【深度前沿】深度森林最新进展,南京大学周志华教授MLA2017解读,最新实验结果挑战深度学习
【导读】北京时间 11月5 日到11月6日,一年一度的“机器学习及其应用”(MLA)系列研讨会在北京交通大学开幕,西瓜书《机器学习》作者、南京大学机器学习与数据挖掘研究所(LAMDA)周志华教授日前在第15届中国机器学习及其应用研讨会(MLA 2017)上的演讲报告题目是深度森林初探,讲述的关于他最新集成学习研究成果-深度森林,一种对深度神经网络可替代性方法,这是他和 LAMDA 博士生冯霁发表在人工智能领域顶级会议IJCAI2017的论文《深度森林:探索深度神经网络以外的方法》(Deep Forest: Towards An Alternative to Deep Neural Networks),在投稿的IJCAI2017的原版论文中,只是在很小的minst数据集上进行了测试,最新版本arxiv论文中已经加入对cifar-10的图像数据分类实验。 最新实验表明gcForest已经是最好的非深度神经网络方法。专知内容组整理出品。 此外,请查看本文末尾,可下载最新MLA 2017 深度森林初探 slide。
Deep Forest: Towards An Alternative to Deep Neural Networks

周志华教授今天讲述的是关于他最新集成学习研究成果-深度森林,周志华教授的个人主页是:https://cs.nju.edu.cn/zhouzh/, 相信国内搞人工智能机器学习的都知道周教授的名气,在这就不多介绍了。下面开始介绍这次周老师的报告,由于笔者能力有限,本篇所有备注皆为专知内容组成员按照现场报告自行补全,不代表周志华老师本人的立场与观点。

如今深度学习应用在各种领域,比如视觉,语音以及文本语言处理。而深度学习其实就是多层的神经网络。

美国工业和应用数学学会在今年6月份给出的定义是“深度学习是一类使用深度神经网络的机器学习方法”。
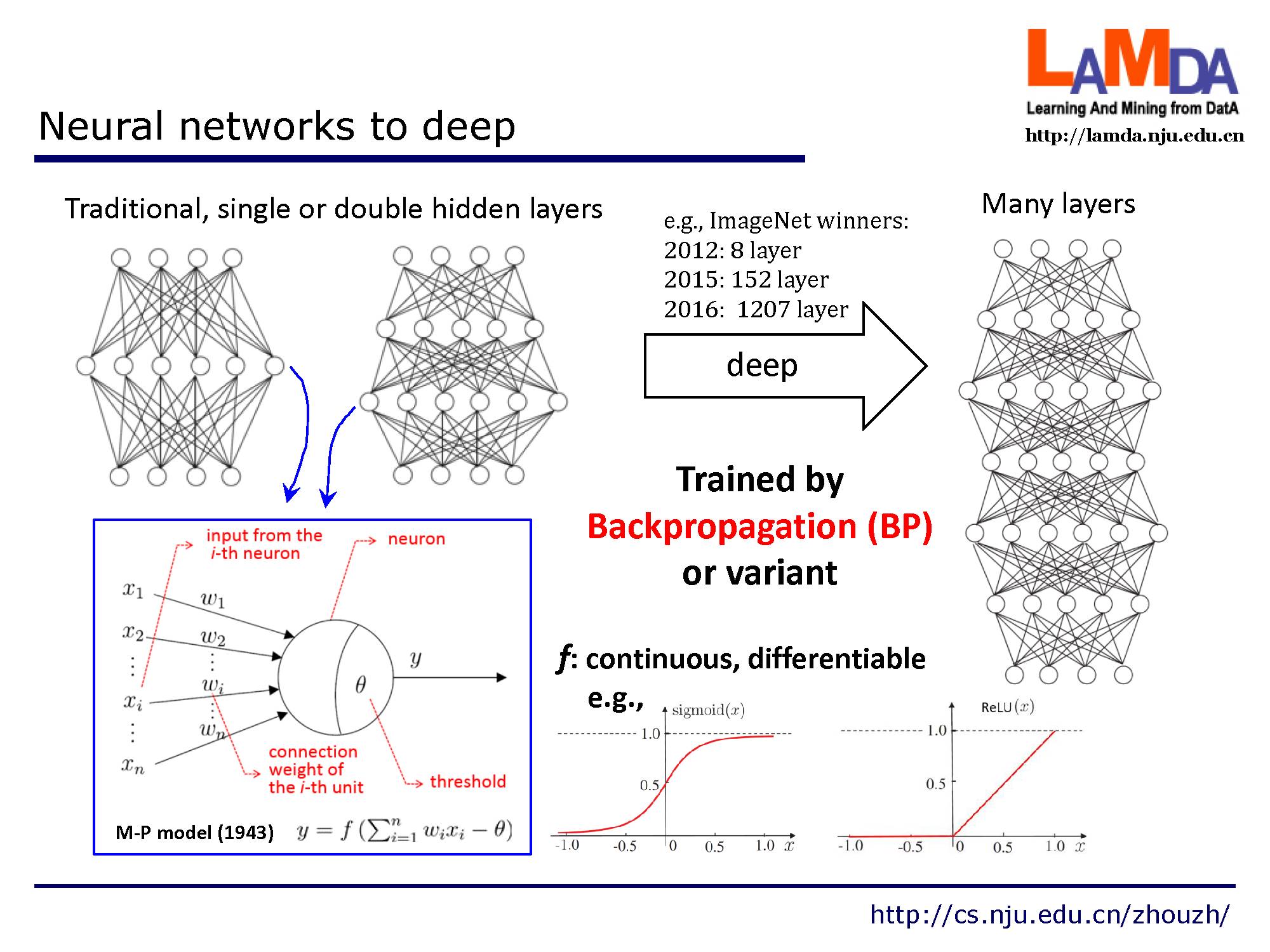
越来越深的网络层数,通常采用BP算法以及其他的一些变体来训练。

我们为什么需要这么深的网络?其中一种解释是一方面,增加模型的复杂度,会改善学习能力,增加层数比单纯的增加节点数要更高效。另一方面,增加模型的复杂度会增加过拟合的风险,在训练过程中,很难来收敛到稳定的状态,很难使用经典的反向传播算法。(需要许多tricks)

深度学习的三大支柱
1. 大量的训练数据
2. 计算力
3. 训练技巧(tricks)
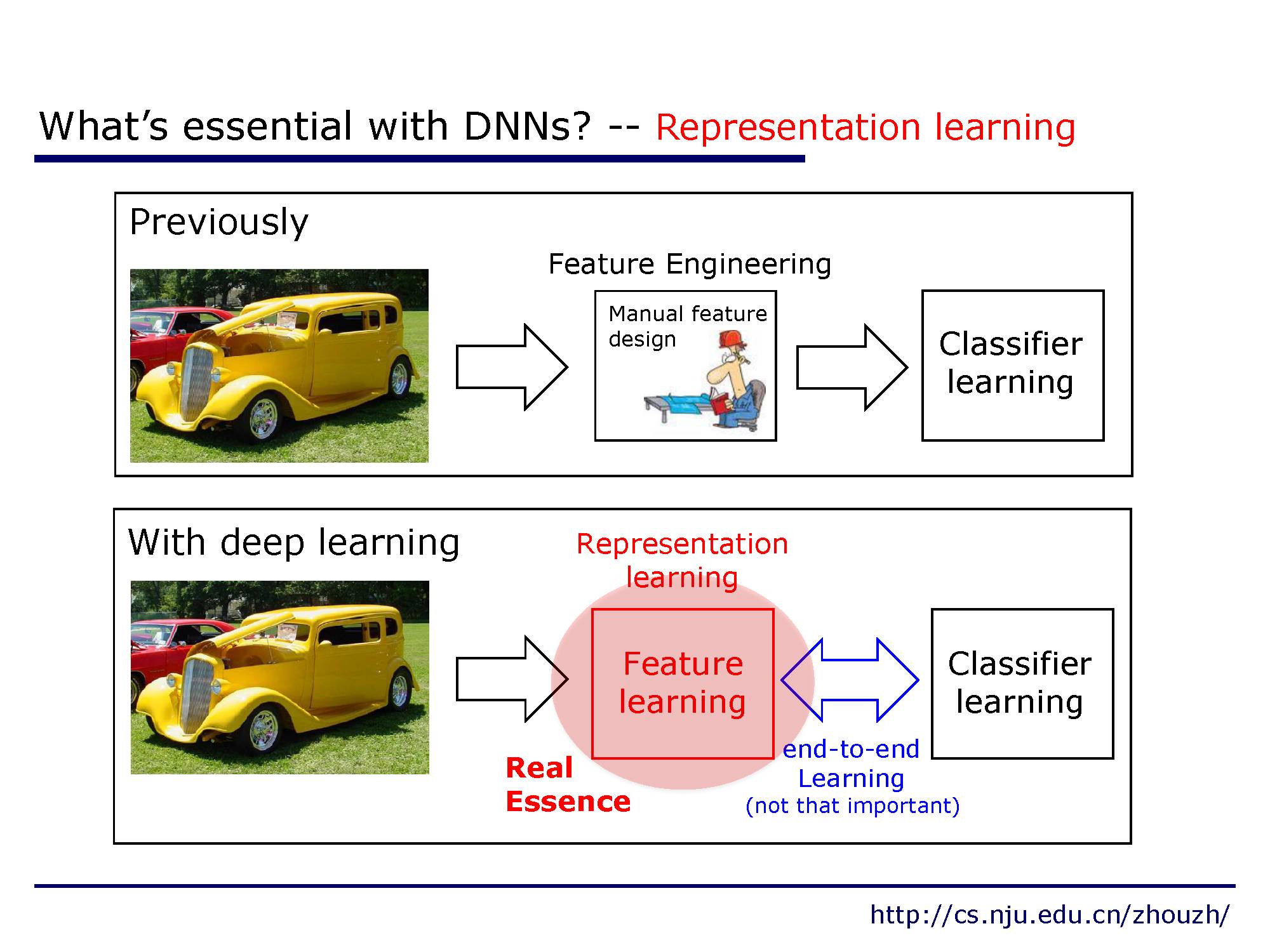
对于深度神经网络来说,表示学习是很重要的。过去需要人工设计各种特征,费时费力,现在利用深度学习可以端到端的学习新的表示方法。

这种表示学习的能力对于那些原始特征不能够在任务中充分表达特性的数据比较适用,比如图像中的像素。

单隐层网络被证明具有通用逼近性质,可以拟合任意复杂的曲线。
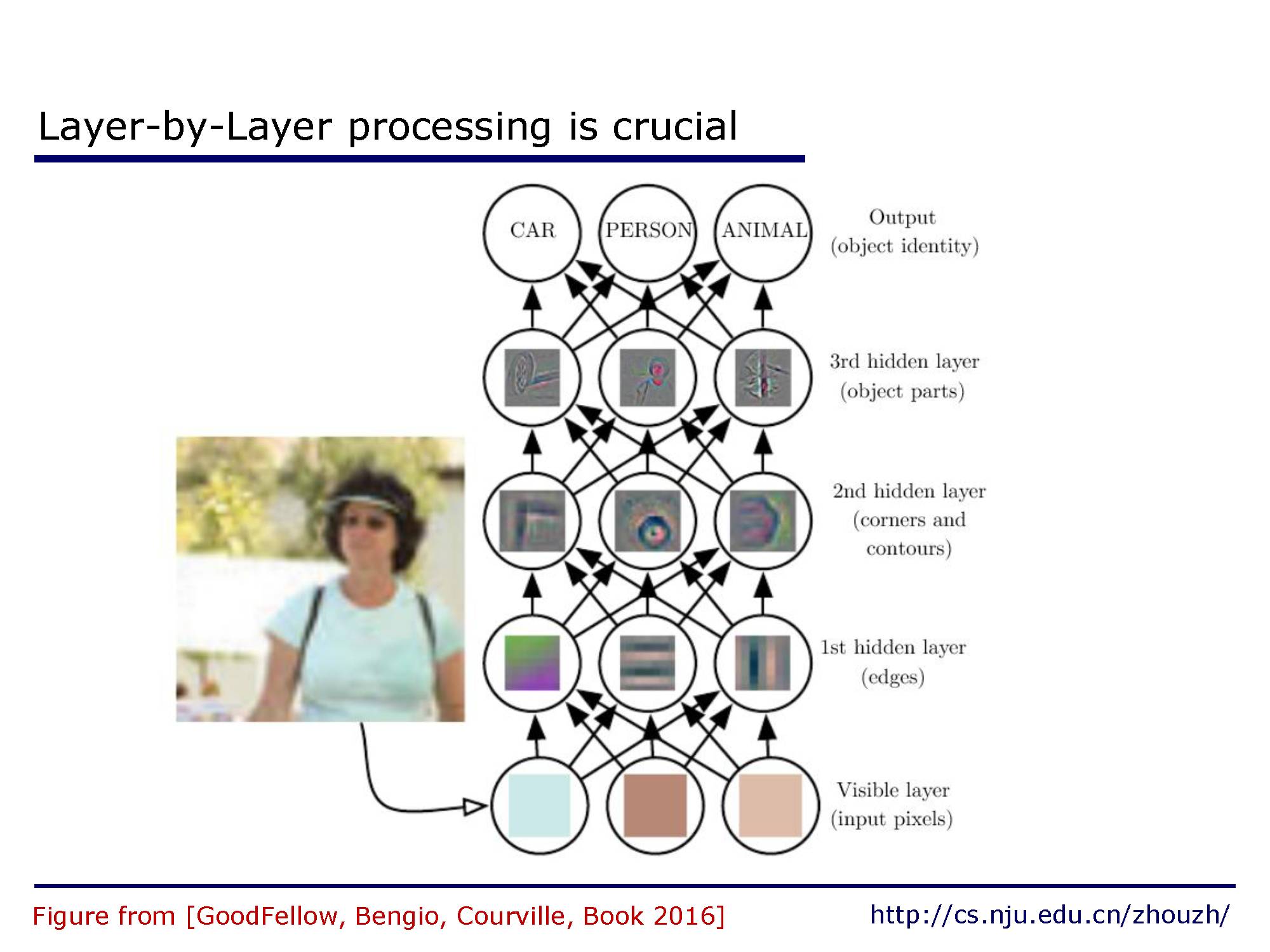
并且,在实际中,一层层的堆叠设计也是很重要的。
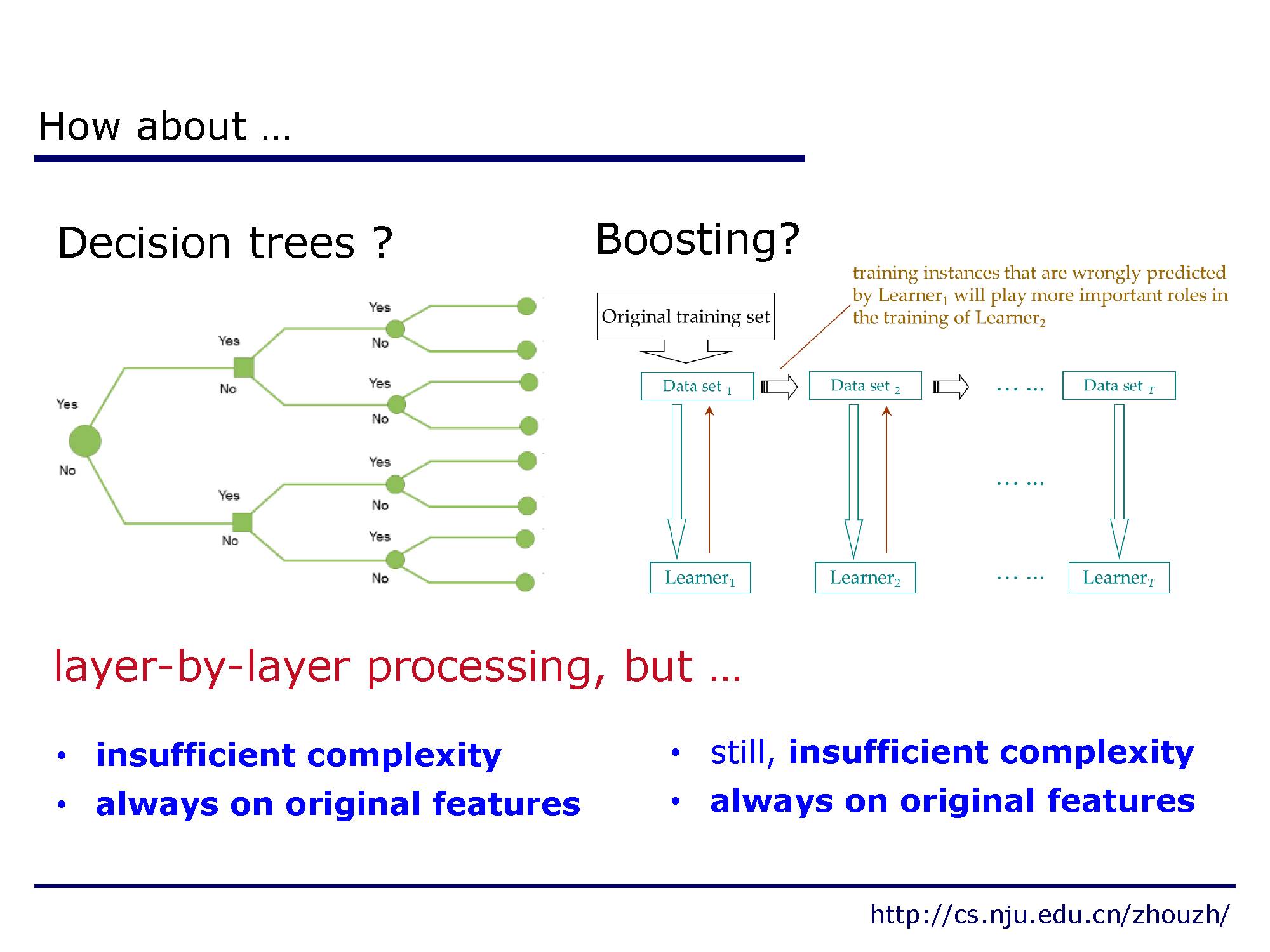
决策树和提升算法也有类似的层次结构,但是他们却没有想深度网络那样的建模能力。复杂度不够,而且常常聚焦保持原始特征。
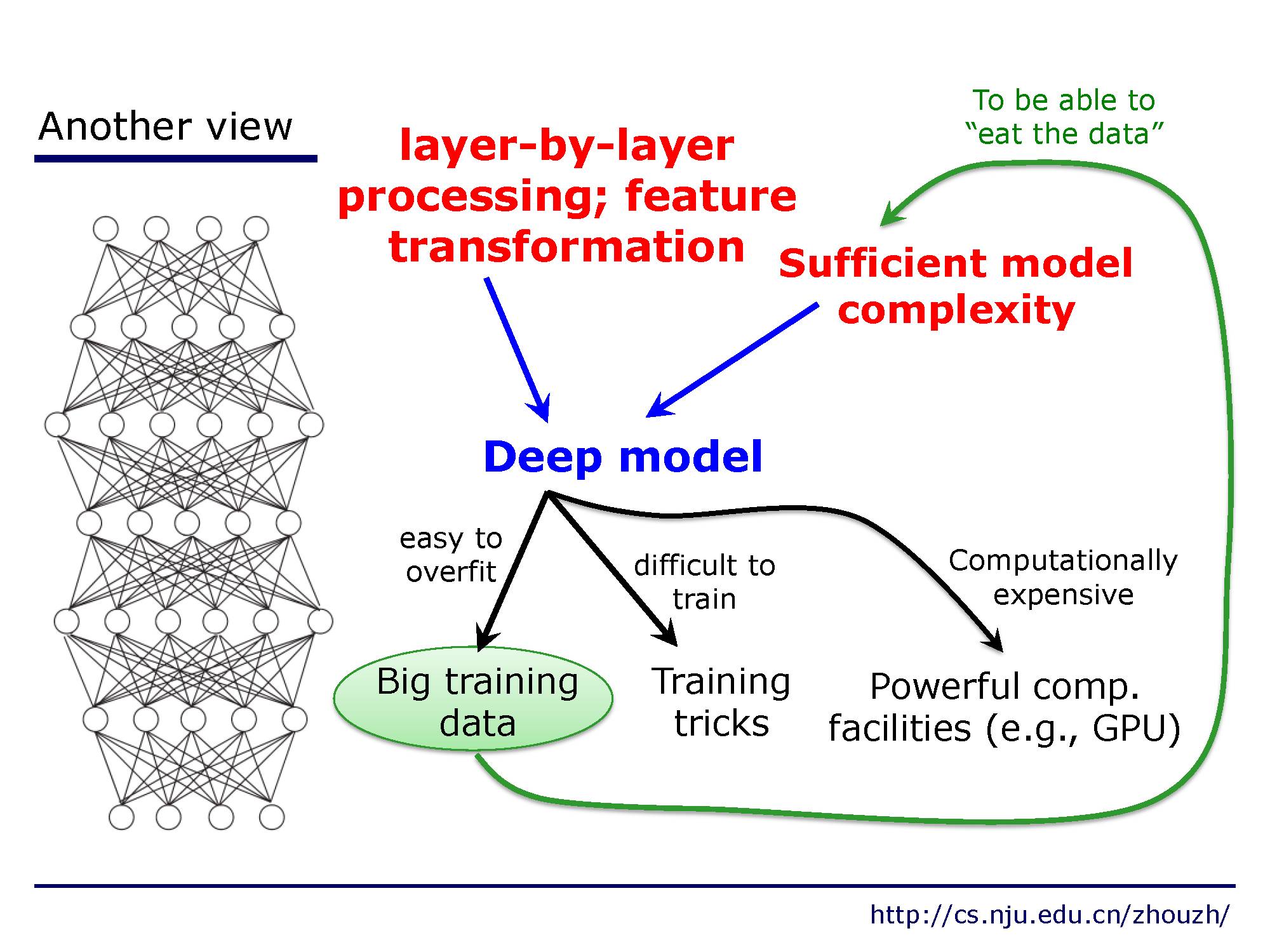
从另外一个角度看,深度神经网络层层处理,可以看成是一个特征转换器,这种结构可以做到足够复杂,同时也需要更多的数据。

实际中,深度模型的要点
1,层层处理;
2,特征变换;
3,足够的模型复杂度。

神经网络的缺点。
1. 太多的超参数需要调试,这其中包含各种调参技巧。而且很难复现别人实验的结果。比如当几个作者用了类似的CNN结构,如果他们使用了不同参数比如卷积层数,实际得到的模型是完全不同的。
2. 如果结构确定了模型的复杂度也就固定死了。
3. 需要大量的数据。
4.理论分析困难。
5.黑盒。

深度神经网络在许多任务上并没有太多优势,有时候甚至没啥用。比如在Kaggle比赛中随机森林和XGBoost通常效果更好些。

回顾下前面讲到的深度模型。现如今深度模型就是深度神经网络:许多可微的非线性层组成的可以用反向传播算法训练的多层结构。
然而实际上,并不是所有的性质都是可微的,有很多不可微的结构存在。这些结构自然不能有反向传播训练。

一个巨大的挑战。如果深度模型包含不可微的部分(无法进行梯度反向传播),他还依然有效吗?

让我们想想,模型中存在不可微结构的同时还要有这些特点,比如层层处理,特征转换以及足够的模型复杂度 我们需要怎么做才可以呢?

这就是我们提出的多粒度级联森林,一种全新的决策树集成方法,使用级联结构让gcForest 做表征学习。它有能和深度神经网络媲美的效果,同时超参数却更少了,也可以根据数据量自适应模型复杂度。

要想在各种数据比赛中取得胜利,集成学习是一个不可或缺的大杀器。
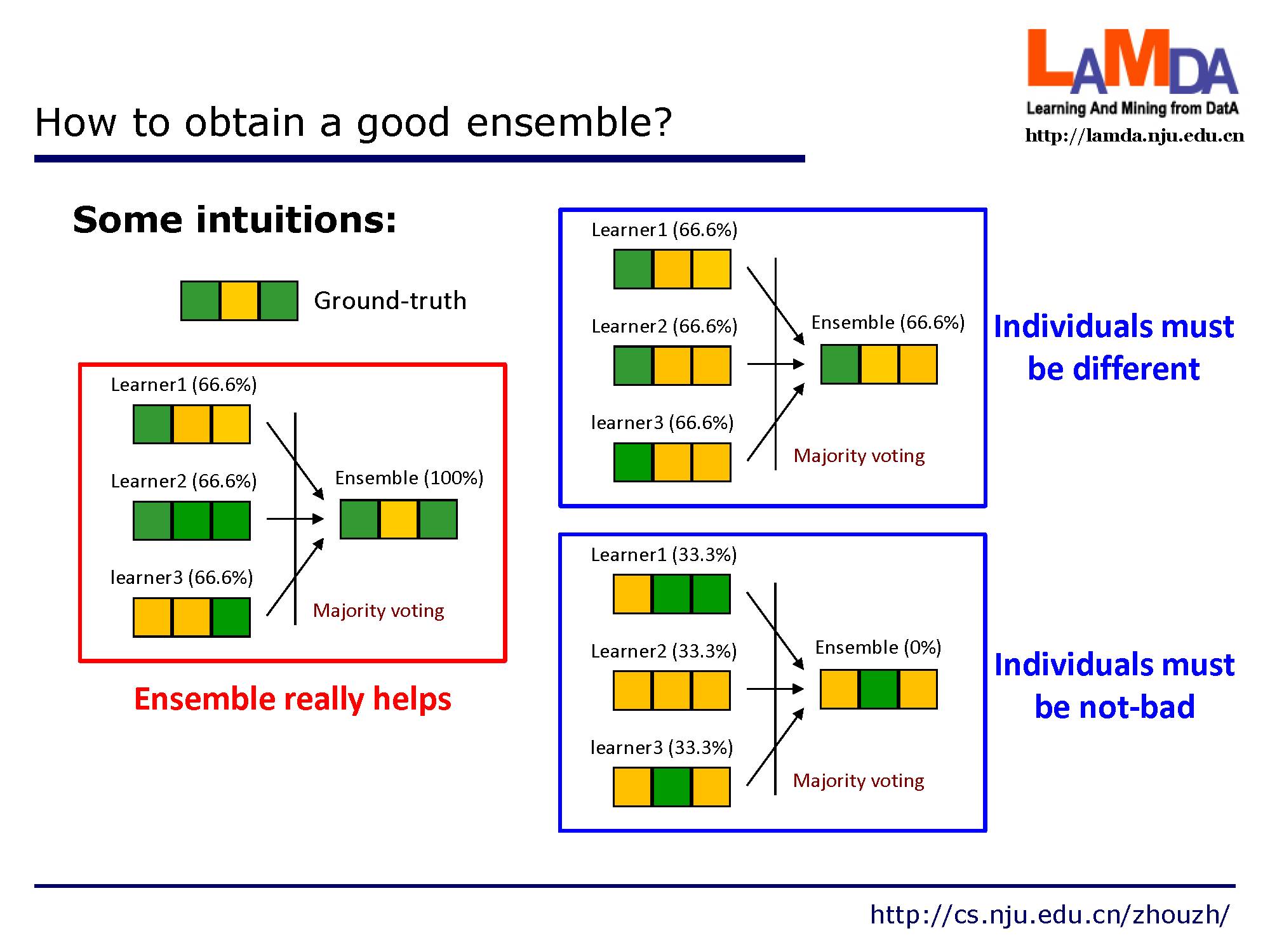
这是因为,为了获得几个比较好的集成结果,每个个体需要有一定的差异性,当然啦个体的效果也不能太差了。

这其中,模型个体的多样性事关键。个体学习器的进度越高,差异性越大,集成效果越好。

如何产生这种差异性的核心思想是加入一些随机性。主要可以在这几个方面操作,包括对数据采样,输入特征,学习参数以及输出特征的操作。

关于集成学习的具体细节可以看周志华老师出版的一本专著。

讲到正题,首先讲下级联森林。
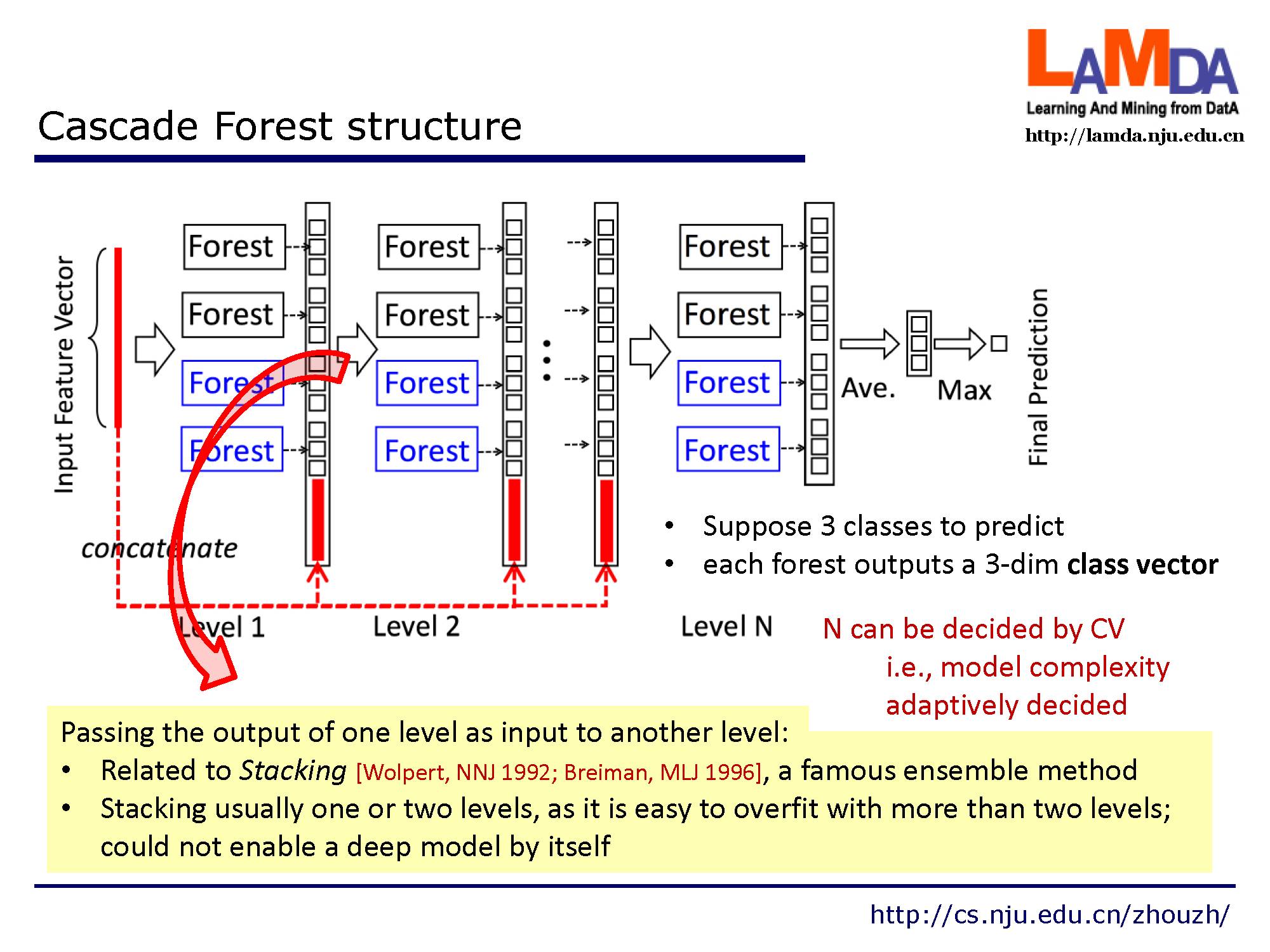
深度神经网络中的表征学习(representation learning)主要依赖于对原始特征进行逐层处理。受此启发,gcForest 采用级联结构(cascade structure),如图所示,其中级联中的每一级接收到由前一级处理的特征信息,并将该级的处理结果输出给下一级。
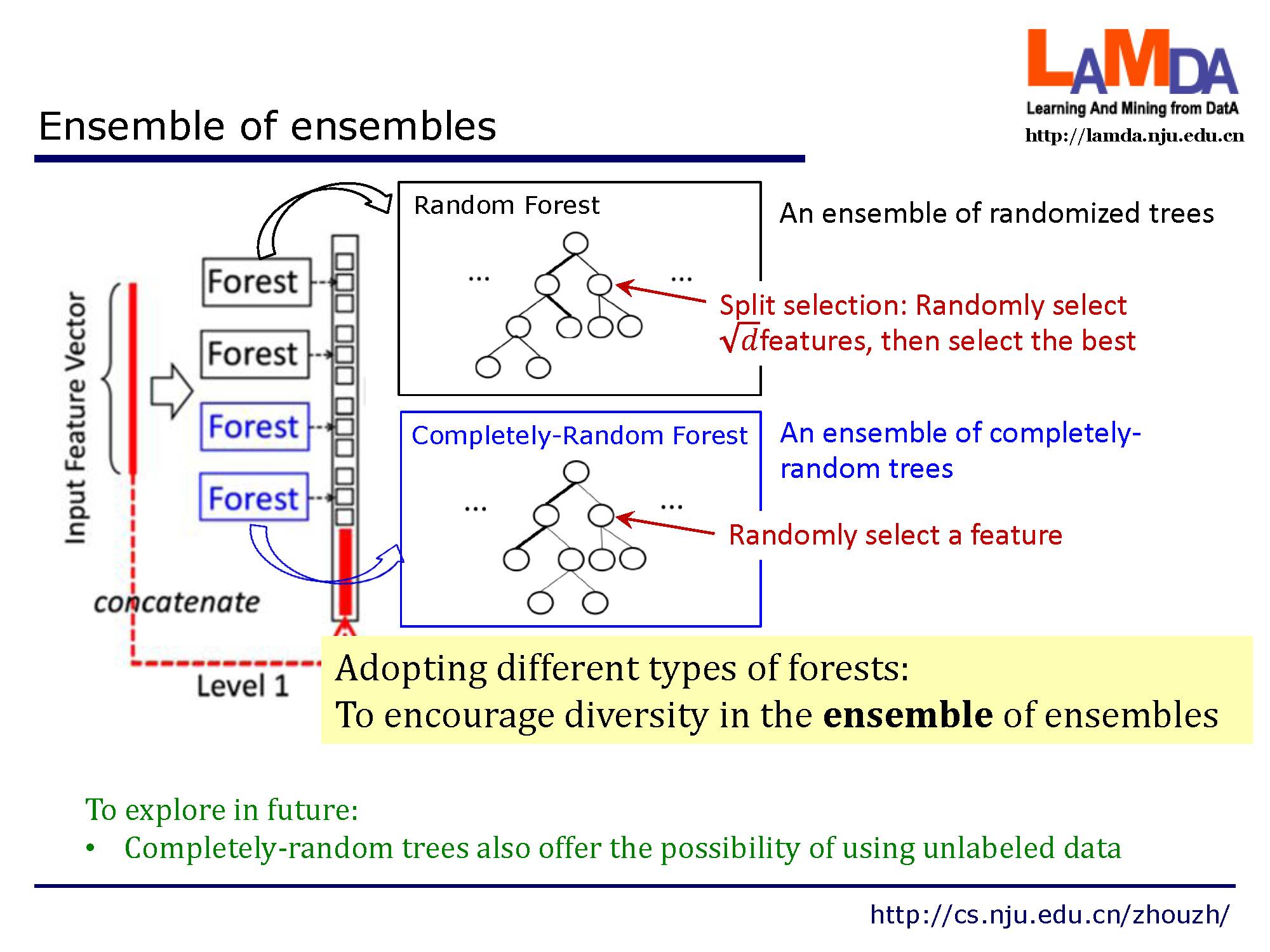
每个级是决策树森林的一个集合,即集成的集成(ensemble of ensembles)。我们包含了不同类型的森林来鼓励多样性,因为前面讲到,多样性是集成学习结构的关键。
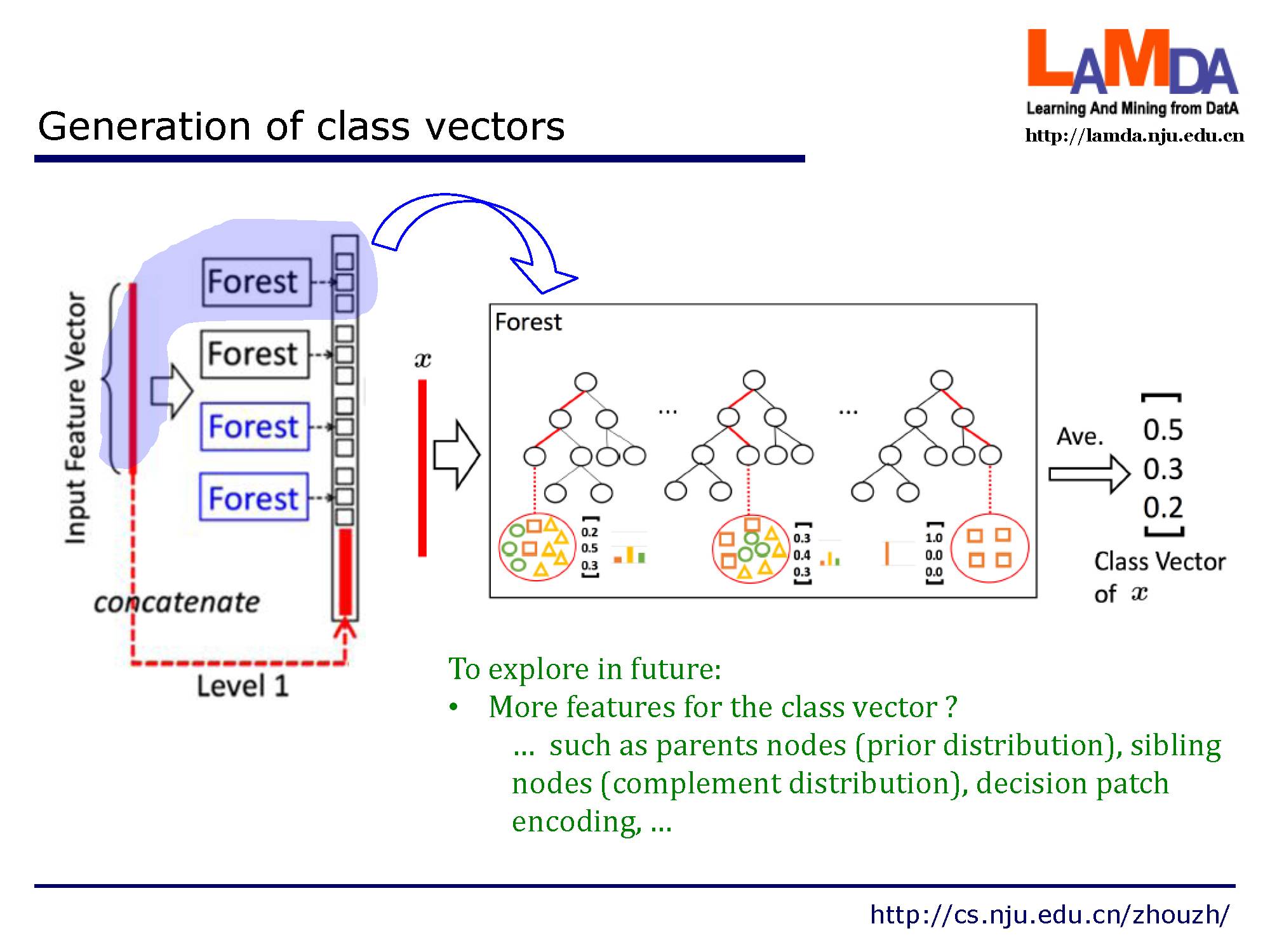
给定一个实例,每个森林会通过计算在相关实例落入的叶节点处的不同类的训练样本的百分比,然后对森林中的所有树计平均值,以生成对类的分布的估计。如图所示,其中红色部分突出了每个实例遍历到叶节点的路径。被估计的类分布形成类向量(class vector),该类向量接着与输入到级联的下一级的原始特征向量相连接。例如,假设有三个类,则四个森林每一个都将产生一个三维的类向量,因此,级联的下一级将接收12 = 3×4个增强特征(augmentedfeature)。

下面讲下多粒度的问题。(Multi-grained)
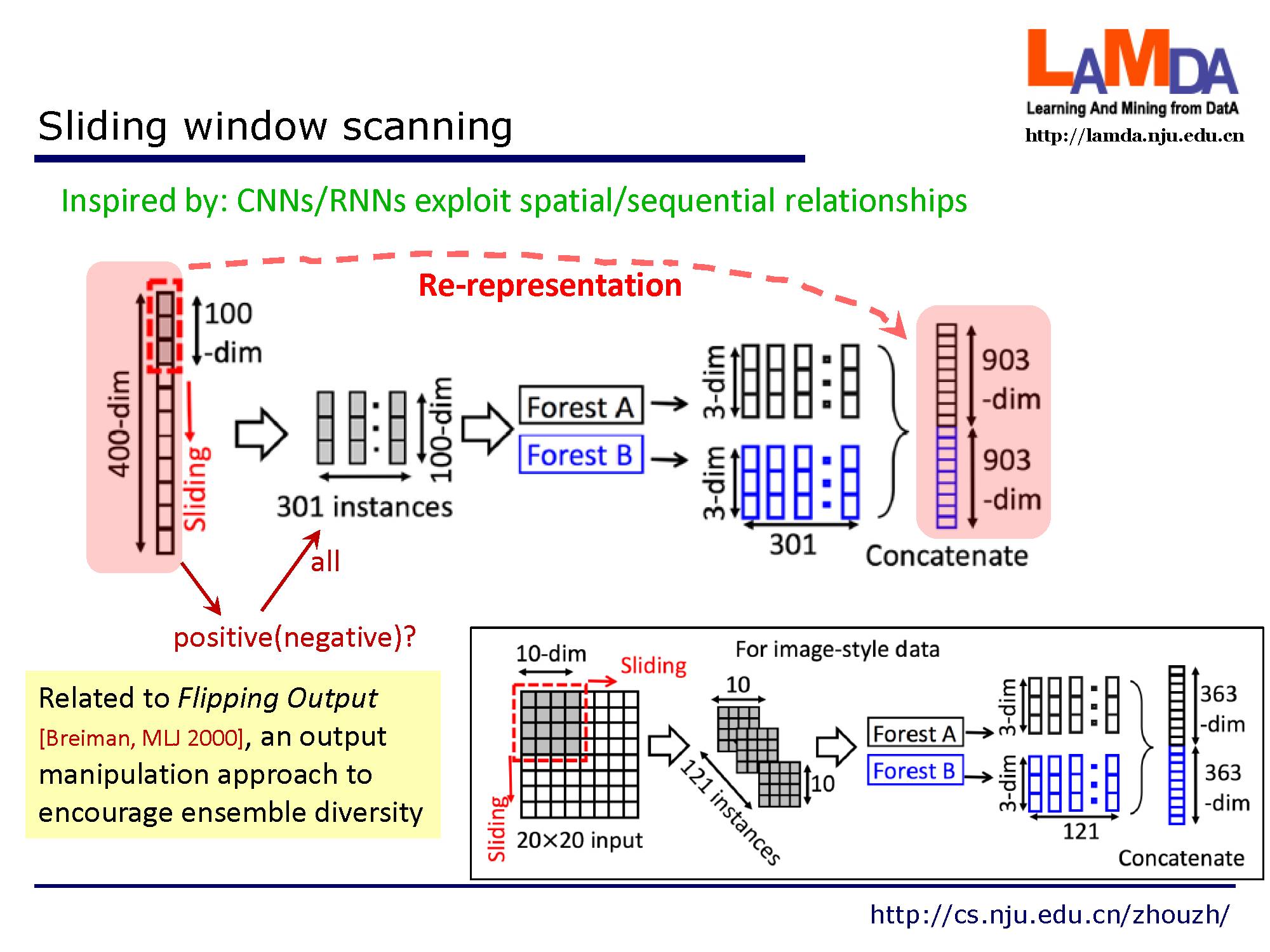
深度神经网络在处理特征关系方面是强大的,例如,卷积神经网络对图像数据有效,其中原始像素之间的空间关系是关键的。,递归神经网络对序列数据有效,其中顺序关系是关键的。受这种认识的启发,我们用多粒度扫描流程来增强级联森林。如图所示,滑动窗口用于扫描原始特征。假设有400个原始特征,并且使用100个特征的窗口大小。对于序列数据,将通过滑动一个特征的窗口来生成100维的特征向量;总共产生301个特征向量。如果原始特征具有空间关系,比如图像像素为400的20×20的面板,则10×10窗口将产生121个特征向量(即121个10×10的面板)。从正/负训练样例中提取的所有特征向量被视为正/负实例;它们将被用于生成如 2.1节中所说的类向量:从相同大小的窗口提取的实例将用于训练完全随机树森林和随机森林,然后生成类向量并连接为转换后的要素。如图所示,假设有3个类,并且使用100维的窗口;然后,每个森林产生301个三维类向量,导致对应于原始400维原始特征向量的1,806维变换特征向量。
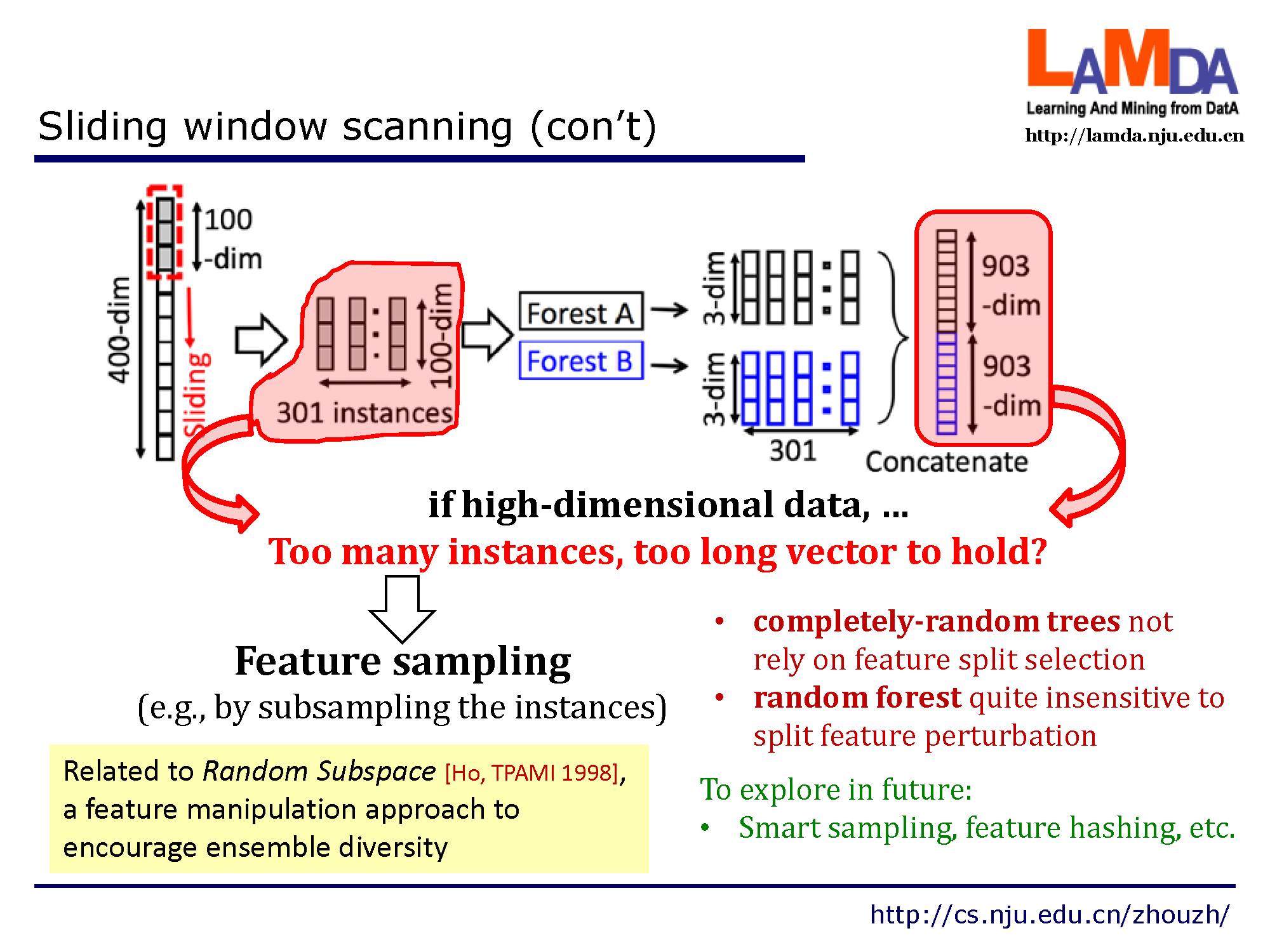
但是当数据维度过高,将会产生过多实例和太长的向量而无法处理。
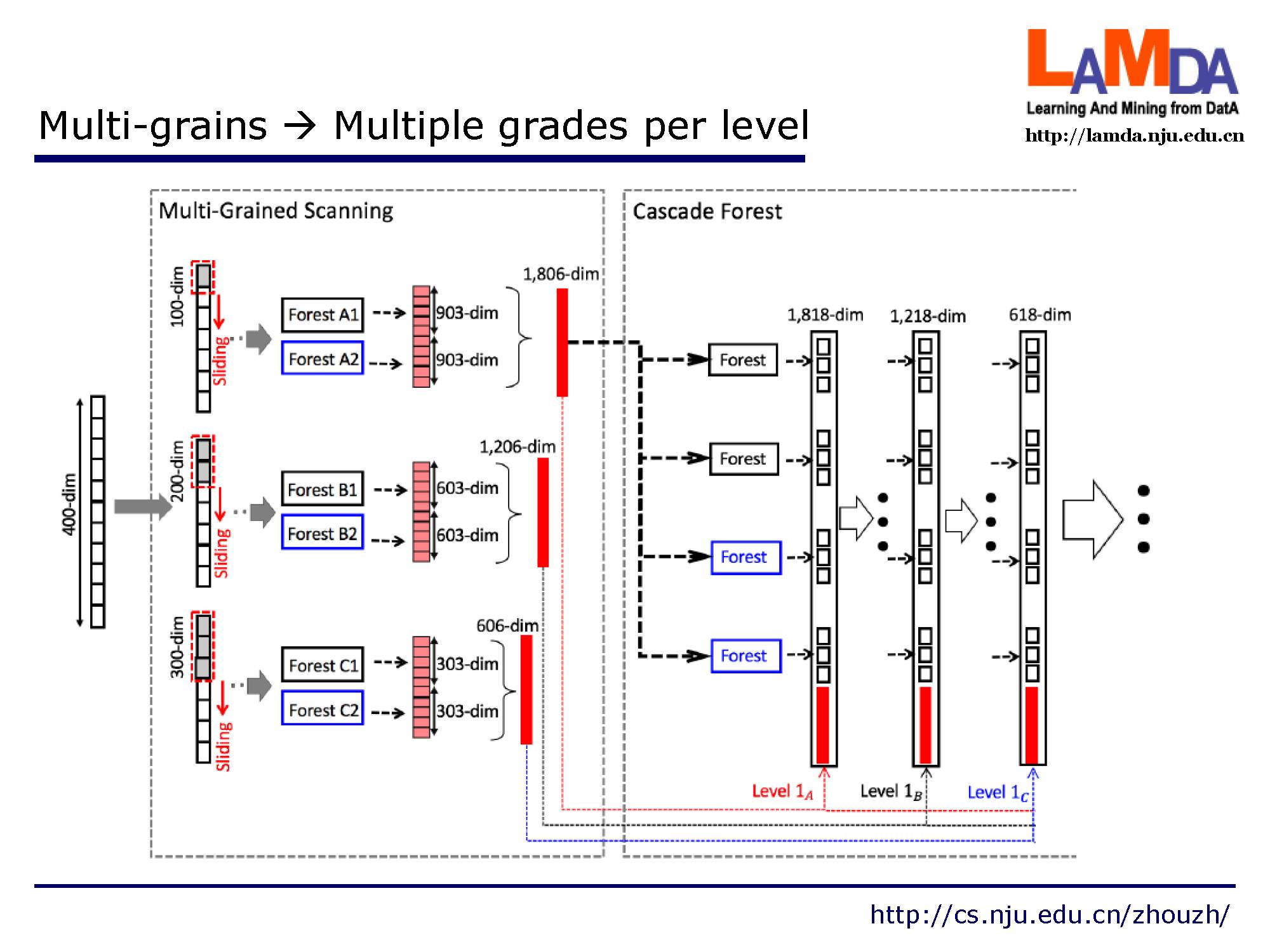
从多粒度到多级处理。假设有三个类要预测,原始特征是400-dim,使用了三个尺寸的滑动窗口。
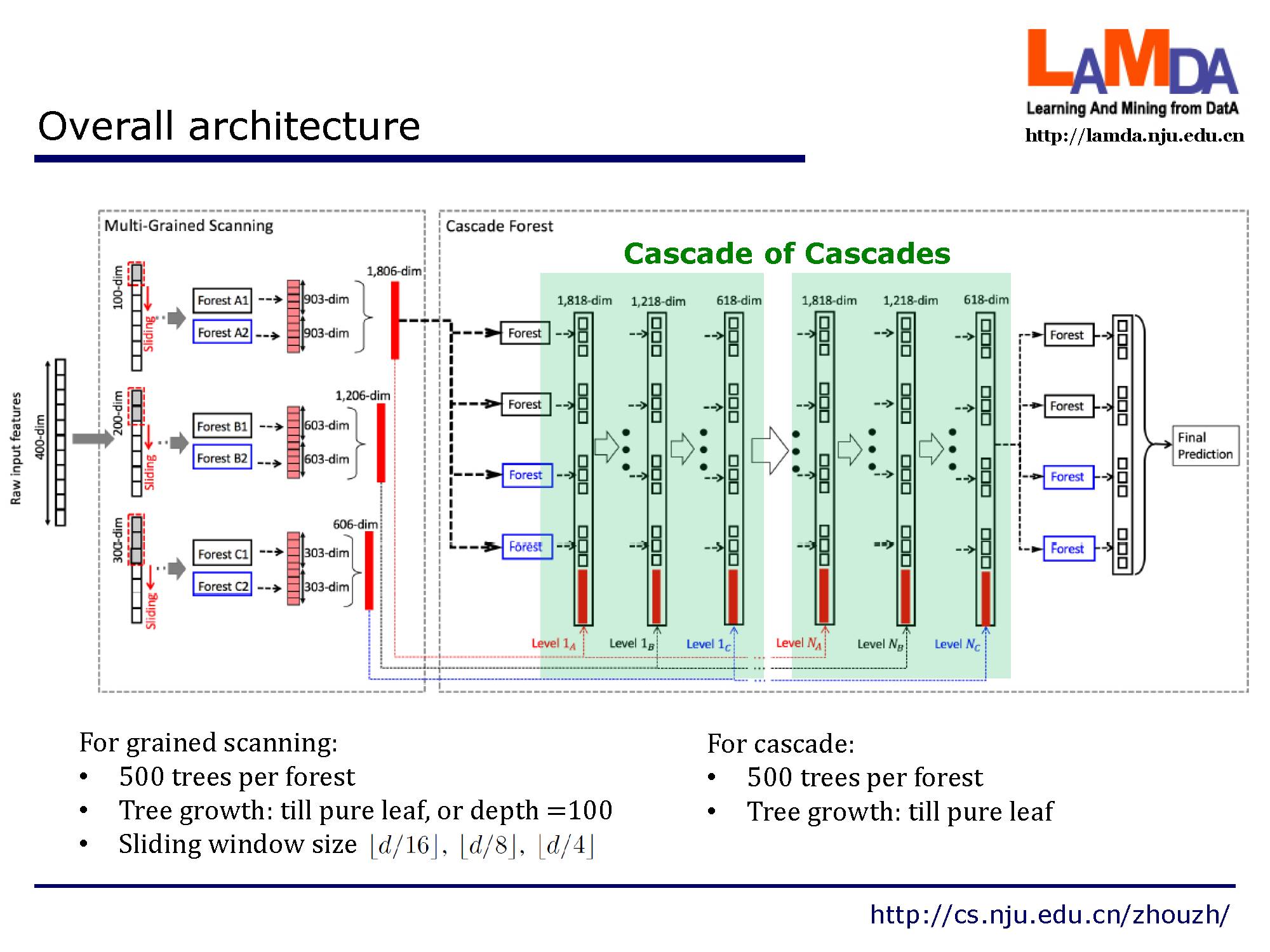
这是提出的总体结构。
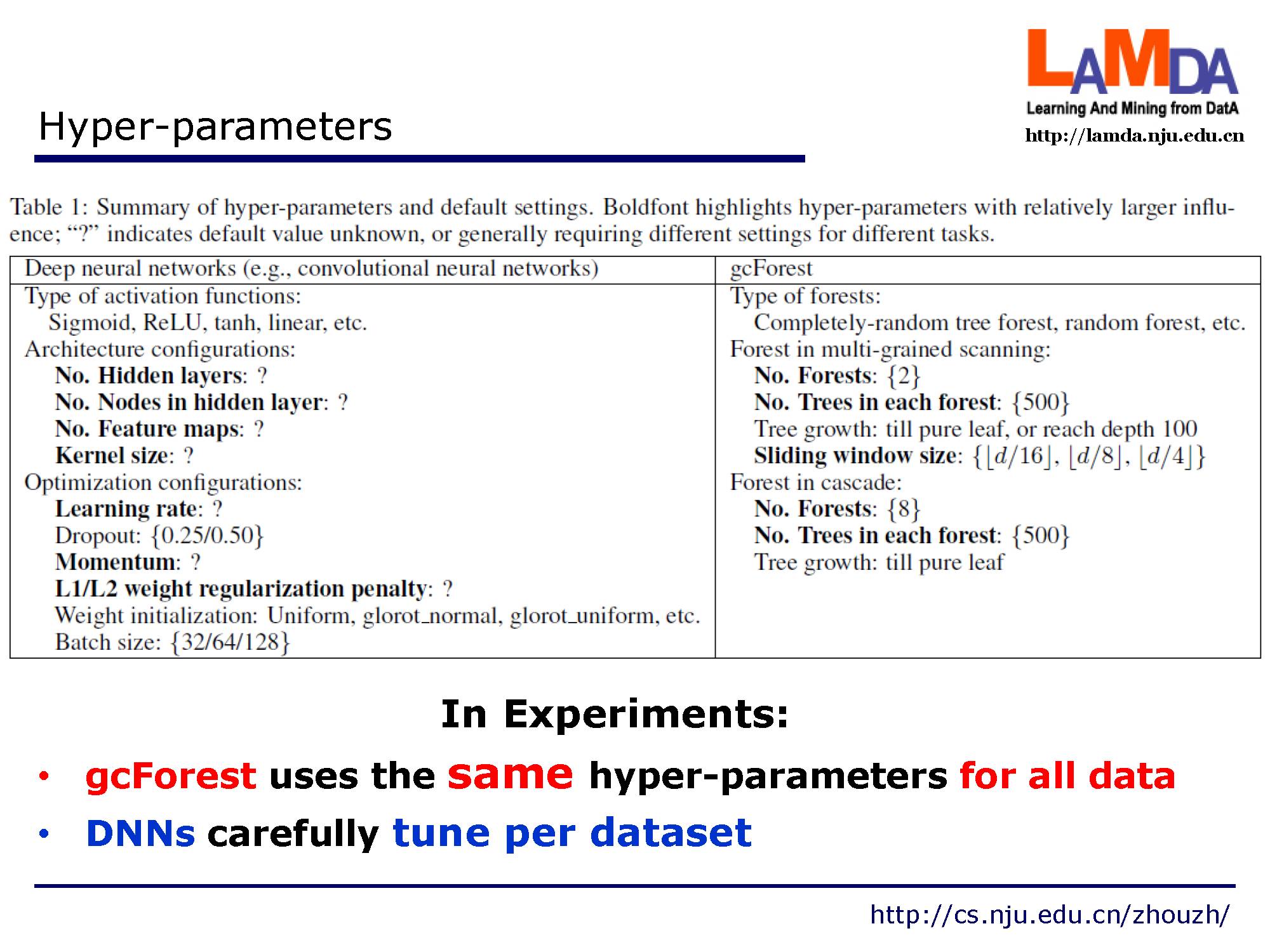
提一些超参数的设置:在实验中,gcForest对所有数据师兄相同的参数配置。而深度神经网络需要针对每个参数进行调试。
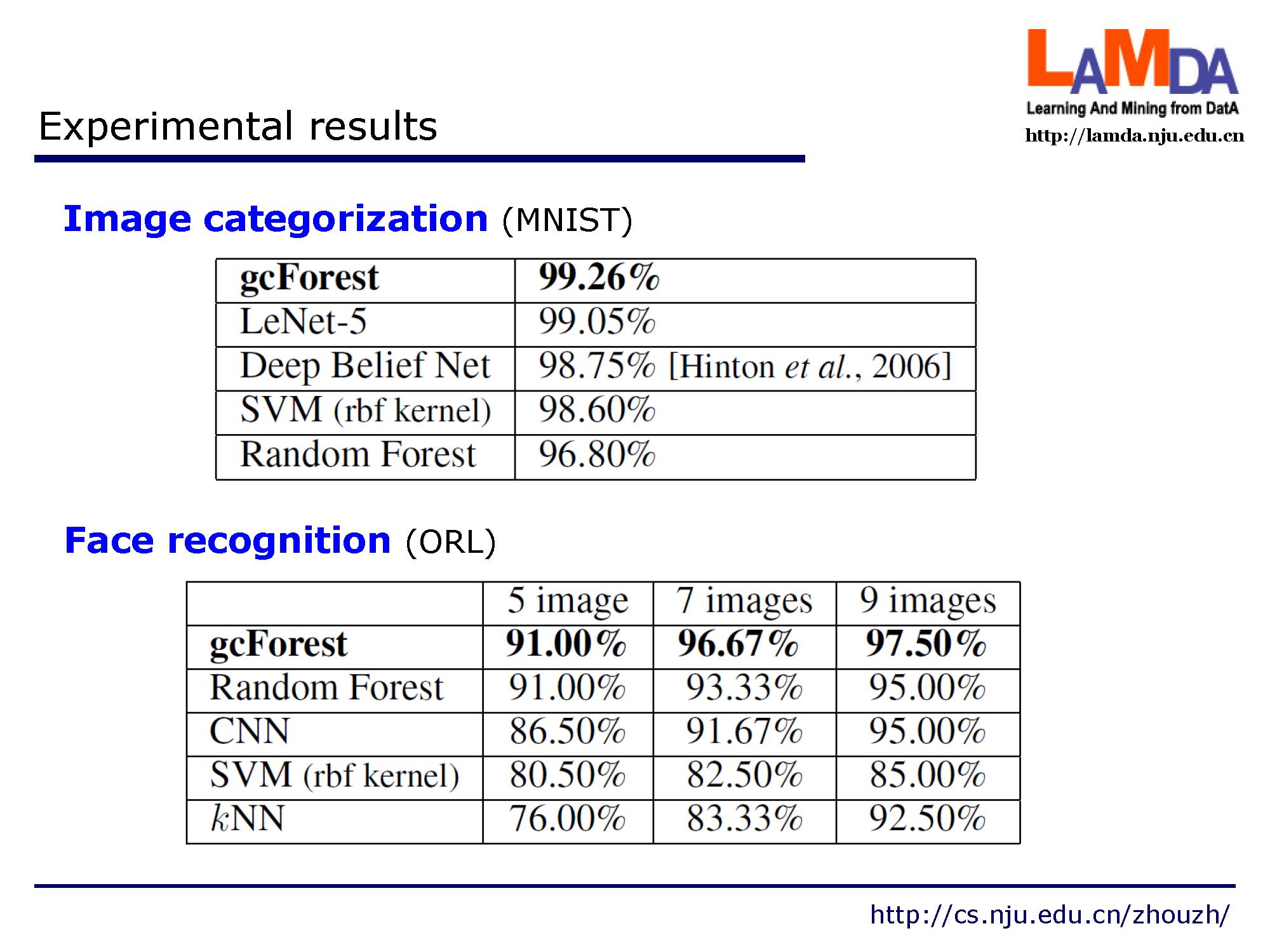
这是在图像分类和人脸识别别数据上的实验结果,可以看出gcForest在和其他经典方法比较中效果显著。
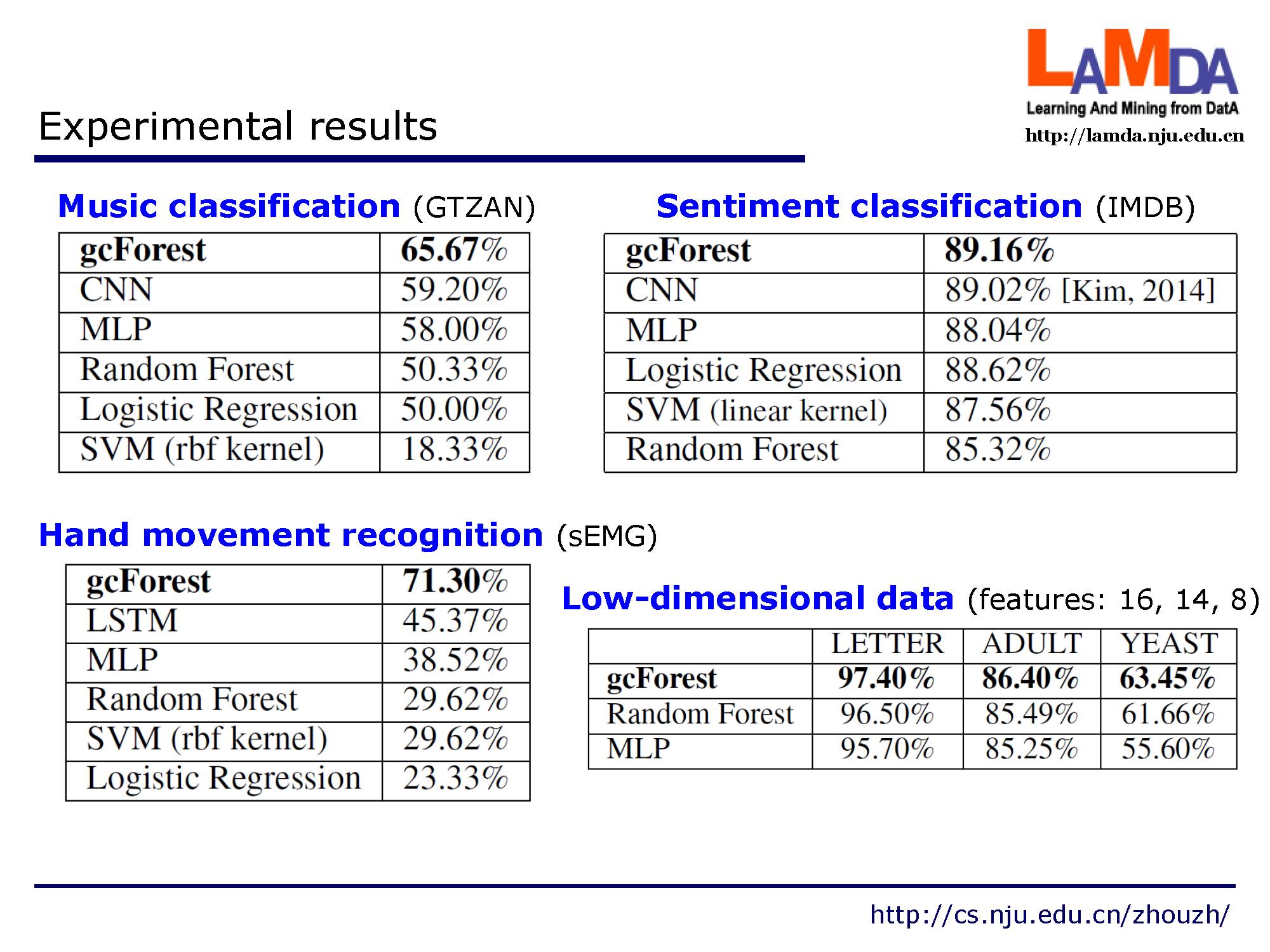
这是一些在不同应用中的实验结果:音乐分类,情感分类,手势识别以及低维数据。提出的方法都领先于其余传统的方法。
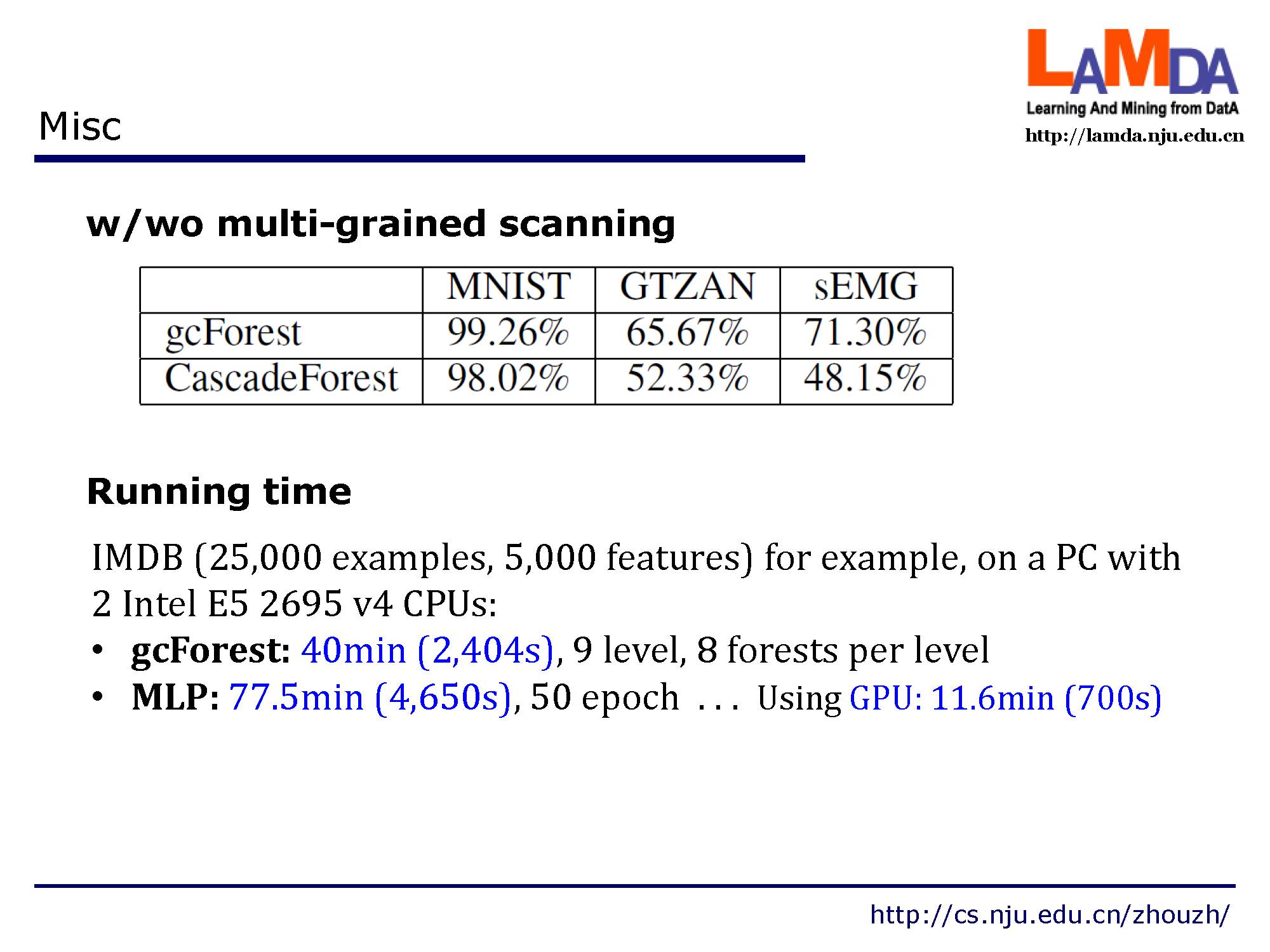
这是是否包含多粒度扫描的结果,以及运行时间。
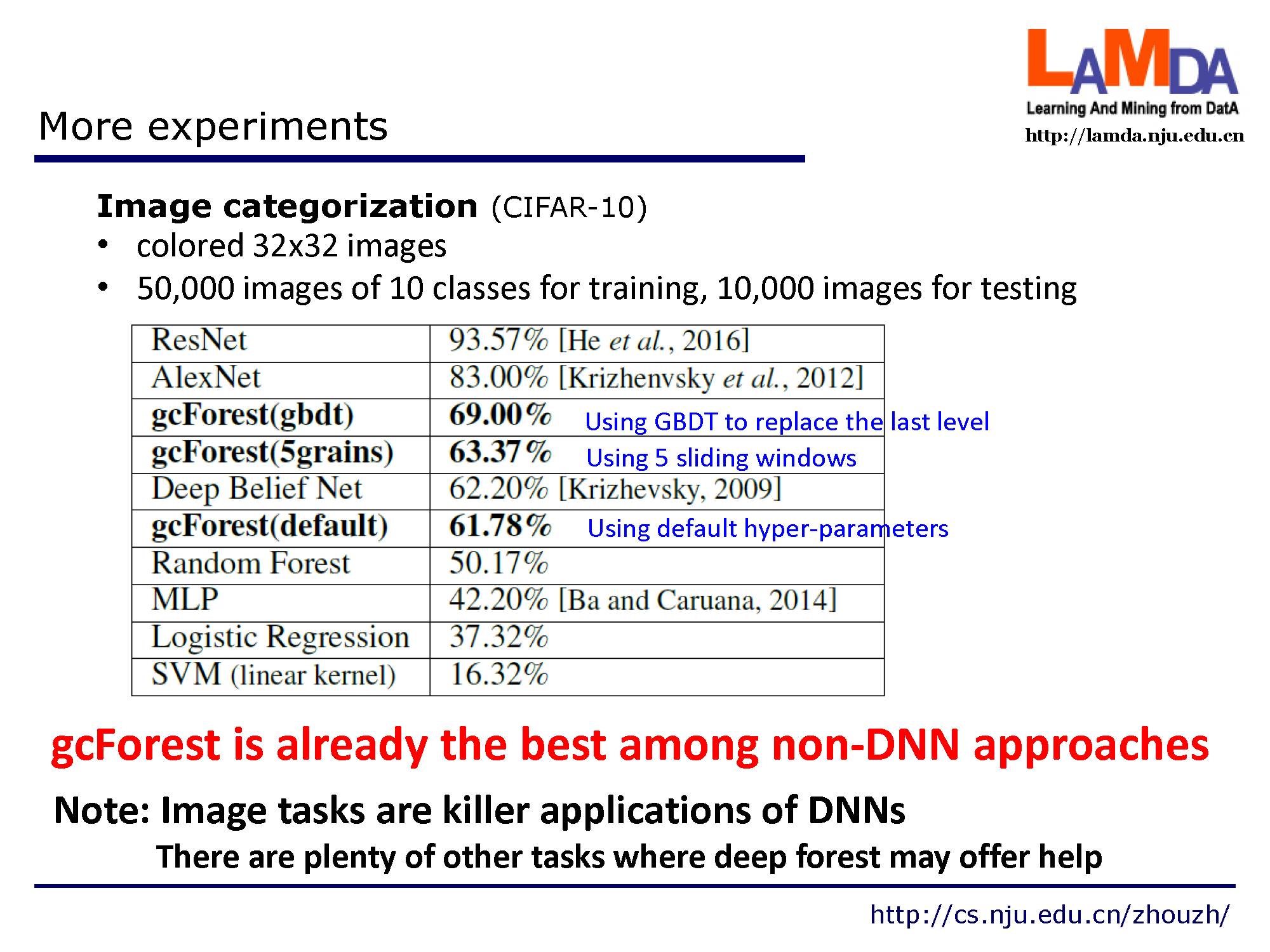
在论文之外做的更多实验,在投稿的IJCAI2017的原版论文中,只是在很小的minst数据集上进行了测试,最新版本arxiv论文中已经加入对cifar-10的图像数据分类实验。 最新实验表明gcForest已经是最好的非深度神经网络方法。注释:当然图像分类是是深度神经网络的拿手任务,gcForest结果还有些差距, 但是在其他很多领域深度森林有着用武之处。
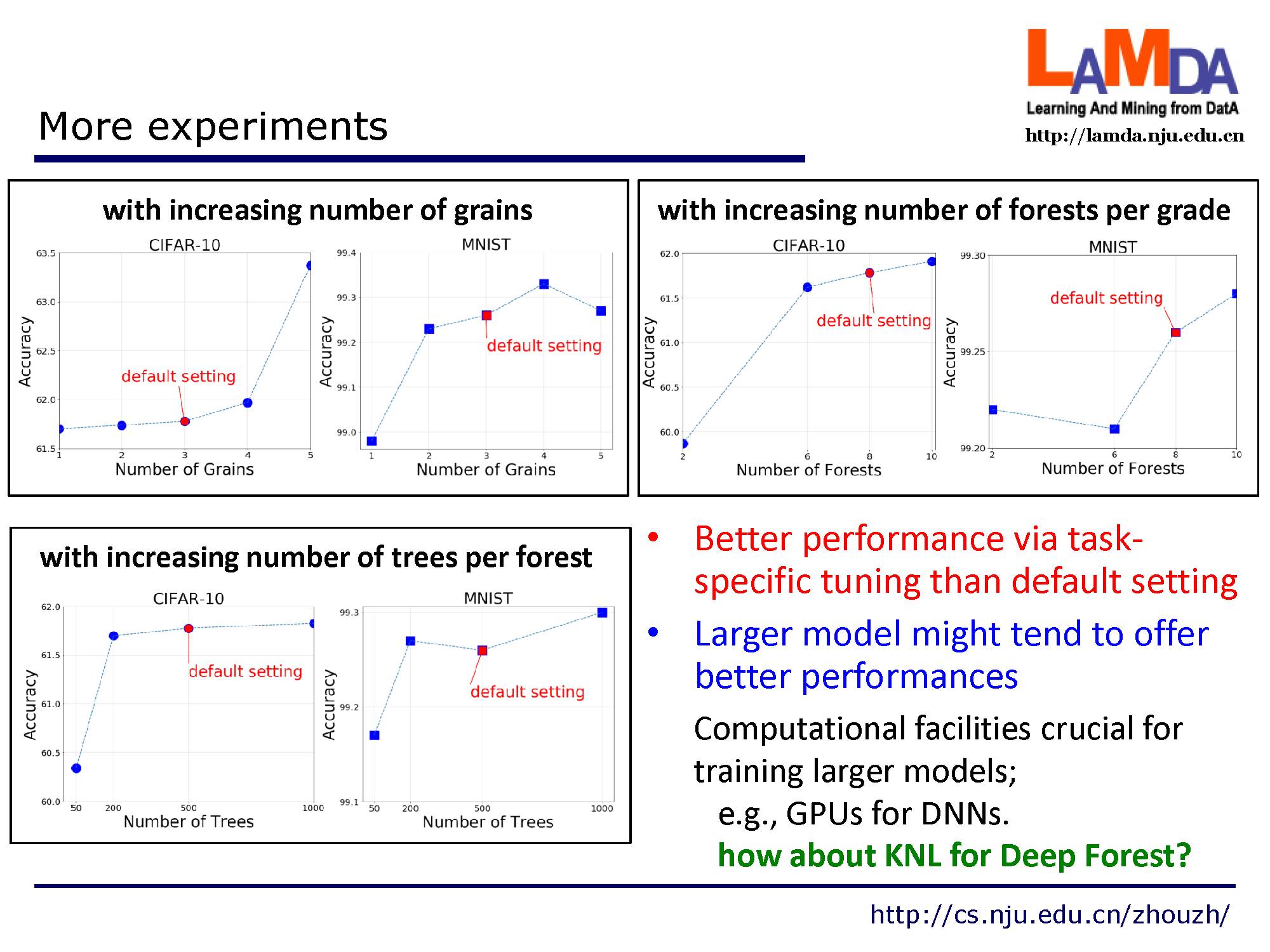
如果进一步针对具体数据进行参数微调,gcForest能到更好的效果。

gcForest是集成方法的一次胜利。当然多样性还是很重要的,我们使用了几乎所有的用于保持个体学习器多样性的方法。

gcForest只是深度森林的一个开始。未来还有很多可能去探索。 附上我们最新添加实验后的论文版本,以及代码地址:http://lamda.nju.edu.cn/code_gcForest.ashx
论文下载:
https://arxiv.org/abs/1702.08835
代码下载:http://lamda.nju.edu.cn/code_gcForest.ashx
MLA会议日程安排:http://tdam-bjkl.bjtu.edu.cn/program.html
特别提示-周志华老师深度森林报告下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“DF”就可以获取报告df下载链接~~
后台回复“MLA2017”就可以获取MLA2017机器学习所有报告下载链接~~
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
获取更多机器学习人工智能知识,请PC登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“ 机器学习” 主题,相关知识等资料!如下图所示~

请查看专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
【教程实战】Google DeepMind David Silver《深度强化学习》公开课教程学习笔记以及实战代码完整版
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!




