结果需要大量时间和数据,这阻碍了神经网络的采用,因而人们的兴趣也减少了。在21世纪初,计算能力呈指数级增长,计算技术出现了“寒武纪大爆发”。在这个10年的爆炸式的计算增长中,深度学习成为这个领域的重要的竞争者,赢得了许多重要的机器学习竞赛。直到2017年,这种兴趣也还没有冷却下来;今天,我们看到一说机器学习,就不得不提深度学习。
作者本人也注册了Udacity的“Deep Learning”课程,这门课很好地介绍了深度学习的动机,以及从TensorFlow的复杂和/或大规模的数据集中学习的智能系统的设计。在课程项目中,我使用并开发了用于图像识别的卷积神经网络,用于自然语言处理的嵌入式神经网络,以及使用循环神经网络/长短期记忆的字符级文本生成。
本文中,作者总结了10个强大的深度学习方法,这是AI工程师可以应用于他们的机器学习问题的。首先,下面这张图直观地说明了人工智能、机器学习和深度学习三者之间的关系。
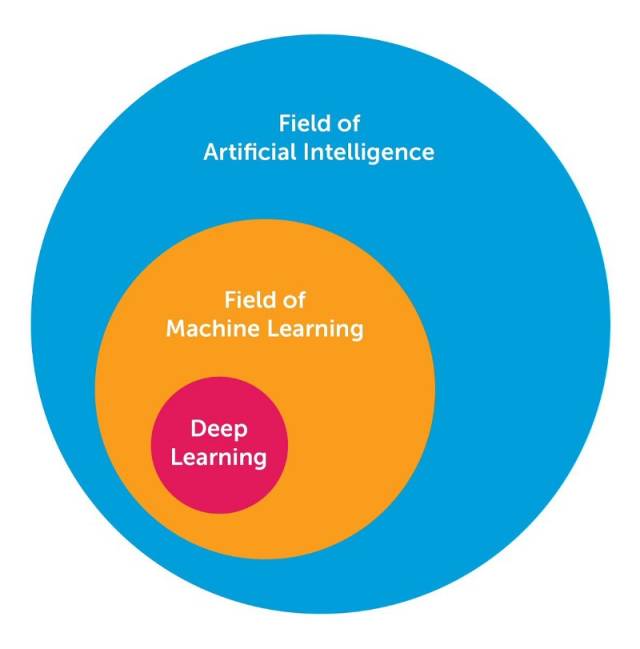
人工智能的领域很广泛,深度学习是机器学习领域的一个子集,机器学习又是人工智能的一个子领域。将深度学习网络与“经典的”前馈式多层网络区分开来的因素如下:
比以前的网络有更多的神经元
更复杂的连接层的方法
用于训练网络的计算机能力的“寒武纪大爆炸”
自动特征提取
这里说的“更多的神经元”时,是指神经元的数量在逐年增加,以表达更复杂的模型。层(layers)也从多层网络中的每一层都完全连接,到在卷积神经网络中层之间连接局部的神经元,再到在循环神经网络中与同一神经元的循环连接( recurrent connections)。
深度学习可以被定义为具有大量参数和层的神经网络,包括以下四种基本网络结构:
无监督预训练网络
卷积神经网络
循环神经网络
递归神经网络
在本文中,主要介绍后三种架构。基本上,卷积神经网络(CNN)是一个标准的神经网络,通过共享的权重在空间中扩展。CNN设计用于通过内部的卷积来识别图像,它可以看到图像中待识别的物体的边缘。循环神经网络(RNN)被设计用于识别序列,例如语音信号或文本。它的内部有循环,这意味着网络上有短的记忆。递归神经网络更像是一个层级网络,在这个网络中,输入必须以一种树的方式进行分层处理。下面的10种方法可以应用于所有这些架构。
反向传播(Back-prop)是一种计算函数偏导数(或梯度)的方法,具有函数构成的形式(就像神经网络中)。当使用基于梯度的方法(梯度下降只是方法之一)解决优化问题时,你需要在每次迭代中计算函数梯度。

对于神经网络,目标函数具有组合的形式。如何计算梯度呢?有两种常用的方法:(i)解析微分(Analytic differentiation)。你已经知道函数的形式,只需要用链式法则(基本微积分)来计算导数。(ii)利用有限差分进行近似微分。这种方法在计算上很昂贵,因为函数值的数量是O(N),N指代参数的数量。不过,有限差分通常用于在调试时验证back-prop实现。
一种直观理解梯度下降的方法是想象一条河流从山顶流下的路径。梯度下降的目标正是河流努力达到的目标——即,到达最底端(山脚)。
现在,如果山的地形是这样的,在到达最终目的地之前,河流不会完全停下来(这是山脚的最低点,那么这就是我们想要的理想情况。)在机器学习中,相当从初始点(山顶)开始,我们找到了解决方案的全局最小(或最佳)解。然而,可能因为地形的性质迫使河流的路径出现几个坑,这可能迫使河流陷入困境。在机器学习术语中,这些坑被称为局部极小值,这是不可取的。有很多方法可以解决这个问题。
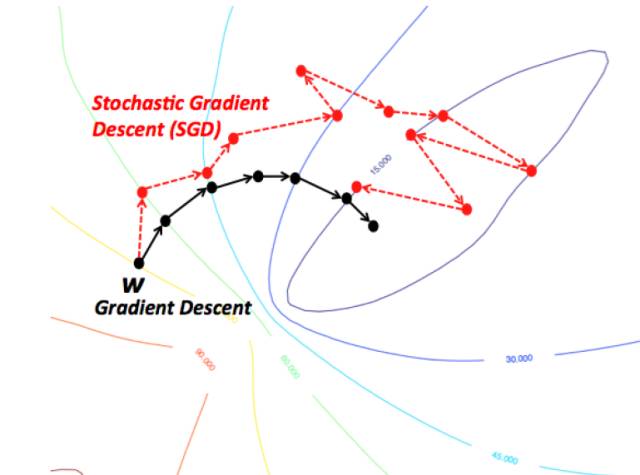
因此,梯度下降很容易被困在局部极小值,这取决于地形的性质(用ML的术语来说是函数的性质)。但是,当你有一种特殊的地形时(形状像一个碗,用ML的术语来说,叫做凸函数),算法总是保证能找到最优解。凸函数对ML的优化来说总是好事,取决于函数的初始值,你可能会以不同的路径结束。同样地,取决于河流的速度(即,梯度下降算法的学习速率或步长),你可能以不同的方式到达最终目的地。这两个标准都会影响到你是否陷入坑里(局部极小值)。
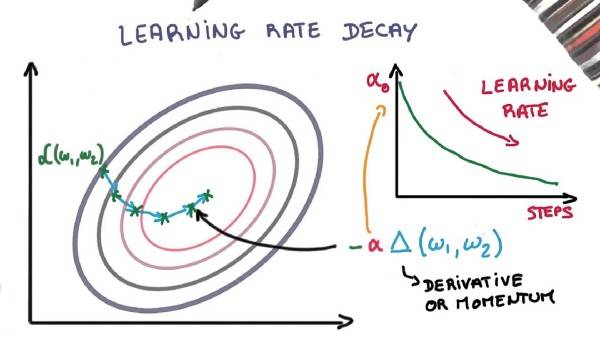
根据随机梯度下降的优化过程调整学习率(learning rate)可以提高性能并减少训练时间。 有时这被称为学习率退火( learning rate annealing)或自适应学习率(adaptive learning rates)。训练过程中最简单,也是最常用的学习率适应是随着时间的推移而降低学习度。 在训练过程开始时使用较大学习率具有进行大的改变的好处,然后降低学习率,使得后续对权重的训练更新更小。这具有早期快速学习好权重,后面进行微调的效果。
两种常用且易于使用的学习率衰减方法如下:
逐步降低学习率。
在特定的时间点较大地降低学习率。
具有大量参数的深度神经网络是非常强大的机器学习系统。然而,过拟合在这样的网络中是一个严重的问题。大型网络的使用也很缓慢,这使得在测试时将许多不同的大型神经网络的预测结合起来变得困难。Dropout是解决这个问题的一种方法。
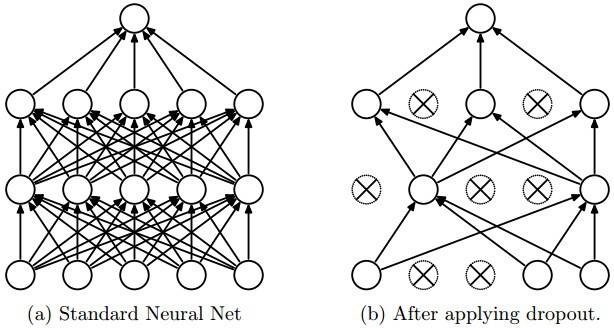
Dropout 的关键想法是在训练过程中随机地从神经网络中把一些units(以及它们的连接)从神经网络中删除。这样可以防止单元过度适应。在训练过程中,从一个指数级的不同的“稀疏”网络中删除一些样本。在测试时,通过简单地使用一个具有较小权重的单一网络,可以很容易地估计所有这些“变瘦”了的网络的平均预测效果。这显著减少了过拟合,相比其他正则化方法有了很大改进。研究表明,在视觉、语音识别、文档分类和计算生物学等监督学习任务中,神经网络的表现有所提高,在许多基准数据集上获得了state-of-the-art的结果。
最大池化(Max pooling)是一个基于样本的离散化过程。目标是对输入表示(图像,隐藏层输出矩阵等)进行下采样,降低其维度,并允许对包含在分区域中的特征进行假设。
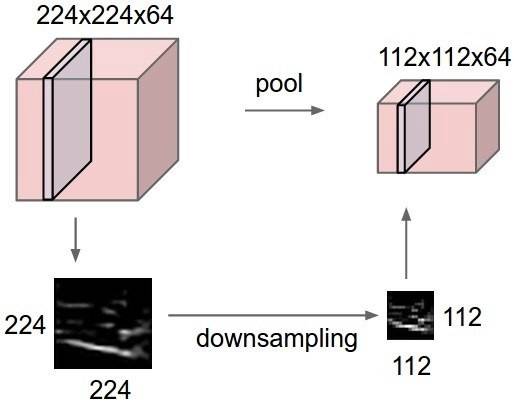
这在一定程度上是为了通过提供一种抽象的表示形式来帮助过拟合。同时,它通过减少学习的参数数量,并为内部表示提供基本的平移不变性(translation invariance),从而减少计算成本。最大池化是通过将一个最大过滤器应用于通常不重叠的初始表示的子区域来完成的。
当然,包括深度网络在内的神经网络需要仔细调整权重初始化和学习参数。而批量标准化有助于实现这一点。
权重问题:无论权重的初始化如何,是随机的也好是经验性的选择也罢,都距离学习到的权重很遥远。考虑一个小批量(mini batch),在最初时,在所需的特征激活方面将会有许多异常值。
深度神经网络本身是有缺陷的,初始层中一个微小的扰动,就会导致后面层巨大的变化。在反向传播过程中,这些现象会导致对梯度的分散,这意味着在学习权重以产生所需输出之前,梯度必须补偿异常值,而这将导致需要额外的时间才能收敛。

批量归一化将梯度从分散规范化到正常值,并在小批量范围内向共同目标(通过归一化)流动。
学习率问题:一般来说,学习率保持较低,只有一小部分的梯度校正权重,原因是异常激活的梯度不应影响学习的激活。通过批量归一化,减少异常激活,因此可以使用更高的学习率来加速学习过程。
LSTM网络在以下三个方面与RNN的神经元不同:
能够决定何时让输入进入神经元;
能够决定何时记住上一个时间步中计算的内容;
能够决定何时让输出传递到下一个时间步长。
LSTM的优点在于它根据当前的输入本身来决定所有这些。所以,你看下面的图表:
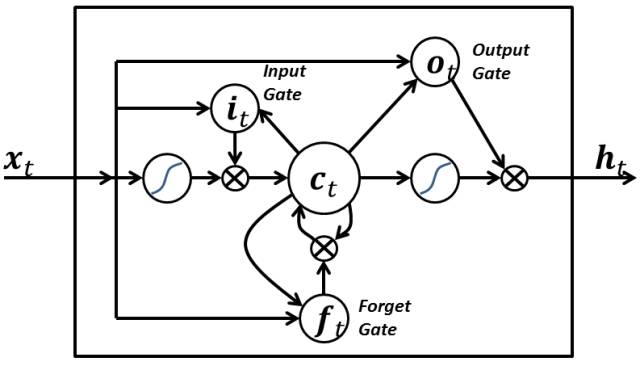
当前时间标记处的输入信号x(t)决定所有上述3点。输入门从点1接收决策,遗忘门从点2接收决策,输出门在点3接收决策,单独的输入能够完成所有这三个决定。这受到我们的大脑如何工作的启发,并且可以基于输入来处理突然的上下文/场景切换。
词嵌入模型的目标是为每个词汇项学习一个高维密集表示,其中嵌入向量之间的相似性显示了相应词之间的语义或句法相似性。Skip-gram是学习单词嵌入算法的模型。
Skip-gram模型(以及许多其他的词语嵌入模型)的主要思想是:如果两个词汇项(vocabulary term)共享的上下文相似,那么这两个词汇项就相似。
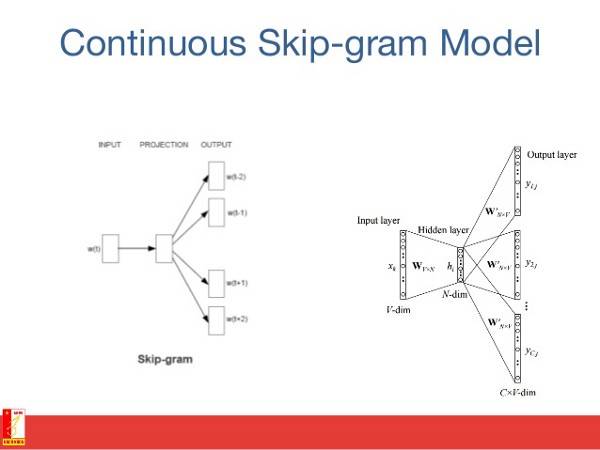
换句话说,假设你有一个句子,比如“猫是哺乳动物”。如果你用“狗”去替换“猫”,这个句子仍然是一个有意义的句子。因此在这个例子中,“狗”和“猫”可以共享相同的上下文(即“是哺乳动物”)。
基于上述假设,你可以考虑一个上下文窗口(context window,一个包含k个连续项的窗口),然后你跳过其中一个单词,试着去学习一个能够得到除跳过项外所有项的神经网络,并预测跳过的项是什么。如果两个词在一个大语料库中反复共享相似的语境,则这些词的嵌入向量将具有相近的向量。
在自然语言处理问题中,我们希望学习将文档中的每个单词表示为一个数字向量,使得出现在相似的上下文中的单词具有彼此接近的向量。在连续的单词模型中,我们的目标是能够使用围绕特定单词的上下文并预测特定单词。

我们通过在一个庞大的语料库中抽取大量的句子来做到这一点,每当我们看到一个单词时,我们就会提取它周围的单词。然后,我们将上下文单词输入到一个神经网络,并预测位于这个上下文中心的单词。
当我们有成千上万的这样的上下文单词和中心词以后,我们就有了一个神经网络数据集的实例。训练神经网络,最后编码的隐藏层输出表示特定单词的嵌入。而当我们对大量的句子进行训练时也能发现,类似语境中的单词得到的是相似的向量。
让我们考虑图像如何穿过卷积神经网络。假设你有一个图像,你应用卷积,并得到像素的组合作为输出。假设这些输出是边缘(edge)。现在再次应用卷积,现在你的输出就是边或线的组合。然后再次应用卷积,你的输出是线的组合,以此类推……你可以把它看作是每一层寻找一个特定的模式。神经网络的最后一层往往会变得非常特异化。如果你在ImageNet上工作,你的网络最后一层大概就是在寻找儿童、狗或飞机等整体图案。再往后倒退几层,你可能会看到网络在寻找眼睛或耳朵或嘴巴或轮子这样的组成部件。
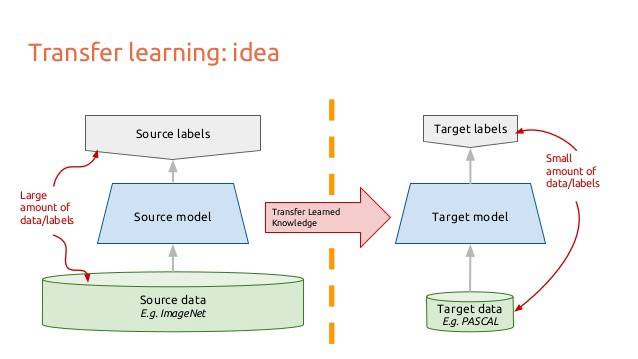
深度CNN中的每一层都逐步建立起越来越高层次的特征表征。最后几层往往是专门针对输入模型的数据。另一方面,早期的图层更为通用。而迁移学习就是当你在一个数据集上训练CNN时,切掉最后一层,在不同的数据集上重新训练最后一层的模型。直观地说,你正在重新训练模型以识别不同的高级特征。因此,训练时间会减少很多,所以当你没有足够的数据或者训练需要太多的资源时,迁移学习是一个有用的工具。
这篇文章简单介绍了深度学习,如果你想了解更多更深层次的东西,建议你继续阅读以下资料:
Andrew Beam “Deep Learning 101”http://beamandrew.github.io/deeplearning/2017/02/23/deep_learning_101_part1.html
Andrey Kurenkov “A Brief History of Neural Nets and Deep Learning”http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/
Adit Deshpande “A Beginner’s Guide to Understanding Convolutional Neural Networks”https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
Chris Olah “Understanding LSTM Networks”http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Algobean “Artificial Neural Networks”https://algobeans.com/2016/03/13/how-do-computers-recognise-handwriting-using-artificial-neural-networks/
Andrej Karpathy “The Unreasonable Effectiveness of Recurrent Neural Networks”http://karpathy.github.io/2015/05/21/rnn-effectiveness/
深度学习强烈注重技术。对每一个新想法都没有太多具体的解释。 大多数新想法都附带了实验结果来证明它们能够工作。深度学习就像玩乐高。掌握乐高跟掌握其他艺术一样具有挑战性,但入门乐高可是相对容易很多的。祝你学习愉快~
文章来源:新智元
原文:https://towardsdatascience.com/the-10-deep-learning-methods-ai-practitioners-need-to-apply-885259f402c1

注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956