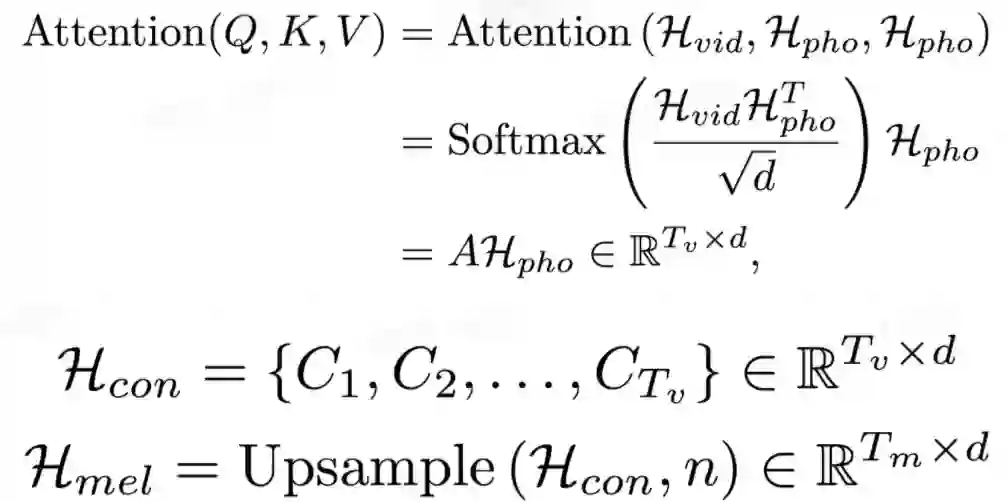清华大学和字节跳动智能创作语音团队业内首次提出神经网络配音器,
让 AI 根据配音脚本,自动生成与画面节奏同步的高质量配音。
影视配音是一项技术含量很高的专业技能。专业配音演员的声音演绎往往让人印象深刻。现在,AI 也有望自动实现这种能力。
近期,清华大学和字节跳动智能创作语音团队业内首次提出了神经网络配音器(Neural Dubber)。这项研究能让 AI 根据配音脚本,自动生成与画面节奏同步的高质量配音。相关论文 Neural Dubber: Dubbing for Videos According to Scripts 已入选机器学习和计算神经科学领域顶级学术会议 NeurIPS 2021。
![]()
配音(Dubbing)广泛用于电影和视频的后期制作,具体指的是在安静的环境(即录音室)中重新录制演员对话的后期制作过程。配音常见于两大应用场景:第一个是替换拍摄时录制的对话,如拍摄场景下录制的语音音质不佳,又或者出于某种原因演员只是对了口型,声音需要事后配上;第二个是对译制片配音,例如,为了便于中国观众欣赏,将其他语言的视频翻译并配音为中文。
清华大学和字节跳动智能创作语音团队的这项研究主要关注第一个应用场景,即 “自动对话替换(ADR)”。在这一场景下,专业的配音演员观看预先录制的视频中的表演,并用适当的韵律(例如重音、语调和节奏)重新录制每一句台词,使他们的讲话与预先录制的视频同步。
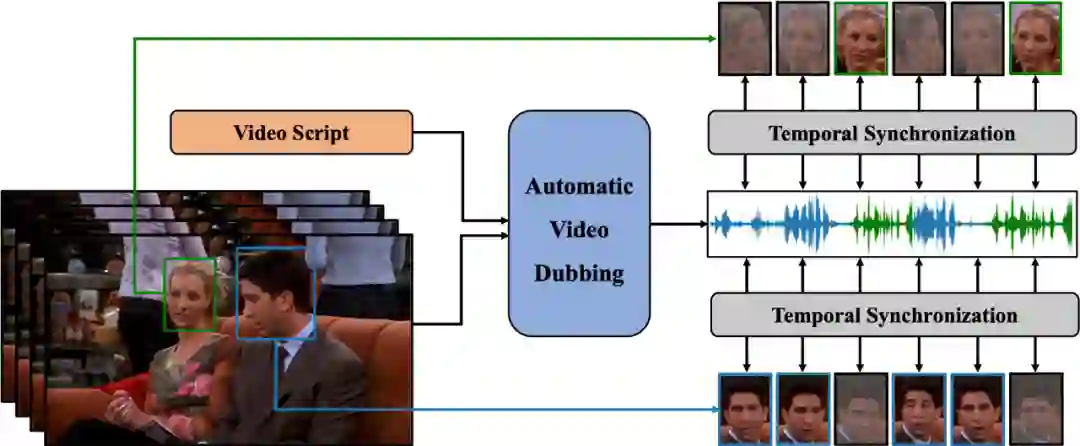
为了实现上述目标,该团队定义了一个新的任务,自动视频配音(Automatic Video Dubbing, AVD), 从给定文本和给定视频中合成与该视频时序上同步的语音。
此前,行业内的很多研究是,根据给定语音生成与之同步的说话人的面部视频(Talking Face Generation)。而 AVD 任务正好相反,是用于生成与视频同步的语音,更加适用于真实的应用场景,因为影视作品拍摄的视频往往质量很高,并不希望再对其进行修改。
![]()
图 1:自动视频配音(AVD)任务示意图。给定文本和视频作为输入,AVD 任务旨在合成与视频在时间上同步的语音。这是两个人互相交谈的场景。面部图片是灰色的,表示当时这个人没有说话。
清华大学和字节跳动智能创作语音团队提出的神经网络配音器(Neural Dubber)旨在解决自动视频配音(AVD)任务。这是第一个解决 AVD 任务的神经网络模型:能够从文本中端到端地并行合成与给定视频同步的高质量语音。神经网络配音器是一种多模态文本到语音 (TTS) 模型,它利用视频中的嘴部运动来控制生成语音的韵律,以达到语音和视频同步的目的。此外,该工作还针对多说话人场景开发了基于图像的说话人嵌入 (ISE) 模块,该模块使神经网络配音器能够根据说话人的面部生成具有合理音色的语音。
神经网络配音器(Neural Dubber)将 AVD 任务具体建模成如下形式:给定音素序列和视频帧序列,模型需要预测与视频同步的梅尔频谱序列。
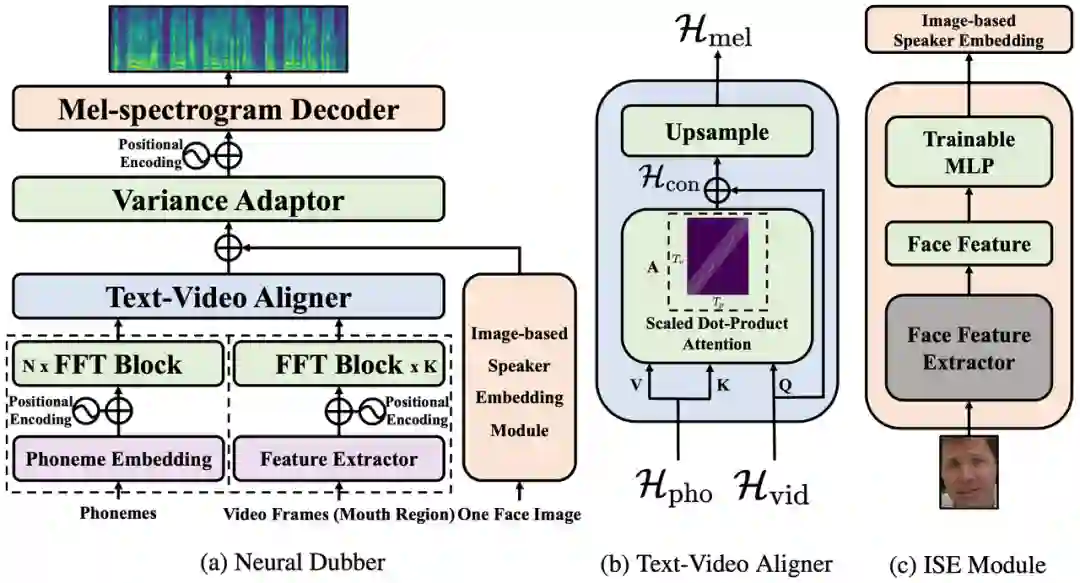
图 2:神经网络配音器(Neural Dubber)的模型结构。
神经网络配音器(Neural Dubber)的整体模型结构如图 2 所示。首先,神经网络配音器应用音素编码器和视频编码器分别处理音素序列和视频帧序列。编码后,音素序列变成音素隐表示序列,视频帧序列变成视频隐表示序列。然后,音素隐表示序列和视频隐表示序列被输入到文本视频对齐器(Text-Video Aligner),得到经过扩展后的梅尔频谱隐表示序列,它与目标梅尔频谱序列的长度相同。该工作在文本视频对齐器中解决了音素和梅尔频谱序列长度不一致的问题。在多说话人场景时,模型会从视频帧序列中随机选择的一张人脸图像,输入到基于图像的说话人嵌入(Image-based Speaker Embedding, ISE)模块以生成基于图像的说话人嵌入。梅尔频谱隐表示序列会与 ISE 相加,并输入到可变信息适配器(Variance Adaptor)中以添加一些方差信息(例如,音高、音量(频谱能量))。最后,梅尔频谱解码器(Mel-spectrogram Decoder)将隐表示序列转换为梅尔频谱序列。
文本视频对齐器(Text-Video Aligner)
文本视频对齐器(图 2(b))可以找到文本和嘴部运动之间的对应关系,利用这种对应关系可以进一步生成与视频同步的语音。
在文本视频对齐器中,注意力模块学习音素序列和视频帧序列之间的对齐方式,并生成文本视频上下文特征序列。然后执行上采样操作以将此序列从与视频帧序列一样长扩展到与目标梅尔频谱序列一样长。
![]()
注意力模块中,视频隐表示序列用作查询。因此,注意力权重由视频显式地控制,并实现了视频帧和音素之间的时序对齐。获得的视频帧和音素之间的单调对齐有助于合成出的语音在细粒度(音素)级别上和视频同步。
之后,将文本视频上下文特征序列扩展到与目标梅尔频谱序列一样的长度。这样音素和梅尔频谱序列之间的长度不匹配问题,就在没有音素和梅尔频谱细粒度对齐监督的情况下得到解决。由于视频帧和音素之间的注意力机制,合成语音的速度和韵律由输入视频显式地控制,使得能够合成与视频同步的语音。
基于图像的说话人嵌入(Image-based Speaker Embedding)
在真实的配音场景中,配音演员需要为不同的表演者改变音色。为了更好地模拟 AVD 任务的真实情况,该研究提出了基于图像的说话人嵌入模块(图 2(c)),目标是在多说话人的场景中利用说话人的面部特征对合成语音进行不同音色的调节。就像人们可以从他人的外表(性别、年龄等)大致推断出对方说话的音色。
基于图像的说话人嵌入是一种新型的多模态说话人嵌入,能够从人脸图片生成说话人嵌入,该嵌入蕴含了图像中所能体现的说话人的声音特征。ISE 模块利用视频中人脸和语音的天然对应关系,采用自监督的方式进行训练,不需要说话人身份的监督。ISE 模块学习到人脸和声音特征的相关性,让神经网络配音器(Neural Dubber)能够产生具有合理音色的语音。合理指的是声音特征与从说话人面部推断出的各种属性(例如,性别和年龄等)相符。
在单说话人数据集 Chemistry Lectures 和多说话人数据集 LRS2 上的实验表明,神经网络配音器(Neural Dubber)可以生成与 SOTA 的 TTS 模型在音质方面相当的语音。最重要的是,定性和定量评估都表明,神经网络配音器可以通过视频控制合成语音的韵律,并生成与视频同步的高质量语音。
由于 AVD 任务旨在给定文本和视频合成与该视频同步的语音,因此语音质量和音视频同步度是重要的评估标准。定性评价上,该研究在测试集进行平均意见分数(MOS)评估,以衡量语音质量和音视频同步度。定量评价上,该研究采用两个指标:Lip Sync Error - Distance (LSE-D) 和 Lip Sync Error - Confidence (LSE-C)。
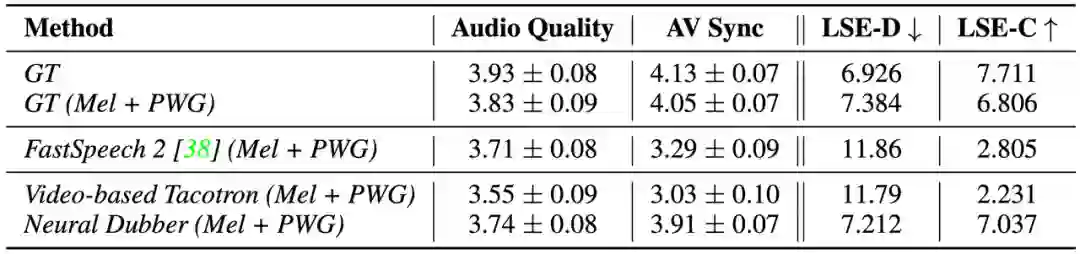
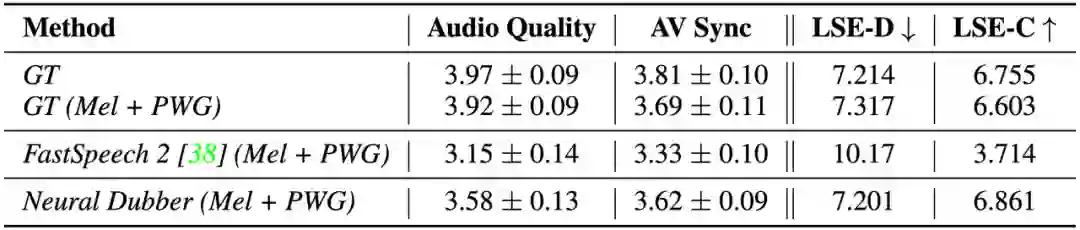
研究者首先在单说话人数据集上进行实验,将 Neural Dubber 与以下几个系统进行比较,包括 1) GT,真实音视频数据;2) GT (Mel + PWG),先将真实音频转换为梅尔频谱图,然后使用 Parallel WaveGAN (PWG) 将其转换回音频;3) FastSpeech 2 (Mel + PWG);4) Video-based Tacotron (Mel + PWG)。为了进行公平比较,2)、3)、4) 和 Neural Dubber 中的使用相同预训练的 Parallel WaveGAN。
![]()
从结果(如表 1 所示)可以看出,Neural Dubber 在音频质量上与 FastSpeech 2 不相上下,这表明 Neural Dubber 可以合成高质量的语音。此外,在音视频同步度方面,Neural Dubber 明显优于 FastSpeech 2 和 Video-based Tacotron,而且与 GT (Mel + PWG) 系统相媲美,这表明 Neural Dubber 可以用视频控制语音的韵律并生成与视频同步的语音。然而, FastSpeech 2 和 Video-based Tacotron 都无法生成与视频同步的语音。
![]()
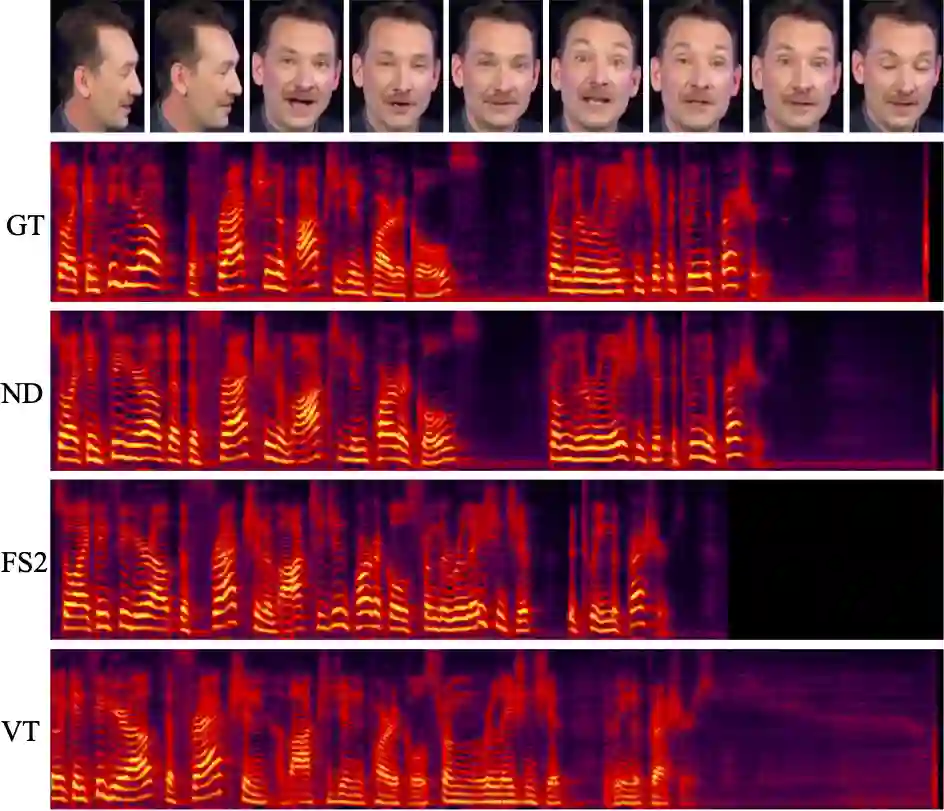
图 3: 由以下系统合成的音频的梅尔频谱图:Ground Truth (GT)、Neural Dubber (ND)、FastSpeech 2 (FS2) 和 Video-based Tacotron (VT)。
图 3 展示了一个定性比较,其中包含由上述系统生成的音频的梅尔频谱图。结果表明 Neural Dubber 生成的音频的韵律十分接近于真实音频的韵律,即与视频同步度很高。
该研究还在多说话人数据集 LRS2 上进行了相同的定性和定量评估。
![]()
从结果(如表 2 所示)可以看出, Neural Dubber 在音频质量方面明显优于 FastSpeech 2,展示了 ISE 在多说话人场景中的有效性。定性和定量评估表明,在音视频同步度方面,Neural Dubber 比 FastSpeech 2 好得多,并且与 GT (Mel + PWG) 系统相当。这些结果表明,Neural Dubber 可以解决比单说话人场景更具挑战性的多说话人场景下的自动视频配音(AVD)问题。
为了展示 ISE 使得 Neural Dubber 能够通过人脸图像控制生成语音的音色。该研究用 Neural Dubber 生成了一些由不同说话者人脸图像作为输入的音频片段。研究者从 LRS2 数据集的测试集中随机选择 12 名男性和 12 名女性进行评估,每个人选择了 10 张具有不同头部姿势、光照和化妆的人脸图像。
![]()
从图 4 可以看出,由同一说话人的图像生成的语音形成一个紧密的簇,不同说话人的簇彼此分离。此外,由不同性别的人脸图像合成的语音之间存在明显差异。
与基于嘴部运动的语音生成(Lip-motion Based Speech Generation )模型 Lip2Wav 对比,Neural Dubber 在自动视频配音任务下的优越性十分显著。
研究者使用 STOI 和 ESTOI 来评估语音可懂度,使用 PESQ 来评估语音质量,使用单词错误率 (WER) 评估语音发音准确度。
![]()
表 3: Lip2Wav 和 Neural Dubber 在单说话人场景下的比较。
如表 3 的结果所示,Neural Dubber 在语音质量和可懂度方面均超过 Lip2Wav。最重要的是,Neural Dubber 的 WER 比 Lip2Wav 低 4 倍左右。这表明 Neural Dubber 在发音准确度上明显优于 Lip2Wav。Lip2Wav 的 WER 高达 72.70%,说明它误读了很多内容,这在 AVD 任务中是不可接受的。总而言之,Neural Dubber 在语音可懂度、音质和发音准确度方面明显优于 Lip2Wav,更适合自动视频配音任务。
清华大学 MARS Lab 多模态学习实验室简介:
MARS Lab 多模态学习实验室,是清华大学交叉信息院下的交叉学科人工智能实验室,由赵行教授组建和指导。
团队特别感兴趣如何让机器像人一样的能够通过多种感知输入进行学习、推理和交互。
团队的研究涵盖了多模态学习的基础问题及其应用。
字节跳动智能创作语音团队简介:
字节跳动智能创作 - 语音团队 (Speech, Audio and Music Intelligence, SAMI) 致力于语音、音频、音乐等技术的研发和产品创新,使命是通过多模态音频技术赋能内容创作和互动,让内容消费和创作变得更简单和愉悦。
团队支持包括语音合成、音频处理和理解、音乐理解和生成等技术方向,并以中台形式服务于公司众多业务线以及向外部企业开放成熟的能力和服务。
了解详情,请点击阅读原文查看项目主页。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com